GrowthBook vs Statsig for AI Experiments: How to Choose the Right Operating Model
If you are comparing GrowthBook vs Statsig for AI experiments, the useful question is not "Which vendor has more experiment features?" The useful question is: which operating model can help your team evaluate AI changes against quality, business outcomes, cost, latency, and release risk without losing rollback control?
GrowthBook and Statsig both connect feature flags with experimentation, but they emphasize different paths. GrowthBook is strongest to evaluate when you want an open-source, warehouse-native experimentation and feature flag platform that works with your existing data and metrics. Statsig is strongest to evaluate when you want a product experimentation stack with explicit AI eval concepts, including prompts, offline evals, online evals, gates, experiments, and analytics.
For FeatBit readers, the third question is just as important: do you need a self-hosted release-control layer that keeps AI exposure, rollout evidence, audit history, and rollback authority close to your infrastructure?
Start With The AI Experiment You Actually Need
AI experiments are not all the same. A prompt wording test, a model route test, a retrieval profile test, and an agent tool-policy test can require different controls.
Before comparing vendors, write the experiment in operational terms:
| Experiment question | Example | What the platform must support |
|---|---|---|
| Prompt quality | Does prompt version B reduce support escalation? | prompt version control, exposure events, quality and outcome metrics |
| Model routing | Does model B improve task success enough to justify cost? | stable assignment, model route metadata, cost and latency guardrails |
| Retrieval change | Does a reranker improve answer acceptance? | rollout targeting, citation quality signals, rollback |
| Agent behavior | Does a tool-enabled agent complete workflows safely? | capability gates, approval modes, incident rollback, audit |
| AI product launch | Can a new AI feature expand from internal to canary to experiment? | targeting, staged rollout, metric review, cleanup |
This framing prevents a common buying mistake. A product team may say "AI experiment" when it means A/B testing a business outcome. A machine learning team may mean offline grading before exposure. A platform team may mean controlled rollout with rollback. The right vendor comparison depends on which job is primary.
What GrowthBook Brings To AI Experimentation
GrowthBook's public positioning centers on feature flags, experimentation, product analytics, open source, and a warehouse-native model. Its documentation says experimentation should sit on top of existing data and metrics, and it emphasizes data transparency, SQL visibility, local SDK evaluation, open source, and self-hosting.
For AI experiments, that points to a practical fit:
- you already trust your data warehouse or metrics layer as the experiment source of truth;
- product, engineering, and data teams want transparent analysis instead of a black-box readout;
- you need feature flags and experiments in one platform;
- open-source inspection or self-hosting is part of the evaluation;
- AI coding agents should help create flags, configure experiments, query metrics, and conclude experiment winners through APIs or MCP.
GrowthBook's AI-native development page also describes agent workflows for creating and updating feature flags, configuring ramp schedules and targeting, setting up experiments from templates, monitoring experiments, querying metrics, concluding winners, and archiving stale flags.
That makes GrowthBook especially interesting when "AI experiments" means making the experimentation platform itself agent-ready. It is less clearly positioned, from the public pages reviewed for this article, as a dedicated AI eval suite for prompt grading, offline datasets, or judge pipelines. If that is your primary requirement, validate the exact GrowthBook workflow you plan to use rather than assuming a generic A/B testing product covers the whole AI evaluation lifecycle.
What Statsig Brings To AI Experimentation
Statsig's public docs separate several related concepts. Feature gates are Statsig's term for feature flags. Its feature gate vs experiment guide says gates are a fit for gradual rollout and monitoring impact as you ramp, while experiments are a fit when you need to compare variants and quantify lift across metrics.
Statsig also has AI Evals documentation. That page describes prompts, offline evals, and online evals as components for iterating on LLM apps in production. It says prompts can represent model provider, model, temperature, and related config; offline evals grade outputs on fixed test sets before real users are exposed; and online evals grade model output in production on real-world use cases. The same docs connect AI Evals with Statsig's standard gates, experiments, and analytics.
That makes Statsig especially relevant when your comparison includes an explicit AI evaluation workflow:
- prompt and model configuration needs versioning inside the platform;
- offline grading is part of the pre-release gate;
- online grading or shadow evaluation is part of production monitoring;
- product metrics, cost, usage, and quality signals need to sit near experiment decisions;
- your team already wants a managed product experimentation and analytics platform.
There is one important caveat: the Statsig AI Evals documentation reviewed for this article says AI Evals are in beta and that Statsig is no longer accepting new beta customers. Treat AI Evals availability, packaging, and roadmap as procurement questions, not assumptions.
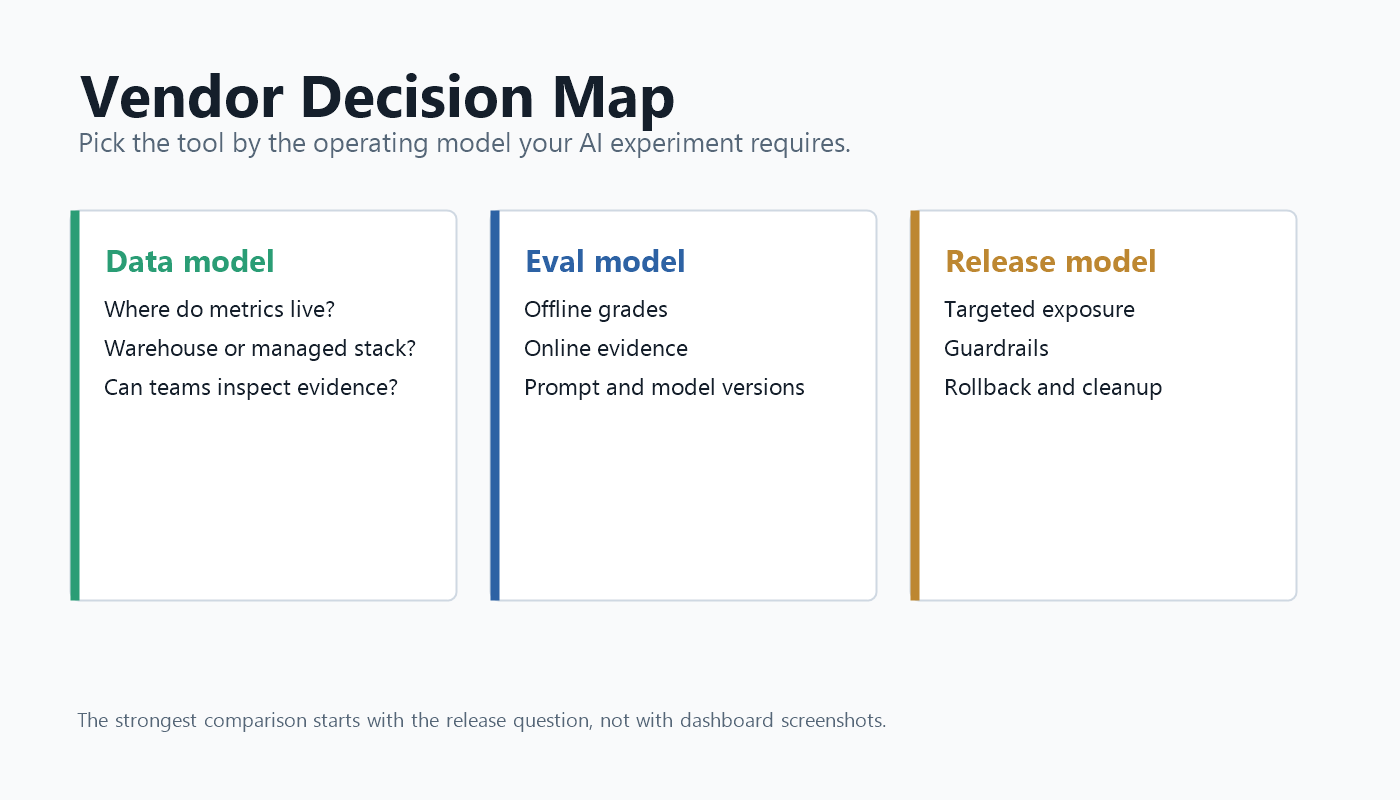
The Core Decision: Data Model, Eval Model, Or Release Model
The GrowthBook vs Statsig comparison becomes clearer when you decide which model matters most.
| Decision area | GrowthBook-leaning question | Statsig-leaning question | FeatBit release-control question |
|---|---|---|---|
| Data source | Do we want experiments on top of existing warehouse metrics and transparent SQL? | Do we want metrics, gates, analytics, and experiments in one managed product stack? | Do we need release evidence to stay close to our feature flag and rollout controls? |
| AI eval workflow | Can our team design AI evals with our current data and observability systems? | Do we need productized prompt, offline eval, and online eval concepts? | Do we need flags to control which prompt, model, retrieval, or agent strategy gets live exposure? |
| Rollout control | Do flags, ramp schedules, and experiments map cleanly to our launch process? | Do gates, experiments, and analytics map cleanly to our launch process? | Can we target, canary, roll back, audit, and clean up AI changes without redeploying? |
| Agent workflow | Do we want AI agents to operate the existing experiment platform through MCP or API? | Do we want AI workflows inside a broader product analytics and experimentation suite? | Do we want AI-assisted release operations against a self-hosted control plane? |
| Ownership | Is open source, self-hosting, or warehouse control central to the decision? | Is a managed experimentation platform with AI eval features central to the decision? | Is private deployment, auditability, and predictable control-plane ownership central to the decision? |
The table is not a ranking. It is a way to prevent a vague vendor debate from hiding the real architecture decision.
A Practical Evaluation Checklist
Use this checklist with both vendors before you request a demo or start a proof of concept.
1. What Is The Assignment Unit?
AI experiments often fail because the assignment unit is wrong. A request-level split can corrupt a chatbot test if one conversation sees multiple prompt or model variants. An account-level split can be too coarse if the product needs workflow-level evidence.
Ask each vendor how you would assign by:
- user;
- account or tenant;
- conversation;
- session;
- workflow;
- custom ID;
- environment or region.
Then ask how that assignment key appears in exposure events, outcome events, guardrail dashboards, and exportable data.
2. What Counts As Exposure?
For AI products, exposure should mean the AI behavior actually ran. A page view is not enough if the user never triggered the model call. An intended route is not enough if the candidate timed out and fell back to the baseline.
Your platform should let you record or analyze:
- evaluated variation;
- actual prompt or model route used;
- fallback state;
- latency and cost;
- quality review or grader output;
- business outcome;
- segment and risk context.
3. How Does Offline Evaluation Connect To Online Evidence?
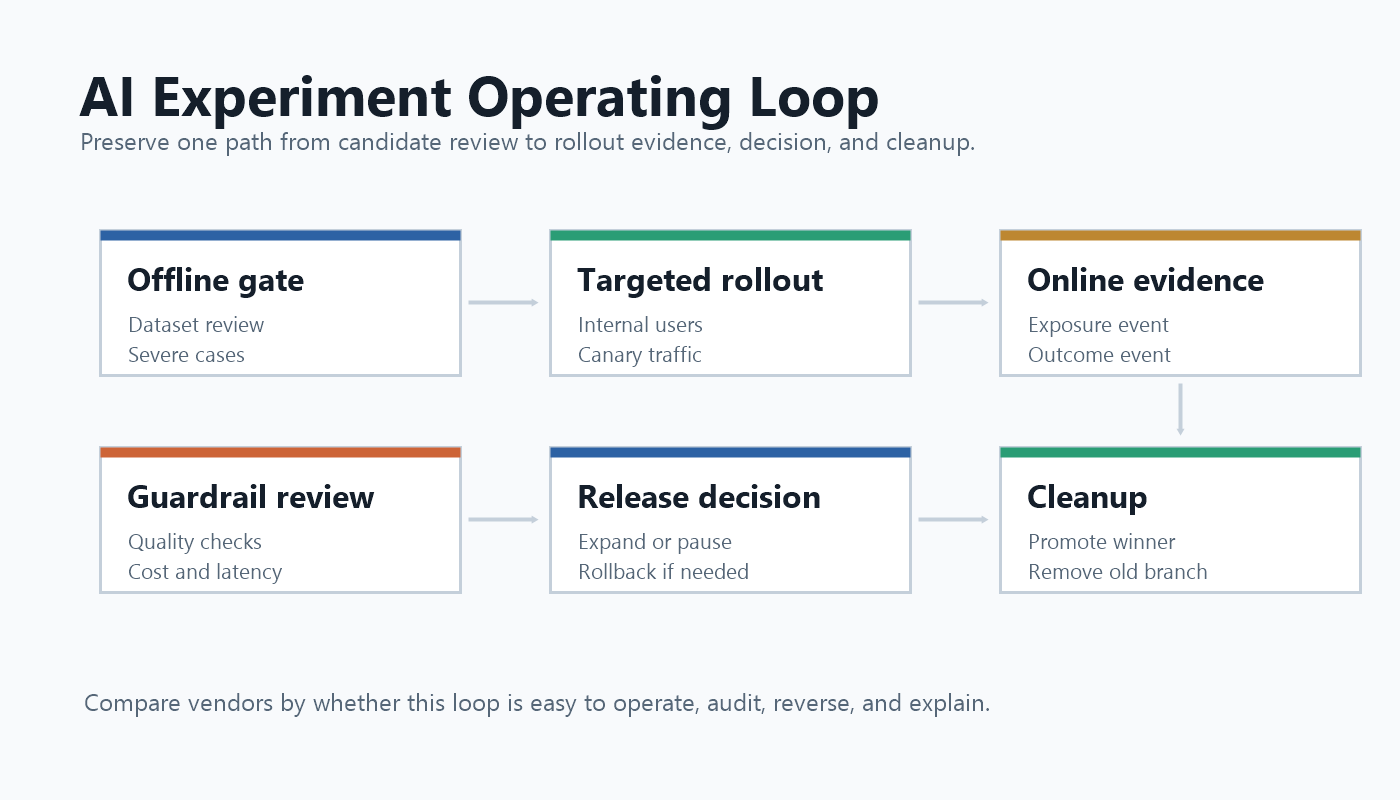
Statsig's AI Evals docs make the offline-to-online distinction explicit. GrowthBook users may connect a similar workflow through feature flags, experiments, warehouse metrics, product analytics, and external eval systems. FeatBit users can treat offline evals as gates before a feature flag expands live exposure.
The important question is continuity. The candidate that passes offline review should be the same named behavior that enters canary, experiment, outcome analysis, and cleanup.
4. Can Operators Roll Back Without Redeploying?
AI release risk is not only statistical. A model can produce a severe quality issue before the experiment reaches significance. A retrieval change can increase latency. A tool-enabled agent can create support load even if its completion rate improves.
Ask whether the platform supports:
- immediate rollback to a baseline variation;
- targeted exclusion of a segment;
- ramp down from experiment allocation to canary or internal traffic;
- audit logs for who changed exposure;
- metric or guardrail review before expansion;
- cleanup after the decision.
FeatBit's safe AI deployment and AI experimentation pages use the same release path: qualify the change, target limited exposure, measure outcomes and guardrails, then expand, pause, roll back, or clean up.

When GrowthBook May Be The Better Fit
GrowthBook may be the better first evaluation when:
- your company wants experimentation to sit on top of existing warehouse data and metric definitions;
- analysts need SQL transparency and exportable analysis workflows;
- open source, self-hosting, or code inspection is a serious requirement;
- feature flags and experiments should be tightly connected;
- AI agents should help operate the experimentation workflow through an API or MCP surface;
- you are comfortable building or integrating the AI-specific eval layer around the experimentation platform.
The proof-of-concept should test one AI change end to end: create the flag or experiment, assign the right unit, log actual exposure, join business outcomes, review guardrails, conclude the decision, and clean up stale code or configuration.
When Statsig May Be The Better Fit
Statsig may be the better first evaluation when:
- you want a managed product experimentation platform with gates, experiments, analytics, and metrics in one system;
- AI eval concepts such as prompts, offline evals, online evals, and LLM-as-judge workflows are central to the buying reason;
- product teams want quantified lift, gate monitoring, and experiment readouts in the same workflow;
- you want feature gates for rollout and experiments for multi-variant measurement;
- you are prepared to verify the current availability and packaging of AI Evals before standardizing on it.
The proof-of-concept should not stop at an eval score. Test whether the evaluated prompt or model config can move from offline review to controlled production exposure, metric attribution, rollback, and final release decision.
Where FeatBit Fits The Same Decision
FeatBit is not a copy of GrowthBook or Statsig. It is an open-source feature flag and experimentation platform with a release-control point of view. The relevant question is whether AI experimentation should be managed as release-decision infrastructure.
FeatBit is worth evaluating when:
- self-hosted or private deployment is important for feature flag data, targeting rules, audit history, or operational events;
- AI behavior needs runtime control through flags, not only analysis after the fact;
- platform teams want targeting, percentage rollout, experiments, Track Insights events, audit logs, REST APIs, and lifecycle cleanup in one release-control model;
- AI changes include prompts, model routes, retrieval profiles, tool policies, fallback modes, or agent strategies that must be targetable and reversible;
- your organization wants AI-assisted release operations but still needs human-owned approval, evidence, rollback, and cleanup.
For implementation context, start with FeatBit's docs for A/B testing with feature flags, targeting rules, percentage rollouts, and the Track Insights API. For operating model context, read feature flag lifecycle management and self-hosted feature flags.
A Vendor-Neutral Proof Of Concept
Use the same proof of concept for GrowthBook, Statsig, FeatBit, or an internal platform:
ai_experiment_poc:
release_question: should_support_assistant_use_candidate_prompt_v4
assignment_unit: conversation_id
eligible_scope:
environment: production
segment: english_support_chat
exclusions:
- high_priority_incidents
- regulated_accounts
control: prompt_v3_model_a_baseline_retrieval
candidate: prompt_v4_model_a_baseline_retrieval
offline_gate:
required_before_exposure:
- severe_case_review_passed
- hallucination_regression_checked
- fallback_path_verified
online_evidence:
exposure_event: support_assistant_prompt_exposure
primary_metric: case_resolved_without_escalation
guardrails:
- p95_latency
- estimated_cost_per_case
- human_correction_rate
- complaint_rate
- fallback_rate
release_actions:
expand: increase eligible exposure
pause: stop new candidate assignment
rollback: route all new conversations to control
cleanup: remove losing prompt branch or promote winner
Score each vendor on whether the proof of concept is natural, auditable, reversible, and understandable to the people who will own the release decision.
Common Mistakes In A GrowthBook vs Statsig Evaluation
Comparing dashboards before designing the release question. AI experiments need a hypothesis, assignment unit, metric contract, guardrails, and rollback path before the dashboard matters.
Treating AI evals and product experiments as interchangeable. Offline evals can screen a candidate. Online experiments decide whether the candidate improves real product outcomes. Both may be needed.
Ignoring fallback behavior. If candidate traffic falls back to baseline, the experiment must record that. Otherwise the candidate can look safer than it was.
Choosing a managed tool before deciding data ownership. Prompt metadata, targeting rules, audit logs, exposure events, and outcome events may be sensitive operational data. Decide whether SaaS, self-hosted, or hybrid deployment fits your requirements.
Forgetting cleanup. Prompt branches, model routes, experiment flags, event schemas, and agent policies all need an end state after the decision.
Bottom Line
Choose GrowthBook when the strongest need is open-source, warehouse-native feature flagging and experimentation that can work with your existing metrics and become agent-operable through APIs or MCP.
Choose Statsig when the strongest need is a managed experimentation and analytics stack with explicit AI eval concepts, and when current AI Evals availability matches your buying timeline.
Evaluate FeatBit when the strongest need is self-hosted release control for AI-era software: targeted exposure, staged rollout, experiment evidence, auditability, rollback, and lifecycle cleanup in a control plane your team can operate.
The best AI experiment platform is the one that keeps the release decision honest. It should show who received which AI behavior, what actually ran, which outcomes changed, which guardrails failed or held, who changed exposure, and how the team can reverse or clean up the decision.
Source Notes
- GrowthBook context: GrowthBook's documentation overview is cited for its public positioning around feature flags, experimentation, existing data and metrics, SQL transparency, open source, and self-hosting. GrowthBook's feature flag product page and AI-native development page are cited for rollout, guardrails, agent workflows, MCP, API, experiment monitoring, and stale flag cleanup claims.
- Statsig context: Statsig's AI Evals overview is cited for prompts, offline evals, online evals, and the beta availability caveat visible in the reviewed documentation. Statsig's feature gates vs experiments guide and feature flags overview are cited for gates, experiments, rollout, lift measurement, targeting, exposures, and gate lifecycle context.
- FeatBit implementation context: AI experimentation, safe AI deployment, feature flag lifecycle management, self-hosted feature flags, A/B testing with feature flags, targeting rules, percentage rollouts, and the Track Insights API support the release-control workflow described here.
- This article does not make performance, pricing, security, compliance, customer outcome, or market-ranking claims about GrowthBook or Statsig. It compares public positioning and evaluation criteria for AI experiment operating models.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the GrowthBook, Statsig, and FeatBit decision frame. - Use
vendor-decision-map.pngnear the opening because it gives readers a fast comparison path without replacing the crawlable text. - Use
ai-experiment-loop.pngin the operating-model section because it shows how offline evaluation, rollout, evidence, guardrails, decision, and cleanup connect. - Use
evaluation-checklist.pngbeside the checklist because it reinforces the concrete proof-of-concept questions buyers should ask.