Custom Judges for AI Evaluation: What to Compare Before You Buy or Build
Custom judges are reusable evaluators that score AI outputs against criteria your team defines. They are useful when generic accuracy, relevance, or toxicity checks are not enough to decide whether a prompt, model route, retrieval profile, or agent workflow should keep receiving production traffic.
The buyer question is not only "Does the platform have custom judges?" The stronger question is: can the judge score become reliable release evidence? A custom judge should connect a rubric, production context, sampling rule, metric key, rollout state, rollback rule, and cleanup path. Without that connection, the team has another score, but not necessarily a safer AI release process.
This article treats "custom judges" as a vendor and category term. LaunchDarkly's public documentation describes custom judges for online evaluations in AI Configs, including attaching judges to config variations and recording numeric evaluation results as AI metrics. OpenAI documents graders as evaluation mechanisms that can return grades from 0 to 1, and MLflow documents custom LLM judges for domain-specific evaluation criteria. Those references show the category direction: AI evaluation is moving from offline test reports toward production release decisions.
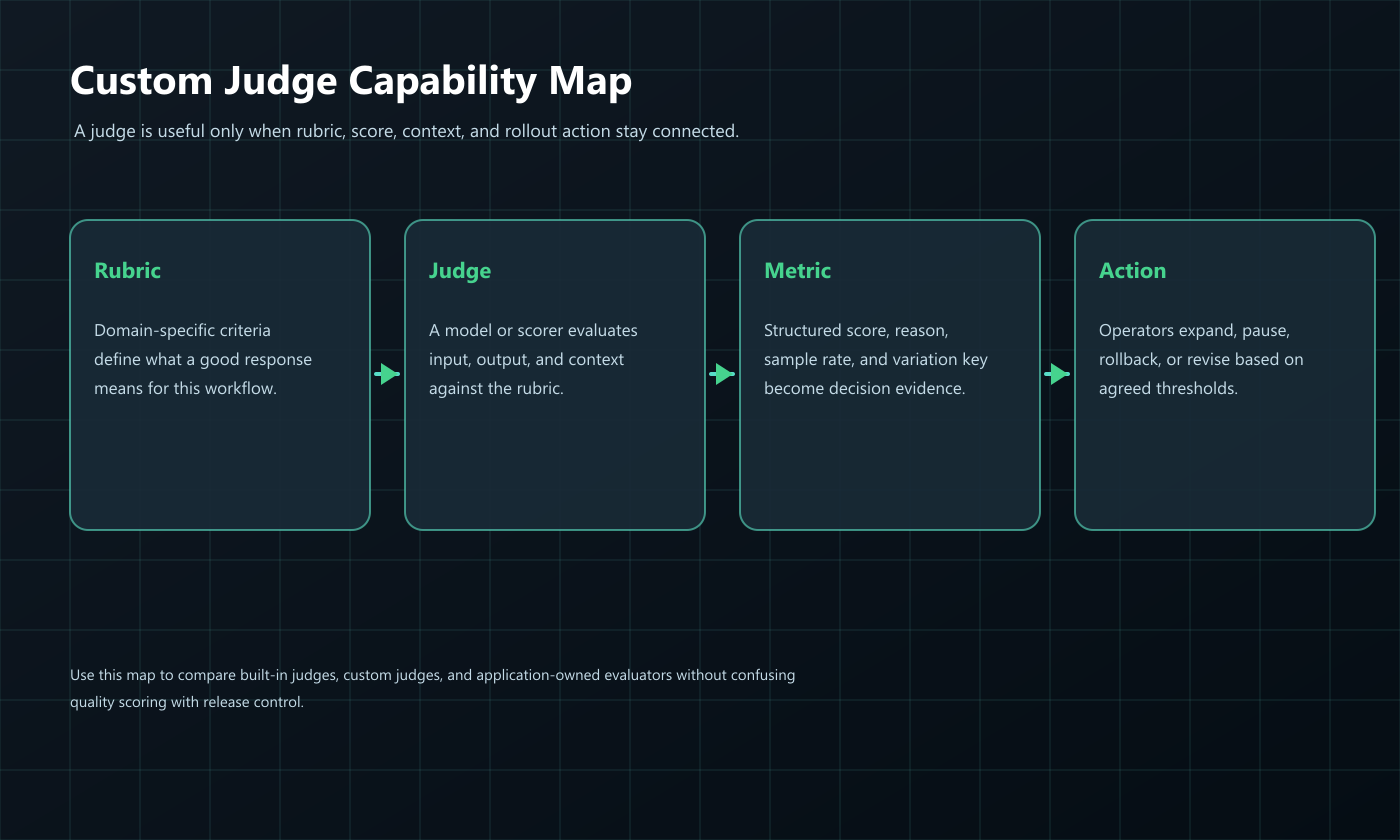
What A Custom Judge Should Decide
A custom judge should answer a narrow quality question in a repeatable way.
Good examples:
- Did the support assistant answer using the approved refund policy?
- Did the generated SQL include unsafe write operations?
- Did the agent choose the correct tool for the user's intent?
- Did the response include a grounded citation from the retrieved sources?
- Did the summary preserve the obligations, owner, deadline, and exception in the source text?
Weak examples:
- Is the answer good?
- Does the model seem better?
- Can we launch this agent?
The second group is too vague for a release decision. A judge prompt can turn those questions into a score, but the score will be hard to interpret because no one agreed on the behavior, scope, threshold, or action.
Use this minimum contract before you rely on a custom judge:
| Field | Why it matters |
|---|---|
| Evaluated behavior | Names the prompt, model route, retrieval profile, tool policy, or agent workflow being judged. |
| Rubric | Defines what the judge should reward, penalize, or ignore. |
| Input context | Provides user request, retrieved documents, tool traces, expected policy, or reference answer when needed. |
| Output format | Produces a structured score, category, pass/fail result, and brief reason. |
| Sampling rule | Decides which live outputs get judged and avoids uncontrolled cost growth. |
| Metric key | Lets monitoring, experiments, and rollout decisions refer to the same signal. |
| Release action | Says what score trend should expand, pause, roll back, or trigger human review. |
This is why FeatBit frames evaluation as part of release-decision infrastructure. The judge evaluates behavior. The release system controls exposure, records evidence, and decides what changes next.
What LaunchDarkly's Custom Judge Language Signals
LaunchDarkly's custom judges documentation is useful category evidence because it makes the production connection explicit. The docs describe judges as AI Configs in judge mode, explain that judges can be attached to config variations, and state that evaluation results appear as standard AI metrics.
Several details matter when you compare this capability:
| Publicly documented detail | Evaluation takeaway |
|---|---|
| Judges evaluate responses only when attached to a config variation that receives live traffic. | A judge is not only an offline grader. It depends on production exposure and variation assignment. |
| Evaluations respect a configured sampling percentage. | Sampling is part of the cost, latency, and signal-quality design. |
| Evaluation results are structured as numeric scores with reasoning. | The release team needs a consistent score shape, not free-form comments only. |
| Programmatic judge evaluation can evaluate arbitrary input and output pairs. | Custom pipelines still need explicit metric tracking if the platform does not automatically record those results. |
| Judge scores can be used as metrics in monitoring, guardrails, and experiments. | The judge is useful when it feeds an action, not when it sits in a separate dashboard. |
This is not a claim that every team should buy that specific product. It is a sign that "custom judges" are becoming part of the same operating layer as AI configs, online evaluation, experiments, and guarded rollout.
Custom Judges Are Not The Whole Eval Stack
A judge score can be valuable and still incomplete.
OpenAI's graders documentation describes graders that compare reference answers with model-generated answers and return grades. MLflow's custom judges documentation describes custom LLM judges for complex, domain-specific criteria. Those are evaluation primitives. They help teams define and run scoring logic.
Production AI releases need more than scoring:
| Capability | Question it answers |
|---|---|
| Offline evals | Is the candidate good enough to test beyond curated examples? |
| Custom judges | Does the output satisfy our domain-specific quality criteria? |
| Online eval flags | Which live users, accounts, conversations, or workflows receive the candidate? |
| Experiments | Did the candidate improve the committed product outcome? |
| Guardrails | Is the candidate hurting latency, cost, safety, trust, or support load? |
| Rollback | Can we return to baseline without a redeploy? |
| Lifecycle cleanup | What happens to losing prompts, model aliases, and temporary flags after the decision? |
For a broader category map, see FeatBit's guide to AI evals and release decisions. If the specific runtime object is unclear, the companion explainer on online eval flags defines how live AI exposure connects to evidence and rollback.
How FeatBit Fits When The Judge Runs Elsewhere
FeatBit does not need to be the system that runs the LLM judge for the release workflow to work. In many architectures, the application, eval service, model gateway, or observability pipeline owns the judge. FeatBit can still provide the production control layer around it:
- target the candidate behavior to internal users, beta accounts, regions, workflows, or risk tiers;
- assign traffic stickily to a prompt, model route, retrieval profile, or agent strategy;
- ramp exposure by percentage when judge scores and guardrails remain healthy;
- roll back to baseline or fallback behavior without redeploying the application;
- attach variation identity to custom metric events and experiment evidence;
- preserve audit history for who changed rollout state and when;
- keep temporary release controls on a lifecycle path after the decision.
FeatBit's AI experimentation, measurement design, and progressive rollout patterns pages describe the release-decision side of that workflow. Implementation primitives include targeting rules, percentage rollouts, A/B testing with feature flags, and the Track Insights API.
If your team needs private infrastructure, data locality, or control over the release-control layer, FeatBit's self-hosted feature flag platform may also be part of the evaluation.
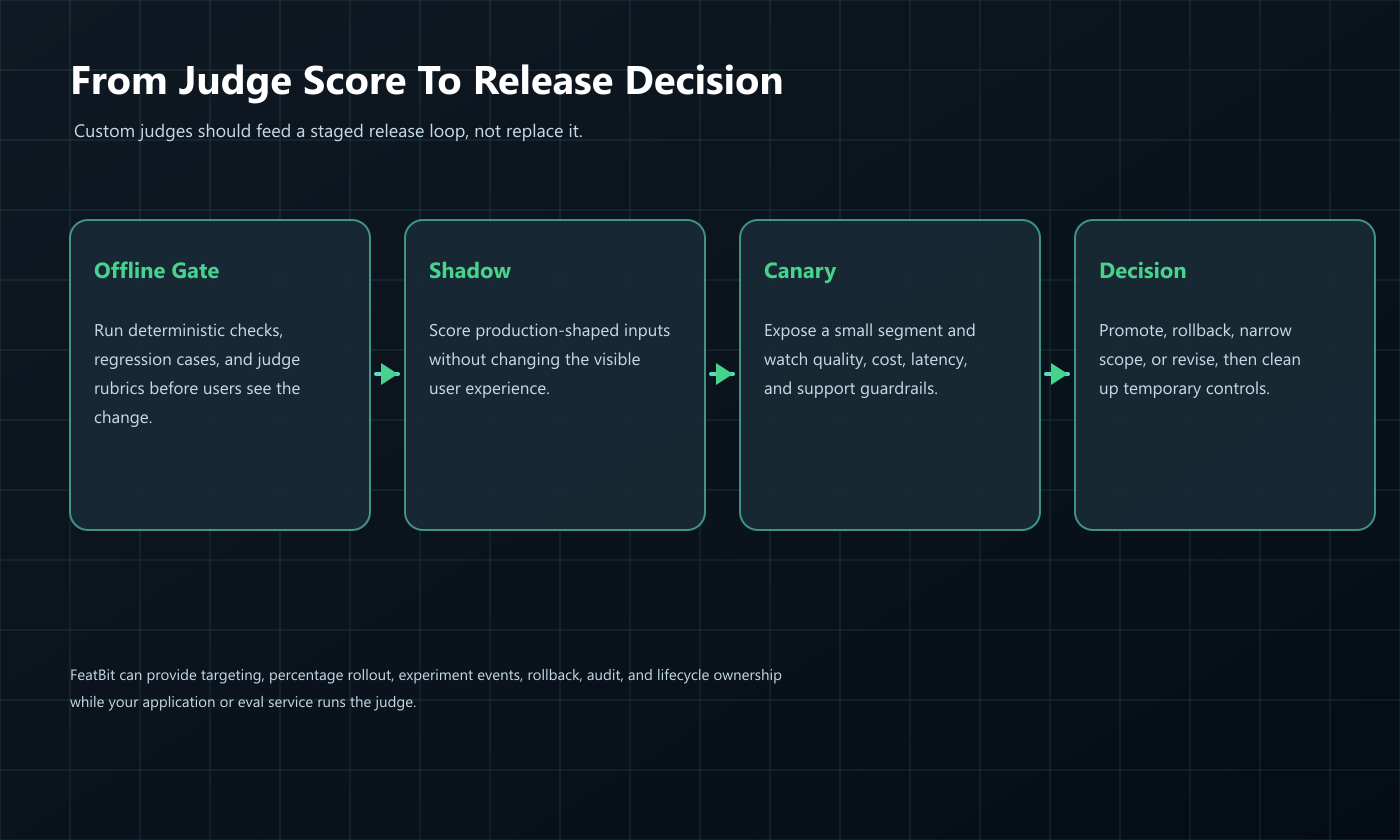
A Practical Architecture For Custom Judge Evidence
A production custom judge workflow usually has five moving parts.
- The application evaluates a runtime flag before it chooses the AI behavior.
- The AI system runs the assigned behavior: prompt, model route, retrieval profile, tool policy, or agent strategy.
- The application or eval service sends the input, output, context, and expected evidence to the judge.
- The judge returns a structured score and short reason.
- The telemetry path records both the flag variation and the judge result so rollout decisions can use them together.
In pseudocode, the shape looks like this:
type AiRoute = {
promptVersion: string;
modelRoute: string;
retrievalProfile: string;
};
const route = await flags.getJson<AiRoute>(
'support_assistant_route',
userContext,
{
promptVersion: 'support_v3',
modelRoute: 'baseline',
retrievalProfile: 'standard'
}
);
const output = await supportAssistant.respond({
route,
userQuestion,
accountContext
});
const judgeResult = await qualityJudge.evaluate({
rubric: 'refund_policy_grounding_v1',
input: userQuestion,
output,
context: accountContext
});
await trackMetric({
flagKey: 'support_assistant_route',
variation: route.modelRoute,
metricKey: 'refund_policy_grounding_score',
value: judgeResult.score,
reason: judgeResult.reason
});
The exact SDK calls will differ by stack. The important point is the join: the release owner must be able to see which variation ran, what the judge scored, which users or workflows were affected, and what action the score should trigger.
What To Compare In A Custom Judge Capability
Use the following checklist when comparing a vendor feature, open-source tool, or internal implementation.
| Area | Questions to ask |
|---|---|
| Rubric control | Can teams define domain-specific criteria, version the rubric, and test it before production use? |
| Judge model choice | Can the team choose or constrain the model that performs grading, and document why it is suitable? |
| Context inputs | Can the judge inspect retrieved sources, tool traces, expected outputs, policy text, or reference answers? |
| Structured output | Does the judge return a machine-readable score, category, pass/fail signal, and reason? |
| Human alignment | Can teams compare judge decisions with expert review and repair weak rubrics? |
| Sampling and cost | Can evaluation run at a controlled sample rate and avoid judging every low-risk output? |
| Online attachment | Can judge results connect to the exact variation, user context, and production output? |
| Experiment use | Can judge scores become guardrails or secondary metrics without replacing the primary product outcome? |
| Rollback action | Can low scores pause, narrow, or roll back exposure through an explicit release workflow? |
| Audit and governance | Who can change judges, rubrics, rollout percentages, and metric thresholds? |
| Data boundary | Where do prompts, outputs, traces, and judge reasons travel, and who stores them? |
| Cleanup | Does the system help remove temporary judges, prompt branches, and flags after the release decision? |
The best custom judge capability is not always the most flexible prompt editor. It is the one that makes evaluation evidence operational: understandable, controlled, auditable, and tied to a decision.
Design The Judge Around The Release Stage
Custom judges behave differently at each stage of an AI release.
| Stage | What the judge can do | What it should not decide alone |
|---|---|---|
| Offline gate | Catch known regressions before any user exposure. | Whether broad production rollout is safe. |
| Shadow test | Score production-shaped inputs without changing the visible experience. | Whether users prefer the candidate. |
| Internal exposure | Help operators inspect real behavior under observation. | Whether every customer segment is safe. |
| Canary | Watch quality drift while a small segment sees the candidate. | Whether the candidate wins the business outcome. |
| A/B experiment | Serve as a guardrail or secondary quality metric. | The whole release decision if the primary outcome worsens. |
| Full rollout | Monitor regressions after promotion. | Whether temporary experiment logic can stay forever. |
This stage discipline prevents a common mistake: using a high judge score as permission for full rollout. A judge can say an answer appears grounded, concise, or policy-compliant. It cannot by itself prove that users trust the answer, support tickets resolve faster, cost remains acceptable, or a high-risk segment is unaffected.
Common Mistakes With Custom Judges
Making the rubric too broad. "Helpful response" is not a release metric. Use a specific criterion such as "answer cites the current refund policy and does not invent refund exceptions."
Letting the judge see too little context. If the judge cannot inspect retrieved documents, tool traces, or expected policy, it may reward fluent but unsupported answers.
Treating judge reasoning as ground truth. The reason is useful for debugging, but the team should still sample results against human review, especially for high-impact workflows.
Using one score to replace outcome metrics. A support assistant can receive a better quality score while increasing escalations. Keep judge scores beside product metrics and guardrails.
Ignoring sampling bias. If only easy cases are judged, the score will look stable while risky cases remain invisible. Sampling should reflect the release risk.
Forgetting rollback. A judge that detects quality regression after exposure expands is only useful if operators can reduce exposure quickly.
Leaving judge-era controls behind. After the decision, remove losing prompt branches, retire obsolete judge rubrics, or convert the control into an intentional long-lived operating flag. FeatBit's feature flag lifecycle management model helps keep release evidence from becoming stale control logic.
When To Buy, Build, Or Combine
Buy a platform-native custom judge capability when your team already uses that platform for AI configuration, wants a managed UI for judges, and benefits from built-in metric recording, guardrails, and experiment integration.
Build or extend your own judge service when your rubric needs application-specific context, private traces, custom model routing, human review alignment, or integration with an existing observability pipeline.
Combine both when the platform handles standard online evaluation, while application-owned evaluators handle specialized workflows such as regulated support, internal code generation, pricing recommendations, or agent tool use.
In all three cases, keep release control explicit. A custom judge should not become a hidden launch authority. It should produce evidence that a release owner can use to continue, pause, roll back, or clean up.
Next Step
If you are evaluating custom judges because an AI behavior is close to production, start by writing the release contract:
custom_judge_release_contract:
behavior: support_assistant_refund_answer
candidate: prompt_v4_model_b
baseline: prompt_v3_model_a
judge: refund_policy_grounding_v1
primary_outcome: case_resolved_without_escalation
judge_guardrail: grounding_score_below_0_75
rollout:
start: internal_users
next: five_percent_canary
experiment: account_level_ab_test
rollback: return_to_prompt_v3_model_a
cleanup: remove_losing_prompt_and_archive_temporary_flag
Then decide where each job belongs: the judge, the feature flag, the metric event, the experiment, the human review queue, and the release owner. That separation keeps "custom judges" from becoming another dashboard and turns them into usable release evidence.
Source Notes
- LaunchDarkly's custom judges documentation is cited for the vendor-specific description of judges, config variations, sampling, metric keys, structured scores, and programmatic judge evaluation.
- LaunchDarkly's online evaluations documentation is cited for the broader relationship between online evaluations, judges, AI metrics, guarded rollouts, and experiments.
- OpenAI's graders documentation is cited for the general concept of graders returning structured evaluation scores.
- MLflow's custom judges documentation is cited as an additional primary source showing domain-specific LLM judge design.
- FeatBit implementation context comes from AI experimentation, measurement design, progressive rollout patterns, targeting rules, percentage rollouts, A/B testing with feature flags, and the Track Insights API.
Image Notes
cover.pngshould represent custom judges as part of a production evaluation and release-decision workflow.judge-capability-map.pngsupports the opening explanation by showing rubric, judge, metric, and release action as separate jobs.judge-release-loop.pngsupports the FeatBit section by showing how judge evidence moves through offline gates, shadow testing, canary exposure, and cleanup.