Industrial A/B Testing in 2026: Bayesian Methods, CUPED, and Lessons from Meta and Statsig
I recently watched a 28-minute interview with Yuzheng Sun, a Statsig evangelist whose résumé runs through Amazon, Meta, and Tencent before landing at the company that today powers experimentation for OpenAI, Anthropic, Figma, Atlassian, and Canva. The interview is one of the most concentrated 28 minutes on industrial A/B testing I've found in Mandarin, and it pairs naturally with two books I'd recommend to any serious practitioner: David Sweet's Experimentation for Engineers (companion code on GitHub) and Ron Kohavi et al.'s Trustworthy Online Controlled Experiments.
I want to use this post to do two things. First, to share the framework the interview lays out — because it deserves a wider engineering audience. Second, to be transparent about how the FeatBit Release Decision Agent lines up against it: what we already ship, what we're adding next, and where we've taken a different methodological path.
The Release Decision Agent is an open-source AI agent that encodes industrial A/B testing best practices — the ones Yuzheng walks through in the interview, and more — into a set of skills: hypothesis-design, measurement-design, reversible-exposure-control, evidence-analysis, learning-capture, and others. The intent is to let an AI walk a PM, engineer, or growth lead — not a trained data scientist — through a controlled experiment with the rigor a Statsig or Meta team builds in by hiring it. Each principle below maps to a skill, and each skill encodes the right move at the right step so the user doesn't have to remember it.
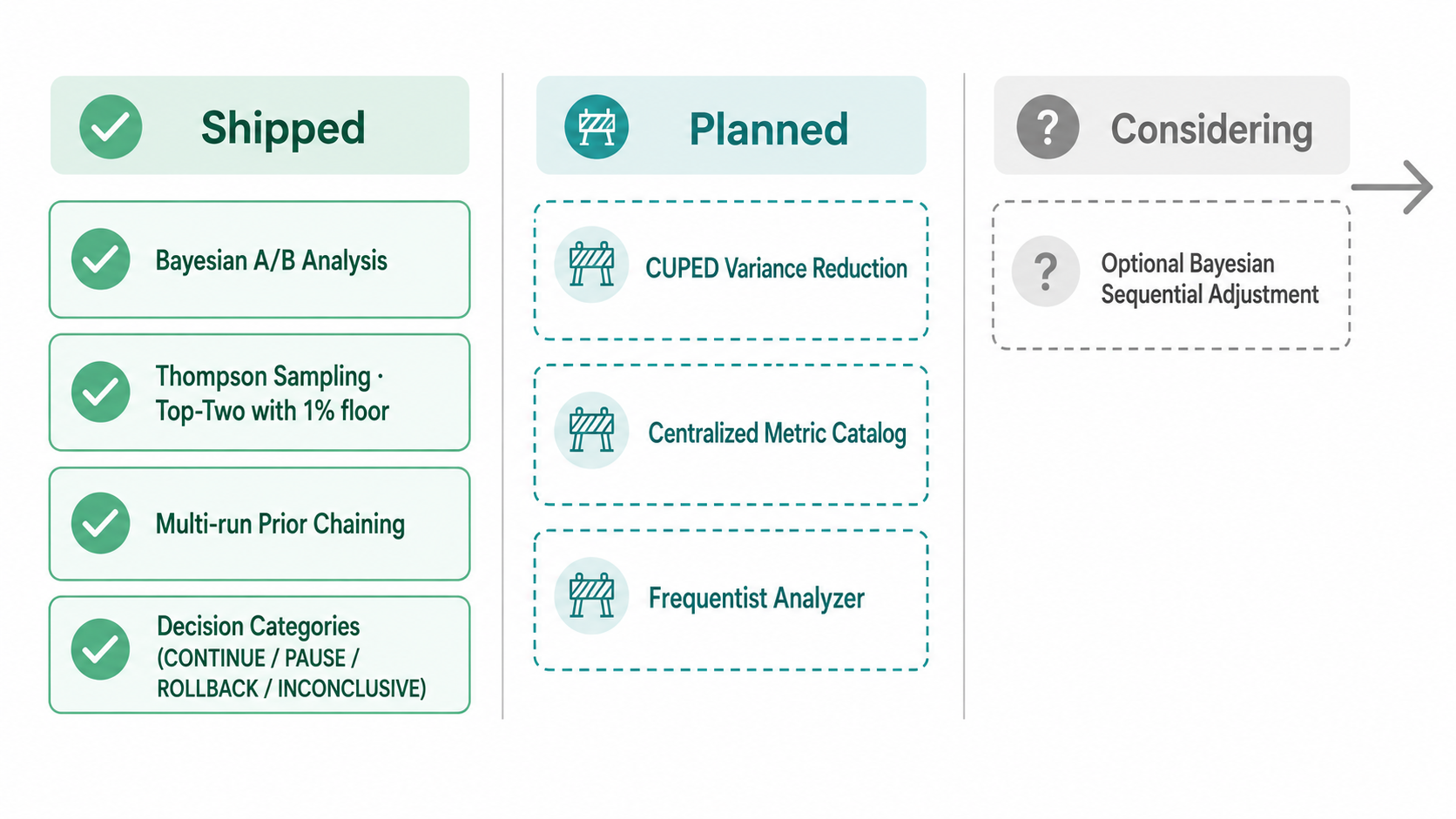
Shared principles, already in our implementation
The value of an experiment comes from being surprised. A result that confirms what you already expected teaches you nothing new — the information lives in the gap between prediction and outcome. Both Kohavi's Bing chapter and Sweet's Chapter 1 report the same number the interview cites: somewhere between 70% and 90% of features engineers expect to win — don't. If you only celebrate wins, your platform is a confirmation engine, not a learning one.
Our hypothesis-design skill enforces this directly. Every hypothesis must be falsifiable before a flag is created. "Will users like it?" gets rejected. "We believe shorter copy will lift signup-to-activation by ≥1pp because the current copy buries the value prop" gets through.
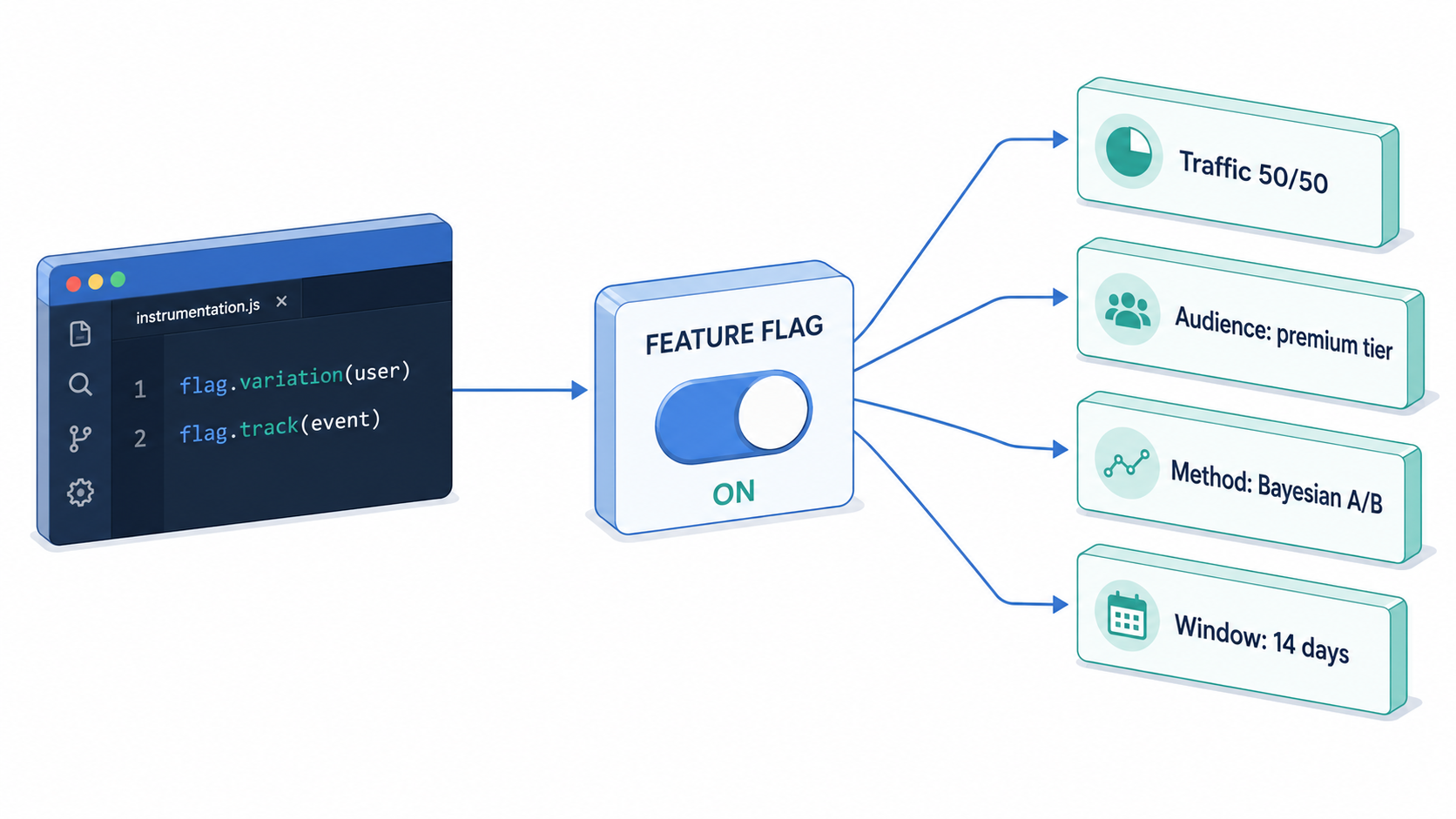
Treat the feature flag and the experiment as one object. A flag controls who sees what; an experiment measures what happens because of it. They share the same traffic splitter, the same audience targeting, the same exposure event — so building them as separate systems means instrumenting the same thing twice and keeping the two in sync forever. This is the architectural insight that lets a company go from "we run a few flagship A/B tests a quarter" to "every flag rollout is automatically an experiment." The interview is right that this is the hidden lever behind Meta-class experimentation rates.
It is also the core design of FeatBit. Developers instrument once — a variation() call plus track() events. The PM configures the experiment scope (traffic split, audience, method, observation window) after the fact, against the same flag. From a code perspective, every flag is already wired for measurement.
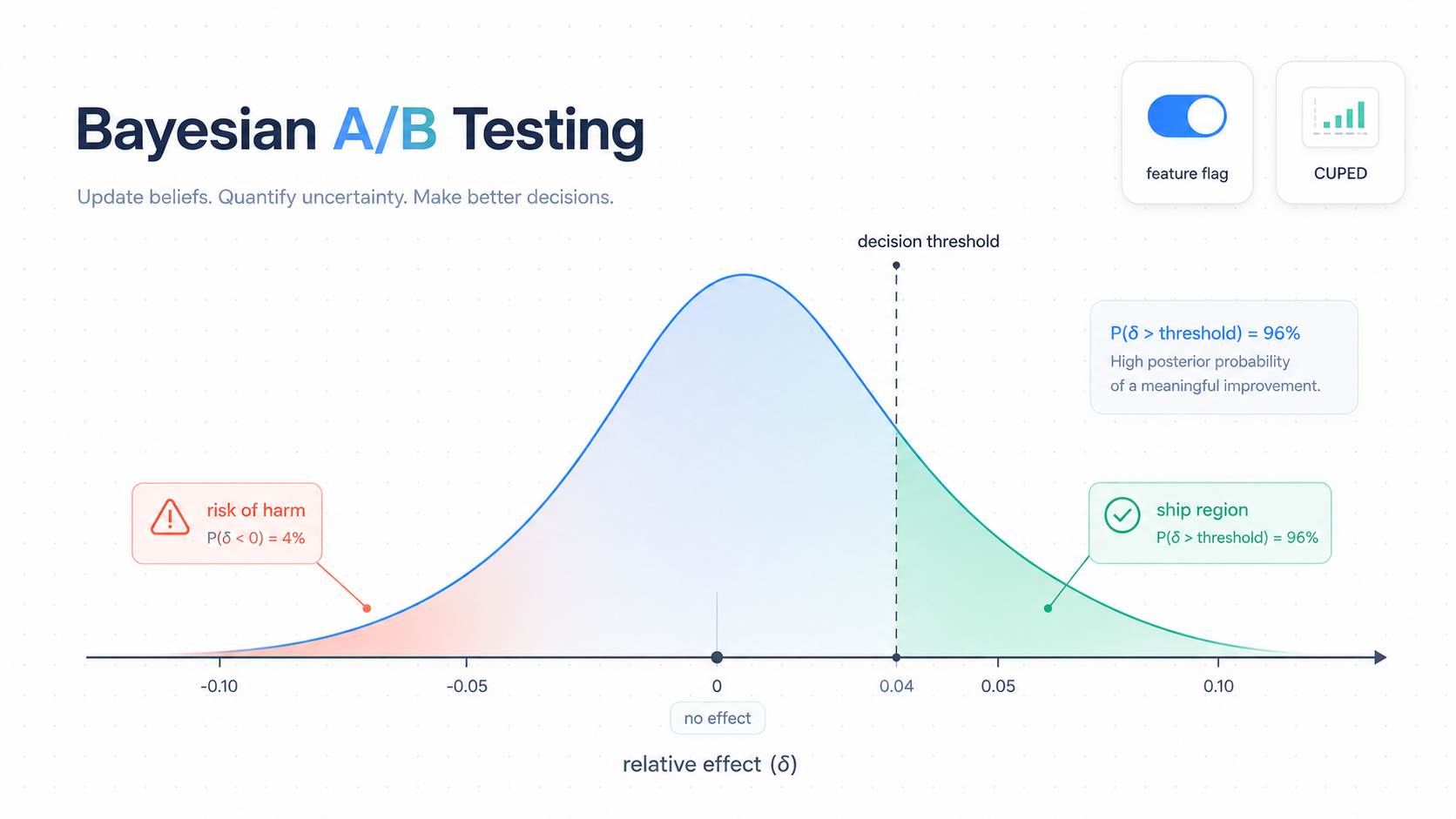
One primary metric. Everything else is a guardrail. A primary metric is the one you're trying to move; guardrails are the metrics that must not break while you do. Picking more than one primary inflates the false-win rate through multiple comparisons and turns every read into a debate about which result to believe. Sweet, Chapter 7, calls this out as the single biggest cause of misread experiments. The interview puts it more bluntly: pedantic data scientists love to multiply metrics; the discipline is to refuse.
Our measurement-design skill rejects multi-primary setups outright. If two metrics both decide success, the hypothesis is too vague — we route back to hypothesis-design. Guardrails are read asymmetrically: a low P(win) is actionable (possible harm); a high P(win) on a guardrail is just noise unless it is your primary.
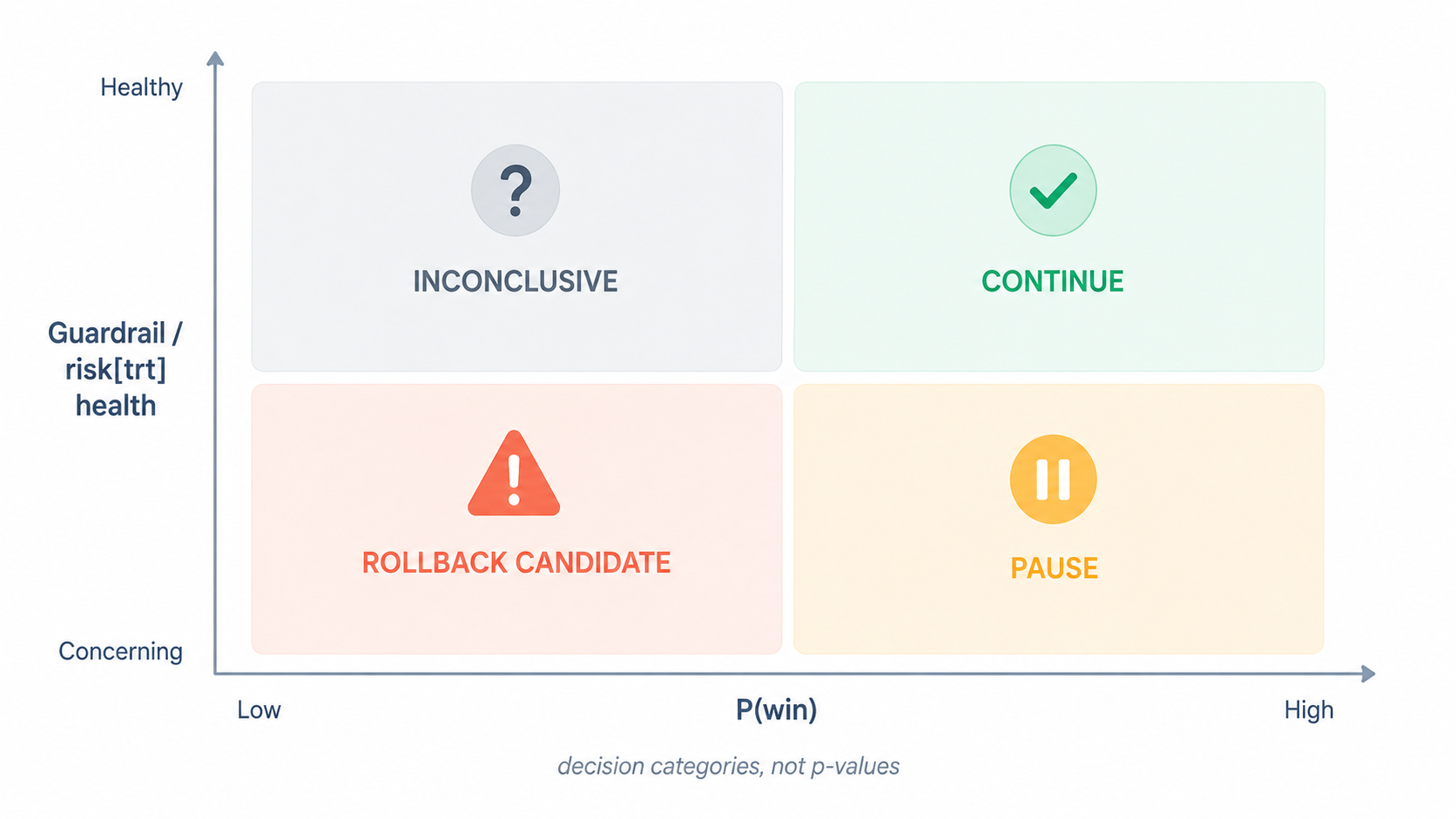
Decision categories beat p-value rituals. A "decision category" is the action the experiment should trigger — ship, hold, roll back — instead of a binary "significant or not" verdict glued to a p < 0.05 threshold. The interview spends real time on a quiet scandal in classical statistics: textbook hypothesis testing inconsistently blends Fisher's P-value framework with the Neyman-Pearson framework. The two were not designed to compose, and most engineers learn the confused hybrid.
We sidestepped that whole debate. Our evidence-analysis skill outputs one of four action categories — CONTINUE, PAUSE, ROLLBACK CANDIDATE, INCONCLUSIVE — backed by P(win) and risk[trt] from a Bayesian posterior. Reviewers do not argue about whether 0.04 differs meaningfully from 0.06. They argue about whether to ship. That is the right argument.
Bandits should be arm-symmetric with a minimum floor. A multi-armed bandit shifts traffic toward variants that look better as data accumulates. "Arm-symmetric" means no variant is privileged just because it is labeled "control"; "minimum floor" means every arm always keeps at least a small slice of traffic so the bandit can recover if an early read turns out wrong. Sweet, Chapter 3, recommends both: never starve any arm of traffic (you cannot recover from early misreadings), and treat the named "control" as a baseline label rather than a privileged variant. Our Thompson Sampling implementation uses a Top-Two strategy with a 1% minimum floor on every arm, and arms are fully symmetric.
Acknowledged gaps and planned work
Three places where the interview is right and we are not there yet.
CUPED is the obvious miss. CUPED — Controlled-experiment Using Pre-Existing Data — uses each user's pre-experiment behavior as a covariate, subtracting out the baseline noise so the metric only reflects what the treatment actually changed. The result: variance drops to roughly 20% of the unadjusted baseline, and experiments converge about five times faster. The interview spends three minutes on it because it deserves three minutes. Trustworthy Online Controlled Experiments discusses it in depth as one of the most cost-effective variance-reduction techniques available; Sweet does not cover it specifically but recommends similar variance-reduction practices in Chapter 8.
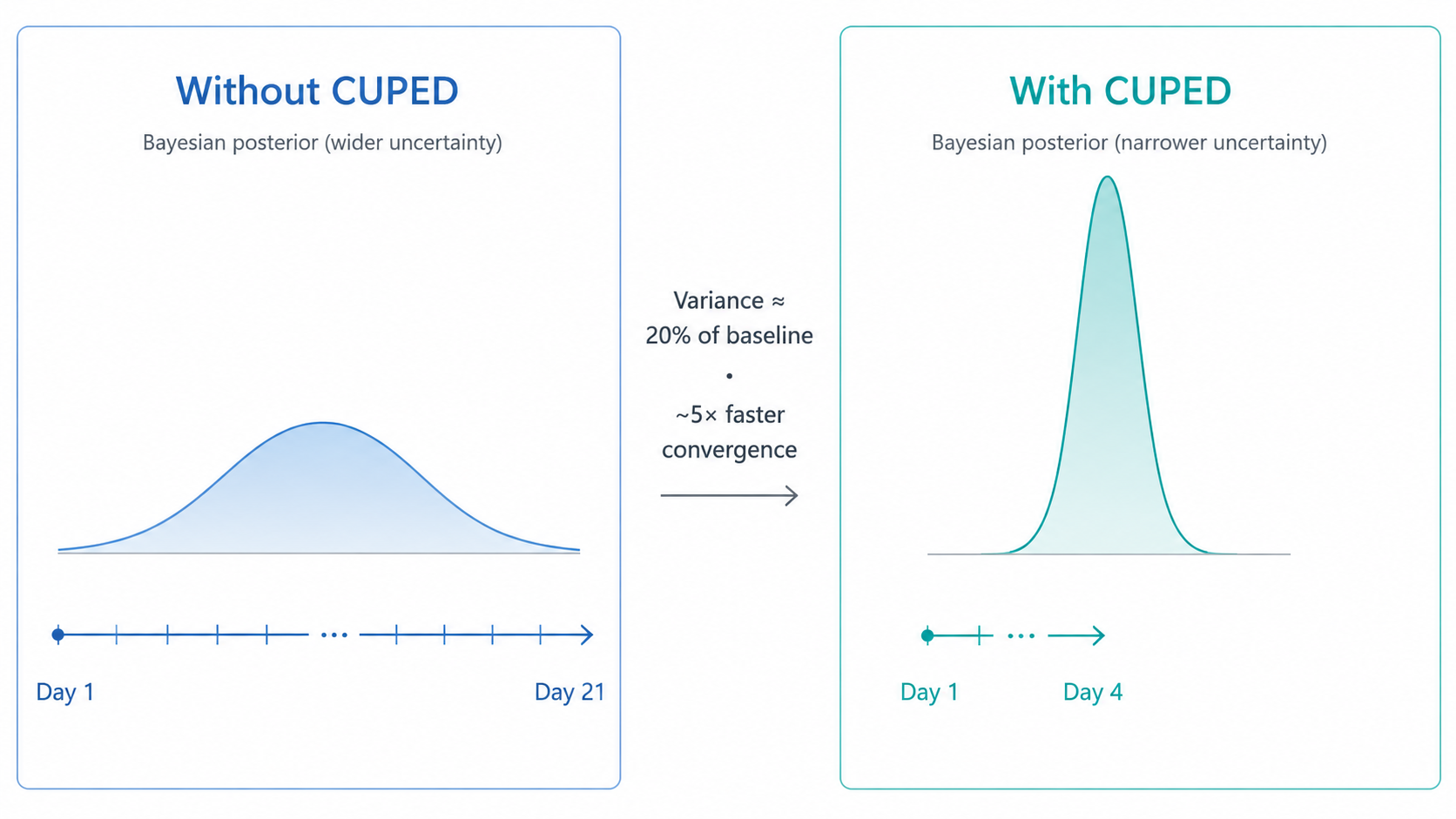
We don't have it. What we do have is a Bayesian informative prior mechanism that borrows strength from past experiments. That is a different axis — historical data across experiments, not pre-experiment covariates within one. The two are complementary, and CUPED is high on our roadmap, especially for continuous metrics like revenue, session duration, and latency.
A centralized metric catalog. The interview describes Statsig's "metric catalog" — every metric in the company defined once, with traceable lineage from event log to aggregation, available across all experiments. Kohavi's institutional view of a trustworthy platform requires this. Our position is two-track. On the FeatBit managed data warehouse, we are currently per-experiment: each experiment defines its primary metric event in isolation, and cross-experiment metric reuse is informal — fine at small scale, brittle at organizational scale, and on the list to fix. But we also let customers point the Release Decision Agent at their own data warehouse, which means their existing semantic layer — dbt models, Looker/Cube definitions, the metric catalog their data team already maintains — becomes the source of truth. For organizations that have already invested in a metric layer, the centralization problem is already solved; we just read from it.
A frequentist analyzer for teams that want one. A frequentist analyzer reports results as p-values and confidence intervals; a Bayesian analyzer reports them as posterior probabilities like P(win) and credible intervals. The interview's view is that the two, with non-informative priors, produce the same decisions. We agree — and we chose Bayesian first because Experimentation for Engineers (Chapters 3 and 6) builds its decision theory on Bayesian foundations, and because P(win) = 96% is something a PM can act on without a statistics degree. That said, our API schema already whitelists method: "frequentist" as a future-supported value. We shipped one analyzer well before shipping two badly. The frequentist analyzer is planned, not philosophical pushback.
An alternative path to the same business need
Formal alpha-spending sequential testing. Sequential testing lets you check an experiment's results as data accumulates instead of waiting for a fixed sample size; the alpha-spending variant keeps the cumulative false-positive rate fixed by allocating the alpha budget across each look in advance, so peeking can't accidentally inflate it. The interview makes a strong case for it as the structural defense against peeking. Sweet, Chapter 8, agrees that peeking is a leading source of false positives. We do not implement frequentist sequential testing, and we currently do not plan to.
What we do support is the two-phase prior-chaining workflow you can see in our UI: an experiment can have Run 1 (pilot, flat prior), Run 2 (main, informative prior derived from Run 1's rel Δ and credible interval), and Run 3 (a 30/60/90-day holdout). The data windows do not overlap, so the math stays clean.
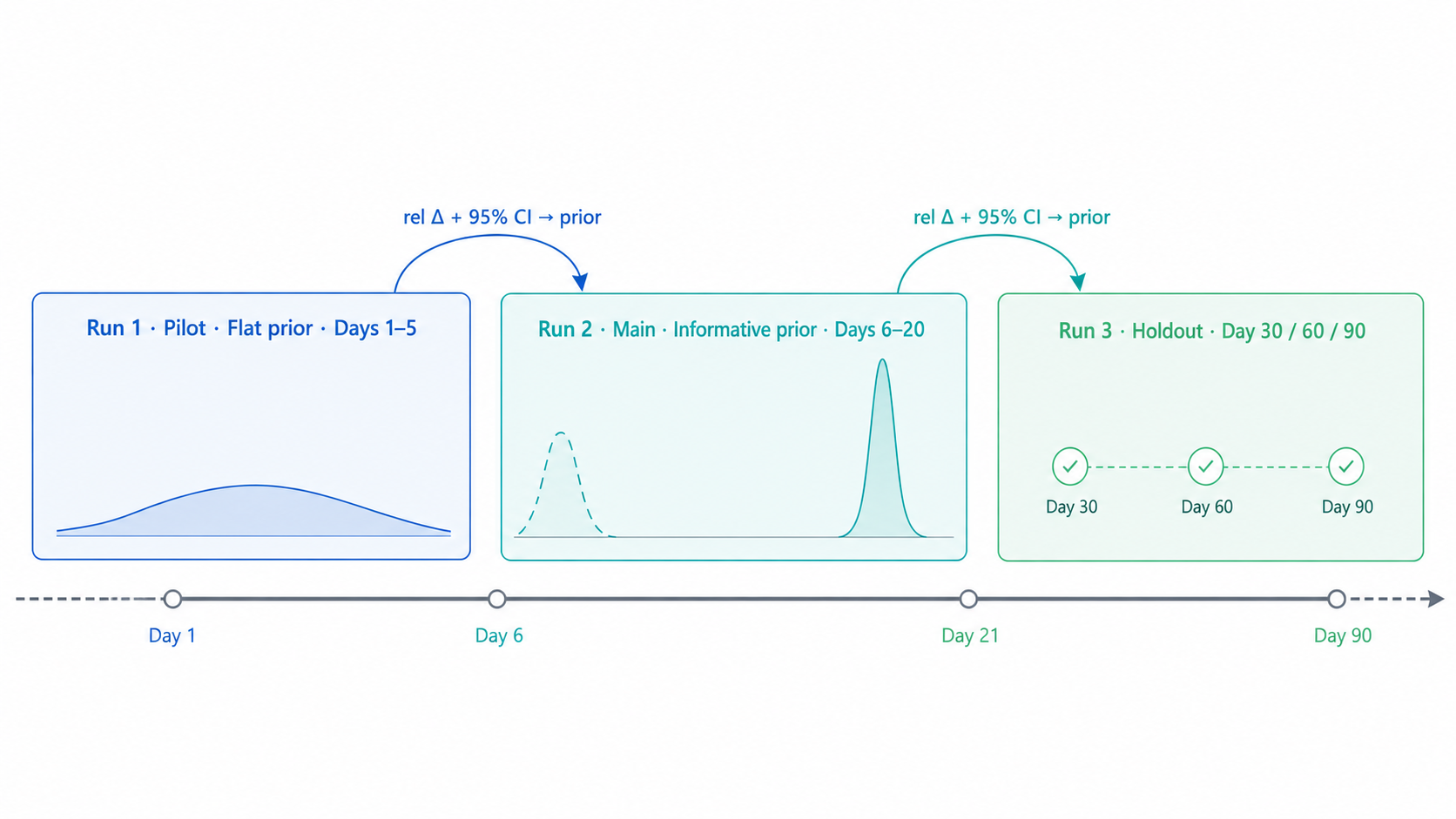
This covers the business need sequential testing addresses — incremental confidence as evidence accumulates — through Bayesian prior chaining instead of alpha spending. The two are not statistically equivalent. A real frequentist sequential test gives guarantees about Type-I error under repeated looks; prior chaining gives a coherent posterior per phase. We find the prior-chaining model easier to explain and easier to act on, and we are sticking with it.
If peek-driven false positives become a real concern in practice, the next thing we would add is an optional Bayesian sequential adjustment — one that tightens the P(win) threshold as the number of looks grows. That is a smaller, more contained extension than wiring in alpha-spending machinery.
Beyond tooling — and the road ahead
The interview lands on a point I want to repeat: experimentation is a culture problem before it is a tooling problem.
A platform can drive the marginal cost of running an experiment toward zero. It can make the decision artifact tamper-evident. It can refuse to let a PM ship without a hypothesis. What no tool can do is make a team comfortable being wrong 80% of the time. That comfort — Kohavi calls it intellectual humility, the interview calls it intellectual honesty — is what separates Meta-class experimentation from spreadsheet-driven A/B tests.
If you are picking an experimentation stack today, the right question is not "does it have CUPED?" It is "does this tool make it easier or harder to admit we were wrong?" That is the question we ask ourselves about every skill we add to the Release Decision Agent.
A/B testing and the underlying statistics keep moving. CUPED was a 2013 paper, Thompson Sampling re-emerged from a 1933 idea after sitting on the shelf for eight decades, and the conversation around always-valid confidence sequences is still alive in the literature. We do not assume today's defaults will be tomorrow's. We will keep reading, keep listening to practitioners like the one in this interview, and keep updating the agent — transparently, in posts like this one — so that what you adopt is grounded in current evidence rather than yesterday's convention.
CUPED is coming. So is the metric catalog. The frequentist analyzer is in the schema, waiting. We will tell you when each one ships, and we will tell you what we learned that made us change our mind.