Can Feature Flags Replace AI Evals?

The short answer is no: feature flags should not replace AI evals.
They answer different questions. AI evals ask, "Does this model, prompt, retrieval change, or agent workflow meet a quality bar?" Feature flags ask, "Who should see this change, when should exposure expand, and how quickly can we stop it if production evidence looks bad?"
For AI product teams, the useful answer is not to choose one. Use evals to decide whether an AI change is ready to enter a controlled release. Use feature flags to expose that change safely, compare variants in production, and connect quality checks to business outcomes.

The real question behind the keyword
Teams usually ask whether feature flags can replace AI evals because AI changes are harder to release than ordinary UI changes.
A prompt update can improve one task and harm another. A model upgrade can reduce latency for one workflow and change tone in another. A retrieval change can improve answer coverage while increasing irrelevant citations. An agent tool permission can unlock a useful workflow and create a new failure mode.
That creates two separate release jobs:
- Decide whether the AI behavior is good enough before broad exposure.
- Control who sees the behavior while real users, real tasks, and real business metrics produce evidence.
AI evals help with the first job. Feature flags help with the second job. Treating either one as a full replacement creates a blind spot.
What AI evals are good at
AI evals give teams a repeatable way to measure model or application behavior against a defined test set, rubric, grader, or benchmark. OpenAI's Evals documentation describes evals as a way to test model outputs and measure performance across tasks. That framing matters because evals are about quality assessment, not traffic control.
Use evals when you need to answer questions like:
- Does the new prompt follow the required format?
- Does the model answer support questions with enough accuracy?
- Does the retrieval system cite relevant documents?
- Does the agent choose the correct tool in common scenarios?
- Does the output stay within policy, tone, or safety boundaries that your team can test?
Good evals are especially useful before release because they create a stable comparison between versions. If version B fails your regression suite, a feature flag cannot make version B better. It can only limit exposure to the risk.
What feature flags are good at
Feature flags control runtime behavior without requiring a new deployment for every exposure decision. In an AI system, a flag can choose a prompt version, model provider, retrieval strategy, ranking policy, guardrail setting, agent tool, fallback path, or rollout percentage.
Use feature flags when you need to answer questions like:
- Should this AI change be visible to internal users only?
- Should version B start at 1 percent of traffic before expanding?
- Should enterprise customers stay on the stable model while beta users test the new one?
- Should the system fall back to the previous prompt when latency, error rate, or negative feedback rises?
- Which variant produces better task completion, conversion, retention, support deflection, or cost outcomes?
Feature flags are strongest when paired with targeting, progressive rollout, auditability, and metric tracking. FeatBit supports the core release-control workflow that matters here: teams can manage flags, target users or segments, roll out gradually, and use experimentation practices to compare outcomes.
For a broader implementation background, see FeatBit's guide to implementing feature flags and the FeatBit documentation on experimentation.
Where feature flags cannot replace evals
Feature flags do not create a quality judgment by themselves. They can expose a change, route traffic, and connect exposures to metrics, but they do not know whether an answer is correct, grounded, helpful, safe, or on brand unless you attach measurement systems that can evaluate those properties.
That means feature flags cannot replace evals for:
- Regression testing before release.
- Golden-set comparisons across prompts, models, or retrieval settings.
- Rubric-based review of answer quality.
- Safety checks that should block release before users are exposed.
- Reproducible analysis of known failure cases.
- CI or pre-production gates for AI behavior.
If a team skips evals and relies only on flag rollout, the first real quality test happens in production. Progressive exposure reduces the blast radius, but it does not remove the need to know what you are shipping.
Where evals cannot replace feature flags
AI evals also have limits. They can show how a change performs against the cases you chose to test, but they cannot fully represent live traffic, changing user intent, production latency, infrastructure cost, account-level behavior, or business impact.
Evals cannot replace feature flags for:
- Gradual exposure to real users.
- Instant rollback without redeploying.
- Targeting by environment, segment, account, geography, plan, or beta group.
- Online experiments that connect exposure to product metrics.
- Operational control when a model provider, tool, or retrieval service behaves differently in production.
- Governance around who changed exposure and when.
This is why AI release management needs both a quality loop and an exposure loop.
A practical decision frame
Use this frame when deciding whether a change belongs in your eval system, your flag system, or both.
| Release question | Use AI evals | Use feature flags |
|---|---|---|
| Did the prompt, model, or retrieval change improve known test cases? | Yes | No |
| Can this version pass a release gate before users see it? | Yes | No |
| Can we expose the change to a small audience first? | No | Yes |
| Can we target a variant to beta users, internal teams, or one customer segment? | No | Yes |
| Can we compare production outcomes between variants? | Sometimes, if eval outputs are logged | Yes |
| Can we roll back quickly when live metrics degrade? | No | Yes |
| Can we explain why a model output was judged better? | Yes, if the rubric is explicit | No |
| Can we control which AI behavior runs at request time? | No | Yes |
The boundary is simple: evals judge behavior; flags operate behavior.
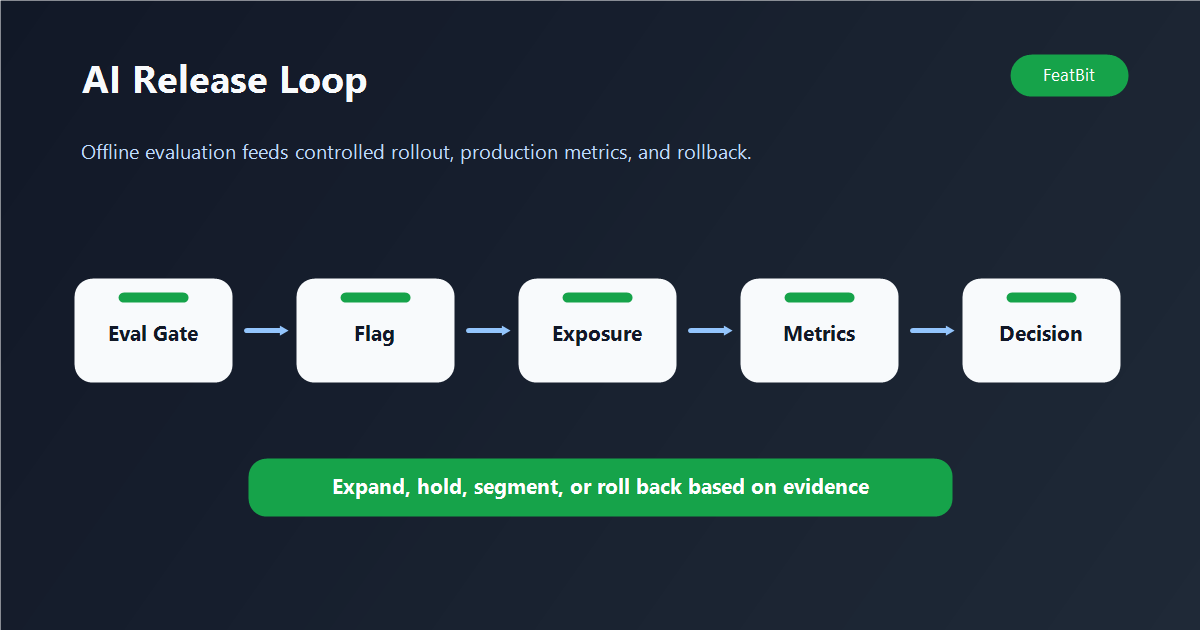
How to combine them for AI changes
A strong AI release workflow usually looks like this:
-
Define the change as a versioned behavior. This could be
support_prompt_v4,gpt-4.1-mini,hybrid_retrieval_v2, oragent_refund_tool_enabled. -
Run offline evals before exposure. Compare the new behavior against the current production behavior. Include expected wins, known risk cases, and regressions from previous incidents.
-
Put the behavior behind a feature flag. The flag should select the AI behavior at runtime. Keep the old behavior available as the fallback path.
-
Start with internal or low-risk exposure. Target employees, a beta segment, or a low percentage of traffic. Avoid expanding until the production evidence is coherent.
-
Track both quality and business metrics. Quality metrics might include human review scores, thumbs up or down, escalation rate, hallucination reports, or task success labels. Business metrics might include conversion, support deflection, retention, resolution time, cost per request, or latency.
-
Decide whether to expand, hold, roll back, or iterate. A change can pass evals and still fail production economics. It can also look neutral in aggregate while harming one important segment. The flag gives you the control surface to act on that evidence.
Example: releasing a new support assistant prompt
Imagine a team changing the prompt for a customer support assistant. The goal is to improve answer completeness without increasing escalations to human support.
The eval work might include:
- A golden set of past support questions.
- Expected source documents for each answer.
- A rubric for completeness, grounding, and tone.
- Regression cases for billing, account deletion, and security-sensitive questions.
The feature flag work might include:
- A flag named
support_assistant_prompt_version. - Variations for
control,prompt_v2, andprompt_v2_with_stricter_citations. - Internal targeting for the support team first.
- A 5 percent external rollout after the eval gate passes.
- Metrics for answer acceptance, escalation, latency, and cost per resolved case.
The team should not ask, "Did the flag replace the eval?" The better question is, "Did the eval prevent weak behavior from reaching users, and did the flag let us learn safely from production?"
How this changes experiment design
Feature flags make AI experiments operationally manageable, but they do not make every AI comparison a clean experiment by default.
For a credible production experiment, define:
- The unit of assignment, such as user, account, organization, or conversation.
- The primary metric, such as resolved support case rate or successful task completion.
- Guardrail metrics, such as latency, error rate, cost, escalation, and negative feedback.
- The exposure rules, including who is excluded and when the rollout stops.
- The fallback behavior if a provider, prompt, tool, or retrieval path fails.
In FeatBit, this is the natural place to connect feature flags with experimentation. The flag controls assignment and exposure. The experiment measures whether the variant improves the outcome that matters. Evals remain the pre-release quality gate and can also feed production review workflows when human or model-graded labels are collected after exposure.
Common mistakes to avoid
Do not use a feature flag as a substitute for a release gate. A flag can limit exposure, but it does not prove that the AI change is acceptable.
Do not treat an eval score as permission for full rollout. Offline scores can miss production behavior, segment-specific harm, latency, cost, and business impact.
Do not compare AI variants without stable assignment. If the same user randomly receives different prompts across a workflow, your metrics may mix novelty, inconsistency, and actual quality differences.
Do not rely on one metric. AI changes often move quality, cost, latency, and business outcomes in different directions.
Do not remove the fallback too early. The previous behavior is part of your operational safety model until production evidence supports cleanup.
A simple operating model
For most AI product teams, the clean operating model is:
- Evals decide whether a change is eligible for exposure.
- Feature flags decide who receives the change.
- Experiments decide whether the change improves real outcomes.
- Observability decides whether the system is healthy.
- Rollback decides what happens when evidence turns negative.
FeatBit fits the release-control and experimentation part of that model. It helps teams turn AI behavior into controlled runtime variants, expose those variants gradually, target the right audiences, and connect exposure to measurable outcomes. It does not remove the need for a thoughtful eval suite, and a good eval suite does not remove the need for runtime control.
FAQ
Can feature flags replace AI evals?
No. Feature flags control exposure. AI evals assess behavior. Use evals before and during release to judge quality, and use flags to target, roll out, compare, and roll back AI behavior in production.
Can AI eval results become feature flag rules?
Sometimes, but be careful. Eval results can inform release decisions, such as whether a variant is eligible for rollout. Per-request eval decisions can also route traffic in advanced systems, but that creates latency, cost, and governance questions. For most teams, evals should feed release decisions rather than become hidden runtime logic.
Should every AI change be behind a feature flag?
Every material AI behavior change should have a reversible control point. That does not mean every small prompt edit needs a long-running experiment, but changes to prompts, models, retrieval, tools, guardrails, or providers should be easy to target and roll back.
What metrics should an AI feature flag experiment track?
Track one primary outcome and several guardrails. Common primary outcomes include task completion, conversion, support resolution, or accepted answer rate. Guardrails often include latency, cost, error rate, escalation, negative feedback, and safety review findings.
Where does FeatBit fit in an AI evaluation workflow?
FeatBit is the runtime control and experimentation layer. It can help expose AI variants safely and measure outcomes, while your eval framework handles quality scoring, regression checks, rubric-based review, and pre-release gates.
Source notes
- OpenAI documents evals as a way to test model behavior and measure task performance: OpenAI Evals guide and Evals API reference.
- OpenFeature defines feature flag evaluation as returning a value from flag state, context, and provider behavior: OpenFeature flag evaluation specification.
- FeatBit's product context for this article comes from its public guidance on feature flag implementation and experimentation.
- Image plan: use
cover.pngas the Open Graph image,evals-vs-flags-decision-map.pngfor the decision comparison, andai-release-loop.pngfor the workflow diagram.