How to A/B Test AI Changes Without Guessing
A/B testing AI means comparing two or more AI behaviors under controlled production exposure, then deciding from user outcomes and guardrail metrics whether the candidate should ship, pause, roll back, or be redesigned. The behavior might be a prompt, model route, retrieval profile, tool policy, ranking strategy, or a bundle of those changes.
The important distinction is this: an offline eval asks whether the candidate is good enough to expose. An online A/B test asks whether the candidate improves the product for real users without creating unacceptable quality, latency, cost, safety, or support risk.
This guide is intentionally broader than a prompt-only or model-only tutorial. Use it when the question is "how do we A/B test this AI change at all?" and you need an experiment shape before choosing tooling.
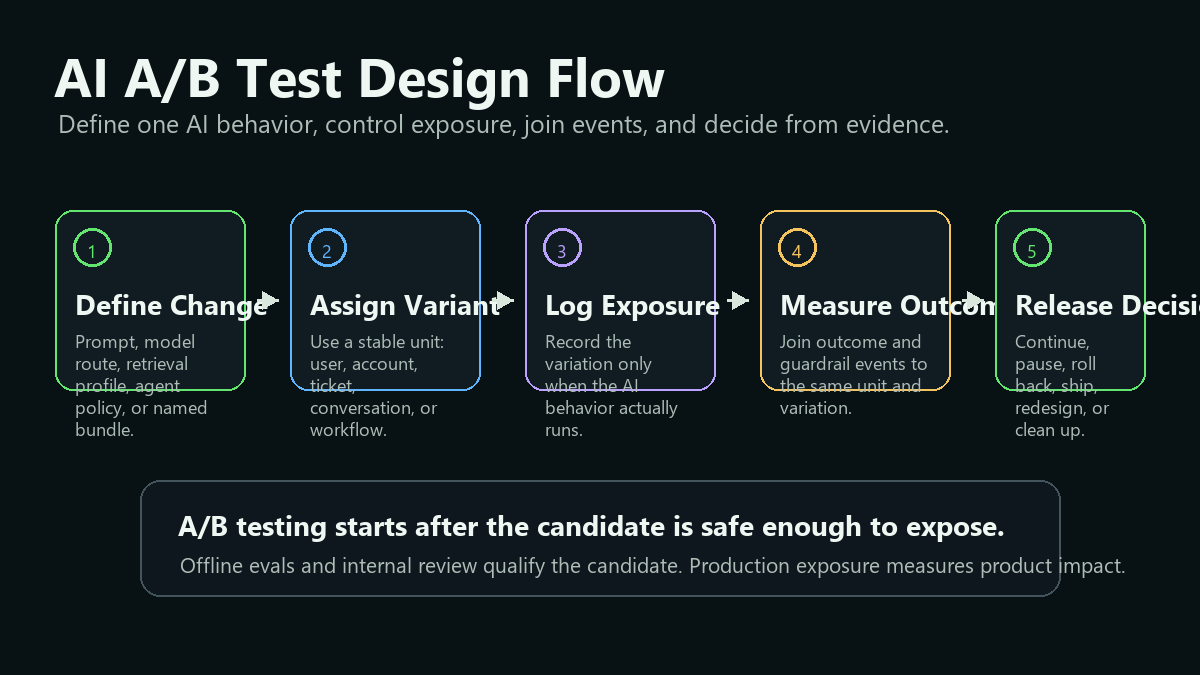
Start With The AI Change, Not The Tool
The first step is to name the AI behavior being tested. If the team cannot name the treatment, the experiment will be hard to interpret.
| AI change | A clean A/B test compares | A muddy test compares |
|---|---|---|
| Prompt | prompt v1 versus prompt v2 for one workflow | a new prompt, new model, and new retrieval index at once |
| Model route | current model route versus candidate route | a provider migration plus a pricing policy change |
| Retrieval | baseline retrieval profile versus reranked retrieval | a new corpus, chunker, prompt, and model bundle |
| Agent policy | current tool policy versus stricter approval policy | several autonomy levels and UI changes together |
| Configuration | conservative temperature versus candidate setting | many parameters changed without a named variant |
Bundled variants are allowed when that is the real product decision. For example, "fast support route v2" might include a smaller model, shorter prompt, and stricter fallback. The key is to name the bundle honestly so the result is not misattributed to only the model or only the prompt.
If the change is specifically a model route, see the model-focused guide to A/B testing AI models for business impact. If the change is a prompt, the prompt-focused guide to A/B testing LLM prompts goes deeper on prompt assignment and prompt cleanup.
Write A Release Hypothesis
An AI A/B test should begin with a release decision, not curiosity. A useful hypothesis names the treatment, audience, expected outcome, guardrails, and decision action before traffic starts.
ai_ab_test:
decision: should support summaries use evidence_first_ai_v2 by default?
control: current_summary_behavior
treatment: evidence_first_ai_v2
eligible_scope: English support tickets for beta accounts
assignment_unit: ticket_id
primary_metric: accepted_ai_summary_rate
guardrails:
- human_correction_rate
- p95_latency_ms
- average_token_cost
- escalation_after_summary_rate
rollback: serve current_summary_behavior to all eligible tickets
cleanup: remove the losing branch after the release decision
That template keeps the team out of two common traps: testing because a model or prompt feels newer, and interpreting the result after seeing the data. FeatBit's release decision framework uses the same loop: intent, hypothesis, reversible exposure, measurement, evidence, decision, and learning.
Decide Whether A/B Testing Is The Right Method
Not every AI change should start as a 50/50 experiment. Use the method that matches the risk and evidence need.
| Situation | Better first step | Why |
|---|---|---|
| Severe safety or compliance risk is plausible | offline eval, red-team review, restricted internal exposure | user traffic should not be the first detector of severe harm |
| The workflow has too little traffic | longer staged rollout, proxy metric, qualitative review | a statistical readout may be too slow or noisy |
| The candidate changes a visible multi-step journey | user, account, conversation, or workflow assignment | request-level randomization can break continuity |
| The candidate affects cost or latency materially | canary plus guardrail gates before balanced A/B | operational health should be checked before broad split |
| The product question is business impact | controlled A/B test with outcome events | offline quality scores cannot prove business impact |
OpenAI's Evals documentation is useful for structured pre-production evaluation. NIST's AI Risk Management Framework frames AI work around governance, mapping, measurement, and management. Those sources support a practical rule: qualify the candidate before exposure, then use production experimentation only for questions that need real-user evidence.
Use Flags For Stable Assignment And Rollback
AI A/B testing needs stable assignment. The same user, account, ticket, conversation, or workflow should stay in the same variation for the decision window unless the team intentionally rolls back or narrows exposure.
Feature flags are a natural control plane for that assignment:
type AiSummaryVariant = "control" | "evidence_first_v2";
const variant = await flags.getString(
"support_summary_ai_behavior",
{
key: ticket.id,
custom: {
accountId: ticket.accountId,
locale: ticket.locale,
plan: ticket.plan,
},
},
"control"
) as AiSummaryVariant;
const summary = await summarizeTicket({
ticket,
behavior: variant,
});
The exact SDK call will vary by stack. The operating model is stable:
- Use the assignment key that matches the experiment unit.
- Keep targeting attributes available for eligibility and segment analysis.
- Start with internal or beta exposure before a balanced customer split.
- Roll back by changing flag targeting, not by redeploying the application.
- Keep a cleanup plan for the temporary experiment branch.
For a first implementation walkthrough, use the FeatBit tutorial on how to experiment with AI using feature flags. For product context, FeatBit's AI control layer explains why prompts, model choices, retrieval rules, and agent behavior are runtime control surfaces.
Record Exposure Only When The AI Behavior Runs
An exposure event should mean the treatment actually had a chance to affect the user. Do not count a page view, button render, or background eligibility check as exposure if the AI behavior never ran.
At minimum, record:
- Experiment key.
- Flag key and variation.
- Assignment unit, such as user, account, ticket, conversation, or workflow.
- AI artifact identifiers, such as prompt version, model route, retrieval profile, or agent policy.
- Targeting attributes needed for segment review.
- Timestamp.
- Fallback or error state if the treatment could not run.
Then record outcome events with the same experiment key, unit ID, and variation.
{
"event": "ai_summary_exposure",
"experimentKey": "support_summary_ai_behavior",
"unitId": "ticket_98271",
"variation": "evidence_first_v2",
"promptVersion": "summary_v2",
"modelRoute": "support_summary_default",
"timestamp": "2026-06-05T09:15:30Z"
}
{
"event": "ai_summary_accepted",
"experimentKey": "support_summary_ai_behavior",
"unitId": "ticket_98271",
"variation": "evidence_first_v2",
"accepted": true,
"latencyMs": 1640,
"estimatedTokenCostUsd": 0.009
}
Joinability is more important than event volume. If exposure and outcome cannot be connected, the A/B test may produce dashboards, but it will not produce release evidence. FeatBit implementation references for this pattern include A/B testing with feature flags, targeted progressive delivery, targeting rules, percentage rollouts, and the Track Insights API.
Build A Metric Stack For AI
AI experiments need one primary metric and several guardrails. The primary metric answers whether the treatment is worth keeping. Guardrails answer whether exposure is allowed to continue.
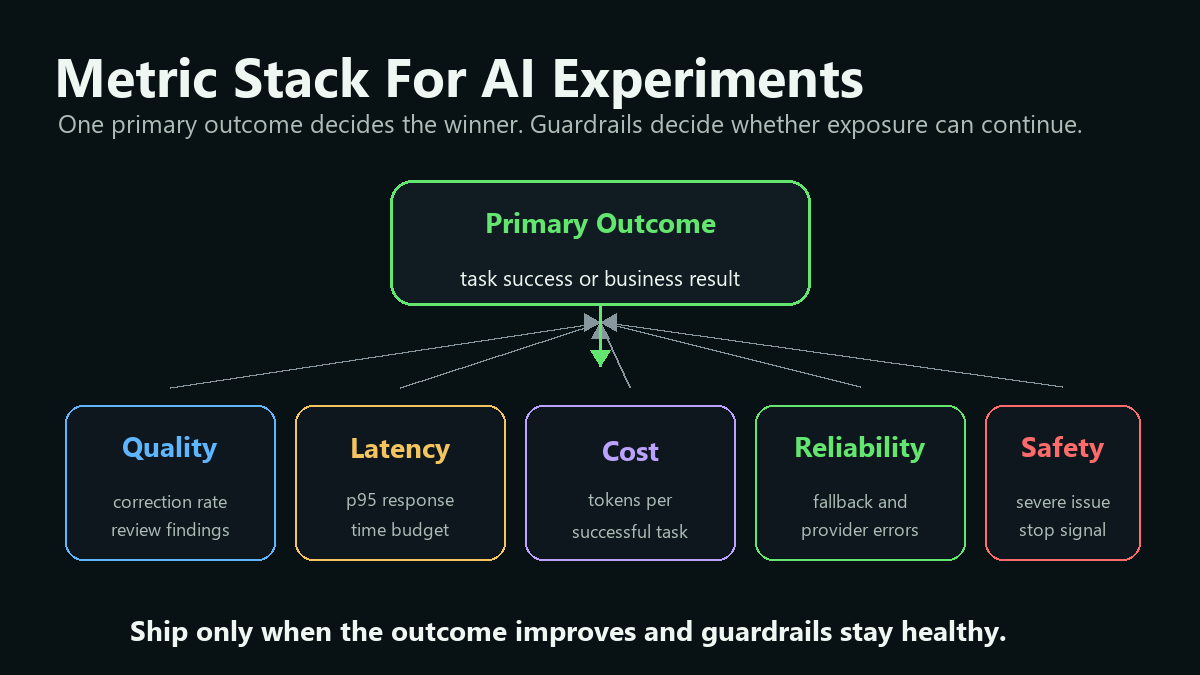
| Metric layer | Example | Decision role |
|---|---|---|
| Primary outcome | accepted summary rate, task completion, assisted conversion, successful resolution | decide whether the treatment is useful |
| Quality guardrail | human correction rate, citation error rate, hallucination report rate | pause or revise when quality regresses |
| Operational guardrail | p95 latency, provider error rate, fallback rate | roll back or narrow exposure when reliability fails |
| Cost guardrail | average token cost, cost per successful task | limit expansion when the treatment is too expensive |
| Safety or trust guardrail | severe review finding, complaint rate, unsafe action attempt | stop exposure when harm appears |
FeatBit's measurement design guidance is useful before instrumentation because it separates the metric that decides the release from the metrics that stop expansion. For AI, this distinction matters because a treatment can improve a business metric while making each answer slower, more expensive, or less trustworthy.
OpenTelemetry's semantic conventions for generative AI systems can help teams standardize traces, metrics, spans, and events around LLM calls. The OpenTelemetry page currently marks the GenAI semantic conventions as development status, so treat them as useful instrumentation context rather than a permanent schema guarantee.
Run The Test As Staged Exposure
A clean AI A/B test usually has stages. Each stage answers a different question.
| Stage | Audience | Question | Exit condition |
|---|---|---|---|
| Offline eval | representative samples and known failure cases | Is the candidate safe enough to expose? | no severe regression in reviewed examples |
| Internal exposure | employees or test accounts | Does the behavior work in the real product path? | telemetry and guardrails look healthy |
| Limited production | small eligible segment | Does anything break under real traffic? | no critical segment-level harm |
| Balanced A/B test | eligible units assigned to control or treatment | Does the candidate improve the primary outcome? | planned decision window produces readable evidence |
| Release decision | winner, rollback, or redesign | What should become permanent? | flag state, code path, and cleanup plan are updated |
Do not skip the staged path because the candidate passed an offline eval. AI failures often appear only when real users bring messy input, real context, long-tail segments, cost pressure, and downstream workflows. FeatBit's safe AI deployment and AI experimentation pages expand this release-control view.
Decide Before Looking At The Dashboard
Write the decision rule before the experiment starts:
decision_rule:
continue_when:
- primary_metric improves enough to matter
- quality guardrails remain inside threshold
- latency and cost remain acceptable
- priority segments show no meaningful harm
pause_when:
- exposure or outcome telemetry cannot be joined
- guardrail noise makes the result unreadable
- one important segment moves opposite the aggregate
rollback_when:
- severe quality or safety issue appears
- provider errors or fallback rate breach threshold
- cost or latency crosses the operating limit
learn_when:
- evidence is inconclusive but identifies a narrower follow-up test
The words "enough to matter" should become a numeric threshold inside your team. The right threshold depends on traffic, baseline performance, risk tolerance, and business value. Do not invent a universal AI A/B testing threshold.
If your team uses Bayesian interpretation, FeatBit's guide to Bayesian A/B testing for builders gives a practical decision frame. If your team uses frequentist methods, the release discipline is still the same: define the metric, window, guardrails, and action before exposure starts.
Common Mistakes
Testing too many unknowns at once. If model, prompt, retrieval, temperature, and UI all change, the result may still be useful, but it proves a bundle. Name the bundle.
Randomizing at request level when continuity matters. Conversations, tickets, accounts, and agent workflows usually need stable assignment for the whole journey.
Counting exposure too early. Exposure should mean the AI behavior ran, not that the user could have encountered it.
Optimizing only for an AI score. Judge scores, human review, and eval pass rates are useful inputs. The online A/B test should still measure the product outcome and guardrails.
Ignoring fallback behavior. If the treatment falls back to the control route under load, track that separately or the treatment may look safer than it was.
Leaving experiment code behind. After the decision, remove or reclassify the temporary flag. FeatBit's feature flag lifecycle management model helps teams keep owner, evidence, end state, and cleanup expectations attached to the release asset.
How FeatBit Fits
FeatBit is useful for AI A/B testing because AI behavior is a runtime release decision. A team can use multivariate flags to target eligible units, assign variants stickily, expand exposure gradually, record evaluation and metric events, roll back when guardrails fail, and clean up after the decision.
That does not replace offline evals, LLM observability, product analytics, human review, or incident response. It connects them. The flag controls who sees which AI behavior. Telemetry explains what happened. The metric stack tells whether the result is useful and safe. The release decision turns evidence into action.
The smallest useful next step is to choose one AI behavior, write the release hypothesis, create one reversible flag, emit one exposure event and one outcome event, and define the rollback rule before the treatment reaches customers.
FAQ
Is A/B testing AI the same as model evaluation?
No. Model evaluation usually tests behavior against datasets, examples, rubrics, or human review before production exposure. A/B testing measures whether a candidate AI behavior improves real product outcomes under controlled production exposure.
Should an AI A/B test compare prompts, models, or complete routes?
Compare the smallest unit that matches the release decision. If the business decision is "ship route v2," test route v2 as a bundle. If the decision is "promote prompt v2," keep model, retrieval, and UI stable where possible.
What should stop an AI A/B test early?
Stop or pause when severe quality issues appear, exposure and outcome telemetry cannot be joined, guardrails breach agreed limits, or an important segment shows unacceptable harm. Do not wait for the primary metric if the release is no longer safe to continue.
Source Notes
- OpenAI Evals guide: https://developers.openai.com/api/docs/guides/evals
- NIST AI Risk Management Framework: https://www.nist.gov/itl/ai-risk-management-framework
- OpenTelemetry semantic conventions for generative AI systems: https://opentelemetry.io/docs/specs/semconv/gen-ai/
- GrowthBook documentation: https://docs.growthbook.io/ is used as category context because it connects feature flagging and experimentation. It is not used as a vendor ranking.
- FeatBit implementation context: linked FeatBit pages and docs throughout this article.
Image And Open Graph Notes
- Use
/images/blogs/how-to-a-b-test-ai/cover.pngas the Open Graph image because it summarizes AI A/B testing as a controlled release decision. - Use
experiment-design.pngnear the opening because it shows the sequence from change definition to release decision while the article keeps the guidance in crawlable Markdown. - Use
metric-stack.pngin the metrics section because it reinforces the distinction between primary outcome, guardrails, and release actions.