Conversation-Level Randomization for AI Experiments
Conversation-level randomization means assigning an entire chat, support thread, tutoring session, agent workflow, or other multi-turn AI interaction to one experiment variation for the full decision window. The point is simple: if the user starts a conversation with one AI behavior, the experiment should not quietly switch prompts, models, retrieval settings, or tool policy halfway through the same journey.
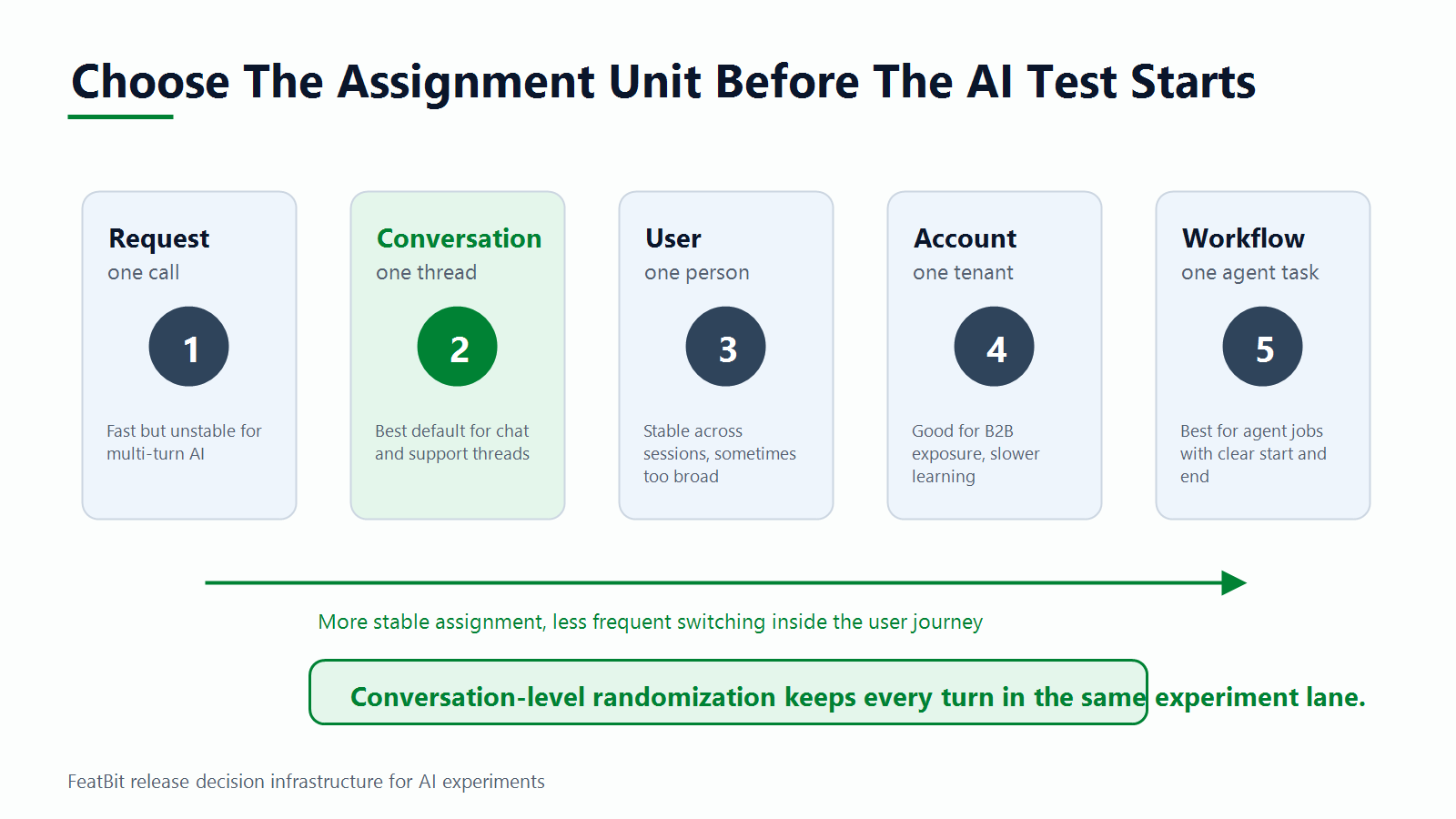
That makes this a narrower question than "how do we A/B test AI models?" The reader job is to choose the right assignment unit when the AI experience unfolds across turns. Conversation-level randomization is useful when continuity affects quality, user trust, metric attribution, or rollback. It is risky when conversations are hard to identify, too sparse for useful measurement, or reused across unrelated jobs.
Why The Randomization Unit Matters
AI experiments often change behavior that users experience over time:
- a support assistant's answer style;
- the model route behind a chatbot;
- the retrieval profile used across a troubleshooting thread;
- an agent's tool policy inside a workflow;
- a prompt bundle that affects follow-up questions.
If those changes are randomized per request, one conversation can receive control behavior in turn one, treatment behavior in turn two, and fallback behavior in turn three. That may look mathematically convenient, but it can damage the product experience and make the result hard to interpret. The outcome belongs to the conversation, yet the exposure keeps changing underneath it.
Conversation-level randomization fixes that by making the conversation ID the stable assignment key. Every eligible call inside the same conversation evaluates to the same variation unless the team intentionally rolls back or excludes the conversation.
When Conversation-Level Assignment Is The Right Default
Use conversation-level randomization when the treatment can change a multi-turn experience. That includes chat, voice, tutoring, support, sales assistance, onboarding copilots, and agent workflows where earlier turns influence later turns.
| Randomization unit | Use when | Avoid when |
|---|---|---|
| Request | each request is independent and users cannot perceive cross-request inconsistency | context carries across turns or outcome is session-based |
| Conversation | the user journey has a clear thread, session, or workflow ID | conversations are too short, too sparse, or reused across unrelated jobs |
| User | personal continuity matters across many sessions | one user performs very different task types that need separate analysis |
| Account | B2B exposure should be consistent across a team or tenant | account count is too small for the decision window |
| Workflow | an agent task has a clear start, end, and outcome event | workflow IDs are not reliable enough to join events |
For many AI products, conversation-level assignment is the practical middle ground. It is more stable than request-level assignment and less coarse than user or account assignment. A returning user can enter a new experiment variation in a later conversation, but each active conversation remains internally consistent.
A Concrete Example
Imagine a support chat team wants to test a new retrieval profile for troubleshooting answers.
The experiment should not ask, "Does retrieval profile B look better in a few examples?" It should ask:
release_hypothesis:
decision: should support chat use retrieval_profile_b by default?
population: eligible English support conversations
assignment_unit: conversation_id
control: current_retrieval_profile
treatment: retrieval_profile_b
primary_metric: conversation_resolved_without_human_escalation
guardrails:
- p95_latency
- answer_correction_rate
- citation_failure_rate
- fallback_rate
rollback: route new conversations to control and review active treatment conversations
The treatment affects more than one answer. A better retrieval profile may help early diagnosis, follow-up clarification, and final resolution. If the experiment randomizes every LLM call independently, the team cannot cleanly explain whether the conversation outcome came from the control profile, the treatment profile, or a mix.
With conversation-level assignment, the release owner can say: this conversation was exposed to the treatment retrieval profile, these outcomes followed, and these guardrails stayed healthy or failed.
Implement It With A Feature Flag Assignment Key
In FeatBit terms, the flag controls the runtime AI behavior and the evaluation context carries the assignment key. For a conversation-level experiment, evaluate the flag against the conversation or workflow identity that should remain stable.
type AiExperimentVariant = "control" | "retrieval_profile_b";
async function resolveSupportAiVariant(input: {
conversationId: string;
userId: string;
accountId: string;
locale: string;
}): Promise<AiExperimentVariant> {
const variation = await featbit.variation("support-ai-retrieval-test", {
key: input.conversationId,
custom: {
userId: input.userId,
accountId: input.accountId,
locale: input.locale,
},
}, "control");
return variation as AiExperimentVariant;
}
The exact SDK shape depends on your application, but the design rule is stable: the key should represent the assignment unit. Attributes such as user, account, locale, plan, region, risk class, or workflow type can still be used for targeting and analysis.
OpenFeature describes evaluation context as the contextual data used during flag evaluation. That concept is especially important for AI experiments because the context should include the unit you are assigning, not just the user who clicked a button.
Track Exposure And Outcome At The Same Level
The assignment unit must appear in both exposure events and outcome events. Otherwise the experiment can control traffic correctly but fail at analysis.
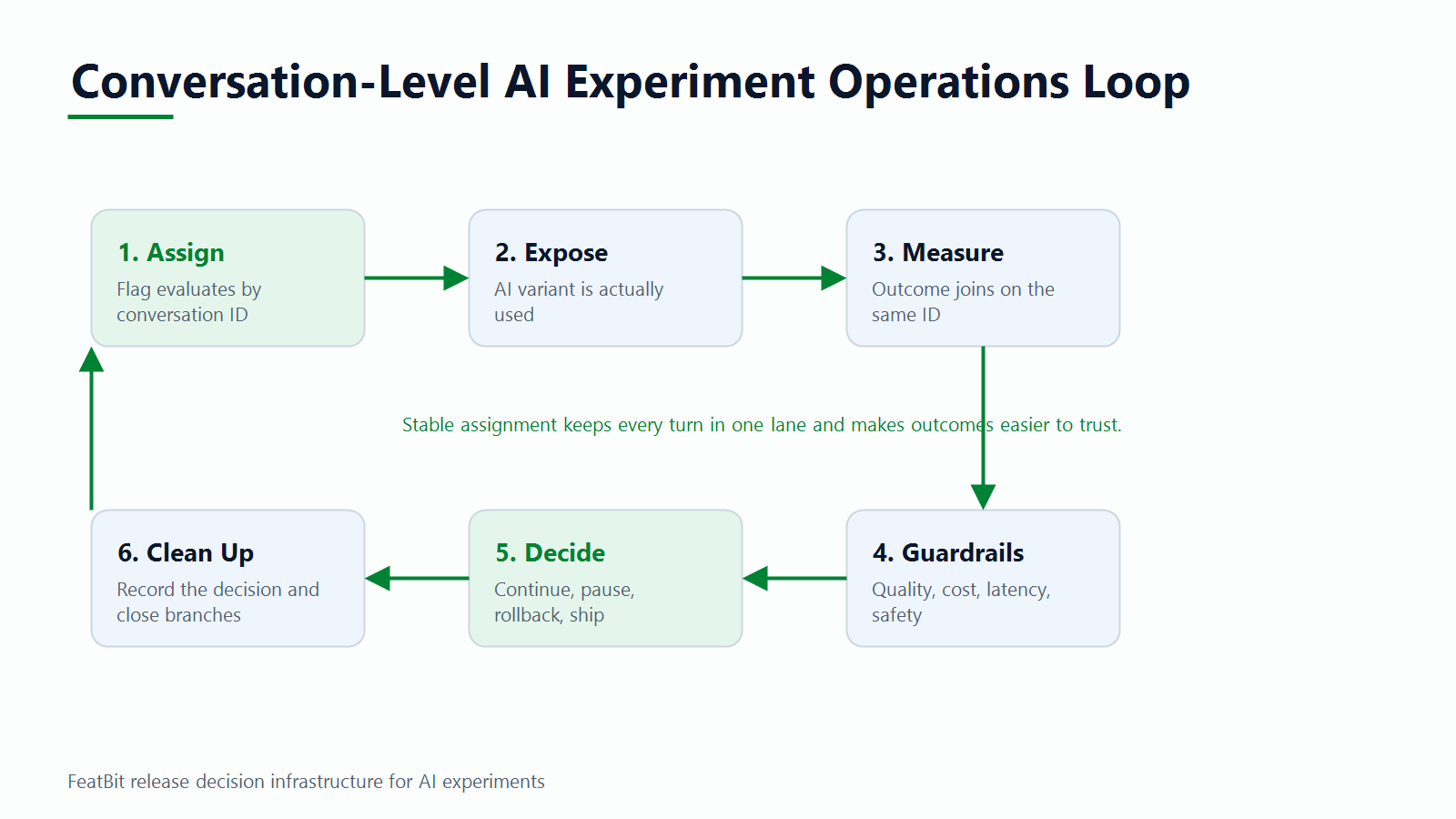
At minimum, record:
- experiment key;
- flag key and variation;
- conversation ID or workflow ID;
- user and account identifiers when available;
- AI surface changed, such as prompt, model route, retrieval profile, or tool policy;
- exposure timestamp when the assigned behavior is actually used;
- primary outcome event tied to the same conversation;
- guardrail signals for latency, cost, fallback, safety review, correction, escalation, or complaint.
{
"event": "ai_conversation_exposure",
"experimentKey": "support-ai-retrieval-test",
"conversationId": "conv_98271",
"userId": "user_142",
"accountId": "acct_1842",
"variation": "retrieval_profile_b",
"surface": "retrieval",
"timestamp": "2026-06-02T10:15:30Z"
}
{
"event": "support_conversation_resolved",
"experimentKey": "support-ai-retrieval-test",
"conversationId": "conv_98271",
"variation": "retrieval_profile_b",
"resolvedWithoutEscalation": true,
"latencyP95Ms": 1840,
"citationFailure": false
}
OpenTelemetry's semantic conventions for generative AI systems include fields such as conversation identifiers, request identifiers, operation names, model names, token counts, and response attributes. You do not need every attribute on day one, but you do need a consistent way to join the AI call, flag variation, conversation, and product outcome.
Decide How To Handle Active Conversations
Conversation-level randomization creates one operational question that request-level randomization can hide: what happens to active conversations when the experiment pauses, rolls back, or ships?
Write the rule before exposure starts.
| Decision state | New conversations | Active conversations | Reason |
|---|---|---|---|
| Continue | keep planned allocation | keep assigned variation | preserve experiment integrity |
| Pause for telemetry gap | route new conversations to control | keep active low-risk conversations stable or freeze treatment calls | avoid adding unreadable exposure |
| Rollback for severe guardrail breach | route new conversations to control | move active treatment conversations to the safest recoverable path | limit harm over statistical purity |
| Ship treatment | route new conversations to treatment | finish current conversations on assigned variation or migrate at next natural boundary | avoid mid-thread inconsistency |
| Inconclusive | keep control as default | close out active conversations, then clean up or redesign | avoid permanent experiment drift |
The right active-conversation rule depends on risk. For a low-risk onboarding assistant, finishing active conversations on the assigned variation may be acceptable. For an agent that can trigger operational side effects, a guardrail breach should prioritize rollback and human review over maintaining a clean experiment.
This is why FeatBit treats AI experimentation as release-decision infrastructure, not just analytics. A feature flag gives the operator a way to target, pause, reduce exposure, or roll back without redeploying the application.
Avoid Common Design Mistakes
Using request-level randomization for multi-turn behavior. This is the core failure mode. If the treatment changes context, reasoning, style, retrieval, memory, or tool access inside a thread, request-level assignment can contaminate both user experience and measurement.
Using user-level assignment when the conversation is the real job. User-level assignment is useful for personal continuity, but it can be too coarse when one user runs unrelated conversations. A developer using a coding assistant for a refactor, bug fix, and documentation update may need conversation or workflow IDs for clean analysis.
Changing the randomization unit after launch. If the team starts with conversation ID and later switches to user ID, early and later exposure are not comparable. Start a new experiment or clearly mark a new run.
Forgetting segment-level readouts. Conversation-level randomization does not remove the need to inspect account, locale, plan, workflow type, or risk class. A treatment can help short support chats and harm long technical threads.
Cleaning up only the analytics object. The flag, prompt branch, retrieval profile, event schema, and decision record all need an end state. If the treatment becomes default, remove temporary branches unless the flag is intentionally becoming a permanent operational control. FeatBit's feature flag lifecycle management guidance helps teams close that loop.
How FeatBit Fits The Workflow
FeatBit is a good fit when conversation-level randomization is part of a broader release-control practice. A team can use a multivariate flag to assign conversations to AI variants, target eligible segments, expand exposure gradually, track flag evaluations and metric events, and roll back when guardrails fail.
That does not mean the feature flag platform replaces offline evals, LLM observability, product analytics, or human review. It connects them. Offline evals qualify the candidate. Observability explains model behavior. Product analytics measures outcomes. The flag controls who sees which behavior. The release decision tells the team whether to continue, pause, roll back, ship, or redesign the experiment.
For implementation context, start with FeatBit's docs for A/B testing with feature flags, targeted progressive delivery, targeting rules, percentage rollouts, and the Track Insights API. For the broader AI release context, see FeatBit's AI experimentation, measurement design, and Bayesian A/B testing for builders pages.
Setup Checklist
Before running a conversation-level AI experiment, confirm:
- The AI behavior affects a multi-turn conversation, session, or workflow.
- The assignment unit is named before exposure starts.
- The flag evaluates against conversation ID, workflow ID, or another stable unit.
- Targeting attributes still include user, account, locale, region, plan, and risk class when relevant.
- Exposure events are emitted only when the assigned AI behavior is actually used.
- Outcome events can be joined to exposure by the same conversation or workflow ID.
- The primary metric and guardrails are written before launch.
- Active-conversation rollback rules are explicit.
- Segment readouts are part of the decision.
- The flag and temporary AI branches have a cleanup path after the decision.
The bottom line: conversation-level randomization is not a statistics detail. It is the control boundary that keeps multi-turn AI experiments understandable, reversible, and useful for product decisions.
Source Notes
- FeatBit implementation context: A/B testing with feature flags, targeted progressive delivery, targeting rules, percentage rollouts, Track Insights API, AI experimentation, measurement design, Bayesian A/B testing for builders, and feature flag lifecycle management.
- Feature flag standard context: OpenFeature's evaluation context concept supports the article's distinction between assignment identity and targeting attributes.
- Observability context: OpenTelemetry's semantic conventions for generative AI systems support the recommendation to connect AI telemetry with conversation, request, model, and outcome metadata.
- Experimentation category context: GrowthBook's feature flag documentation, Statsig's feature gates versus experiments guide, Optimizely's metrics documentation, and LaunchDarkly's experiment flags documentation are useful category references for connecting flag assignment, variations, and metrics. They are not used as vendor rankings.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes conversation-level assignment, AI variants, guardrails, and release decision flow. - Use
randomization-unit-map.pngnear the opening because it helps readers compare request, conversation, user, account, and workflow assignment without hiding the main criteria outside crawlable text. - Use
experiment-operations-loop.pngin the tracking section because it reinforces the operational loop from exposure to outcome, guardrail review, decision, and cleanup.