A/B Testing for LLM Prompts: A Practical Rollout Playbook
A/B testing for LLM prompts should answer a release question, not a copywriting preference: when prompt A and prompt B are served to comparable users under controlled exposure, which prompt improves the real product outcome while staying inside quality, cost, latency, and safety guardrails?
That makes prompt experiments different from a quick playground comparison. You need stable assignment, exposure events, outcome metrics, guardrails, and rollback before the new prompt becomes the default. FeatBit's point of view is that a prompt change is a runtime release decision. It should be targetable, measurable, reversible, and cleaned up after the decision.
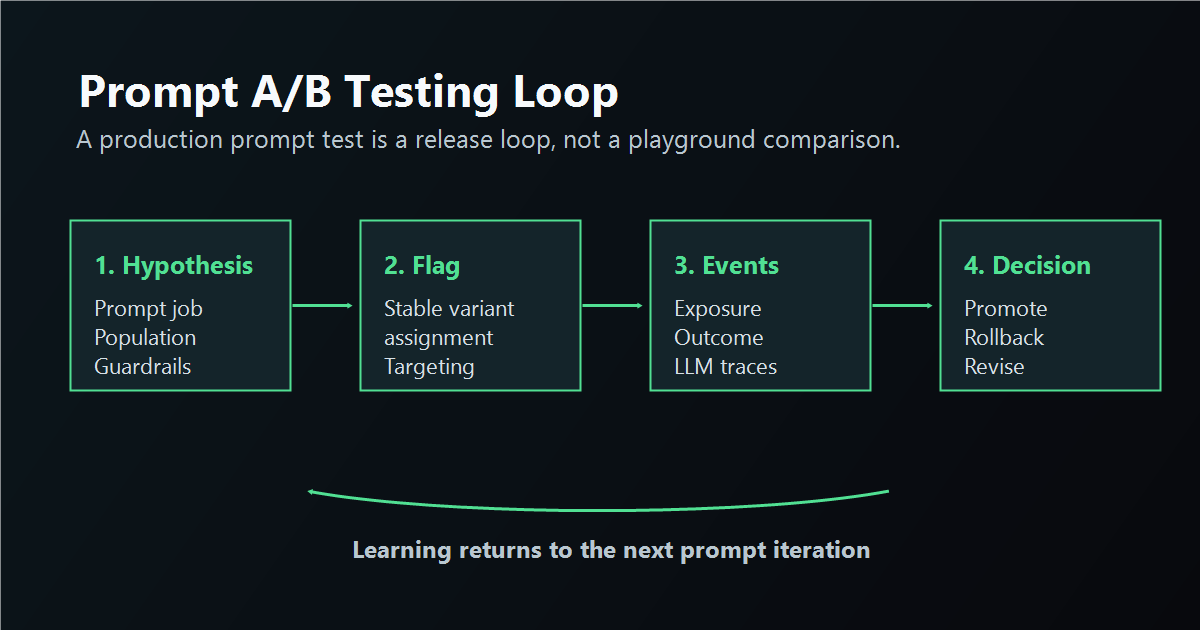
What Makes Prompt A/B Testing Different
Prompt tests look simple because the artifact is text. The release risk is not simple.
A prompt can change answer length, tone, refusal behavior, tool-use frequency, retrieval sensitivity, token cost, latency, and the way users trust the product. It can improve the average answer while making an important segment worse. It can also appear better in offline examples while failing on production phrasing, customer-specific context, or long-tail inputs.
Treat an LLM prompt A/B test as a controlled production experiment when:
- The prompt affects a user-visible answer or an operator-visible decision.
- The team needs evidence from real traffic, not only an offline eval.
- The new prompt might change cost, latency, fallback rate, escalation rate, or trust.
- The team needs to roll back without redeploying the application.
- The result should become a release decision: keep the old prompt, promote the new prompt, narrow the rollout, or iterate.
OpenAI's eval guidance describes evals as a way to test model outputs against task-specific criteria before deployment. That is useful pre-production evidence. A production A/B test answers a different question: what happens when real users, real context, and real product incentives meet the prompt variant?
Start With A Release Hypothesis
Do not start with "prompt v2 sounds better." Start with the decision you need to make.
A useful hypothesis is narrow:
For support ticket summarization, prompt B will increase accepted AI drafts by 6 percent among English-language tickets while keeping p95 latency, average token cost, hallucination reports, and human escalation rate within existing guardrails.
That hypothesis defines the experiment:
| Element | Example |
|---|---|
| Decision point | Support ticket summarization prompt |
| Control | Current production prompt |
| Treatment | Candidate prompt with stricter structure and evidence citations |
| Population | Eligible English-language support tickets |
| Primary metric | Accepted AI draft rate |
| Guardrails | Latency, token cost, hallucination reports, escalation rate |
| Decision | Promote, roll back, keep testing, or revise |
The hypothesis should also say what is not changing. If you change the prompt, model, retrieval rules, temperature, and tool policy at the same time, you are testing a bundle. That can be valid, but the variant should be named as a bundle so the result is not misread as "the prompt won."
Use Feature Flags For Stable Prompt Assignment
An LLM prompt experiment needs stable assignment. The same user, account, ticket, or workflow should not bounce between prompt variants in a way that contaminates the result or creates inconsistent experiences.
A feature flag can carry the prompt version or prompt template identifier:
const promptVariant = await flags.getString(
'support_summary_prompt',
user,
'control_v1'
);
const prompt = promptVariant === 'treatment_v2'
? supportSummaryPromptV2
: supportSummaryPromptV1;
const response = await llm.generate({
prompt,
ticket,
customerContext,
});
The important part is not the exact SDK call. The important part is the control plane:
- Target internal users before exposing customers.
- Assign eligible production traffic stickily by user, account, or request entity.
- Exclude segments that are too risky for the first test.
- Record which prompt variant served each request.
- Roll back by changing the flag, not by waiting for a redeploy.
This is why FeatBit describes feature flags as an AI control layer. Prompt versioning records what changed; flags control who sees each prompt version in production.
Pick Metrics That Match The Prompt's Job
Prompt A/B tests often fail because the metric is too vague. "Better answer" is not a release metric. The primary metric should match the product job the prompt is supposed to improve.
| Prompt use case | Primary metric examples | Guardrail examples |
|---|---|---|
| Support answer drafting | Accepted draft rate, time to first useful response | Hallucination reports, escalation rate, p95 latency, token cost |
| Product onboarding copilot | Completed setup task, qualified next step | Unsafe answer rate, user frustration signal, manual override rate |
| RAG answer generation | Helpful answer click, successful search session, citation acceptance | Missing citation rate, source mismatch rate, retrieval cost |
| Coding assistant | Accepted suggestion, task completion, review pass rate | Build failure rate, security finding rate, reviewer correction load |
| Agent instruction prompt | Completed workflow without intervention | Tool error rate, blocked action rate, human override rate |
Guardrails are part of the decision, not optional dashboard decoration. A prompt can improve task completion while increasing token cost beyond budget. It can reduce escalations by being overconfident. It can raise short-term conversion while hurting support quality. The experiment should make those tradeoffs visible before promotion.

Run The Prompt Test As A Staged Release
A practical prompt experiment has more than one step.
- Offline eval: compare control and treatment against representative examples, known failure cases, and rubric checks.
- Internal exposure: serve the treatment prompt to employees or a trusted test segment through the flag.
- Limited production exposure: assign a small eligible cohort while watching telemetry and support signals.
- Balanced A/B test: run a clean control and treatment comparison once the prompt is safe enough to measure.
- Decision and cleanup: promote the winner, roll back, or revise the prompt; then remove stale experiment branches.
This sequence keeps the release question clear. Offline eval asks whether the prompt is ready to touch production. Early exposure asks whether obvious production failures appear. The A/B test asks whether the prompt improves the product outcome enough to become the default.
FeatBit's safe AI deployment and LLM canary release pages expand the rollout side of this workflow. For a broader experimentation context across prompts, models, retrieval settings, and agent behavior, see experimentation for AI systems.
Instrument Exposure And Outcome Events
You cannot analyze a prompt experiment if exposure and outcomes cannot be joined.
At minimum, record:
- The flag key and variation.
- The prompt version identifier.
- The assignment key, such as user ID, account ID, ticket ID, or session ID.
- The model and parameter set if they could affect the result.
- The request class, locale, plan, workflow, or segment used for analysis.
- Outcome events tied to the same assignment key.
- Guardrail signals such as latency, token cost, fallback, error, refusal, escalation, and review correction.
OpenTelemetry semantic conventions for generative AI systems make it easier for teams to attach consistent attributes to LLM calls and analyze traces across providers and frameworks. You do not need every attribute on day one, but you do need a consistent way to connect prompt variant, LLM behavior, and product outcome.
In FeatBit, the implementation path usually connects three pieces:
- A multivariate flag assigns the prompt variant.
- Evaluation events tell the team who saw which variant.
- Metric or track events record what happened after exposure.
For implementation details, start with FeatBit's docs for A/B testing with feature flags, targeted progressive delivery, and feature flag insights.
Decide Before You Look At The Result
A prompt experiment needs a decision rule before the first user is assigned. Otherwise the team can keep changing the interpretation until the answer matches intuition.
Use a plain-language decision rule:
prompt_experiment_decision:
primary_metric: accepted_ai_draft_rate
promote_when:
- treatment improves the primary metric enough to matter
- latency and token cost remain inside guardrails
- hallucination reports do not increase
- segment readout shows no meaningful harm in priority cohorts
roll_back_when:
- safety or correctness issue appears
- guardrail threshold is breached
- exposure or outcome telemetry is missing
revise_when:
- offline review finds a repeatable failure mode
- treatment helps one segment but harms another important segment
The wording "enough to matter" should be translated into a numeric threshold by the team running the experiment. The right threshold depends on traffic volume, business impact, risk tolerance, and whether the prompt controls a low-risk suggestion or a high-impact workflow.
NIST's AI Risk Management Framework is a useful external reference for this mindset because it frames AI risk management around governance, mapping, measurement, and management. For prompt releases, that means the experiment is not only a metric report. It is a controlled risk decision.
Common Mistakes In LLM Prompt Experiments
The most common mistake is treating prompt A/B testing as a one-off analytics exercise instead of a release-control workflow.
Other avoidable mistakes include:
- Testing a prompt without stable assignment.
- Letting the same user see multiple variants during a short decision window.
- Changing prompt, model, retrieval, and temperature together without naming the bundle.
- Optimizing for a judge score while ignoring real user behavior.
- Looking only at aggregate results and missing segment-level harm.
- Running without a rollback path.
- Forgetting to remove the old prompt branch after the decision.
The cleanup point matters. A prompt experiment flag should have an owner, review date, expected end state, and cleanup path. If prompt B becomes permanent, remove the obsolete prompt template and archive the experiment flag according to your feature flag lifecycle management rules.
How FeatBit Fits The Workflow
FeatBit is useful for prompt A/B testing because prompt selection is a runtime decision. A team can use a multivariate flag to route users, accounts, or request classes to prompt variants, start with internal traffic, expand by percentage, record exposure, and roll back quickly when guardrails fail.
FeatBit does not replace prompt evaluation tools, LLM observability, product analytics, or human review. It connects the release decision. The flag controls who sees which prompt. Evaluation and analytics explain whether the treatment is better. Observability shows whether the system remains healthy. The release decision tells the team whether to promote, pause, roll back, or iterate.
The goal is not to run more prompt experiments. The goal is to stop shipping prompt changes by intuition when the change can affect users, cost, safety, or trust.
Source And Image Notes
- OpenAI Evals guide: https://platform.openai.com/docs/guides/evals
- OpenTelemetry semantic conventions for generative AI systems: https://opentelemetry.io/docs/specs/semconv/gen-ai/
- NIST AI Risk Management Framework: https://www.nist.gov/itl/ai-risk-management-framework
- FeatBit A/B testing docs: https://docs.featbit.co/getting-started/how-to-guides/ab-testing
- FeatBit targeted progressive delivery docs: https://docs.featbit.co/getting-started/how-to-guides/targeted-progressive-delivery
- FeatBit feature flag insights docs: https://docs.featbit.co/feature-flags/the-flag-insights
- Open Graph recommendation: use
/images/blogs/ab-testing-llm-prompts/cover.pngas the social preview image. The body diagrams support the release workflow and guardrail scorecard; the main guidance remains in crawlable Markdown text.