AI Evals: A Practical Guide to Evaluation Tools and Release Decisions
AI evals are the evaluation systems teams use to test prompts, models, retrieval pipelines, agent workflows, and AI product behavior. The term is useful, but it is also overloaded. Some vendors use it for offline model-output grading. Others connect it to online production grading, prompt management, experimentation, feature flags, or agent release control.
The practical question is not "Which AI eval product has the broadest label?" It is "Which evaluation job are we trying to complete, and what release decision will the evidence change?"
For FeatBit readers, the answer is a layered workflow: use AI evals to judge behavior, use feature flags to control exposure, use experiments to measure real outcomes, and use rollback when production evidence turns negative.
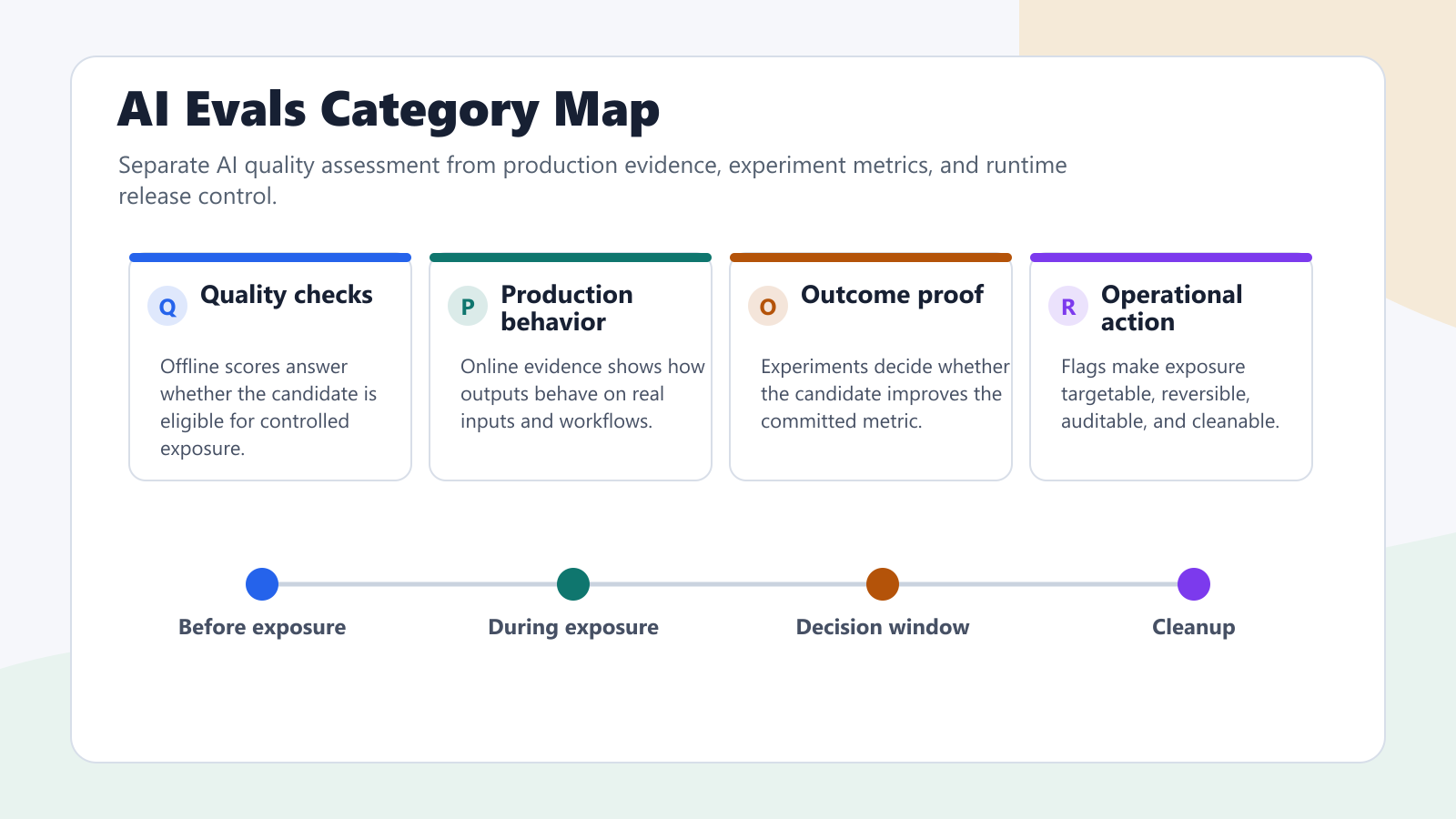
What AI Evals Mean In Product Teams
An AI eval is a repeatable evaluation of an AI system against a defined task, dataset, rubric, grader, user outcome, or operational guardrail.
That can include:
- a golden dataset that checks whether a support assistant answers known questions correctly;
- a regression set that protects high-risk prompts, policy boundaries, or tool-use cases;
- an LLM-as-judge rubric that scores answer completeness, grounding, tone, or format;
- a production grader that reviews live model outputs;
- an experiment metric that decides whether the AI change improved a user or business outcome;
- a release gate that says whether the candidate can advance, pause, roll back, or become the default.
OpenAI's Evals API describes evaluations as testing criteria and data-source configuration that can be run against model configurations. Statsig's AI Evals documentation uses a broader product framing that includes prompts, offline evals, online evals, feature gates, experiments, and analytics. Those are different scopes, not a contradiction. The word "evals" now covers both AI quality assessment and the product workflow around shipping that assessment safely.
The Four Jobs An AI Eval Stack Must Cover
Most teams do not need one giant AI eval tool. They need a stack that covers four distinct jobs.
| Job | Main question | Evidence type | Release action |
|---|---|---|---|
| Offline evaluation | Is the candidate good enough to test beyond controlled examples? | datasets, rubrics, graders, regression cases | pass, repair, reject, or narrow scope |
| Online evaluation | How does the candidate behave on production inputs or live outputs? | shadow results, production grading, human review, telemetry | expand carefully, pause, or repair |
| Experimentation | Does the candidate improve the committed user or business outcome? | exposure events, outcome metrics, guardrails, segment readouts | ship winner, keep control, or iterate |
| Runtime control | Who receives the candidate, and how fast can we stop it? | flag state, targeting, rollout stage, audit trail | target, ramp, roll back, or clean up |
This is the first de-duplication step for the keyword "AI evals." An offline eval guide explains how to build the quality gate. An online eval flag guide explains the production control point. This article is the category guide: how to compare the term across tools and decide what capability you actually need.
AI Eval Vendor Language Is Converging Around Release Decisions
Vendor terminology is useful when it reveals the category boundaries. It becomes risky when every label sounds like it solves the whole release problem.
| Vendor or source | What the public material emphasizes | How to interpret it |
|---|---|---|
| OpenAI Evals | Testing criteria, datasets, graders, and runs against model configurations | Strong language for reproducible evaluation of model or application behavior. |
| Statsig AI Evals | Prompts, offline evals, online evals, feature gates, experiments, analytics, and LLM-as-judge grading | A broad product suite that connects AI quality scoring with production-serving workflows. |
| LaunchDarkly AgentControl experimentation | Config variations, AI metrics, experiments, and end-user behavior metrics | A reminder that monitoring config performance and measuring user impact are separate jobs. |
| GrowthBook AI-native development | Agents creating flags, configuring rollouts, running experiments, querying analytics, and cleaning up stale code | A sign that release and experimentation workflows are becoming agent-accessible. |
| Optimizely Feature Experimentation | Primary, secondary, and monitoring metrics for variation decisions | Useful metric discipline for deciding whether an experiment is winning, losing, or inconclusive. |
| FeatBit | Release-decision infrastructure, feature flags, progressive rollout, experimentation, rollback, and lifecycle ownership | Runtime control for deciding who sees an AI behavior and what happens when evidence changes. |
Do not treat this as a vendor ranking. Treat it as a capability map. A team buying or building AI evals should ask which jobs are included, which jobs require integration, and which jobs remain operational responsibility.
A Decision Matrix For Choosing The Right AI Eval Capability

Use this matrix before adding another eval dashboard or experiment tool.
| Reader question | Capability to prioritize | Why |
|---|---|---|
| "Will this prompt regress known cases?" | Offline evals | The candidate should fail before users see it. |
| "Does this model handle real production input shape?" | Shadow or online evals | Production inputs reveal cases curated datasets miss. |
| "Will this AI feature improve task completion or revenue?" | Experimentation | Product impact requires controlled exposure and outcome metrics. |
| "Can we expose only internal users or one beta segment?" | Feature flags and targeting | Evaluation evidence is not useful if exposure cannot be controlled. |
| "Can we stop the candidate without redeploying?" | Runtime rollback control | AI failures need a fast operational response. |
| "Can we explain why the decision changed?" | Audit trail and release record | Future teams need the evidence, owner, and cleanup path. |
An AI eval stack is weak when it scores outputs but cannot control exposure. It is also weak when it controls exposure but cannot judge AI quality. The connection between those two layers is where release decisions become trustworthy.
Example: Evaluating A Support Assistant Change
Imagine a team changing the support assistant from support_prompt_v3 to support_prompt_v4 and moving from one model route to another. The proposed change may improve answer completeness, but it could also increase latency, token cost, escalation rate, or incorrect confidence.
A mature AI eval workflow would separate the evidence:
- Run offline evals against historical support questions, protected billing cases, account-security questions, and long-thread examples.
- Shadow the candidate against production inputs without showing candidate answers to users.
- Put the candidate behavior behind a feature flag such as
support_assistant_route. - Target internal support agents, then a small low-risk segment, before broader exposure.
- Run an experiment only after the candidate is safe enough for visible user comparison.
- Track one primary outcome, such as resolved case without escalation, plus guardrails for latency, cost, complaint rate, fallback rate, and human correction.
- Decide whether to expand, pause, roll back, or promote the candidate.
- Clean up losing prompt, model, or routing branches after the decision.
FeatBit's AI experimentation and safe AI deployment pages expand the release-control side of this workflow. FeatBit's measurement design guidance helps teams separate the primary metric from guardrails before exposure begins.
What To Ask Before Buying Or Building AI Evals
AI evals deserve the same operational scrutiny as any release system. Use these questions to expose gaps early.
| Evaluation area | Questions to ask |
|---|---|
| Scope | Does the tool evaluate models only, or the full AI application path including prompt, retrieval, tools, and fallback behavior? |
| Dataset quality | Can datasets be versioned, reviewed, sampled, and protected from silent drift? |
| Grading | Which checks are deterministic, which are model-graded, and which require human review? |
| Production evidence | Can offline evals connect to shadow tests, online grading, or live outcome metrics? |
| Exposure control | Can the team target, ramp, pause, or roll back the candidate without redeploying? |
| Experiment design | Can exposure events be joined to outcome events by user, account, conversation, or workflow? |
| Governance | Who can change prompts, configs, rollout percentages, graders, and decision rules? |
| Lifecycle | What happens to losing variants, stale eval gates, and temporary release flags after a decision? |
The lifecycle question is easy to miss. AI teams create many temporary control points: prompt variants, model aliases, retrieval routes, agent tool modes, guardrail settings, and experiment flags. Without cleanup, yesterday's eval becomes tomorrow's confusing branch. FeatBit's feature flag lifecycle management model is useful here because release controls need owners, review windows, evidence, and cleanup paths.
Where Feature Flags Fit In AI Evals
Feature flags do not grade model outputs. They do not replace an eval dataset, a rubric, a human review queue, or an LLM-as-judge workflow.
They solve the runtime control problem around AI evals:
- select which prompt, model, retrieval profile, tool policy, or fallback path runs;
- target eligible users, accounts, environments, or risk tiers;
- start with internal or beta exposure;
- ramp by percentage when evidence is healthy;
- attach variation identity to telemetry and outcome events;
- roll back to the baseline when guardrails fail;
- preserve audit history for the release decision.
That is why FeatBit treats feature flags as release-decision infrastructure. The eval decides whether the candidate is eligible. The flag decides who receives it. The experiment decides whether it improved the outcome. The release owner decides whether to expand, pause, roll back, or clean up.
For implementation, FeatBit docs on targeting rules, percentage rollouts, A/B testing, and the Track Insights API are the practical bridge between exposure control and metric evidence.
Common Mistakes In AI Eval Programs
Treating a high eval score as permission for full rollout. Offline scores qualify a candidate. They do not prove live user value, segment safety, latency, cost, or trust.
Adding online grading without assignment discipline. If the same user or conversation receives inconsistent AI behavior, production evidence becomes hard to interpret.
Measuring AI quality but not business outcome. A support assistant can receive a better quality score while increasing human escalations. Decide the primary outcome before exposure begins.
Letting the eval tool own the release decision silently. Evaluation systems should produce evidence. Release systems should make exposure, rollback, and cleanup explicit.
Skipping rollback design. If the fallback behavior is not available at runtime, the team may need a new deployment during an incident.
Ignoring who can change the grader. A model-graded rubric, prompt, threshold, or dataset is part of the release system. It needs ownership and review, not only dashboard access.
A Practical Operating Model
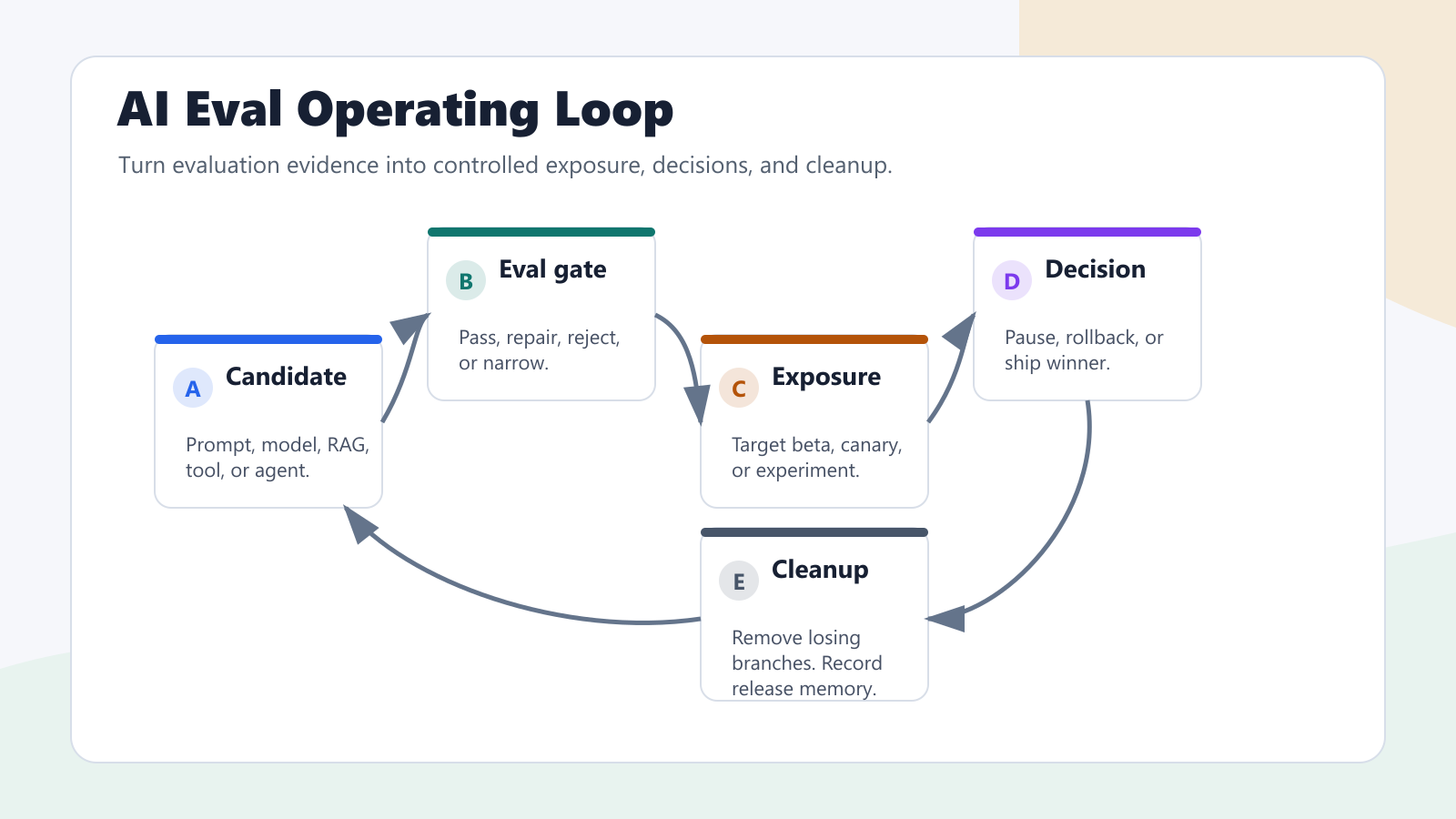
Use this operating model when the team says "we need AI evals":
- Define the AI behavior as a versioned release candidate.
- Run offline evals against known tasks, regression cases, and risk guardrails.
- Decide whether the candidate can move to shadow, internal, canary, or experiment exposure.
- Put the candidate behind a runtime flag before any visible production exposure.
- Emit exposure events when the AI behavior actually runs.
- Join exposure to quality labels, user outcomes, cost, latency, and guardrails.
- Use a written decision state: continue, pause, rollback candidate, ship winner, or inconclusive.
- Promote the winner, keep a deliberate operational kill switch if needed, and remove temporary branches.
This is the difference between evals as a dashboard and evals as a release discipline. The dashboard explains what happened. The release discipline says what the team is allowed to do next.
FAQ
Are AI evals the same as A/B tests?
No. AI evals usually judge AI behavior against datasets, rubrics, graders, human review, or production output quality. A/B tests compare controlled variations against user or business metrics. A mature AI release process often needs both.
Are offline AI evals enough before release?
They are necessary for many material AI changes, but they are not enough for broad rollout. Offline evals cannot prove live user behavior, production latency, cost, traffic mix, or business impact.
What is the difference between online evals and monitoring?
Monitoring shows system health. Online evals connect live AI behavior to a specific candidate, grader, quality label, or outcome question. Monitoring is still required, but evaluation needs attribution and a release decision.
Should AI evals be automated?
Automate repeatable checks, dataset runs, grading, and reporting where possible. Keep human review for severe cases, domain-specific judgment, policy-sensitive workflows, and decisions that change broad production exposure.
Where does FeatBit fit?
FeatBit fits the runtime control, experimentation, and release-decision layer. It helps teams decide who sees which AI behavior, ramp safely, track exposure, connect metrics, roll back quickly, and clean up after the decision.
Bottom Line
AI evals are not one product capability. They are a release evidence system for AI behavior.
Use offline evals to catch preventable regressions. Use online evals to inspect production behavior. Use experiments to measure real outcomes. Use feature flags to control exposure and rollback. Use lifecycle discipline so temporary AI release controls do not become permanent confusion.
That is the practical way to evaluate AI changes without pretending a score, a dashboard, or a rollout switch can make the full release decision alone.
Source Notes
- OpenAI evaluation context: the OpenAI Evals API reference describes evals as testing criteria and data-source configuration that can be run against model configurations.
- AI eval product terminology: Statsig's AI Evals overview describes prompts, offline evals, online evals, feature gates, experiments, analytics, and LLM-as-judge grading.
- Experimentation category context: LaunchDarkly's AgentControl experimentation documentation distinguishes config monitoring from experiments on end-user behavior; Optimizely's Feature Experimentation metrics documentation explains primary, secondary, and monitoring metrics.
- Agent-ready release workflow context: GrowthBook's AI-native development page describes agent-accessible flags, rollouts, experiments, analytics, winner decisions, and stale-code cleanup.
- Feature flag standard context: the OpenFeature flag evaluation specification provides vendor-neutral language for flag keys, evaluation context, typed values, and detailed evaluation metadata.
- FeatBit implementation context: AI experimentation, safe AI deployment, measurement design, feature flag lifecycle management, targeting rules, percentage rollouts, A/B testing, and the Track Insights API support the workflow described here.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the AI eval category as a release-decision stack. - Use
ai-evals-category-map.pngnear the opening because it separates offline quality checks, online evidence, experiment metrics, and release controls. - Use
ai-evals-decision-matrix.pngin the decision matrix section because it helps readers choose the right capability for the job. - Use
ai-evals-operating-loop.pngnear the operating model because it shows the end-to-end workflow from candidate change to cleanup.