Judge Models for AI Output Quality: Turn Reviews Into Release Evidence
A judge model for AI output quality is an evaluator that scores or classifies another AI system's answer. It can review whether a response followed instructions, used evidence, avoided unsafe content, cited the right source, or completed the task well enough for the product workflow. That makes it useful, but not sufficient, for release decisions.
The practical question is not "can a model grade another model?" The useful question is: can the judge produce consistent, calibrated evidence that helps a team decide whether a prompt, model route, retrieval profile, or agent policy should expand, pause, roll back, or remain under review?
This article is for platform engineers, AI product engineers, and release owners who want to use judge models without turning subjective quality review into an untrusted dashboard.
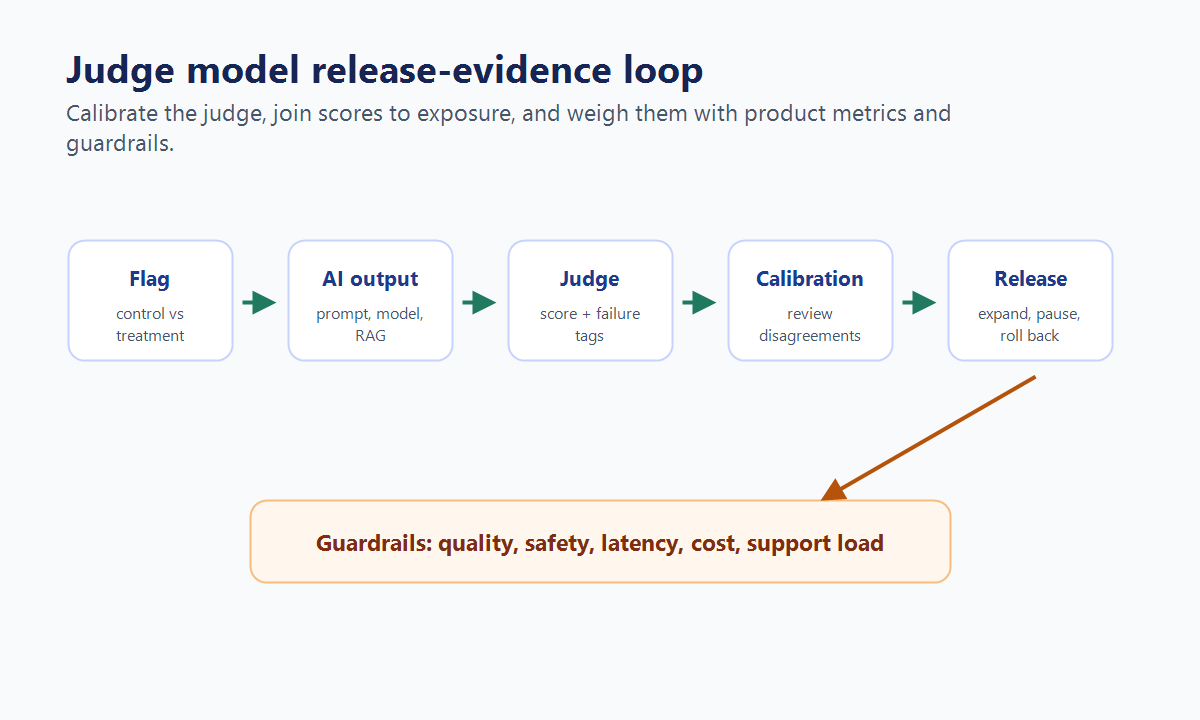
Where Judge Models Fit
AI output quality often needs more than click and conversion metrics. A user may not click a correction button even when an answer is incomplete. A support ticket may close for reasons unrelated to the model. A user can accept an answer that is fluent but unsupported.
Judge models help fill part of that gap. They can review samples at scale and produce repeatable signals such as:
| Quality dimension | Example judge question | Release use |
|---|---|---|
| Instruction following | Did the answer follow the task and format requirements? | catch prompt regressions before expansion |
| Factual grounding | Is the answer supported by retrieved or provided evidence? | detect retrieval and citation problems |
| Completeness | Did the answer cover the user's actual request? | compare prompt or model variants |
| Safety and policy | Did the output avoid disallowed or risky behavior? | block or narrow exposure |
| Helpfulness | Would the answer help the user complete the workflow? | add quality context to product metrics |
Those signals become more useful when they are tied to a controlled exposure. A feature flag can assign eligible traffic to baseline_model, candidate_model, or evidence_first_prompt. The judge can score sampled outputs from each variation. Product and guardrail metrics can then show whether the judged quality connects to real outcomes.
FeatBit's AI experimentation and safe AI deployment patterns make this a release-control loop: the flag controls exposure, the judge reviews quality, metrics show product impact, and rollback remains available while evidence is still incomplete.
Do Not Treat The Judge As The Decision Maker
A judge model is a measurement instrument. It is not the release owner.
The judge can be biased by prompt wording, rubric ambiguity, model familiarity, position effects, output length, missing context, or examples that do not match production. If the release process treats the judge score as truth, the team can ship a candidate that learned to satisfy the evaluator while harming the actual workflow.
Use the judge as one evidence source:
- offline evals qualify a candidate before exposure;
- feature flags control which users, accounts, conversations, or workflows receive the candidate;
- judge models score sampled outputs against a defined rubric;
- human reviewers calibrate the judge and inspect disagreements;
- product metrics show whether users complete the job;
- guardrails stop expansion when quality, latency, cost, safety, or support load worsens.
That framing is consistent with NIST's AI Risk Management Framework: measurement has to connect to governance and risk management, not just model scoring. In product terms, the release decision should remain a human-owned rule that weighs several signals.
Start With A Rubric, Not A Score
Do not begin by asking a judge model to return "quality: 8/10." Start with the failure modes that would change the release decision.
For a support-answer assistant, the rubric might be:
quality_rubric:
task: answer a support question using retrieved product documentation
pass_conditions:
- answers the user's specific question
- cites only provided or approved sources
- names setup steps in the correct order
- says when the evidence is insufficient
fail_conditions:
- invents product behavior
- gives steps not present in the evidence
- omits a required warning or prerequisite
- recommends an unsafe operational action
score_labels:
0: unusable or unsafe
1: major issue, should not be shown without rewrite
2: minor issue, useful with correction
3: acceptable for the workflow
The labels matter more than the numeric scale. A four-level rubric is often easier to calibrate than a ten-point score because reviewers can reason about release action: block, revise, inspect, or accept.

Connect Judge Results To Flag Variations
Judge scores become release evidence only when they can be joined back to the exposure decision.
{
"event": "ai_answer_exposure",
"flagKey": "support_answer_route",
"variation": "evidence_first_prompt",
"unitId": "conversation_4821",
"workflow": "support_chat",
"timestamp": "2026-06-03T10:15:00Z"
}
Then record the judge result with the same assignment identity and variation.
{
"event": "ai_answer_judged",
"flagKey": "support_answer_route",
"variation": "evidence_first_prompt",
"unitId": "conversation_4821",
"rubricVersion": "support_answer_quality_v3",
"judgeModel": "quality_judge_2026_06",
"score": 3,
"failureTags": [],
"requiresHumanReview": false
}
Finally, connect product outcomes and guardrails:
{
"event": "support_conversation_resolved",
"flagKey": "support_answer_route",
"variation": "evidence_first_prompt",
"unitId": "conversation_4821",
"resolvedWithoutEscalation": true,
"latencyMs": 1840,
"estimatedCostUsd": 0.021
}
FeatBit's Track Insights API, targeting rules, and percentage rollouts are the implementation side of this pattern. The flag decides exposure. The events make the quality and outcome comparison readable.
Calibrate Before You Trust The Judge
Calibration means comparing judge output against known examples and human review before using it as a release signal.
Use a small but representative calibration set:
| Sample type | Why include it |
|---|---|
| known good answers | check that the judge does not punish valid concise answers |
| known bad answers | check that obvious failures are caught |
| borderline answers | reveal rubric ambiguity |
| high-risk workflows | test whether the judge catches unacceptable failure modes |
| production samples | verify that the judge handles real user language |
Track agreement between the judge and human reviewers. More importantly, inspect disagreements. If the judge often rewards long answers, penalizes cautious answers, misses citation errors, or ignores segment-specific risk, fix the rubric and prompt before expanding the AI candidate.
For AI releases, calibration should happen at two points:
- Before exposure, use offline examples to qualify the judge.
- During limited exposure, compare judge scores against sampled human review and product outcomes.
OpenAI's Evals documentation and Google Cloud's generative AI evaluation overview are useful category references for structured evaluation. Production release control still needs exposure, telemetry, guardrails, and rollback.
Use Judge Results As Guardrails
A judge score can be a guardrail that stops expansion before a broad incident.
release_rule:
continue_when:
- accepted_answer_rate improves or remains stable
- judge_pass_rate is not worse than control
- citation_failure_rate does not increase
- p95_latency_ms remains within budget
- cost_per_resolved_conversation remains within limit
pause_when:
- judge-human disagreement rises above the review threshold
- unsafe_or_unsupported_answer_rate increases
- telemetry cannot join exposure, judge result, and outcome
rollback_when:
- severe quality failure appears in treatment samples
- treatment worsens product outcome and quality guardrails
Do not let a higher average judge score hide a serious failure tag. A candidate that improves helpfulness while introducing unsupported claims may need rollback or a narrower audience, not more traffic.
FeatBit's measurement design guidance uses the same distinction between primary metrics and guardrails. The primary metric decides whether the candidate is worth keeping. Guardrails decide when exposure should stop.
Choose The Right Assignment Unit
The assignment unit affects judge interpretation. If the AI behavior changes a whole conversation, judge outputs at the conversation level. If it changes a single classification call, request-level review may be enough. If it changes account-wide behavior, inspect account-level outcomes.
| AI behavior | Suggested assignment unit | Judge sample |
|---|---|---|
| support chat prompt | conversation or ticket | full thread plus final answer |
| model route for summaries | document, ticket, or task | input and generated summary |
| retrieval profile | conversation or query intent | retrieved evidence and answer |
| agent tool policy | workflow run | tool calls, final state, and user-visible output |
| recommendation copy | user or session | rendered copy and downstream action |
For multi-turn AI experiences, see conversation-level randomization for AI experiments. The core rule is the same here: judge the unit that the user actually experiences.
Operational Mistakes To Avoid
Using one generic judge for every workflow. A sales assistant, support bot, coding agent, and compliance helper need different rubrics. Reuse structure, not blind scoring prompts.
Hiding the rubric from reviewers. If humans cannot understand what the judge is scoring, they cannot calibrate or challenge it.
Reviewing only treatment outputs. Always compare control and treatment. A candidate may look weak in isolation but still improve a known baseline, or look strong while control performs better.
Letting judge prompts drift without versioning. Record the rubric version and judge model version. Otherwise score changes can be mistaken for product changes.
Counting judge score as exposure. Exposure happens when the user or workflow receives the AI behavior. Judging is a downstream measurement event.
Skipping rollback design. If a judge guardrail fails, the team needs a flag state that can quickly reduce or stop treatment exposure.
How FeatBit Fits
FeatBit does not replace model-evaluation frameworks, human review tools, observability, or product analytics. It connects those systems at the release-control point.
A team can use FeatBit to:
- assign traffic to prompt, model, retrieval, or agent-policy variations;
- target internal users, beta accounts, regions, workflows, or risk tiers;
- expand exposure through percentage rollout;
- record exposure and metric events;
- connect judge results to variations and outcomes;
- reduce exposure or roll back when quality guardrails fail;
- clean up temporary evaluation flags after the decision.
That is the difference between "the judge liked the new model" and "the candidate improved the release metric, stayed inside quality guardrails, matched human calibration, and can safely expand."
Setup Checklist
Before using a judge model for AI output quality, confirm:
- The AI behavior under review is controlled by a reversible flag or equivalent release gate.
- The rubric names pass conditions, fail conditions, and release actions.
- Human reviewers have calibrated the judge on representative examples.
- Exposure events include flag key, variation, assignment unit, and workflow.
- Judge results include rubric version, judge model version, score, and failure tags.
- Product outcomes and guardrails can be joined to the same unit.
- Control and treatment are both sampled.
- Severe failure tags can stop expansion even when the average score improves.
- Rollback can reduce treatment exposure without redeploying.
- The judge, rubric, flag, and temporary branches have an owner and cleanup path.
Judge models are useful when they make AI release evidence more readable. They are risky when they become an unreviewed substitute for judgment. Keep the evaluator calibrated, connect it to flag exposure and product outcomes, and let the release decision weigh the full evidence.
Source Notes
- FeatBit implementation context: AI experimentation, safe AI deployment, AI control layer, measurement design, conversation-level randomization for AI experiments, targeting rules, percentage rollouts, and the Track Insights API.
- AI risk framing: NIST's AI Risk Management Framework supports the article's recommendation to connect quality measurement with governance and risk management.
- Evaluation category context: OpenAI's Evals documentation and Google Cloud's generative AI evaluation overview are cited for structured AI evaluation concepts. They are not substitutes for production exposure and outcome telemetry.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes judge models as part of a release-evidence loop. - Use
judge-release-loop.pngnear the opening because it shows how flag assignment, judge review, human calibration, guardrails, and release decisions connect. - Use
rubric-calibration.pngin the rubric section because it supports the reader's calibration task while keeping the actual rubric in crawlable text.