AgentControl Evaluation Guide for AI Agent Runtime Control
If you searched for AgentControl, you are probably trying to understand LaunchDarkly's AI agent control product, compare it with your existing release stack, or decide whether agent behavior should be managed inside a feature management platform.
The useful evaluation question is not just "Can this tool change prompts without a deploy?" The stronger question is: can this runtime control layer help your team manage AI agent behavior with targeted rollout, evidence, rollback, auditability, lifecycle ownership, and the right deployment model for your data and operations?
This guide treats AgentControl as a vendor-specific term and turns it into a vendor-neutral evaluation checklist. For a broader implementation pattern, read FeatBit's guide to controlling AI agents in production with feature flags. This article is narrower: it is for teams evaluating an AgentControl-style product category and deciding what to compare before standardizing on it.
What AgentControl Means in LaunchDarkly's Docs
LaunchDarkly's public AgentControl documentation describes an AgentControl config as a resource for managing how an application uses large language models. The documented scope includes prompts, instructions, model settings, variations, targeting rules, monitoring, experimentation, and lifecycle management.
The same docs distinguish completion mode from agent mode. Completion mode is for single-step model responses with messages and roles. Agent mode is for structured, multi-step workflows. LaunchDarkly also states that tool usage depends on the application and SDK implementation, not only on the selected configuration mode.
That distinction matters for buyers. A runtime AI control product can manage configuration and targeting, but the application still owns execution boundaries. LaunchDarkly's docs also state that LaunchDarkly does not invoke model providers on behalf of the application. The application calls the model provider directly with its own credentials and uses returned configuration from the AI SDK.
So the first evaluation frame is clear: AgentControl is not just prompt storage. It is a runtime configuration and release-control layer for AI behavior. But it still has to be evaluated beside your application architecture, model-provider integration, authorization layer, tool router, observability stack, and data-governance requirements.
The Evaluation Question Is Bigger Than Prompt Management
Many teams start with prompt and model configuration because those are visible. Production agent control usually breaks in less visible places:
- an agent receives a new tool before the approval policy is ready;
- a model change works for internal users but fails for one customer segment;
- a retrieval profile crosses a data-boundary assumption;
- an evaluator score exists, but operators do not know which rollout decision it should trigger;
- rollback turns off the whole agent because the team cannot disable one risky capability;
- audit logs show that a config changed, but not why the release decision changed.
An AgentControl-style product should therefore be evaluated as a production operating layer, not only as a generative AI configuration UI.
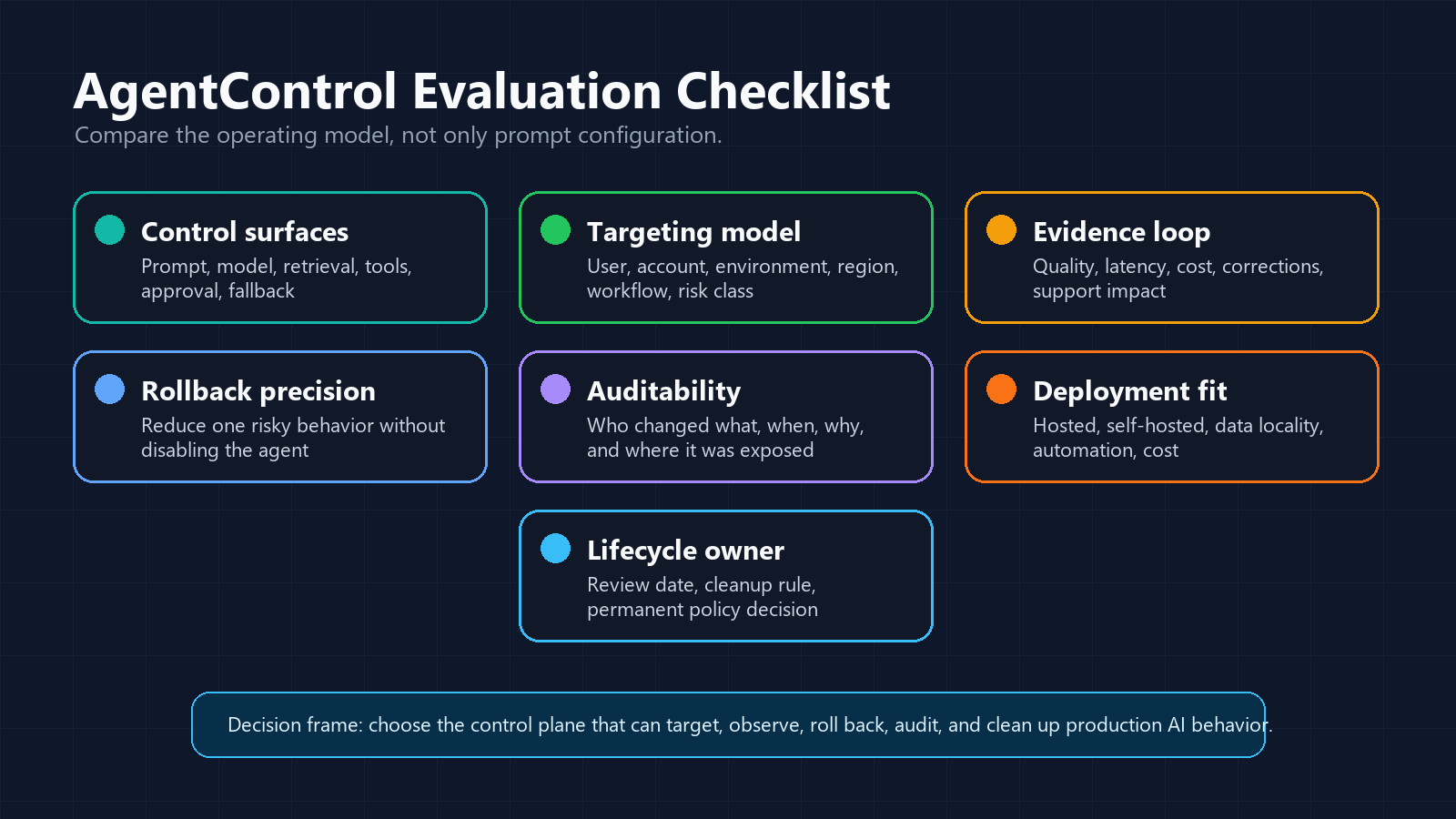
| Evaluation area | What to ask |
|---|---|
| Control surfaces | Can the system manage prompts, models, retrieval, tools, approval, fallback, and incident state as separate decisions? |
| Targeting model | Can rollout vary by user, account, environment, region, workflow, agent, and risk class? |
| Evidence loop | Can operators connect evaluated variations to quality, latency, cost, errors, user feedback, and experiment outcomes? |
| Rollback precision | Can the team reduce one capability, prompt profile, model profile, or tool tier without disabling unrelated behavior? |
| Auditability | Does the system show who changed the control state, what changed, and which production contexts were affected? |
| Deployment model | Does the control plane fit your data-residency, private infrastructure, cost, and operations requirements? |
| Lifecycle ownership | Can temporary rollout controls become clean decisions instead of permanent policy debt? |
This is where FeatBit's point of view differs from a narrow "AI prompt management" frame. Feature flags are release-decision infrastructure. For AI agents, the release decision may involve prompt choice, model routing, retrieval profile, tool authority, approval mode, rollout segment, experiment exposure, or rollback state.
A Practical Runtime Control Map
Use the map below when comparing AgentControl, FeatBit, or any AI agent runtime-control layer.
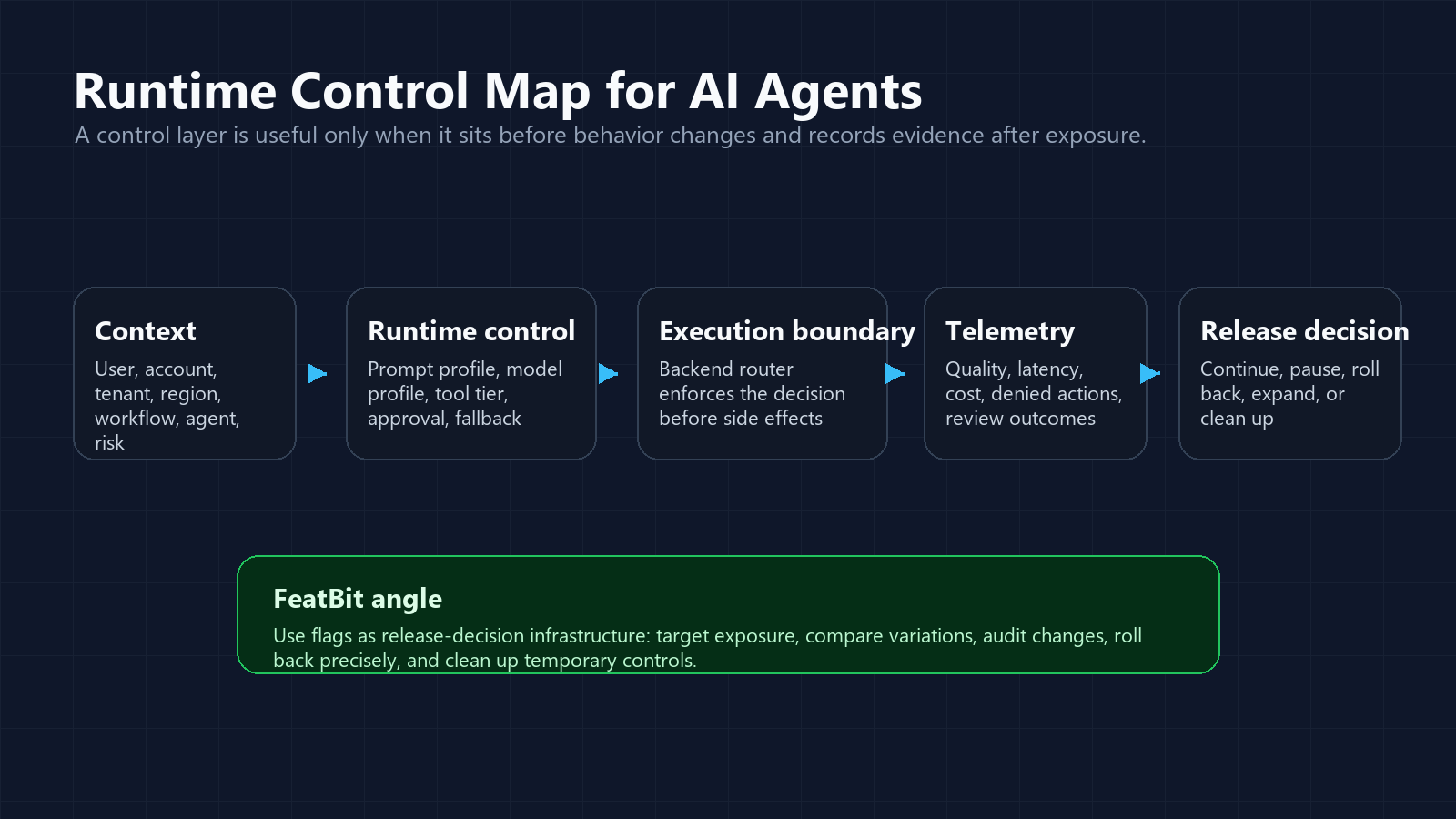
The important boundary is the moment before production behavior changes. A model can propose an answer or action. The production system should still decide which configuration is active, which tools are available, which approval rule applies, and what evidence is recorded.
For an agent workflow, that usually means:
- Build a structured context for the session, including user, account, environment, region, workflow, agent ID, and risk class.
- Evaluate runtime controls server-side before the agent assembles prompts, selects models, retrieves context, or calls tools.
- Pass the evaluated decision to the agent or orchestration layer.
- Enforce tool and approval decisions at the execution boundary, not only in the prompt.
- Attach evaluated variations to telemetry, audit events, metric events, and review records.
- Continue, pause, roll back, or clean up based on evidence.
That pattern keeps the control layer useful even if the model, framework, or tool router changes later.
How FeatBit Fits the Same Category
FeatBit is not LaunchDarkly AgentControl, and this article does not claim feature parity with a vendor add-on. FeatBit's relevant angle is release control: using feature flags, targeting, experimentation, audit, observability integrations, and self-hosted infrastructure to manage runtime behavior in production.
For AI agents, FeatBit can be used to control:
- whether an agent workflow is enabled for a given user, account, environment, or segment;
- which prompt, model, retrieval, or strategy profile is active;
- whether the agent runs in
off,observe,search_only,draft_write,approval_required, orfallbackmode; - which tool tier is active for a workflow or risk class;
- which percentage or customer segment receives a new capability;
- which rollback state should take effect during an incident;
- who changed a flag and when, through audit logs and operational integrations.
FeatBit's AI control layer, AI agent deployment loop, and feature flag lifecycle management pages explain the broader release-control model. The docs for targeting rules, percentage rollouts, flag insights, audit logs, and OpenTelemetry integration are the implementation primitives behind that model.
The deployment question is often decisive. If your agent control plane touches sensitive customer behavior, internal policy, or regulated operational workflows, an open-source and self-hosted feature flag platform may be part of the evaluation, not an afterthought.
AgentControl Evaluation Matrix
Use this matrix to compare options without reducing the decision to a feature list.
| Buyer question | Why it matters | FeatBit evaluation angle |
|---|---|---|
| What is the controlled unit? | Prompt, model, retrieval, tool, approval, and fallback decisions have different owners and rollback needs. | Model each risky runtime decision as a named flag or policy mode, not one global agent switch. |
| Where is enforcement? | A prompt instruction is not the same as a server-side boundary before a side effect. | Evaluate flags before orchestration and enforce tool decisions in the backend or tool router. |
| What context is targetable? | AI agent behavior often needs account, tenant, workflow, region, and environment targeting. | Use structured evaluation context and segments for controlled exposure. |
| What evidence supports expansion? | Rollout should depend on quality, latency, cost, corrections, support impact, and errors. | Connect flag variations to insights, metrics, traces, and experiment events. |
| How precise is rollback? | Operators need to reduce one risky behavior without disabling unrelated capabilities. | Use separate controls for mode, tool tier, prompt profile, model profile, approval, and incident state. |
| Who owns cleanup? | Temporary controls become technical and policy debt if no one decides their end state. | Use lifecycle ownership, review windows, and cleanup expectations. |
| Where does the control plane run? | Some teams need private deployment, data locality, or predictable infrastructure ownership. | Evaluate FeatBit self-hosting, open source, API access, MCP, CLI, and automation options. |
The matrix intentionally separates release control from hard security. Runtime flags can decide which approved capability is active. They should not be the only thing preventing an agent from reaching forbidden data, bypassing authorization, or executing irreversible actions.
When FeatBit Is Worth Evaluating Alongside AgentControl
FeatBit is especially relevant when the buying question is not only "Which vendor has an AI agent control page?" but "Which control plane should our team operate for production release decisions?"
Evaluate FeatBit when:
- you want feature flags, experimentation, rollout, rollback, and lifecycle management in one release-control layer;
- self-hosting, open source, private infrastructure, or data-location control matters;
- platform teams need automation through REST APIs, webhooks, CLI, MCP, or agent skills;
- AI agent controls should share the same governance model as ordinary product releases;
- cost predictability and infrastructure ownership are part of the vendor decision;
- temporary AI rollout controls need cleanup rules so agent policy does not become code debt.
Evaluate a managed vendor add-on when:
- your organization already standardizes on that vendor's platform;
- your team wants a hosted AI-specific configuration workflow before building platform abstractions;
- your primary need is prompt and model configuration management inside the existing vendor account;
- your data, governance, and cost model fit the vendor's managed service boundaries.
Those are operating-model choices, not moral choices. The mistake is pretending the choice is only about an AI feature checklist.
Pitfalls to Avoid in Any AgentControl Decision
Treating prompt control as full agent control. Prompt and model updates are important, but production agents also need tool authority, retrieval boundaries, approval policy, rollback, and evidence.
Skipping the execution boundary. The model can receive the selected policy, but the backend or tool router should enforce decisions before side effects run.
Using one global AI switch. A kill switch is useful during an incident. Normal operations need narrower controls for prompt profile, model profile, tool tier, approval, and fallback.
Measuring only model metrics. Token usage, latency, and generation count are useful. Agent release decisions also need quality review, correction rate, denied-action rate, support impact, business metrics, and rollback events.
Ignoring data ownership until procurement. The control plane may store prompts, config metadata, evaluation events, audit history, or operational policy. Decide early whether that belongs in a hosted vendor system, a self-hosted platform, or a hybrid model.
Leaving temporary controls forever. AI teams change prompts, models, retrieval sources, and tool authority quickly. Every temporary rollout control needs an owner and cleanup condition.
Starting Checklist
Before choosing an AgentControl-style platform, answer these questions with your platform, security, product, and operations teams:
- Which AI agent workflows are close enough to production to need runtime control?
- Which control surfaces must change after deployment: prompt, model, retrieval, tools, approval, rollout, experiment, or fallback?
- Which contexts must be targetable: user, account, tenant, plan, environment, region, workflow, agent ID, or risk class?
- Which hard boundaries remain outside the control plane: IAM, API authorization, sandboxing, secrets, irreversible actions, and data policy?
- What evidence decides continue, pause, rollback, or cleanup?
- Who can change production AI behavior, and how is that change audited?
- Does the control plane need to run in your infrastructure?
- What happens to each temporary flag, config, or policy after the release decision is complete?
The best AgentControl evaluation is not a vendor feature inventory. It is a release-control design review. If the system can target the right audience, change behavior safely, collect the right evidence, roll back precisely, and leave a clean lifecycle trail, it can become part of your AI production operating model.
Source Notes and Internal Link Plan
This article uses LaunchDarkly sources as vendor and category context. It does not make comparative performance, pricing, security, compliance, or market-ranking claims.
- LaunchDarkly's AgentControl documentation is used for the public description of configs, completion mode, agent mode, targeting, monitoring, experiments, and the statement that applications call model providers directly.
- LaunchDarkly's Agent graphs documentation is used for the distinction between graph representation and application-side execution.
- LaunchDarkly's Online evaluations documentation and Judges documentation are used as category context for evaluation metrics and judge-based scoring.
- FeatBit implementation links: targeting rules, percentage rollouts, flag insights, audit logs, and OpenTelemetry integration.
- FeatBit reader journey links: control AI agents in production, feature flags for AI agents, AI control layer, AI agent deployment loop, self-hosted feature flags, and feature flag lifecycle management.
- Image and Open Graph recommendation: use
cover.pngas the social preview. Use the evaluation checklist near the opening decision frame and the runtime control map near the operating-model section because both summarize guidance already available in crawlable text.
Next Step
Pick one AI agent workflow and write its release-control map before comparing vendors: controlled unit, target context, enforcement point, fallback, evidence, audit owner, deployment requirement, and cleanup rule. If any field is unclear, keep the agent in observe-only or search-only mode until the operating model is explicit.