GrowthBook AI Experimentation: A Release-Control Evaluation Guide
If you searched for GrowthBook AI experimentation, you are probably trying to understand how GrowthBook connects feature flags, experimentation, product metrics, and AI-assisted workflows, or you are comparing it with another release-control platform before standardizing on a stack.
The useful question is not only "Does GrowthBook support AI experiments?" GrowthBook's public AI software page describes controlled experiments for comparing models and measuring satisfaction, latency, cost, and custom product metrics. The stronger buyer question is: "Can our team control AI exposure, collect trustworthy evidence, roll back precisely, and clean up temporary experiment controls after the decision?"
This guide turns the GrowthBook-specific query into a vendor-neutral evaluation checklist. It uses GrowthBook's public pages as source context, then explains how to compare the same workflow against FeatBit's release-decision model.
What GrowthBook Publicly Emphasizes For AI Experimentation
GrowthBook positions itself as an open-source platform for feature flags, experimentation, and product analytics. Its experimentation product page emphasizes warehouse-native experimentation, custom SQL metrics, decision frameworks, guardrails, and experiment workflows across feature flags, visual editor changes, and URL redirects.
For AI-specific use cases, GrowthBook's AI software page says teams can run controlled experiments comparing model providers or routes and measure outcomes such as satisfaction, latency, cost, and custom metrics. Its agent-ready development page describes AI agents creating flags, configuring ramp schedules, setting up experiments, monitoring running experiments, concluding winners, and cleaning up stale flags through MCP or REST.
GrowthBook's docs also connect the core release-control primitives. The feature flag documentation describes flags as a way to control application behavior without deploying new code, target users, gradually roll out changes, and run A/B tests on client or server code.
Those are useful category signals. They show that GrowthBook's AI experimentation message is not only prompt testing. It is a combination of feature flags, metric analysis, data warehouse context, rollout control, and agent-accessible operations.
The Evaluation Question For Platform Teams
For engineering leaders and platform teams, the decision is less about a vendor label and more about the operating model around AI behavior.
AI experimentation can involve:
| AI change | Example release decision | Why normal deployment is not enough |
|---|---|---|
| Prompt variant | Should support answers use the new prompt by default? | A prompt can improve clarity while increasing corrections or escalation. |
| Model route | Should paid accounts move from the baseline model to a candidate model? | Model quality, latency, cost, and provider errors can diverge by segment. |
| Retrieval profile | Should the assistant use a new reranker for product docs? | Better recall may come with worse citation quality or higher latency. |
| Agent tool policy | Should an agent move from draft-only to approval-required write mode? | Tool authority changes blast radius, audit needs, and rollback precision. |
| AI configuration | Should a more exploratory setting be enabled for a workflow? | A configuration win in one task family can be unsafe in another. |
An AI experimentation platform should help the team answer four release questions:
- Who is eligible to see the candidate behavior?
- What evidence will decide whether it expands, pauses, rolls back, or ships?
- Can operators stop only the risky behavior without redeploying the whole application?
- What happens to the losing variant, temporary flag, event schema, and decision record after the experiment?
FeatBit's point of view is that these are release-decision questions. Experimentation is not separate from rollout control. The flag controls exposure, the metrics create evidence, rollback limits blast radius, and lifecycle management prevents yesterday's experiment from becoming tomorrow's stale branch.
A Practical Checklist For GrowthBook AI Experimentation
Use this checklist when evaluating GrowthBook, FeatBit, or any feature flag and experimentation platform for AI work.

| Evaluation area | What to ask | Why it matters |
|---|---|---|
| Controlled surface | Can the platform control prompt, model, retrieval, tool policy, fallback, or product feature variants as separate decisions? | AI failures are easier to contain when each risky behavior has its own control point. |
| Assignment unit | Can you randomize by user, account, conversation, workflow, or another stable unit? | Request-level randomization can corrupt multi-turn AI experiences and weaken experiment evidence. |
| Targeting context | Can rollout rules use environment, account, plan, region, risk class, workflow, and internal-user attributes? | AI behavior often needs segment-specific eligibility before broad exposure. |
| Metric design | Can primary outcomes, secondary metrics, and guardrails be defined before traffic starts? | A model can improve one metric while harming cost, latency, quality, or trust. |
| Exposure evidence | Can exposure events be joined to outcome events by variation and stable unit? | Without joinable evidence, a dashboard cannot support a release decision. |
| Rollback precision | Can operators reduce exposure or return to baseline without redeploying? | AI degradation often needs containment before root-cause analysis is complete. |
| Agent access | Can AI agents propose or operate changes through reviewed, permissioned APIs or MCP workflows? | Agent speed is useful only when permissions, approvals, and audit remain deterministic. |
| Lifecycle ownership | Can temporary experiment flags, stale code paths, and losing variants be reviewed and cleaned up? | AI teams create many temporary controls; unmanaged controls become release debt. |
| Deployment model | Does the control plane fit your cloud, self-hosted, privacy, data-location, and cost expectations? | Experiment events, flag state, metrics, and audit history may become sensitive operational data. |
The checklist deliberately avoids ranking vendors. A team already standardized on GrowthBook may value warehouse-native analysis and agent-ready workflows. A team evaluating FeatBit may prioritize release-decision control, self-hosted ownership, open-source deployment, lifecycle governance, and one release-control layer for conventional and AI changes. The right comparison depends on the operating model your team is trying to run.
Where FeatBit Fits In The Same Buyer Journey
FeatBit is an open-source feature flag and experimentation platform focused on release control: targeted rollout, progressive delivery, experimentation, rollback, observability, auditability, and lifecycle ownership.
For AI experimentation, FeatBit's relevant role is the runtime control layer:
- evaluate a flag before the application selects a prompt, model route, retrieval profile, agent mode, or fallback path;
- target internal users, beta accounts, low-risk segments, or a small percentage of production traffic;
- keep assignment stable for the user, account, conversation, or workflow being tested;
- connect flag variations to exposure events, outcome events, guardrails, and operational telemetry;
- reduce exposure or return to the baseline when guardrails fail;
- record the release decision and clean up temporary experiment branches.
The same pattern applies to non-AI releases. That is important for platform teams that do not want one control plane for standard product features and a separate control plane for AI behavior. FeatBit's AI experimentation, AI control layer, safe AI deployment, and feature flag lifecycle management pages explain the broader operating model.
For implementation, FeatBit's docs on targeting rules, percentage rollouts, experimentation, Track Insights API, and flag insights are the practical primitives behind the release loop.
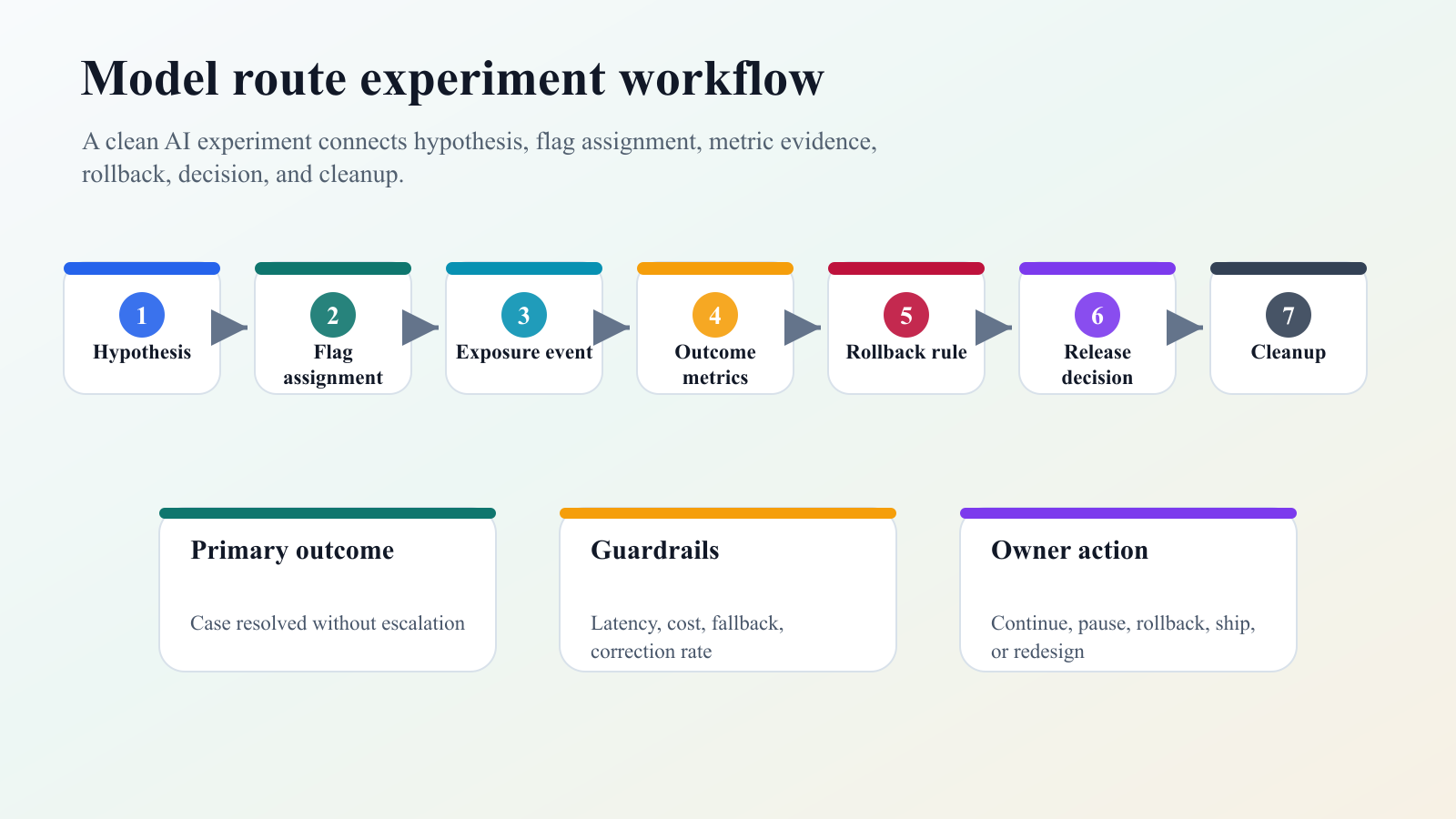
Example: Comparing A Model Route Experiment
Imagine a support product wants to compare a baseline model route with a candidate route for paid-account support conversations.
The experiment should not begin with "try the new model." It should begin with a release hypothesis:
release_hypothesis:
question: should paid-account support chat use candidate_model_route by default?
current_behavior: baseline_model_route
candidate_behavior: candidate_model_route
assignment_unit: account_id
eligible_scope:
environment: production
segment: paid_accounts
workflow: english_support_chat
primary_outcome: case_resolved_without_escalation
guardrails:
- p95_latency
- cost_per_resolved_case
- fallback_rate
- human_correction_rate
- complaint_rate
rollback_when:
- telemetry_missing
- severe_quality_failure
- guardrail_breach
cleanup:
after_decision: promote_winner_or_remove_losing_route
The platform evaluation then becomes concrete:
| Workflow step | What the platform must support |
|---|---|
| Candidate setup | Define baseline and candidate routes as clear variations, not informal config values. |
| Eligibility | Exclude internal risk, unsupported regions, high-priority incidents, or accounts without enough telemetry. |
| Assignment | Keep the same account in the same variation during the decision window. |
| Exposure | Emit an exposure event when the model route actually runs. |
| Outcome | Join support resolution, latency, cost, correction, fallback, and complaint signals to the same variation. |
| Decision | Decide continue, pause, rollback, ship winner, or inconclusive before rewriting the metric goal. |
| Cleanup | Remove the losing branch or convert the winning route into the default with a deliberate rollback control. |
This is where feature flags and experimentation meet. The feature flag does not prove the model is better. It controls who receives each route and labels the evidence. The experiment analysis does not roll back production by itself. It gives the release owner evidence for a controlled action.
Questions To Ask Before Choosing A Platform
Bring these questions to a GrowthBook demo, a FeatBit evaluation, or an internal build-versus-buy discussion:
- Which AI behavior surfaces will the platform control: prompt, model, retrieval, tool policy, fallback, or full workflow?
- Which identity should be stable for each experiment: user, account, conversation, session, workflow, or request?
- Where are exposure and outcome events stored, and can the team inspect how metrics are calculated?
- Which guardrails stop expansion even if the primary outcome improves?
- Who can change production targeting, ramp schedules, and experiment decisions?
- Can agent-created changes enter a review queue instead of changing production silently?
- What audit trail shows who changed behavior, when it changed, and which segment was affected?
- Can the platform run in the deployment model your data and operations require?
- How are stale AI experiment flags, losing routes, and obsolete event names detected and cleaned up?
The answers matter more than the vendor phrase "AI experimentation." A platform is useful when it makes the release decision more explicit, not when it only adds another dashboard.
Common Mistakes In AI Experimentation Evaluations
Treating AI experimentation as only model comparison. Model routes matter, but AI releases may also change prompts, retrieval, tools, autonomy, fallback, and product flow. The platform should match the real control surface.
Ignoring rollback until after launch. If the baseline route is not available at runtime, the team may need a deployment during an incident. Design rollback before exposure.
Changing metrics after the experiment starts. Diagnostic metrics can be added, but the primary decision metric and guardrails should be defined before traffic begins.
Letting agents bypass release governance. Agent-ready APIs and MCP tools can speed setup, but production targeting, experiment conclusion, and cleanup still need permissions, review, and audit.
Forgetting lifecycle ownership. AI experiment flags often control prompts, model aliases, retrieval profiles, and event schemas. Cleaning up only the flag record is not enough if obsolete AI assets remain reachable.
Bottom Line
GrowthBook AI experimentation is best evaluated as a release-control workflow, not only as a vendor feature name.
Use GrowthBook's public material to understand its emphasis on feature flags, warehouse-native experimentation, product metrics, and agent-ready operations. Then evaluate the same workflow against your actual production needs: controlled AI surfaces, stable assignment, trustworthy metrics, rollback precision, agent governance, deployment model, and lifecycle cleanup.
For FeatBit teams, the operating model is direct: every AI change that can affect production behavior should be targetable, measurable, reversible, and owned through cleanup. That is how experimentation becomes a release decision instead of a dashboard exercise.
Source Notes
- GrowthBook vendor context: GrowthBook's experimentation product page, AI software page, agent-ready development page, feature flag product page, and feature flag documentation are used for public positioning, feature flag, experimentation, metric, AI model comparison, and agent workflow context. This article does not make performance, security, pricing, or market-ranking claims about GrowthBook.
- FeatBit implementation context: AI experimentation, AI control layer, safe AI deployment, feature flag lifecycle management, targeting rules, percentage rollouts, experimentation, Track Insights API, and flag insights support the release-control workflow described here.
- Internal reader journey: continue with AI-native experimentation and feature flags, what is an online eval flag, A/B testing LLM prompts, and A/B testing AI models.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it frames the article as a vendor-aware release-control evaluation guide. - Use
vendor-evaluation-map.pngnear the opening because it separates GrowthBook source context, platform criteria, and FeatBit evaluation without hiding the main guidance in the image. - Use
evaluation-checklist.pngin the checklist section because it reinforces the criteria readers can use during vendor evaluation. - Use
model-route-workflow.pngin the example section because it shows how a model route experiment moves from hypothesis to cleanup.