How to A/B Test AI Models for Business Impact
A/B testing AI models means comparing model behavior under real production traffic, with users consistently assigned to a control model or a candidate model, and judging the result by business outcomes plus guardrail metrics. It is not the same job as running an offline benchmark.
The practical question is: "If we route real users to model B instead of model A, does the product outcome improve enough to justify the cost, latency, reliability, and trust tradeoffs?"
That question needs an experiment design, not only a leaderboard. The model route must be controlled at runtime, the exposure must be logged, the outcome metric must be chosen before traffic starts, and rollback must remain available if the candidate model harms a guardrail.

Start With A Release Hypothesis
Do not begin with "we want to try a newer model." Begin with a falsifiable release hypothesis:
hypothesis:
change: route eligible support-chat sessions from current_model to candidate_model_b
expected_outcome: more sessions resolved without human escalation
user_scope: logged-in customers using English support chat
reason: candidate_model_b handles troubleshooting context better in offline evals
decision_window: 14_days
This shape matters because AI model decisions often mix engineering curiosity, product value, and operational risk. A newer model can be more capable in one task family while being slower, more expensive, or less predictable in another. The hypothesis tells everyone what the experiment is allowed to prove.
Use offline evaluation to make the candidate eligible. OpenAI's Evals documentation is a useful example of structured model evaluation before production exposure. Use the online A/B test to decide whether the candidate improves the product under real traffic.
Pick The Right Unit Of Randomization
For model A/B tests, the randomization unit is often more important than the split percentage. If the same user sees different models inside one task, the result becomes hard to interpret and the product experience may feel inconsistent.
Common units include:
| Unit | Good fit | Risk |
|---|---|---|
| User | Chat, search, writing, recommendations | one user may handle several unrelated tasks |
| Account | B2B products, admin workflows, support teams | fewer units, slower learning |
| Conversation or session | support chat, agent workflow, tutoring flow | repeated users may cross variations later |
| Request | stateless ranking or completion tasks | high risk of inconsistent experience |
| Workflow | multi-step agent tasks | needs clear start and end events |
For most user-facing AI products, start with user, account, session, or workflow assignment. Request-level assignment is useful only when the experience is truly independent per request or when the experiment is measuring a backend routing decision that users cannot perceive across requests.
In FeatBit, this is a feature flag design problem. The flag should evaluate against the identity that represents the experiment unit. For a B2B support assistant, that may be account ID. For a consumer chatbot, it may be user ID or conversation ID. The point is consistency: the same eligible unit should receive the same model variation during the decision window.
Separate Primary Metric From Guardrails
An AI model test should have one primary business metric and several guardrails. The primary metric decides whether the candidate model is worth shipping. Guardrails decide whether the experiment should pause or roll back even if the primary metric improves.
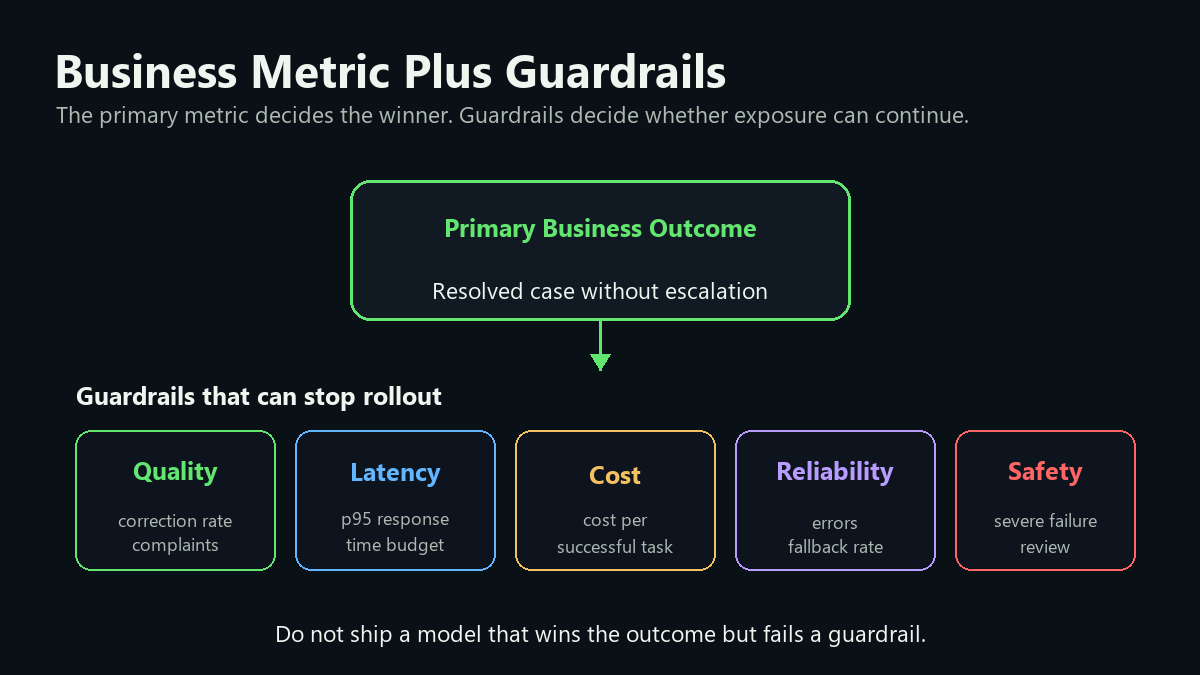
Examples:
| AI product | Primary metric | Guardrails |
|---|---|---|
| Support assistant | resolved case without escalation | p95 latency, correction rate, complaint rate, cost per resolved case |
| RAG search | accepted answer or successful click-through | no-answer rate, hallucination review rate, retrieval failures |
| Sales assistant | qualified reply or meeting booked | unsubscribe rate, manual edit rate, brand-risk review |
| Coding assistant | accepted pull request without extra rework | failed tests, review churn, rollback rate |
| Model router | cost per successful task | fallback rate, latency, quality review, provider errors |
FeatBit's measurement design guidance uses the same principle: define the metric that decides the release separately from metrics that stop expansion. That keeps the team from rationalizing a win after seeing the data.
Log Exposure Before Outcome
A model A/B test needs two event families:
- Exposure event: which unit saw which model route.
- Outcome event: what happened later in the user or workflow journey.
The exposure event should be emitted when the application actually uses the model route, not merely when it renders a page that might call the model. The outcome event should include the same stable experiment unit and variation key so analysis can connect cause to result.
{
"event": "ai_model_exposure",
"experimentKey": "support_answer_model_test",
"unitId": "account_1842",
"variation": "candidate_model_b",
"modelRoute": "support-b-v2",
"timestamp": "2026-06-02T10:15:30Z"
}
{
"event": "support_case_resolved",
"experimentKey": "support_answer_model_test",
"unitId": "account_1842",
"variation": "candidate_model_b",
"resolvedWithoutEscalation": true,
"latencyMs": 1820,
"estimatedCostUsd": 0.014
}
FeatBit implementation primitives for this pattern include targeting rules, percentage rollouts, experimentation, and the Track Insights API. The flag controls who gets each model route. The events make the outcome measurable.
Use A Flag As The Model Route Control
The model route should be a runtime decision, not a redeploy. A multivariate flag can represent the candidate routes:
flag:
key: support_answer_model
type: string
variations:
- current_model
- candidate_model_b
- fallback_model
targeting:
eligible_segment: support_chat_eligible_accounts
allocation:
current_model: 50
candidate_model_b: 50
fallback:
serve: current_model
Your application evaluates the flag before the model call, then routes to the chosen model and records the evaluated variation with telemetry. This gives the team four controls that ordinary model configuration does not provide by itself:
| Control need | Why it matters |
|---|---|
| Targeting | keep risky model routes away from ineligible accounts, regions, or workflows |
| Stable allocation | keep users or accounts consistently assigned during the test |
| Rollback | return traffic to the control model without redeploying the application |
| Audit trail | record who changed the model route and when |
FeatBit's AI experimentation page covers the broader pattern for model versions, prompt variants, retrieval settings, and agent strategies. For model tests, the useful unit is the route that changes real behavior.
Decide Before You Expand
The decision rule should be written before the test starts. It does not need to sound like a statistics paper. It needs to be clear enough that product, engineering, and operations can make the same decision from the same evidence.
decision_rule:
ship_candidate_when:
- primary_metric improves enough to matter for the business
- latency and error guardrails remain within agreed limits
- cost per successful task stays within budget
- no critical segment shows unacceptable harm
keep_control_when:
- primary_metric is flat or worse
- candidate improves outcome but fails guardrails
- analysis is inconclusive after the planned window
rollback_immediately_when:
- severe quality failure appears
- model provider errors breach the incident threshold
- exposure or outcome telemetry is missing
Teams using Bayesian interpretation can use FeatBit's Bayesian A/B testing for builders as a practical decision frame. Teams using frequentist methods should still keep the same release discipline: define the metric, window, guardrails, and action before exposure starts.
What Competitor Experiment Platforms Teach The Category
It is useful to look at how experimentation platforms frame the category, without turning the article into a vendor ranking. GrowthBook positions feature flags and experiments as connected rollout and measurement tools in its feature flag documentation. Statsig separates gradual exposure from quantified experiment readout in its feature gates versus experiments guide. Optimizely's metrics documentation emphasizes that experiments need metrics. LaunchDarkly's experiment flags documentation also connects flags, variations, and metrics.
The shared category lesson is simple: the flag assignment and the measurement plan must be designed together. For AI models, that coordination is even more important because the treatment can change quality, latency, cost, safety, and downstream human work at the same time.
Common Mistakes When A/B Testing AI Models
Using benchmark score as the primary online metric. Benchmarks are useful before exposure. The online test should measure the product or business outcome that users experience.
Changing the prompt and model at the same time. If model B also uses a new prompt, retrieval setting, or tool policy, the test is not only a model test. That can be fine, but name it honestly as a route test.
Randomizing per request when users expect continuity. A chatbot that changes model behavior across turns may confuse the user and corrupt the readout.
Ignoring cost as a guardrail. A model can improve task completion while making each successful task too expensive to scale.
Failing to track fallback behavior. If candidate model traffic silently falls back to the control route, the experiment may look safer than it really is.
Leaving the test flag in code after the decision. When the winner becomes the default, record the decision and clean up the temporary route unless the flag is intentionally becoming a permanent operational control. FeatBit's feature flag lifecycle management model helps teams close that loop.
A Practical Setup Checklist
Before starting an AI model A/B test, confirm:
- The candidate model passed offline evaluation and severe-case review.
- The release hypothesis names the user scope, expected outcome, and decision window.
- The randomization unit matches the product experience.
- The model route is controlled by a flag with explicit fallback.
- Exposure events are emitted only when the model route is used.
- Outcome events can be joined to exposure by experiment unit and variation.
- The primary metric and guardrails are written before traffic starts.
- The rollback rule is available to the release owner.
- Segment readouts will be checked before expansion.
- The flag has a cleanup or permanent-control decision after the test.
The bottom line: A/B testing AI models is not only a statistics exercise. It is a release-control workflow. Use offline evals to qualify candidates, feature flags to control model routing, real-user outcomes to decide business impact, and guardrails to keep the experiment reversible.
Source Notes
- External evaluation context: OpenAI's Evals documentation is used as an example of structured offline model evaluation before production exposure.
- Experimentation category context: GrowthBook's feature flag documentation, Statsig's feature gates versus experiments guide, Optimizely's metrics documentation, and LaunchDarkly's experiment flags documentation are cited for the general category relationship between flags, variations, metrics, and experiment decisions. They are not used as vendor rankings.
- FeatBit implementation context: AI experimentation, measurement design, Bayesian A/B testing for builders, feature flag lifecycle management, targeting rules, percentage rollouts, experimentation, and the Track Insights API.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the model route, metric, guardrail, and decision pattern. - Use
model-experiment-loop.pngnear the opening because it shows the flow from hypothesis to release decision without hiding the main guidance outside crawlable text. - Use
metric-map.pngin the metrics section because it reinforces the distinction between primary outcome and guardrails.