Conversation-Level Assignment for AI Feature Flags
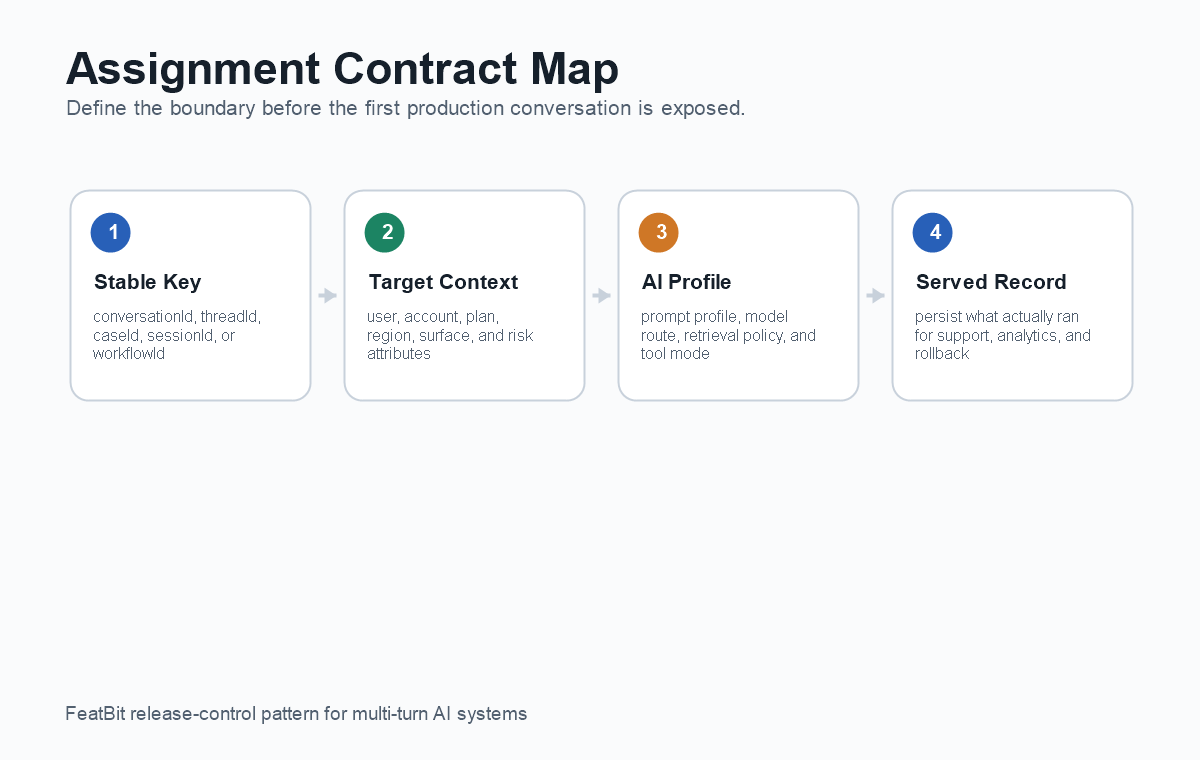
Conversation-level assignment means one AI conversation, thread, session, case, or agent run receives one stable feature flag decision for the AI behavior that affects that conversation. The flag may choose a prompt profile, model route, retrieval policy, tool mode, guardrail threshold, or experiment variant, but the assigned behavior should not change silently from turn to turn.
For AI product teams, the useful question is not only "should this experiment randomize by conversation?" It is broader: when an AI feature changes a multi-turn experience, what assignment contract keeps the user experience coherent, the evidence joinable, and the rollback path safe?
The Short Answer
Use conversation-level assignment when the AI behavior belongs to one bounded interaction:
- a support chat thread;
- a tutoring session;
- a sales assistant conversation;
- an onboarding copilot flow;
- an internal agent workflow;
- a ticket, case, or task session where earlier turns shape later turns.
Use the conversation ID, thread ID, case ID, session ID, or workflow ID as the feature flag assignment key. Keep user, account, region, plan, risk level, and surface as targeting or analysis attributes, but do not let them accidentally replace the assignment unit.
This is different from request-level assignment. Request-level assignment can work for independent backend calls. It is usually risky for multi-turn AI experiences because one conversation can receive control behavior in one turn and treatment behavior in the next.
It is also different from user-level assignment. User-level assignment is useful when the same person should receive one durable behavior across many sessions. Conversation-level assignment is useful when each conversation is the product job and the outcome belongs to that job.
What Conversation-Level Assignment Controls
In a feature flag system, "assignment" is the repeatable decision that maps an evaluation context to a variation. For AI features, that decision may control more than a visible UI change.
| Controlled surface | Conversation-level example | Why stable assignment matters |
|---|---|---|
| Prompt profile | A support assistant uses the structured troubleshooting prompt for the whole case. | Follow-up questions and summaries depend on earlier wording. |
| Model route | A conversation uses the candidate model route until the conversation ends. | Quality, latency, cost, and fallback should be attributed to one route. |
| Retrieval policy | A tutoring session uses the same retrieval depth and reranker. | Mixed retrieval policies can change context mid-task. |
| Tool mode | An agent stays in approval_required_write mode for one workflow. |
Tool authority should not escalate silently during a run. |
| Guardrail threshold | A high-risk workflow uses stricter review for the whole interaction. | Safety and review evidence need one clear policy boundary. |
| Experiment variant | A chat thread receives control or treatment for the decision window. | Exposure and outcome events can join on the same unit. |
This makes conversation-level assignment a release-control boundary. It tells engineering where to evaluate the flag, product where to measure the outcome, and operations what can be rolled back without redeploying application code.
Design The Assignment Contract
Do not let an SDK call define the assignment contract by accident. Write the contract before rollout.
flag: support_assistant_profile
assignment_unit: conversation
assignment_key: conversation_id
eligible_population:
- production
- english_support
- beta_accounts
control:
prompt_profile: support_v3
model_route: baseline
retrieval_profile: default
treatment:
prompt_profile: support_v4_structured
model_route: candidate
retrieval_profile: expanded_docs
primary_outcome: case_resolved_without_escalation
guardrails:
- p95_latency
- fallback_rate
- answer_correction_rate
- citation_failure_rate
- estimated_cost_per_resolved_case
rollback_rule: route new conversations to control and review active treatment conversations
cleanup_rule: promote one profile or remove the temporary branch after the release decision
The exact fields depend on the product, but the contract should answer five questions:
- Which stable ID owns the assignment?
- Which AI behavior surfaces can the flag change?
- Which traffic is eligible?
- Which events prove actual exposure and outcome?
- What happens to new and active conversations during rollback?
OpenFeature's evaluation context model is useful here because it separates the targeting key from other contextual attributes. For conversation-level assignment, the targeting key should represent the conversation-level subject, while custom attributes describe user, account, region, risk, or workflow context.
Evaluate Before AI Behavior Runs
The flag should be evaluated before prompt assembly, retrieval, model routing, tool selection, or guardrail enforcement. If the application evaluates after the AI behavior starts, the assignment may not represent what the user actually experienced.
type SupportAssistantProfile = {
promptProfile: 'support_v3' | 'support_v4_structured';
modelRoute: 'baseline' | 'candidate';
retrievalProfile: 'default' | 'expanded_docs';
toolMode: 'read_only' | 'approval_required_write';
};
const fallbackProfile: SupportAssistantProfile = {
promptProfile: 'support_v3',
modelRoute: 'baseline',
retrievalProfile: 'default',
toolMode: 'read_only',
};
async function resolveConversationProfile(input: {
conversationId: string;
userId: string;
accountId: string;
region: 'us' | 'eu' | 'apac';
plan: 'free' | 'pro' | 'enterprise';
riskLevel: 'low' | 'medium' | 'high';
}): Promise<SupportAssistantProfile> {
return featbit.jsonVariation(
'support_assistant_profile',
{
key: input.conversationId,
custom: {
assignmentUnit: 'conversation',
userId: input.userId,
accountId: input.accountId,
region: input.region,
plan: input.plan,
riskLevel: input.riskLevel,
},
},
fallbackProfile
);
}
The important rule is not the exact method name. The important rule is that the same assignment key appears in flag evaluation, exposure events, outcome events, and rollback review.
FeatBit's targeting rules, percentage rollouts, and user attributes support this pattern. The application passes a stable context; the flag controls which AI behavior is eligible; the service enforces the selected behavior.
Persist The Served Assignment
Flag evaluation gives the runtime decision. The product should also persist what was actually served.
That persisted record can live on the conversation, case, task, or workflow record:
{
"conversationId": "conv_98271",
"flagKey": "support_assistant_profile",
"assignmentUnit": "conversation",
"variation": "structured_support_candidate",
"promptProfile": "support_v4_structured",
"modelRoute": "candidate",
"retrievalProfile": "expanded_docs",
"assignedAt": "2026-06-20T09:12:44Z"
}
Persisting the served assignment helps with three operational jobs:
- Support and engineering can inspect which behavior a user actually received.
- Analytics can join outcomes to the same conversation even if later flag settings change.
- Rollback tooling can distinguish new conversations from active conversations already exposed to the candidate behavior.
This does not mean every future turn must ignore flag changes. It means changes should follow an explicit boundary. A low-risk assistant may finish active conversations on the assigned variation. A high-risk agent may need immediate containment if a guardrail fails.
Connect Assignment To Exposure And Metrics
Conversation-level assignment is only useful if exposure and outcome data use the same key.

Record exposure when the assigned AI behavior is actually used, not merely when the flag is read:
{
"event": "ai_conversation_exposed",
"flagKey": "support_assistant_profile",
"assignmentUnit": "conversation",
"conversationId": "conv_98271",
"userId": "user_142",
"accountId": "acct_1842",
"variation": "structured_support_candidate",
"promptProfile": "support_v4_structured",
"modelRoute": "candidate",
"retrievalProfile": "expanded_docs",
"timestamp": "2026-06-20T09:13:02Z"
}
Then record outcomes and guardrails with the same conversation ID:
{
"event": "support_conversation_outcome",
"flagKey": "support_assistant_profile",
"conversationId": "conv_98271",
"variation": "structured_support_candidate",
"resolvedWithoutEscalation": true,
"fallbackUsed": false,
"answerCorrectionRate": 0.0,
"p95LatencyMs": 1830,
"citationFailure": false
}
FeatBit's Track Insights API can report feature flag usage and custom metric events. For AI features, the event design should also connect to observability data. OpenTelemetry's generative AI semantic conventions provide category context for structured AI telemetry such as model, request, response, token, and conversation attributes.
Plan Rollout And Rollback For Active Conversations
Conversation-level assignment makes one rollout question unavoidable: what happens to conversations that are already in progress when the flag changes?

Use a simple decision table before launch:
| State | New conversations | Active conversations | Why |
|---|---|---|---|
| Internal preview | target employees or test accounts | finish on assigned behavior | validate wiring before customer exposure |
| Limited rollout | assign a small eligible percentage | keep stable unless a guardrail fails | preserve user continuity and readable evidence |
| Pause for missing telemetry | route new conversations to control | keep low-risk active conversations stable or stop candidate calls | avoid adding unreadable exposure |
| Rollback for severe issue | route new conversations to control | move risky active conversations to the safest recoverable path | containment matters more than clean analysis |
| Ship candidate | make the winning profile default for new conversations | migrate at the next natural boundary or finish stable | avoid mid-conversation surprises |
| Clean up | remove temporary branches | keep historical decision records | prevent AI release controls from becoming stale debt |
For traditional UI flags, changing the flag may update the next page load. For AI conversations, a mid-thread change can alter tone, context, retrieval, tool access, or safety behavior in a way the user cannot understand. That is why the rollout rule should distinguish new conversations from active conversations.
Where FeatBit Fits
FeatBit is useful for conversation-level assignment because it provides the runtime control plane around the AI behavior:
- evaluate a feature flag against a stable conversation, thread, case, or workflow key;
- target internal users, beta accounts, regions, plans, risk classes, or percentages;
- keep AI behavior stable across a multi-turn interaction;
- record flag evaluations and custom metric events for release evidence;
- reduce exposure or roll back without redeploying application code;
- use audit history and lifecycle ownership to clean up temporary controls.
This does not replace the model gateway, authorization layer, prompt registry, observability system, product analytics, or human review. FeatBit should control the release decision: who sees which AI behavior, under which conditions, with what rollback path.
For the broader operating model, see FeatBit's AI control layer, safe AI deployment, AI experimentation, and feature flag lifecycle management pages.
Common Mistakes
Using request IDs as the assignment key for a chat experience. This may increase apparent sample size, but it can mix behavior inside one conversation and make outcomes hard to attribute.
Calling everything a user assignment. User-level assignment is not wrong, but it is too broad when one user can run many unrelated tasks that need separate evidence.
Changing active conversations without a boundary. A flag update should not silently switch prompt, model, retrieval, or tool behavior halfway through a high-context interaction.
Logging intended assignment instead of actual exposure. If the treatment route falls back before producing an answer, record the fallback. The exposure should describe what actually served the user.
Putting sensitive conversation text in the flag context. Pass stable identifiers and derived attributes such as workflow, risk level, or region. Keep raw messages, documents, and secrets in systems designed for that data.
Forgetting cleanup. After the rollout decision, remove losing prompt branches, obsolete model routes, temporary metric names, and stale flags unless the control intentionally becomes permanent.
Starting Checklist
Before using conversation-level assignment for an AI feature flag, confirm:
- The AI behavior affects a multi-turn conversation, thread, case, session, or workflow.
- The assignment key is stable and available before AI behavior runs.
- The flag is evaluated server-side or edge-side when the control affects sensitive AI behavior.
- User, account, plan, region, surface, and risk attributes are available for targeting and analysis.
- The served assignment is persisted or otherwise reconstructable.
- Exposure events are emitted only when the assigned behavior actually runs.
- Outcome and guardrail events use the same assignment key.
- New-conversation and active-conversation rollback rules are written before exposure.
- Segment review is planned for priority accounts, regions, plans, workflows, or risk classes.
- The flag has an owner, decision date, and cleanup rule.
The bottom line: conversation-level assignment is the contract that keeps AI feature flags stable across multi-turn behavior. Use it when the conversation is the unit the user experiences, the unit the team measures, and the unit operators need to contain when a rollout goes wrong.
Source Notes
- FeatBit implementation context: targeting rules, percentage rollouts, user attributes, Track Insights API, AI control layer, safe AI deployment, AI experimentation, and feature flag lifecycle management.
- Feature flag standard context: OpenFeature's evaluation context specification supports the distinction between assignment identity and targeting attributes.
- Experimentation and vendor category context: GrowthBook's feature flag documentation and AI software page are cited for public category context around flags, experiments, model comparisons, and metrics. LaunchDarkly's randomization units documentation is cited for the broader experimentation concept of assigning by a stable unit. These sources are not used as vendor rankings.
- Observability context: OpenTelemetry's generative AI semantic conventions support the recommendation to keep AI telemetry structured and joinable with release-control evidence.
- Related FeatBit reading: conversation-level randomization for AI experiments, thread-level randomization for chatbot experiments, what targeting dimensions should AI features use, and conversation analytics for AI products.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes conversation-level assignment as a runtime control boundary for AI feature flags. - Use
assignment-contract-map.pngnear the opening because it shows the stable assignment contract before the implementation details. - Use
conversation-evidence-loop.pngin the measurement section because it connects assignment, actual exposure, outcomes, guardrails, and rollout action. - Use
active-conversation-rollout.pngin the rollback section because it highlights the operational distinction between new and active conversations.