LaunchDarkly vs Statsig for AI Evals: Which Operating Model Fits Your AI Release?
If you are comparing LaunchDarkly vs Statsig for AI evals, do not start with a generic vendor scorecard. Start with the release question your team needs to answer.
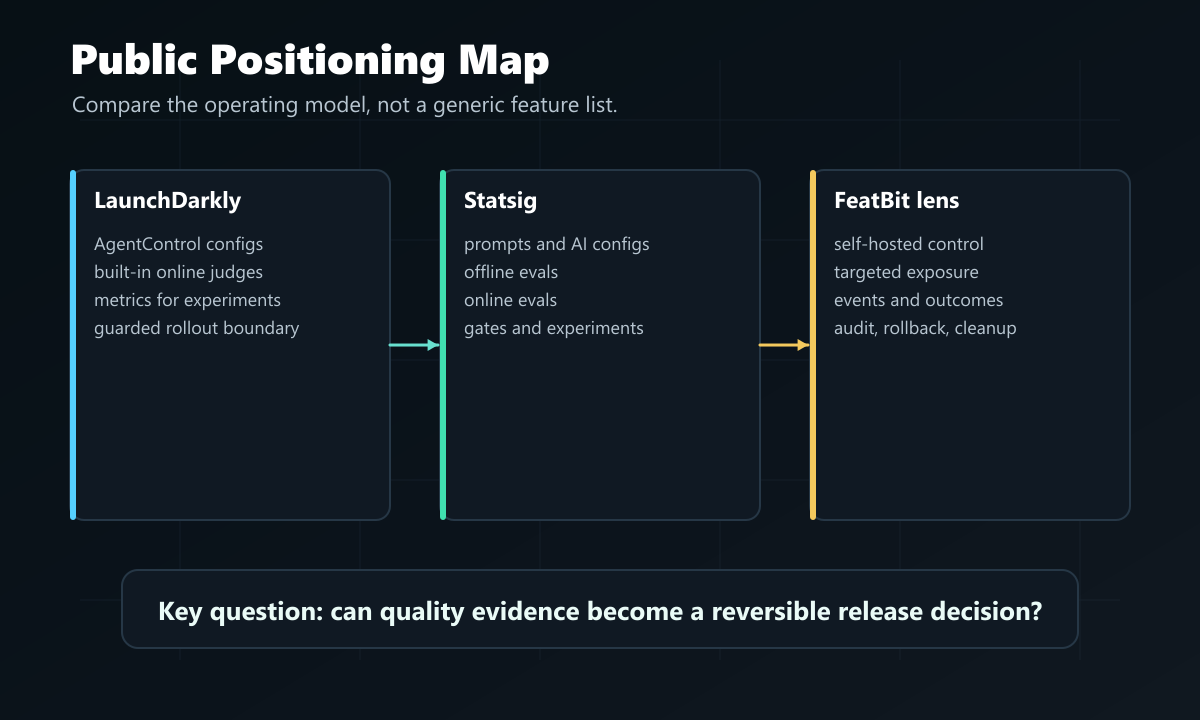
LaunchDarkly's public AgentControl documentation is strongest to evaluate when your team wants AI configs, online judges, monitoring metrics, guarded rollout, and experimentation close to an existing feature-management workflow. Statsig's public AI Evals documentation is strongest to evaluate when your team wants a dedicated eval workflow around prompts, offline evals, online evals, gates, experiments, and analytics.
For FeatBit readers, there is a third operating-model question: do you need the eval result to become a reversible release decision in a self-hosted or open-source control plane? AI evals tell you something about quality. Release control decides who sees the candidate, which business outcome matters, what guardrail can stop expansion, and how the team rolls back or cleans up.
Short Answer
Use LaunchDarkly as a first evaluation when the main job is to connect AI config variations to online evaluation, monitoring, guarded rollout, and experiments inside a feature-management platform.
Use Statsig as a first evaluation when the main job is to manage prompts and AI configs through a productized eval path that includes offline evals, online evals, feature gates, experiments, and analytics.
Evaluate FeatBit when the main job is runtime release control for AI-era software: targeted exposure, percentage rollout, A/B testing, Track Insights events, auditability, rollback, self-hosting, and lifecycle cleanup. FeatBit is not positioned here as a native AI judge. It is the control layer that can make external or application-owned eval evidence operational.
What The Query Usually Means
"LaunchDarkly vs Statsig AI Evals" is a navigational comparison query. The reader probably already knows both vendor names and is trying to decide where to spend proof-of-concept time.
The useful comparison is not "Which vendor is better?" It is:
| Reader question | Why it matters |
|---|---|
| Do we need native quality grading, or do we already have eval infrastructure? | Native judges and offline evals reduce integration work, but some teams already own graders, traces, and review workflows. |
| Do we need experiments on business outcomes? | A quality score can improve while user trust, conversion, support load, latency, or cost gets worse. |
| Do we need guarded rollout or reversible release control? | AI regressions may require immediate pause or rollback before an experiment reaches a clean result. |
| Where do prompts, responses, scores, and model-provider calls live? | Data boundaries can matter for privacy, procurement, cost, and operational control. |
| Who owns cleanup after the decision? | Temporary prompts, model routes, judges, event schemas, and flags become release debt if they never end. |
That framing creates a fairer comparison. LaunchDarkly and Statsig both publish AI evaluation language, but they emphasize different workflows.
LaunchDarkly AgentControl: What To Verify
LaunchDarkly documents AgentControl online evaluations with built-in judges for accuracy, relevance, and toxicity. Its docs say online evaluations run in production on live user traffic, score responses continuously, and can help monitor quality after release. The same documentation says evaluation scores can be used in guarded rollouts and experiments, and that sampling affects model usage and provider cost.
LaunchDarkly's AgentControl experimentation documentation also draws a useful boundary. Monitoring can show AI metrics such as token usage or call duration. Experimentation measures how config variations affect end-user behavior through metrics. The docs also note that guarded rollouts and experiments cannot run at the same time on the same flag: use guarded rollout for regression monitoring, and use an experiment to measure metric impact.
That makes LaunchDarkly worth testing when your AI release workflow looks like this:
- AI behavior is represented as an AgentControl config or variation.
- Quality checks can run as attached or programmatic judges.
- The team wants quality metrics near rollout controls.
- The same platform already owns feature flags, targeting, experiments, or guarded rollout.
- Operators need to compare variations with live data and decide which variation to serve.
Questions to ask during a proof of concept:
| Area | LaunchDarkly proof-of-concept question |
|---|---|
| Config fit | Does the AI behavior map cleanly to AgentControl config variations, or does it need direct judge evaluation in code? |
| Judge design | Are built-in judges enough, or do you need custom domain-specific judges? |
| Experiment boundary | When should a rollout use guarded rollout, and when should it become an experiment? |
| Cost control | What sampling rate gives enough signal without excessive model-provider usage? |
| Data flow | Which prompts, outputs, judge requests, scores, and reasons are stored or transmitted? |
| Release action | Can a low quality score or bad business outcome pause, narrow, or roll back the candidate quickly? |
The key risk is over-reading an online judge score. A judge can help detect quality changes, but it does not automatically prove business impact. Your proof of concept should include at least one user or business outcome metric.
Statsig AI Evals: What To Verify
Statsig's AI Evals documentation describes prompts, offline evals, and online evals as core components for iterating on LLM apps in production. The docs say prompts can represent model provider, model, temperature, and related prompt configuration; offline evals grade outputs on fixed test sets before real users are exposed; and online evals grade model output in production on real-world use cases. The same overview connects AI Evals with Statsig's standard feature gates, experiments, and analytics.
Statsig's public AI Evals product page also positions the workflow around AI configs, prompt and model versioning, automated grading pipelines, online evals, dashboards, SDK logging, and online experimentation. Treat that as product positioning until your team validates the exact workflow in a demo or trial.
There is an availability caveat. The Statsig documentation reviewed on June 8, 2026 says AI Evals are in beta and that Statsig is no longer accepting new beta customers at that time. If AI Evals are central to the purchase, availability and packaging should be explicit procurement checks.
Statsig is worth testing when your AI release workflow looks like this:
- Prompt and model configuration should live inside a productized AI eval workflow.
- Offline evals are part of the pre-release gate.
- Online evals or shadow runs should grade real production use cases.
- Feature gates, experiments, analytics, and AI eval signals should sit in one product stack.
- Product and data teams want evaluation and business metrics close together.
Questions to ask during a proof of concept:
| Area | Statsig proof-of-concept question |
|---|---|
| Availability | Is AI Evals available for your account, region, plan, timeline, and production use case? |
| Offline gate | Can your fixed test set, rubric, and severe regression checks run before user exposure? |
| Online eval | Can candidate prompts be shadow run or evaluated in production without confusing the user experience? |
| Assignment unit | Can you assign by user, account, conversation, workflow, or another custom unit? |
| Metric join | Can eval scores, exposure events, product outcomes, cost, latency, and guardrails be joined cleanly? |
| Lifecycle | What happens to losing prompts, temporary gates, and experiment logic after the decision? |
The key risk is assuming a productized eval workflow removes the need for release design. Even with offline and online evals, your team still needs a primary outcome, guardrails, rollback rule, and owner.
The Real Decision: Eval Workflow Or Release Workflow
The comparison becomes clearer when you separate evaluation from release control.
| Decision area | LaunchDarkly leaning question | Statsig leaning question | FeatBit release-control question |
|---|---|---|---|
| AI config model | Do we want online judges attached to AI config variations inside feature management? | Do we want prompts and AI configs inside a dedicated AI Evals workflow? | Do we need any prompt, model, retrieval, or agent route to be controlled by a runtime flag? |
| Pre-release quality | Can our pre-release checks be handled outside the platform or through programmatic judge evaluation? | Do we need productized offline evals as a first-class workflow? | Which offline gate must pass before targeted production exposure starts? |
| Production evidence | Do online evaluation metrics and experiments cover our live decision? | Do online evals, experiments, analytics, and gates cover our live decision? | Can exposure and outcome events be joined to the served variation? |
| Rollout safety | Do guarded rollouts and experiments map to our release stages? | Do gates and experiments map to our release stages? | Can we target, ramp, pause, roll back, audit, and clean up without redeploying? |
| Ownership | Are we comfortable with the vendor's managed data flow and platform boundary? | Are we comfortable with the vendor's managed data flow and beta or packaging status? | Do we need open-source inspection, self-hosting, or private release infrastructure? |
This table is not a ranking. It is a way to stop a tool comparison from hiding the actual operating model.
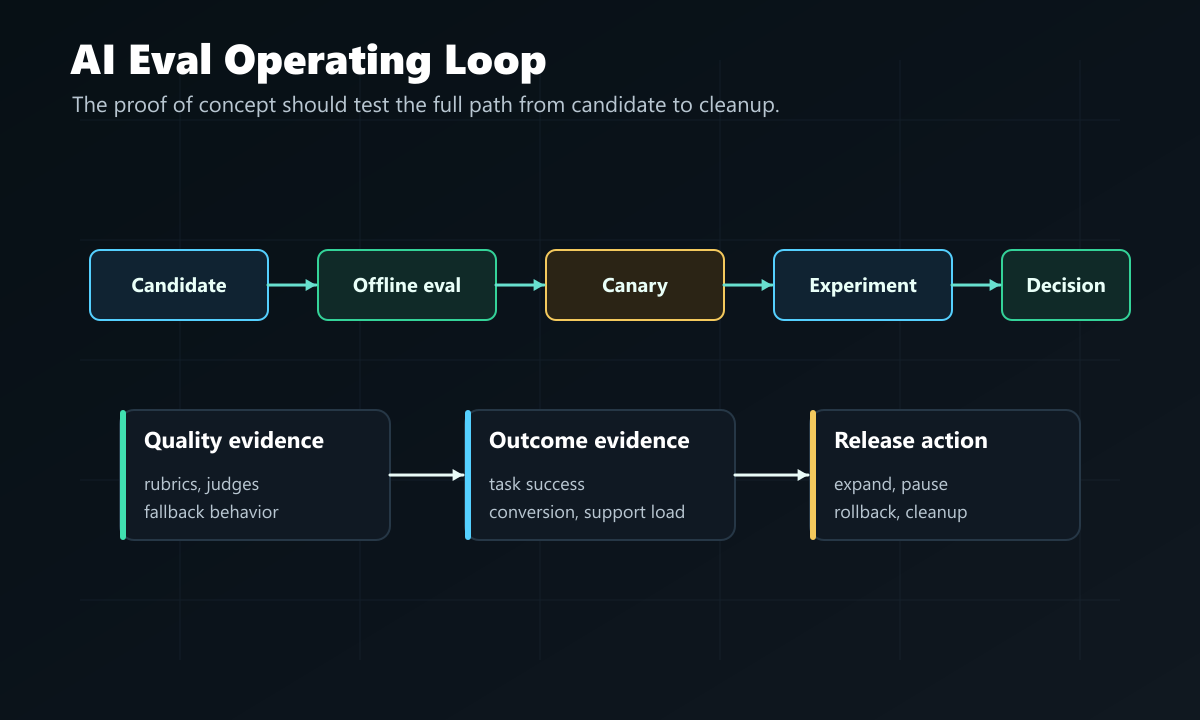
A Shared Proof Of Concept
Do not evaluate LaunchDarkly and Statsig with different demo scenarios. Use one concrete AI release and ask each vendor to implement the same path.
ai_eval_poc:
release_question: should_support_assistant_use_candidate_prompt_v4
candidate: prompt_v4_model_b_standard_retrieval
baseline: prompt_v3_model_a_standard_retrieval
assignment_unit: conversation_id
eligible_scope:
environment: production
segment: english_support_chat
exclusions:
- regulated_accounts
- active_incident_accounts
offline_gate:
must_pass:
- refund_policy_regression
- account_security_regression
- required_answer_format
online_evidence:
quality_metric: policy_grounding_score
primary_outcome: case_resolved_without_escalation
guardrails:
- complaint_rate
- human_correction_rate
- p95_latency
- estimated_cost_per_case
- fallback_rate
release_actions:
healthy_shadow: internal_users
healthy_canary: limited_customer_segment
experiment_winner: expand_or_promote
guardrail_breach: rollback_to_baseline
after_decision: remove_losing_route_or_keep_intentional_kill_switch
A useful vendor demo should show the same things in sequence:
- How the candidate is versioned.
- How offline quality is checked before exposure.
- How production assignment stays stable.
- How exposure is emitted only when the AI behavior actually runs.
- How quality scores and business outcomes are joined.
- How guardrails pause, narrow, or roll back exposure.
- How the release owner records the final decision.
- How temporary prompts, routes, flags, judges, and event schemas are cleaned up.
Where FeatBit Fits In This Comparison
FeatBit is an open-source feature flag and experimentation platform with a release-decision point of view. In this comparison, FeatBit is most relevant when the team already has, or plans to build, an eval layer and needs a controlled production boundary around it.
FeatBit can help AI teams:
- target internal users, beta accounts, regions, plans, or risk tiers;
- choose prompt, model, retrieval, fallback, or agent-policy variations at runtime;
- ramp by percentage as evidence improves;
- connect flag variation to custom metric events through the Track Insights API;
- use targeting rules, percentage rollouts, and A/B testing with feature flags;
- keep audit history and rollback controls close to the release owner;
- manage cleanup through feature flag lifecycle management;
- run in a self-hosted feature flag platform when data ownership and infrastructure control matter.
For AI-specific operating context, FeatBit's AI experimentation, safe AI deployment, and measurement design pages use the same pattern: qualify the candidate, expose it gradually, measure quality and outcomes, watch guardrails, then expand, pause, roll back, or clean up.
That is a different buyer story from native AI eval suites. FeatBit does not need to own the judge to own the release decision. The application or eval service can score AI outputs, while FeatBit controls who sees the candidate and how the result becomes action.
Evaluation Checklist
Use this checklist with both vendors and with any internal or FeatBit-based architecture.

| Area | What to verify |
|---|---|
| Native evals | Offline evals, online evals, built-in judges, custom judges, rubric control, output structure, and availability. |
| Experiment design | Assignment unit, stable variation, exposure timing, primary metric, guardrails, and segment analysis. |
| Runtime control | Targeting, percentage rollout, environment separation, pause, rollback, and fallback behavior. |
| Data boundary | Where prompts, outputs, scores, judge reasons, provider calls, and metric events travel and persist. |
| Cost control | Evaluation sampling, extra model-provider calls, dashboard usage, event volume, and export requirements. |
| Governance | Who can edit prompts, judges, rollout percentage, experiments, and rollback rules. |
| Lifecycle | How winners are promoted, losers are removed, temporary flags are archived, and decision evidence is preserved. |
The best answer is not always the platform with the longest AI eval feature list. It is the platform that makes your specific AI release decision understandable, measurable, reversible, and maintainable.
Common Mistakes In A LaunchDarkly vs Statsig AI Evals Evaluation
Comparing judge features before defining the release question. A judge score only matters when the team knows which behavior is being judged, which population is eligible, and which action the score can trigger.
Treating offline evals as launch approval. Offline evals can catch known regressions before exposure. They do not prove production behavior, user trust, or business impact.
Letting the assignment unit default to request-level randomization. AI assistants, support workflows, and agents often need conversation, user, account, or workflow assignment so the experience stays coherent.
Tracking exposure too early. Exposure should be recorded when the assigned AI behavior actually runs, not when the page loads or the route is merely eligible.
Ignoring fallback state. If the candidate frequently falls back to baseline, the evidence should show that. Otherwise the candidate can look safer, cheaper, or better than it really was.
Forgetting procurement caveats. Verify current availability, packaging, data processing, sampling cost, export paths, and support for your exact use case. Public docs and product pages are starting points, not contracts.
Leaving temporary controls behind. After a decision, remove losing prompt branches, retire obsolete judges, promote the winner, or intentionally keep a long-lived operational control with an owner.
Bottom Line
Choose LaunchDarkly for AI evals when AgentControl configs, online judges, monitoring, guarded rollout, and experimentation naturally fit the feature-management workflow your team already wants.
Choose Statsig for AI evals when prompts, offline evals, online evals, gates, experiments, and analytics should form the main evaluation workflow, and when current availability matches your buying timeline.
Evaluate FeatBit when your priority is open-source or self-hosted release control: flags, targeting, experiments, events, auditability, rollback, and lifecycle cleanup around whatever AI eval system your team trusts.
The winning operating model is the one that can answer this in production: who received which AI behavior, what quality evidence was collected, which business outcome changed, which guardrail mattered, who changed exposure, and how the team can reverse or clean up the decision.
Source Notes
- LaunchDarkly AgentControl online evaluation context: LaunchDarkly's online evaluations documentation describes built-in judges, production scoring, sampling, provider-call boundaries, evaluation metrics, and use of online evaluation scores in guarded rollouts and experiments.
- LaunchDarkly experimentation context: LaunchDarkly's AgentControl experimentation documentation describes measuring how config variations affect end-user behavior through defined metrics, and distinguishes guarded rollouts from experiments.
- Statsig AI Evals context: Statsig's AI Evals overview describes prompts, offline evals, online evals, feature gates, experiments, analytics, LLM-as-a-judge, and the beta availability caveat visible in the documentation reviewed for this article.
- Statsig product-positioning context: Statsig's AI Evals product page is cited for public positioning around AI configs, offline and online evals, automated grading pipelines, dashboards, SDK logging, and online experimentation.
- FeatBit implementation context: AI experimentation, safe AI deployment, measurement design, feature flag lifecycle management, self-hosted feature flags, targeting rules, percentage rollouts, A/B testing with feature flags, and the Track Insights API support the release-control workflow described here.
- This article compares public documentation signals and evaluation criteria. It does not claim vendor performance results, security rankings, pricing advantage, customer outcomes, or private roadmap commitments.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the vendor comparison and release-decision lens. - Use
comparison-map.pngnear the opening because it separates LaunchDarkly, Statsig, and FeatBit's operating-model roles. - Use
operating-loop.pngin the proof-of-concept section because it shows the path from candidate through eval, experiment, decision, and cleanup. - Use
buyer-checklist.pngbeside the checklist because it reinforces the procurement and architecture questions readers should verify.