Should AI Experiments Randomize by User or Conversation?
Most AI experiments should not default blindly to either user-level or conversation-level randomization. Randomize by user when the changed behavior must stay consistent across many sessions for the same person. Randomize by conversation when the changed behavior affects one multi-turn task and the outcome belongs to that task.
The practical rule is this: choose the assignment unit that matches the level where the user experiences continuity, the product team measures the outcome, and the release owner can roll back safely. In AI systems, that unit is often more important than the traffic split because prompts, model routes, retrieval settings, memory, and tool policies can affect several downstream turns.
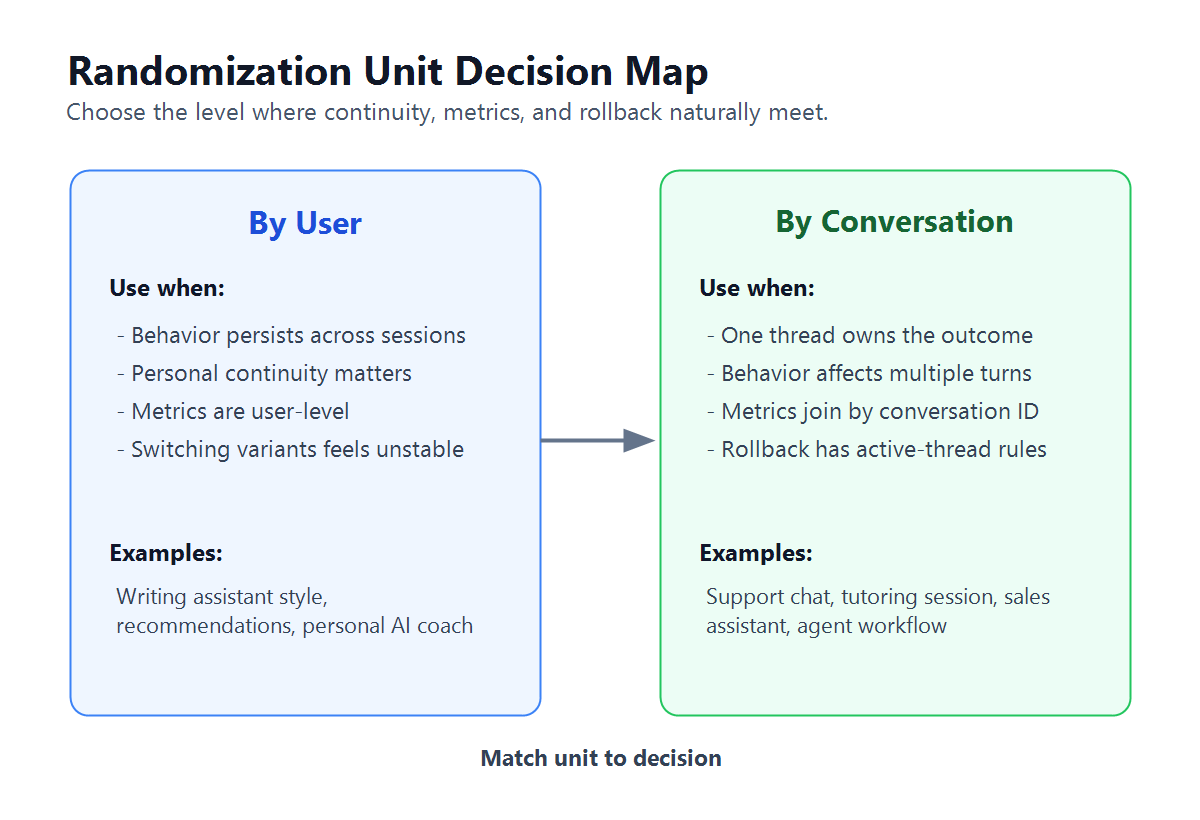
The Short Answer
Use user-level randomization when the experiment changes a durable personal experience:
- recommendation style across visits;
- a writing assistant's default behavior;
- a persistent model route for a logged-in user;
- a personal onboarding coach that remembers past steps;
- any AI behavior where switching between variants across conversations would feel incoherent.
Use conversation-level randomization when the experiment changes one bounded interaction:
- a support chat thread;
- a sales assistant conversation;
- a tutoring session;
- an agent workflow with a start and finish;
- a retrieval, prompt, or tool policy that affects a single multi-turn job.
Do not use request-level randomization for a user-facing AI experience unless each request is genuinely independent. If one conversation can see control in the first turn and treatment in the second turn, the experiment may be easier to run but harder to trust.
Why AI Experiments Make This Choice Harder
Traditional product experiments often randomize by user because the feature is visible at the user level. AI systems add more possible boundaries:
| Unit | Example | What it protects | Main risk |
|---|---|---|---|
| Request | one independent completion or ranking call | maximum sample volume | mixed behavior inside one user journey |
| Conversation | one support chat, tutor session, or agent run | continuity inside a multi-turn task | the same user may see different variants in later conversations |
| User | one person across sessions | personal consistency | unrelated tasks from the same user are grouped together |
| Account | one company, tenant, or workspace | shared B2B experience | fewer units and slower learning |
| Workflow | one business process or agent job | metric attribution to the finished job | needs reliable workflow identifiers |
AI changes often affect context. A prompt variant may change follow-up questions. A model route may change tone, latency, cost, and fallback behavior. A retrieval setting may change which sources the assistant uses later in the thread. A tool policy may change what an agent is allowed to do after it has already gathered context.
That is why the randomization unit is not just a statistics detail. It is the release-control boundary.
Choose User-Level Randomization When Continuity Belongs To The Person
User-level assignment is usually the better default when the user should experience one AI behavior across multiple sessions during the experiment window.
Good fits include:
- a coding assistant that changes its explanation style for the developer;
- a writing product that changes the default rewrite strategy;
- a recommendation assistant that should learn from prior user interactions;
- a personal productivity assistant where memory and preference carry forward;
- a consumer chatbot where variant switching across separate chats would feel like product instability.
The strongest argument for user-level randomization is consistency. If the same person receives different behavior every time they start a new session, the treatment may create confusion that is not really part of the AI quality change. User-level assignment also makes it easier to measure longer-term outcomes such as activation, retention, repeated usage, or human support contact over a period of time.
The tradeoff is that one user can perform many unrelated jobs. A developer may ask a coding assistant to debug a test, explain an API, and write documentation. If the experiment goal is tied to each task, user-level assignment can blur which behavior caused which outcome.
Choose Conversation-Level Randomization When Continuity Belongs To The Task
Conversation-level assignment is usually better when the AI behavior should stay stable inside one thread, session, case, or workflow, but does not need to follow the same user forever.
Good fits include:
- support assistants where the outcome is case resolution;
- sales assistants where the outcome is qualified handoff or booked meeting;
- tutoring sessions where the outcome is concept mastery for one lesson;
- ecommerce shopping assistants where the outcome is cart addition or checkout start;
- internal agents where the outcome is completion of one bounded workflow.
The strongest argument for conversation-level randomization is metric alignment. The exposure and outcome belong to the same unit. A support conversation either used the treatment retrieval profile or it did not. The team can then connect that exposure to resolution, escalation, latency, cost, citation quality, and complaint signals for the same conversation.
The tradeoff is cross-conversation inconsistency. A returning user may receive treatment in one conversation and control in another. That can be acceptable when each conversation is a separate job. It is less acceptable when the user expects the AI to behave like one persistent personal assistant.
A Decision Checklist
Use this checklist before starting the experiment:
| Question | Choose user when | Choose conversation when |
|---|---|---|
| Where does continuity matter most? | Across visits, sessions, or tasks for the same person | Inside one thread, case, session, or workflow |
| Where is the primary metric measured? | User activation, retention, repeat use, account journey | Conversation resolution, task completion, handoff, checkout, lesson outcome |
| Can one user perform unrelated jobs? | No, or the experiment intentionally covers all of them | Yes, and each job deserves its own assignment |
| Would variant switching across conversations confuse the user? | Yes | No, as long as each active conversation is stable |
| Does rollback need to affect active work? | Roll back future user exposures or targeted users | Route new conversations to control and decide what to do with active ones |
| Do you have a stable ID? | User ID or account ID is reliable | Conversation, thread, session, case, or workflow ID is reliable |
If the answers split evenly, choose the unit that matches the primary decision. For example, if the decision is "should this retrieval profile become the default for support cases?", conversation-level assignment is usually clearer. If the decision is "should this assistant personality become the default for this user population?", user-level assignment is usually clearer.
Align Exposure And Outcome Events
The assignment unit must appear in both exposure events and outcome events. This is where many AI experiments fail quietly: traffic is assigned at one level, but outcomes are measured at another.
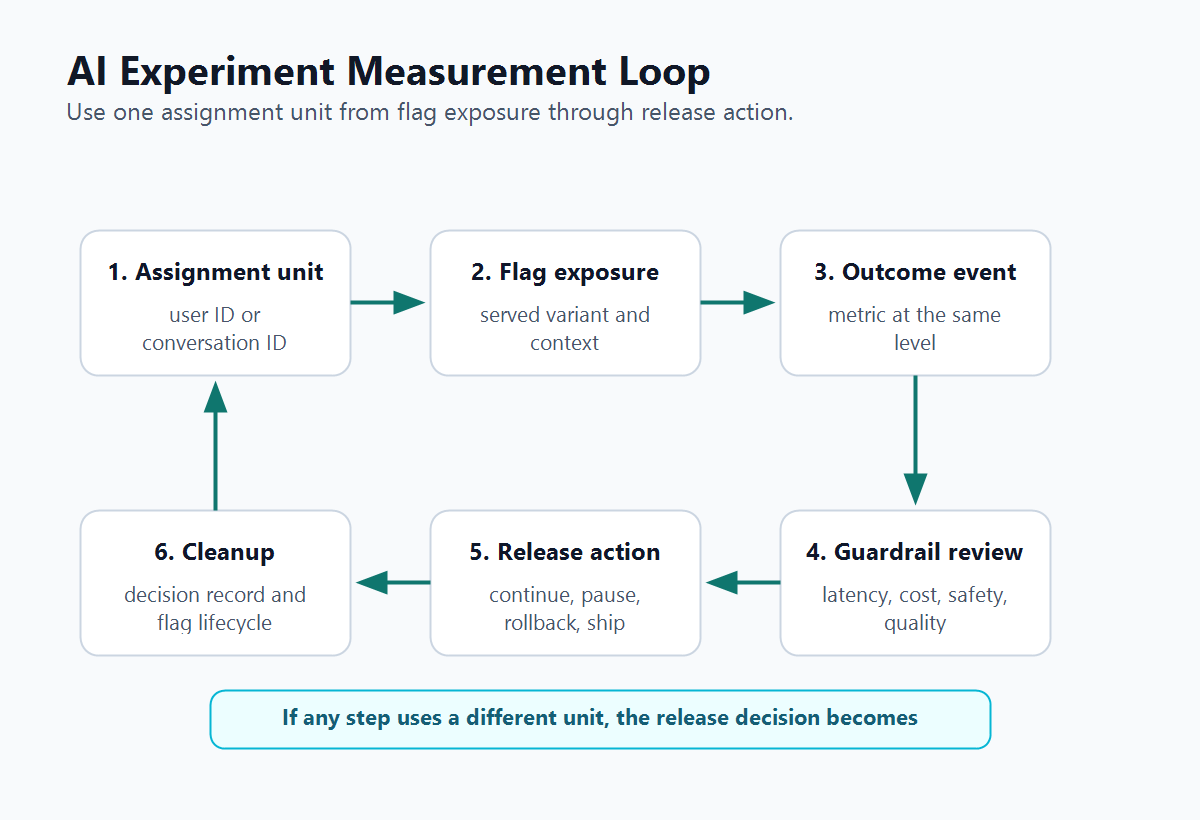
For a conversation-level support experiment, the exposure event should include the conversation ID:
{
"event": "ai_conversation_exposure",
"experimentKey": "support_retrieval_test",
"assignmentUnit": "conversation",
"conversationId": "conv_98271",
"userId": "user_142",
"accountId": "acct_1842",
"variation": "retrieval_profile_b",
"timestamp": "2026-06-05T10:15:30Z"
}
The outcome event should join back to the same conversation:
{
"event": "support_conversation_outcome",
"experimentKey": "support_retrieval_test",
"conversationId": "conv_98271",
"variation": "retrieval_profile_b",
"resolvedWithoutEscalation": true,
"humanHandoffRequested": false,
"p95LatencyMs": 1840
}
For a user-level writing assistant experiment, the same pattern applies, but the assignment unit and outcome window change:
{
"event": "ai_user_exposure",
"experimentKey": "writing_assistant_style_test",
"assignmentUnit": "user",
"userId": "user_142",
"variation": "concise_suggestions",
"timestamp": "2026-06-05T10:15:30Z"
}
The key is not the event name. The key is consistency: the flag assignment, exposure record, outcome metric, segment readout, and rollback rule should all agree about the unit being tested.
How This Looks In FeatBit
In FeatBit, the randomization choice becomes a feature flag evaluation design. The flag controls the runtime AI behavior, while the evaluation context carries the stable assignment key.
For conversation-level assignment, evaluate against the conversation or workflow ID:
type SupportAiVariant = 'control' | 'retrieval_profile_b';
async function resolveSupportAiVariant(input: {
conversationId: string;
userId: string;
accountId: string;
locale: string;
}): Promise<SupportAiVariant> {
const variation = await featbit.variation(
'support-retrieval-test',
{
key: input.conversationId,
custom: {
assignmentUnit: 'conversation',
userId: input.userId,
accountId: input.accountId,
locale: input.locale,
},
},
'control'
);
return variation as SupportAiVariant;
}
For user-level assignment, evaluate against the user ID and keep conversation ID as analysis context:
type WritingAssistantVariant = 'control' | 'concise_suggestions';
async function resolveWritingAssistantVariant(input: {
userId: string;
conversationId?: string;
accountId?: string;
}): Promise<WritingAssistantVariant> {
const variation = await featbit.variation(
'writing-assistant-style-test',
{
key: input.userId,
custom: {
assignmentUnit: 'user',
conversationId: input.conversationId,
accountId: input.accountId,
},
},
'control'
);
return variation as WritingAssistantVariant;
}
FeatBit's A/B testing with feature flags, targeting rules, percentage rollouts, and Track Insights API are the implementation primitives behind this pattern. The same runtime flag can target eligible traffic, hold stable assignment, expand gradually, and roll back without redeploying application code.
For broader release context, FeatBit's AI experimentation, safe AI deployment, and feature flag lifecycle management pages explain how controlled exposure turns AI changes into reversible release decisions.
Plan Rollback Before The Experiment Starts
The randomization unit also changes the rollback plan.
For user-level experiments, rollback usually means routing affected users back to control, reducing percentage allocation, excluding a risky segment, or disabling the treatment. That works well when the AI behavior is durable and the user can safely return to the old experience.
For conversation-level experiments, rollback needs two rules:
- What happens to new eligible conversations?
- What happens to active conversations already assigned to treatment?
For low-risk experiences, active conversations may finish on their assigned variant to preserve continuity. For higher-risk behavior, such as agent tool use, policy-sensitive support answers, or operational actions, containment matters more than experiment purity. Route new conversations to control, stop risky treatment calls, and review active treatment conversations before continuing.
This is why the experiment should not be separated from release governance. The team needs a decision rule that can produce an action: continue, pause, roll back, segment, ship, or redesign.
Common Mistakes
Randomizing by user while measuring by conversation. This can work only if the decision is truly user-level. If the primary metric is conversation resolution, the assignment should usually be conversation-level or the analysis needs a clear reason for user-level grouping.
Randomizing by conversation while measuring retention. A conversation-level treatment can affect user retention, but retention is a user-level metric. Treat it as a secondary or longer-window readout unless the experiment is designed for that level.
Changing the unit mid-experiment. Switching from user ID to conversation ID creates a new assignment process. Start a new run or clearly separate the data.
Letting fallback re-randomize the unit. Retries, provider failover, and model fallback should not silently assign a different variant. Log fallback as a guardrail event.
Forgetting account-level constraints. In B2B products, account-level consistency may matter even when the user or conversation seems like the natural unit. If one tenant needs a shared experience, consider account or workspace assignment.
Leaving temporary AI branches behind. After the experiment decision, clean up prompt branches, model routes, retrieval configs, event schemas, and temporary flags unless they become permanent operational controls.
The Bottom Line
Randomize AI experiments by user when the experience must stay consistent for the person across sessions. Randomize by conversation when the AI change belongs to a bounded multi-turn task and the outcome can be measured at that same task boundary.
The best unit is the one that lets the team make a trustworthy release decision. It keeps the user experience coherent, makes exposure and outcome events joinable, supports segment review, and gives operators a rollback path before an AI issue spreads.
Source Notes
- FeatBit implementation context: A/B testing with feature flags, targeting rules, percentage rollouts, Track Insights API, AI experimentation, safe AI deployment, and feature flag lifecycle management.
- Feature flag standard context: OpenFeature's evaluation context concept supports separating assignment identity from other targeting attributes.
- Experimentation category context: LaunchDarkly's randomization units documentation, Optimizely's bucketing documentation, and Statsig's experiments overview are used as category references for assignment units, deterministic bucketing, and experiment setup. They are not vendor rankings.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the central decision between user and conversation assignment. - Use
randomization-unit-decision-map.pngnear the opening because it helps readers compare continuity, metrics, and rollback boundaries. - Use
ai-experiment-measurement-loop.pngin the measurement section because it reinforces the join between assignment, exposure, outcomes, guardrails, and release action.