Model Benchmark vs Real-User Outcome: What to Do When They Disagree
When a model wins an offline benchmark but loses on real-user outcomes, treat the mismatch as a release investigation, not a debate about which signal is more legitimate. The benchmark said the candidate was eligible for exposure. The production outcome is telling you whether the change works in your product, for your users, under your latency, cost, safety, and workflow constraints.
The useful response is to pause expansion, verify the measurement path, isolate the segment or workflow where the gap appears, and decide whether to roll back, reroute, or update the benchmark. A model benchmark should screen candidates. A real-user outcome should decide production release.
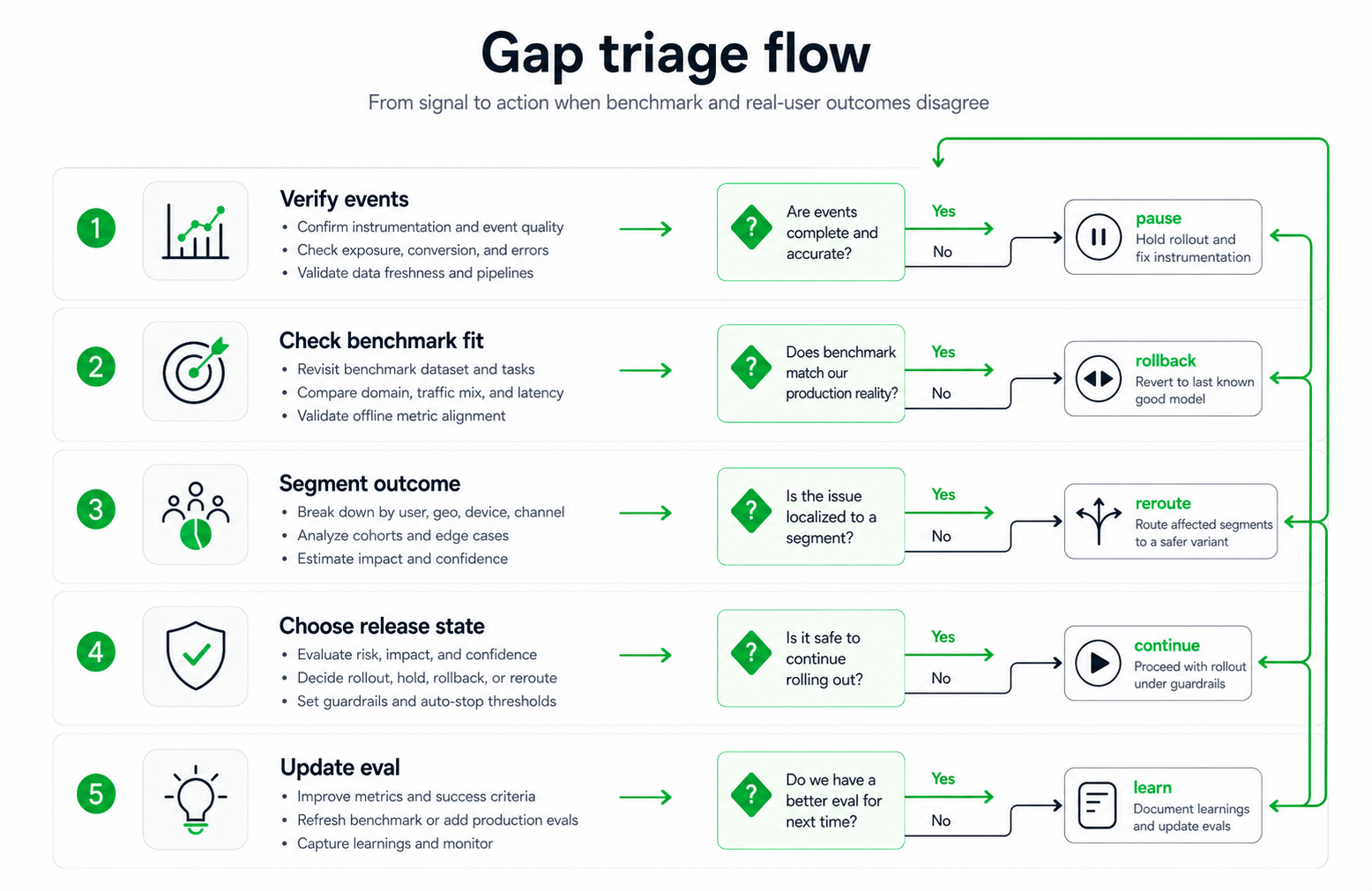
The Short Answer
If benchmark performance and real-user outcomes disagree, start with this order:
- Confirm exposure and outcome events can be joined by user, account, session, workflow, and variation.
- Check whether the benchmark measured the same task, traffic mix, language, latency budget, and failure severity as production.
- Segment the outcome by cohort, workflow, prompt family, retrieval path, fallback behavior, and model route.
- Decide whether the current release state should continue, pause, roll back, or become a narrower follow-up experiment.
- Feed the discovered production failure back into the benchmark or offline eval suite.
Do not keep expanding traffic because the benchmark score is higher. Do not discard the benchmark because one online metric moved in the wrong direction. Use both signals for their proper job.
Why The Gap Happens
Benchmarks compress reality so teams can compare models repeatably. Production expands reality back out.
MLCommons frames benchmark work as representative benchmark suites for AI and ML evaluation, and Stanford's HELM project describes holistic evaluation as a way to improve transparency in language model comparison. Those are useful pre-release tools. They are not a complete substitute for product-specific release evidence.
Real-user outcome gaps usually come from one of six sources:
| Gap source | What it looks like in production | What to check |
|---|---|---|
| Task mismatch | The model scores well on curated prompts but fails the actual workflow | user intent, prompt families, retrieval context, tool calls |
| Traffic mismatch | Aggregate benchmark win hides harm in one customer segment | cohort, region, language, account tier, risk profile |
| Metric mismatch | Offline quality improves but the product outcome drops | primary outcome, guardrails, delayed effects |
| System mismatch | The model works alone but fails inside the deployed stack | latency, fallback rate, provider errors, context truncation |
| Measurement mismatch | The online result is noisy or unjoinable | exposure event, outcome event, stable unit ID |
| Decision mismatch | The team treats an eligibility signal as a ship signal | release hypothesis, decision rule, rollback gate |
NIST's AI Risk Management Framework is relevant here because trustworthy AI depends on context of use. In release terms, the model is not only evaluated in the abstract. It is evaluated inside a product workflow with users, constraints, dependencies, and consequences.
First Verify The Measurement Path
Before interpreting the gap, prove that the telemetry can support the decision.
A reliable model outcome readout needs at least these fields:
{
"experimentKey": "support_answer_model_gap_check",
"unitId": "account_1842",
"variation": "candidate_model_b",
"modelRoute": "support-b-v2",
"promptVersion": "resolve-v5",
"retrievalProfile": "kb-rerank-v2",
"exposedAt": "2026-06-03T10:15:30Z"
}
And the downstream outcome event must use the same stable unit and variation:
{
"experimentKey": "support_answer_model_gap_check",
"unitId": "account_1842",
"variation": "candidate_model_b",
"event": "support_case_resolved",
"resolvedWithoutEscalation": false,
"latencyMs": 2810,
"fallbackUsed": false
}
If the exposure and outcome cannot be joined, the release state should be PAUSE, not "benchmark wins" or "real users lose." Missing measurement is a release blocker because the team cannot tell whether the model, prompt, retrieval path, fallback, or event pipeline caused the result.
FeatBit's Track Insights API, feature flag insights, and measurement design guidance fit this step: the variation assignment and the outcome event need to be designed together before exposure expands.
Read The Conflict Pattern
Once the measurement path is trustworthy, classify the conflict. Different conflicts require different release actions.
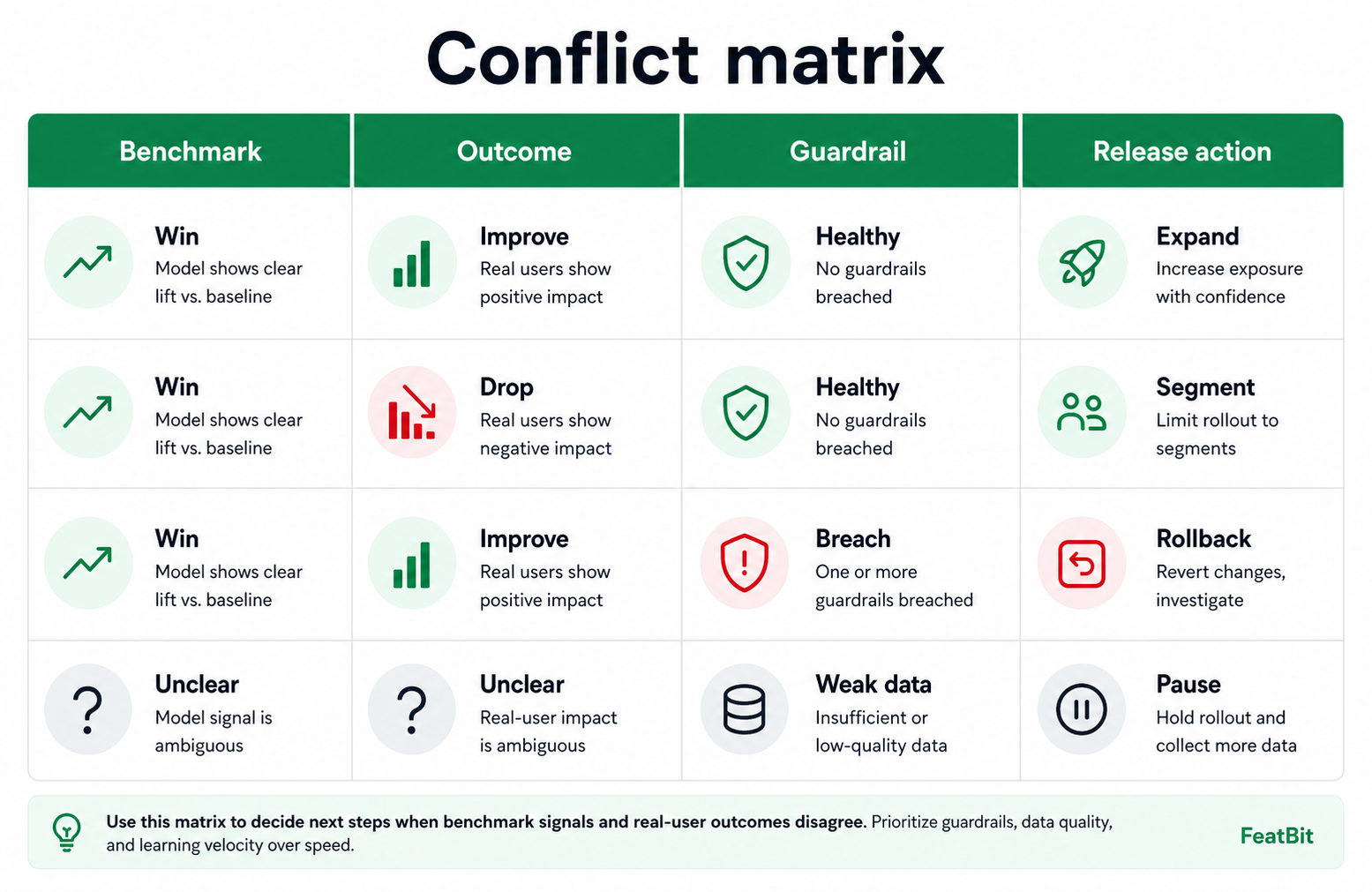
| Benchmark signal | Real-user outcome | Guardrails | Likely decision |
|---|---|---|---|
| Candidate wins | Outcome improves | Guardrails healthy | Continue or expand within the rollout plan |
| Candidate wins | Outcome drops | Guardrails healthy | Pause expansion, segment readout, inspect task mismatch |
| Candidate wins | Outcome improves | Guardrail breach | Roll back or reduce exposure until the guardrail is fixed |
| Candidate loses | Outcome improves | Guardrails healthy | Re-examine benchmark relevance before rejecting the candidate |
| Benchmark unclear | Outcome unclear | Telemetry weak | Pause and fix measurement before more exposure |
| Severe benchmark failure | Outcome not yet measured | Any state | Do not advance to user exposure |
This table is deliberately action-oriented. A dashboard that says "model B is better" is not enough. The release owner needs to know whether to continue, pause, roll back, or run a narrower follow-up.
Segment Before You Argue
Aggregate metrics often hide the reason benchmark and production disagree. Segment the production result before changing the model again.
Useful first cuts include:
- user or account cohort;
- language, locale, or region;
- product workflow or journey step;
- prompt family and prompt version;
- retrieval profile and source set;
- model route and fallback route;
- latency bucket and provider error path;
- human review, correction, or override event;
- high-risk versus low-risk task class.
Suppose a support model wins an offline troubleshooting benchmark but reduces resolved cases without escalation. The aggregate result is only the starting point. The real issue might be that the model performs well on short English tickets but times out on long enterprise logs. It might answer more confidently but trigger more human corrections. It might improve quality while increasing latency enough that users abandon the session.
Each explanation changes the release action. A language-specific problem may need targeted rollback. A latency problem may need a routing or cost guardrail. A prompt-family problem may need a narrower benchmark update.
Use Feature Flags To Keep The Investigation Reversible
The worst time to discover a benchmark gap is after the candidate model has become the only production path. Keep model routes behind runtime controls until the decision is stable.
A FeatBit flag can represent the model decision surface:
flag:
key: support_answer_model
type: string
variations:
- current_model
- candidate_model_b
- fallback_model
release_state:
canary: 5_percent_low_risk_accounts
investigation: candidate_model_b_paused_for_enterprise_log_workflows
rollback: current_model
That gives the team several practical options:
| Investigation need | Runtime control |
|---|---|
| Stop expanding the candidate | freeze the percentage rollout |
| Protect a harmed segment | target that segment back to control |
| Keep learning in low-risk traffic | continue a smaller canary |
| Compare a fixed prompt or route | add a controlled variation |
| Recover quickly | route traffic to the fallback model without redeploying |
| Preserve accountability | keep an audit record of rollout changes |
FeatBit's AI experimentation, safe AI deployment, targeting rules, and percentage rollouts pages expand this operating model. The point is not that a flag proves the model is good. The flag keeps the release decision controllable while the team gathers evidence.
Update The Benchmark With Production Learning
When production reveals a real gap, the benchmark should get better. Do not only change the model route and move on.
Turn the investigation into benchmark inputs:
| Production finding | Benchmark or eval update |
|---|---|
| Harm in one language or region | add representative tasks for that cohort |
| High correction rate on long context | add long-context failure cases |
| User abandonment from latency | add latency and timeout constraints to eligibility |
| Retrieval source errors | add source-quality and citation checks |
| Fallback masking model failures | track fallback rate as a guardrail |
| Human override spike | include review rework in the online outcome |
OpenAI's Evals documentation is a useful example of structured model evaluation before production exposure. The release lesson is that evals should evolve from production evidence. A benchmark that never absorbs real-user failure cases will keep certifying candidates that fail the same way.
A Practical Triage Runbook
Use this runbook when a model benchmark win and a real-user outcome diverge.
| Step | Owner | Decision |
|---|---|---|
| Freeze expansion | release owner | keep current exposure or reduce to a safe cohort |
| Verify event joins | data or platform engineer | pause if exposure and outcome are not joinable |
| Inspect guardrails | engineering lead | roll back if latency, cost, safety, or reliability breaches |
| Segment the outcome | product and analytics | identify harmed or benefiting cohorts |
| Compare with benchmark coverage | AI or platform engineer | decide whether benchmark coverage is stale or incomplete |
| Choose release state | product and engineering | continue, pause, rollback candidate, or inconclusive |
| Update eval suite | AI or platform engineer | add production failure cases and constraints |
| Close flag lifecycle | flag owner | clean up temporary routes or convert to operational control |
The last step is easy to forget. If the candidate is rolled back, archive the failed experiment path when it is no longer needed. If the candidate wins after a fix, remove temporary branches after the rollback window. FeatBit's feature flag lifecycle management guidance helps make that cleanup part of the release decision instead of an afterthought.
Common Mistakes
Treating the benchmark as a release metric. Benchmarks qualify candidates. They do not prove product impact.
Treating the online result as automatically correct. A real-user outcome can be wrong if exposure logging, outcome attribution, or stable assignment is broken.
Ignoring guardrails because the primary metric improved. A model can increase completion while making each completed task too slow, too expensive, or too risky.
Changing the model, prompt, and retrieval path together without naming the route. If several AI surfaces change at once, call it a route test and track the full route metadata.
Rolling back everyone when only one segment is harmed. A targeted rollback may preserve learning while protecting the affected cohort.
Failing to update the benchmark. Production gaps are expensive evidence. Put them back into offline evaluation so the same failure does not repeat.
The Bottom Line
A model benchmark versus real-user outcome conflict is not a failure of evaluation. It is a normal release signal.
Use benchmarks to decide which models deserve controlled exposure. Use feature flags to keep that exposure targeted, measurable, and reversible. Use real-user outcomes and guardrails to decide whether the model should continue, pause, roll back, or become the default. Then update the benchmark with what production taught you.
That is how model evaluation becomes a release-decision loop instead of a leaderboard argument.
Source Notes
- Benchmark context: MLCommons describes benchmark work as representative benchmark suites for AI and ML evaluation, while Stanford CRFM presents HELM as a living benchmark for transparent language model evaluation.
- AI risk context: NIST's AI Risk Management Framework supports the article's point that trustworthy AI assessment depends on context of use, not only generic model performance.
- Evaluation context: OpenAI's Evals API documentation is used as an example of structured pre-production model evaluation.
- Experimentation category context: GrowthBook's documentation, Statsig's feature gates versus experiments guide, Optimizely's Feature Experimentation metrics documentation, and LaunchDarkly's experiment flags documentation show the broader category pattern of connecting rollout controls with metrics. These links are not vendor rankings.
- FeatBit implementation context: AI experimentation, safe AI deployment, feature flags as release decision infrastructure, measurement design, feature flag lifecycle management, targeting rules, percentage rollouts, Track Insights API, and flag insights support the operational workflow described here.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the article's benchmark-to-outcome investigation path. - Use
gap-triage-flow.pngnear the opening because it shows the ordered response to a benchmark and outcome mismatch. - Use
conflict-matrix.pngin the conflict-pattern section because it helps readers map evidence states to release actions while the article keeps the primary guidance in crawlable text.