AI Evals Overview: A Scorecard for Quality and Business Outcomes
AI evals should help a team decide what to do with an AI change. A score that looks good in an offline dashboard is useful, but it is not a release decision by itself. The release owner still needs to know whether the candidate prompt, model route, retrieval profile, or agent workflow improves the user outcome without breaking quality, cost, latency, safety, or trust guardrails.
This overview gives AI product and platform teams a practical scorecard. Use it when the question is not only "What are AI evals?" but "Which evidence should decide whether this AI change can advance, pause, roll back, or become the default?"

The Short Answer
An AI evals scorecard is a written contract that connects evaluation evidence to a release action.
It should cover five layers:
| Scorecard layer | Question it answers | Typical evidence | Release action |
|---|---|---|---|
| Offline quality | Is the candidate good enough to test beyond curated cases? | datasets, rubrics, regression cases, graders, human review | repair, reject, narrow scope, or move to shadow |
| Online behavior | Does the candidate handle production input shape? | shadow outputs, production grading, fallback rate, human review queue | continue, pause, or repair |
| Business outcome | Does the candidate improve the committed product result? | task completion, support deflection, conversion, retention, accepted answer | expand, keep control, or iterate |
| Guardrails | Is the candidate causing unacceptable harm? | latency, cost, complaint rate, unsafe output, escalation, provider errors | pause or roll back |
| Release control | Can the team target, ramp, audit, and stop the candidate? | flag state, rollout stage, owner, event joinability, rollback path | canary, experiment, full rollout, rollback, or cleanup |
This is narrower than a generic buyer guide to AI eval tools. The job here is to design the decision scorecard before production exposure starts.
Why AI Evals Need A Release Scorecard
Vendor terminology is converging, but the word "evals" still covers several jobs. OpenAI's Evals API describes evaluations as testing criteria and data-source configuration that can be run against model configurations. Statsig's AI Evals documentation uses a broader product frame that includes prompts, offline evals, online evals, feature gates, experiments, analytics, and LLM-as-judge grading.
Both frames are useful. They also show why teams need a scorecard instead of one overloaded metric. Offline grading can catch regressions before user exposure. Online grading can inspect production outputs. Experiments can compare user outcomes. Feature flags can target, ramp, and roll back exposure.
The scorecard ties those parts together. It says which evidence is required, which metric decides the release, which guardrail can stop expansion, and which owner is allowed to change rollout state.
NIST's AI Risk Management Framework is useful background here because it treats trustworthy AI as a risk-management problem across design, development, use, and evaluation. For release teams, the practical translation is simple: evals should be connected to the context of use, not only to a generic model score.
Start With The Release Question
The strongest AI evals overview for your team is not a list of tools. It is a release question written before the candidate is exposed.
Weak release questions sound like this:
- "Is the new prompt better?"
- "Did the model score higher?"
- "Can we launch the assistant?"
Useful release questions sound like this:
- "Should
support_prompt_v4advance from offline eval to shadow testing for English support chats?" - "Should the candidate model route expand from internal users to 5 percent of paid accounts?"
- "Should the retrieval profile become the default if it improves case resolution without increasing complaint rate, latency, or cost?"
The second set is better because it names the behavior, scope, next stage, primary outcome, and guardrails. That makes the eval actionable.
Build The Scorecard Before The Eval Runs
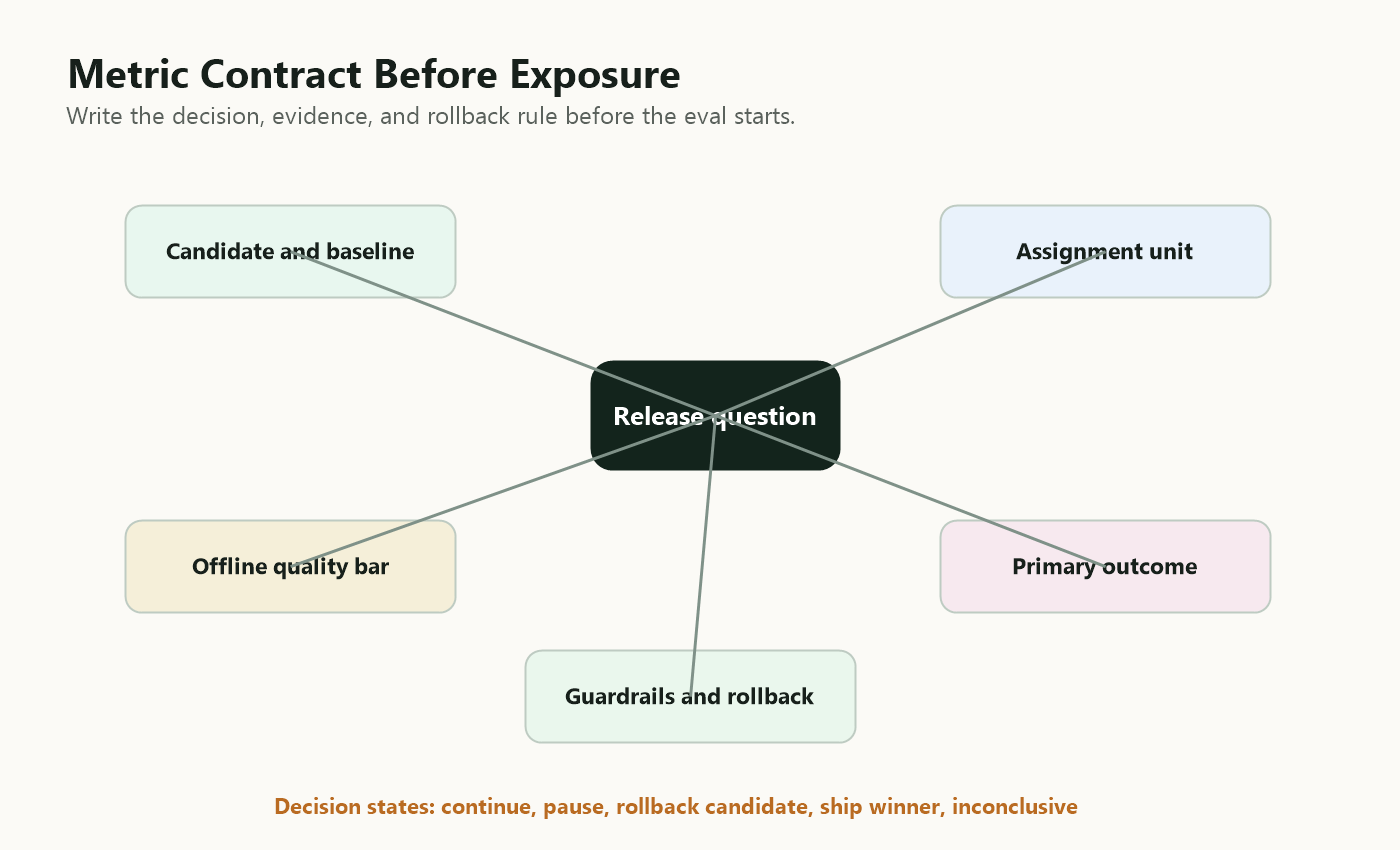
Use a small written contract before running an offline eval, shadow test, canary, or experiment.
ai_eval_scorecard:
release_question: should_support_assistant_v4_expand_to_paid_accounts
candidate: support_prompt_v4_model_b_reranker_v2
baseline: support_prompt_v3_model_a_baseline_search
owner: ai_platform_team
assignment_unit: account_id
eligible_scope:
environment: production
surface: english_support_chat
exclusions:
- regulated_accounts
- active_incident_accounts
offline_quality:
must_pass:
- protected_billing_cases
- account_security_regressions
- answer_format_assertions
review:
- grounding
- completeness
- tone
primary_business_outcome: case_resolved_without_escalation
guardrails:
- p95_latency
- cost_per_resolved_case
- complaint_rate
- human_correction_rate
- fallback_rate
rollout_action:
pass_offline: move_to_shadow_test
healthy_shadow: internal_users
healthy_canary: 50_50_experiment
guardrail_breach: rollback_to_baseline
cleanup: remove_losing_route_or_promote_winner_after_decision
The exact fields can change by product. The discipline should not. A team should know what evidence can move a candidate forward before the dashboard exists.
Separate Quality Metrics From Outcome Metrics
AI quality metrics describe the behavior of the AI system. Outcome metrics describe the effect on the user or business workflow. You usually need both.
| AI change | Quality evidence | Business outcome | Guardrails |
|---|---|---|---|
| Support assistant prompt | grounded answer, correct policy, complete response | case resolved without escalation | complaint rate, correction rate, latency, cost |
| Model route | rubric score, regression pass, format validity | successful task per session | provider errors, fallback rate, cost per success |
| RAG retrieval profile | citation relevance, source coverage, no-answer rate | accepted answer or successful search | unsafe source rate, latency, stale content |
| Agent tool policy | correct tool choice, safe argument shape | workflow completed without human takeover | wrong-tool rate, approval queue, incident count |
| Classification prompt | routing accuracy, confidence calibration | downstream task completed correctly | high-risk false positives, manual reroutes |
Do not let an average quality score decide the whole release. A support assistant can sound better while increasing escalations. A model route can improve answer quality while making the workflow too slow or expensive. A tool-using agent can complete more tasks while raising the severity of the failures it creates.
FeatBit's measurement design guidance uses the same separation: one primary metric decides the release, while guardrails protect the system from unacceptable tradeoffs.
Decide The Evidence Stage
Not every AI eval answers the same question. The scorecard should name the stage so people do not overclaim the evidence.
| Stage | What it can prove | What it cannot prove |
|---|---|---|
| Offline eval | Candidate handles known examples, regressions, and rubric checks | Live user behavior or business impact |
| Shadow test | Candidate handles production input shape without visible exposure | User preference or conversion impact |
| Internal exposure | Candidate works for employees or operators under observation | Broad segment performance |
| Canary rollout | Candidate is safe enough for limited visible traffic | Final business value |
| A/B experiment | Candidate changes a committed outcome under controlled assignment | Long-term lifecycle cleanup by itself |
| Full rollout | Winner can become default with a rollback window | That temporary branches can remain forever |
This stage discipline keeps an offline eval from becoming a launch permission slip. It also keeps an experiment from starting before the team has checked severe regressions.
For staged AI exposure patterns, see FeatBit's safe AI deployment, AI experimentation, and progressive rollout patterns pages.
Use Feature Flags To Preserve Assignment And Rollback
AI evals need exposure control when they move toward production. The application should evaluate a runtime flag before choosing the candidate behavior, then attach the evaluated variation to telemetry and outcome events.
OpenFeature's evaluation context specification gives vendor-neutral language for the data used during flag evaluation, including a targeting key and custom fields that can support rule-based targeting or fractional evaluation. In AI evals, that context might include account ID, environment, region, workflow, risk tier, conversation ID, or application surface.
FeatBit's role is the release-control layer around the eval:
- target internal users, beta accounts, regions, risk classes, or workflows;
- keep assignment stable by user, account, conversation, or workflow;
- ramp traffic by percentage when evidence remains healthy;
- keep baseline and fallback behavior available without redeploying;
- attach flag variation to exposure and outcome events;
- preserve an audit trail for the release decision;
- clean up temporary prompt, model, retrieval, or agent branches after the decision.
FeatBit implementation references include targeting rules, percentage rollouts, A/B testing, flag insights, and the Track Insights API.
Example: Scorecard For A Support Assistant
Imagine a team wants to replace a support assistant route. The candidate combines a new prompt, a different model route, and a retrieval reranker. The expected benefit is fewer escalations. The risks are poor account-security answers, higher latency, higher cost, and lower trust for high-value accounts.
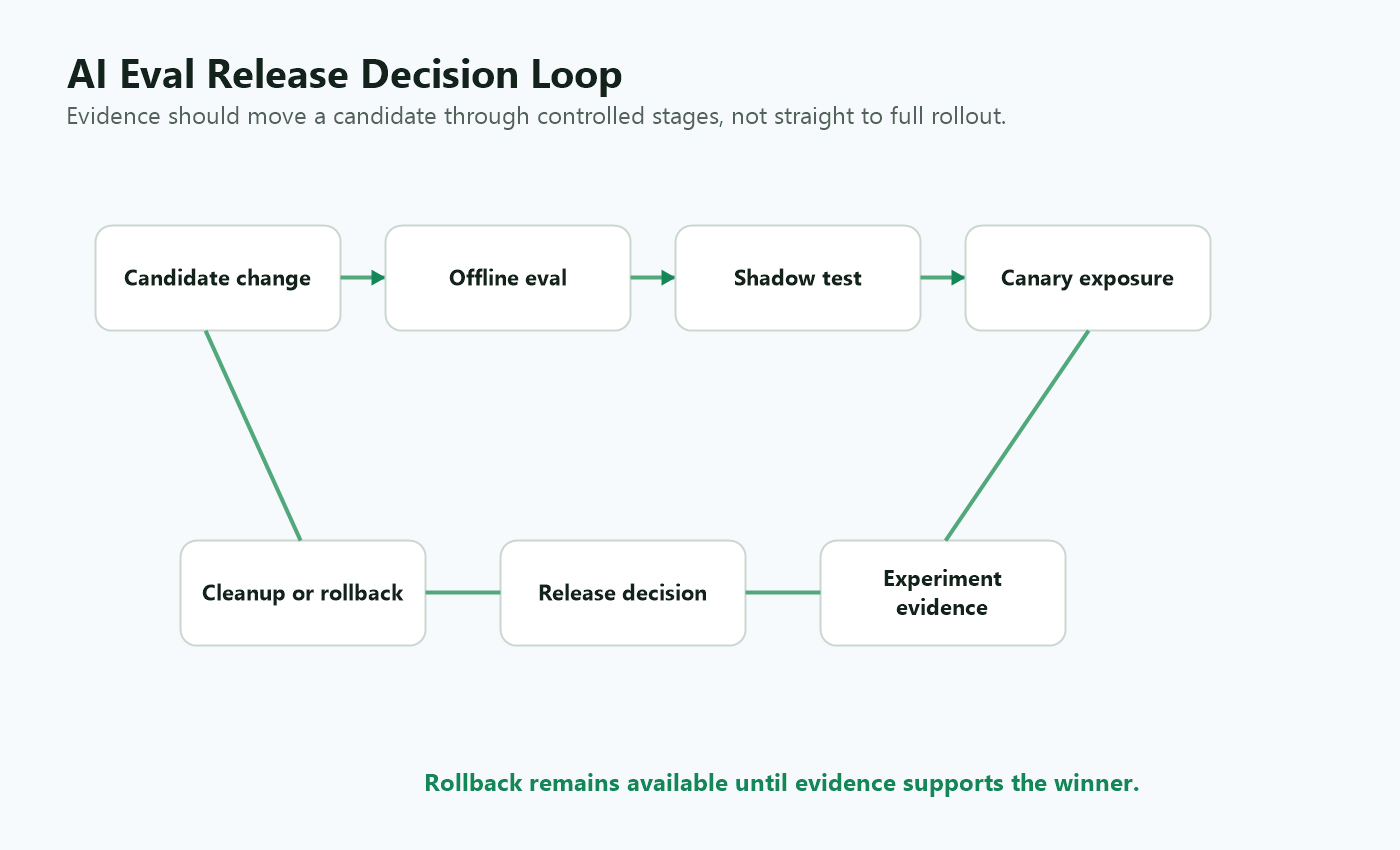
A practical scorecard would look like this:
| Decision point | Evidence required | Action |
|---|---|---|
| Candidate eligibility | Protected billing and account-security cases pass; answer format remains valid; no severe regression in human review | Move to shadow test |
| Shadow readiness | Candidate runs on production inputs without visible exposure; fallback and telemetry work; cost estimate is inside budget | Target internal users |
| Canary health | Internal users and a low-risk segment show acceptable correction rate, latency, cost, and complaint rate | Expand to limited experiment |
| Experiment readout | Resolved cases without escalation improve; guardrails remain inside limits; no severe segment harm appears | Ship winner or keep control |
| Release cleanup | Decision, owner, metric readout, and rollback window are recorded | Remove losing branch or intentionally keep operational kill switch |
This turns evals into a release workflow. The team can explain why the candidate advanced, why it stopped, or why it became the default.
Common Scorecard Mistakes
Using one quality score as the release decision. A single score can screen candidates, but it rarely captures user outcome, segment risk, cost, latency, safety, and support load.
Changing the metric after seeing the result. The primary outcome and guardrails should be written before exposure. Otherwise, the team can rationalize whichever signal looks favorable.
Mixing too many AI surfaces without naming the route. If prompt, model, retrieval, and tool policy all change together, call it a route test. Do not attribute the result to only one component.
Tracking exposure before the AI behavior runs. A page view is not an AI exposure if the candidate prompt, model route, retrieval profile, or agent strategy was never used.
Forgetting the assignment unit. Request-level randomization can corrupt conversations and multi-step workflows. Choose user, account, conversation, or workflow assignment based on the product journey.
Treating rollback as an incident-only problem. Rollback is part of the eval design. The fallback path must exist before traffic expands.
Leaving temporary eval controls behind. AI teams create many temporary prompt routes, model aliases, retrieval flags, and experiment branches. FeatBit's feature flag lifecycle management model helps keep those release controls from becoming stale production logic.
A Practical Checklist
Before an AI change reaches users, confirm:
- The release question names the candidate behavior, scope, and next stage.
- Offline evals compare the candidate against the current baseline.
- Severe regression cases are separated from average quality.
- The primary business outcome is defined before exposure.
- Guardrails cover quality, latency, cost, safety, fallback, and segment harm.
- The assignment unit matches the user journey.
- A feature flag controls candidate exposure and keeps rollback available.
- Exposure events fire only when the AI behavior actually runs.
- Outcome events can be joined to the same unit ID and variation.
- The owner, decision states, and cleanup rule are written before rollout.
Bottom Line
AI evals are most useful when they produce release decisions, not just scores.
Use offline evals to block preventable regressions. Use online evidence to understand production behavior. Use experiments to measure user and business outcomes. Use feature flags to control exposure, preserve attribution, and roll back quickly. Use a scorecard so the team knows what evidence can move an AI change from candidate to rollout, rollback, or cleanup.
That is the practical overview: AI evals should evaluate the behavior, the product outcome, and the operational risk together.
Source Notes
- OpenAI evaluation context: the OpenAI Evals API reference describes evals as testing criteria and data-source configuration that can be run against model configurations.
- AI eval terminology context: Statsig's AI Evals overview describes prompts, offline evals, online evals, feature gates, experiments, analytics, and LLM-as-judge grading. This article uses it as category terminology context, not as a vendor ranking.
- AI risk context: NIST's AI Risk Management Framework supports the point that AI evaluation should be tied to risk management across the AI lifecycle and context of use.
- Feature flag standard context: the OpenFeature evaluation context specification is cited for targeting keys and contextual data used during flag evaluation.
- FeatBit implementation context: safe AI deployment, AI experimentation, measurement design, progressive rollout patterns, feature flag lifecycle management, targeting rules, percentage rollouts, A/B testing, flag insights, and the Track Insights API support the workflow described here.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the article's central idea: AI evals as a release scorecard. - Use
scorecard-layers.pngnear the opening because it separates offline quality, online behavior, business outcomes, guardrails, and release control. - Use
metric-contract.pngin the scorecard section because it visualizes the contract that should exist before evals run. - Use
release-decision-loop.pngnear the support assistant example because it shows how scorecard evidence becomes rollout, rollback, or cleanup.