AI-Native Experimentation and Feature Flags: Evaluate AI Changes Without Guessing
AI-native experimentation is the operating model for evaluating AI changes after they leave the notebook but before they become the default experience. It connects feature flags, controlled exposure, exposure events, outcome metrics, quality guardrails, and rollback decisions so teams can test prompts, model routes, retrieval settings, and agent behavior under real production conditions.
That makes it broader than a normal A/B test and narrower than "let AI ship faster." The useful reader job is: "How do we expose an AI change safely, measure whether it improves quality and business outcomes, and decide whether to continue, pause, roll back, or make it permanent?"
Feature flags are the control plane for that job. They decide who sees which AI behavior, keep assignment stable, let operators reduce exposure without redeploying, and preserve the release memory needed to learn from the result.
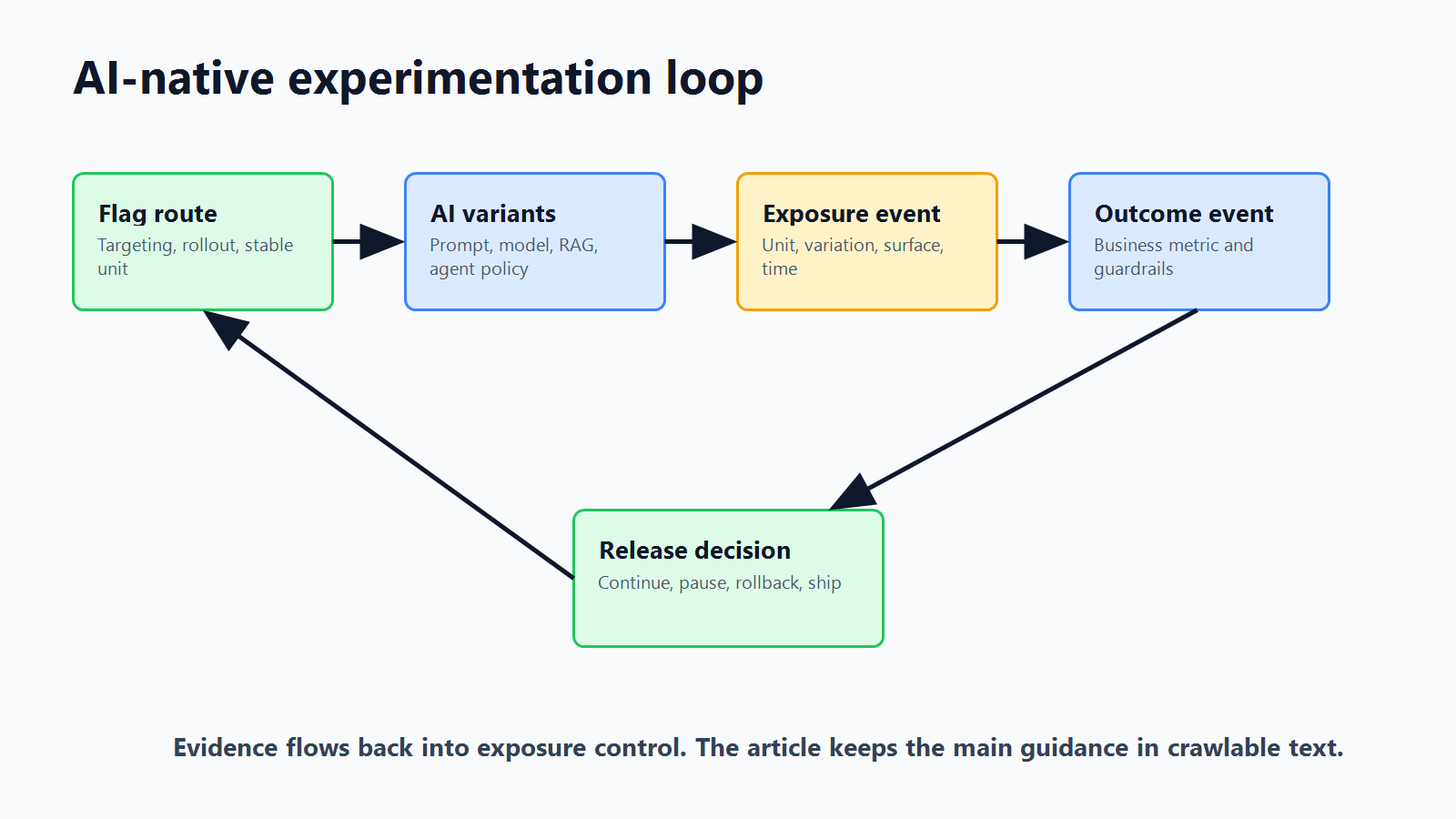
What Makes Experimentation AI-Native
Traditional experimentation often compares two user-interface changes or one product flow against another. AI-native experimentation compares behavior that may come from several runtime surfaces:
| AI change surface | Example variant | Why a flag helps |
|---|---|---|
| Prompt | concise answer prompt versus step-by-step prompt | change behavior without redeploying the service |
| Model route | current model versus candidate model | target eligible traffic and roll back quickly |
| Retrieval | baseline index versus new reranker | isolate retrieval changes from prompt changes |
| Tool policy | read-only agent versus approval-required write mode | expand autonomy only after evidence |
| Agent strategy | single-step workflow versus planner-executor workflow | compare task success and operational risk |
| Configuration | conservative temperature versus higher exploration | keep fallback settings available |
The shared pattern is not "AI" as a buzzword. It is runtime variability. AI teams need to evaluate behavior that can change without a full deployment, and that behavior needs the same release discipline as product code.
GrowthBook's AI-native development page is a useful category signal: it frames agents as participants in the release process that can create flags, run experiments, conclude winners, and clean up stale code through MCP or REST. FeatBit's angle is similar at the control-plane level but more focused on release-decision infrastructure: every AI decision point should have exposure control, measurement, auditability, and rollback before it reaches broad traffic.
Start With The Release Decision, Not The Variant
Do not start with "test a better prompt" or "try the new model." Start with the decision the experiment must support.
release_decision:
question: should the support assistant use the new retrieval profile by default?
candidate_change: rerank answers with support-reranker-v2
current_behavior: baseline keyword and embedding search
expected_outcome: more sessions resolved without human escalation
eligible_scope: English support chat for paid accounts
decision_window: 14 days
fallback_behavior: baseline retrieval profile
This keeps the experiment from drifting into a demo. The team knows the production behavior being evaluated, who is eligible, what outcome matters, how long the decision window lasts, and what rollback means.
FeatBit's release decision framework uses the same loop: intent, hypothesis, reversible exposure, measurement, evidence, decision, and learning. AI-native experimentation applies that loop to prompts, models, RAG profiles, tools, and agent strategies.
Use Feature Flags For Stable Assignment
An AI experiment needs stable assignment. If the same user, account, conversation, or workflow receives different behavior every time the model is called, the result becomes hard to interpret and the experience may feel inconsistent.
Choose the assignment unit before exposure starts:
| Assignment unit | Good fit | Watch out for |
|---|---|---|
| User | personal assistants, copilots, search, recommendations | one user may perform unrelated task types |
| Account | B2B assistants, admin workflows, enterprise support | fewer units can slow the decision |
| Conversation | chat, tutoring, support, onboarding | returning users may enter another variation later |
| Workflow | multi-step agents, code generation, review automation | events need a clear workflow ID |
| Request | stateless ranking or backend routing | users may notice inconsistent behavior |
In FeatBit, this maps to the identity used during flag evaluation. The application evaluates the flag against the unit that should remain stable, then routes to the assigned AI variant.
type AiVariant = "control" | "candidate_prompt" | "candidate_retrieval";
async function resolveSupportAssistantVariant(user: {
key: string;
accountId: string;
locale: string;
}): Promise<AiVariant> {
const variation = await featbit.variation("support-ai-experiment", {
key: user.accountId,
custom: {
userKey: user.key,
locale: user.locale,
},
}, "control");
return variation as AiVariant;
}
The flag is not the experiment analysis by itself. It is the exposure control. It gives the team a deterministic way to assign traffic, target eligible segments, narrow exposure, and fall back to the control behavior.
Design Metrics That Catch AI Tradeoffs
AI changes rarely improve or degrade one dimension at a time. A candidate prompt may increase completion, but also increase latency. A new model route may improve answer quality, but cost too much for lower-value workflows. A more autonomous agent may finish tasks faster, but create more support escalations when it is wrong.
Use one primary outcome and several guardrails.
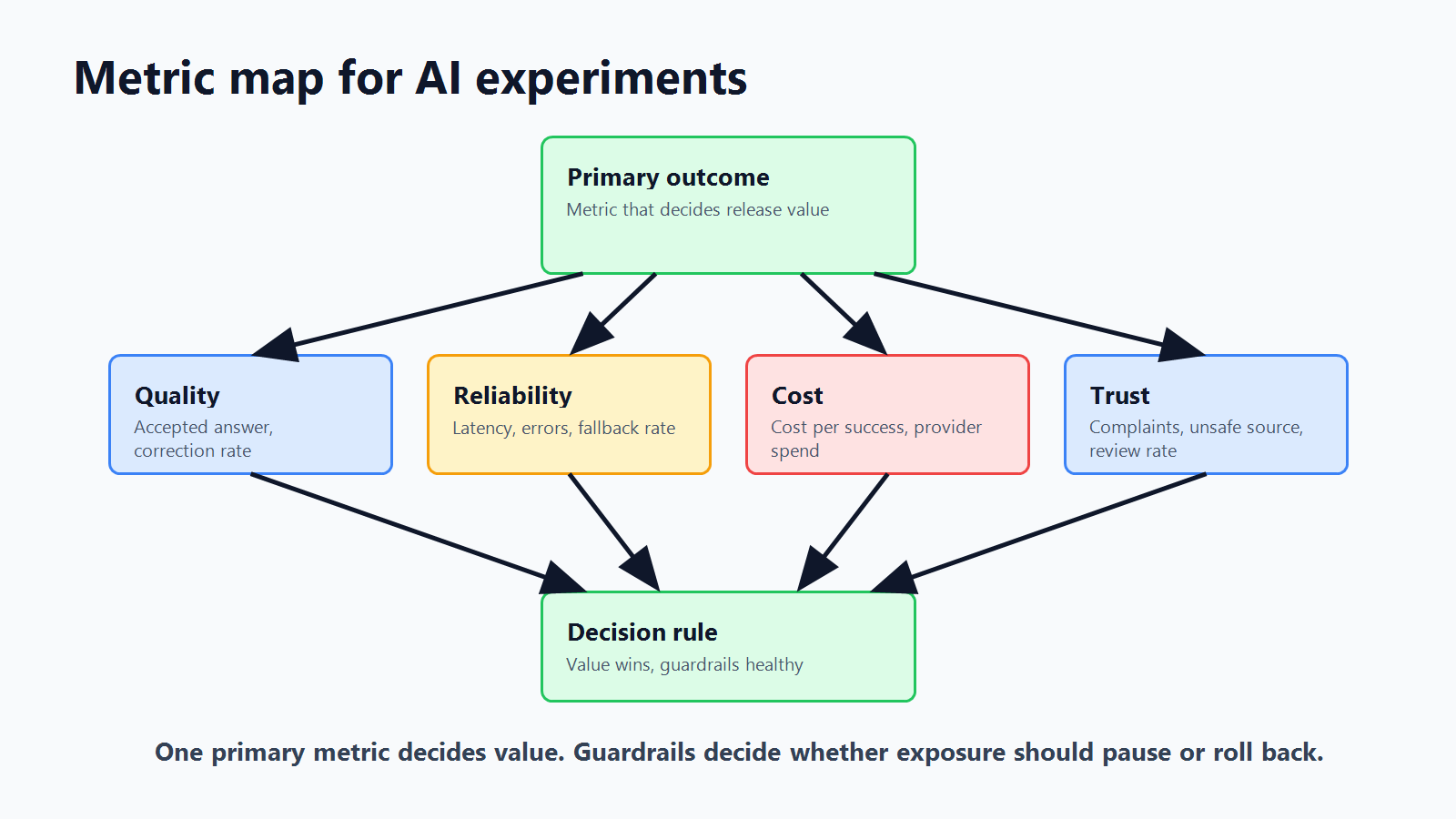
| Experiment | Primary outcome | Guardrails |
|---|---|---|
| Prompt variant | accepted answer or task completion | hallucination review rate, user correction rate, latency |
| Model route | successful task per session | cost per success, provider errors, fallback rate |
| Retrieval profile | resolved search or accepted citation | no-result rate, citation failure, unsafe source rate |
| Agent tool mode | workflow completed without human takeover | approval queue size, wrong-tool rate, incident count |
| Autonomy level | time to completion | reversal rate, operator intervention, customer complaint rate |
FeatBit's measurement design guidance is useful here because it separates the metric that decides the release from the metrics that stop expansion. That distinction prevents teams from shipping an AI change that wins one dashboard while harming reliability, cost, or trust.
Connect Exposure Events To Outcome Events
An AI-native experiment needs an exposure event whenever the production system actually uses the assigned AI behavior. It also needs outcome events later in the journey.
{
"event": "ai_exposure",
"experimentKey": "support-ai-experiment",
"unitId": "account_1842",
"variation": "candidate_retrieval",
"surface": "retrieval_profile",
"timestamp": "2026-06-02T09:15:30Z"
}
{
"event": "support_resolution",
"experimentKey": "support-ai-experiment",
"unitId": "account_1842",
"variation": "candidate_retrieval",
"resolvedWithoutEscalation": true,
"latencyMs": 1860,
"estimatedCostUsd": 0.012
}
The key is joinability. The exposure and outcome events need the same experiment key, stable unit ID, and variation. Without that connection, the team may still have telemetry, but it will not have decision evidence.
FeatBit implementation paths for this include targeting rules, percentage rollouts, experimentation, and the Track Insights API. OpenFeature's flag evaluation specification also calls out detailed evaluation metadata as useful for telemetry, troubleshooting, and advanced integrations, which matters when AI behavior needs an evidence trail.
Add Guarded Agent Participation
AI-native experimentation may include AI agents in two different roles:
- The agent is the product behavior being tested.
- The agent helps operate the release process.
Keep those roles separate. An agent can draft a hypothesis, create a flag proposal, prepare an event schema, query experiment status, or summarize stale flags. It should not silently expand a production experiment, conclude a winner, or clean up flag code without the same permissions, approval workflow, environment scoping, and audit trail that apply to human operators.
That boundary is especially important for MCP-connected workflows. The official Model Context Protocol security guidance emphasizes consent, authorization boundaries, and protection against unsafe tool use. For feature flags and experiments, those concerns are not abstract. A tool call can change production exposure.
Use this operating model:
| Agent action | Default posture |
|---|---|
| Draft experiment brief | allowed with review |
| Propose flag variations | allowed with review |
| Create a non-production flag | allowed for authorized environments |
| Change production targeting | approval required |
| Expand traffic percentage | approval required and guardrail checked |
| Conclude winner | human decision or policy-approved workflow |
| Remove stale experiment code | pull request with tests and review |
FeatBit's AI control layer and AI experimentation pages cover this broader runtime-control model. The practical rule is simple: agents can accelerate the workflow, but the production control plane still needs deterministic policy.
Choose The Right Decision State
An AI experiment should not end with a vague "looks good." Use decision states that map to operator action.
| Decision state | Meaning | Action |
|---|---|---|
| Continue | evidence is healthy but not complete | keep or expand exposure within the plan |
| Pause | telemetry, sample, or guardrail quality is not reliable | stop expansion and fix the measurement gap |
| Rollback candidate | guardrails show material harm | reduce exposure or return to control |
| Ship winner | primary outcome improves and guardrails are acceptable | make the winner default and schedule cleanup |
| Inconclusive | result does not support a confident change | keep control, redesign, or run a better-scoped test |
The decision state should be visible in the release record. It tells engineering whether to keep code paths, product whether the hypothesis held, operations whether rollback remains needed, and future teams why the decision happened.
For statistical interpretation, FeatBit's Bayesian A/B testing for builders offers a builder-friendly decision frame. The exact statistics method matters less than the operational discipline: decide what evidence will change the release before the experiment starts.
Avoid Common AI Experimentation Failures
Testing too many AI surfaces at once. If the prompt, model, retrieval profile, and tool policy all change together, the experiment becomes a route test. That can be valid, but name it honestly and avoid attributing the result to only one component.
Using offline evals as the release decision. Offline evals qualify a candidate. Production experiments decide whether users and business outcomes improve under real conditions.
Ignoring fallback behavior. If the candidate silently falls back to control during provider errors, the experiment may look safer than it is. Track fallback rate as a guardrail.
Randomizing at the wrong level. Request-level randomization can corrupt multi-turn user experiences. Match the unit of assignment to the product journey.
Letting the experiment flag become permanent debt. When the winner ships, record the decision, keep an operational kill switch only if needed, and clean up temporary experiment branches. FeatBit's feature flag lifecycle management guidance helps teams separate temporary experiment flags from permanent operational controls.
A Practical Setup Checklist
Before exposing an AI change, confirm:
- The candidate passed offline review or evaluation for severe failures.
- The release hypothesis names the behavior, audience, expected outcome, and decision window.
- The feature flag represents the runtime decision being tested.
- The assignment unit is stable for the user journey.
- Targeting excludes ineligible accounts, regions, or workflows.
- Exposure events are emitted when the AI behavior is actually used.
- Outcome events can be joined to exposure events.
- The primary metric and guardrails are defined before traffic starts.
- Rollback rules are explicit and available to the release owner.
- Agent actions, if used, pass through permissions, approval, and audit controls.
- The experiment has a cleanup plan after the decision.
AI-native experimentation is not a new label for ordinary A/B testing. It is a release-control loop for AI behavior. Use feature flags to expose AI variants deliberately, use metrics and guardrails to judge quality and business impact, and use the decision record to ship, pause, roll back, or learn without guessing.
Source Notes
- Category terminology: GrowthBook's AI-native development page, feature flag product page, and experimentation product page are cited as primary vendor context for agent-ready flags, experimentation, and rollout terminology. They are not used as a vendor ranking.
- Feature flag standard context: OpenFeature's flag evaluation specification is cited for detailed evaluation metadata and telemetry relevance.
- Agent tool safety context: the Model Context Protocol security best practices are cited for consent, authorization, and unsafe tool-use considerations around agent-operated workflows.
- FeatBit implementation context: AI experimentation, AI control layer, release decision framework, measurement design, Bayesian A/B testing for builders, feature flag lifecycle management, targeting rules, percentage rollouts, experimentation, and the Track Insights API support the operational pattern described in this article.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it represents the flag-controlled AI experimentation loop without relying on text inside the image. - Use
experiment-loop.pngnear the opening because it shows the relationship among feature flag assignment, AI variants, exposure events, metric evidence, and release decisions. - Use
metric-map.pngin the metrics section because it reinforces the primary outcome versus guardrail distinction in a way that complements the crawlable text.