Offline Graders: How to Score AI Changes Before Rollout
Offline graders are the scoring functions, rubrics, assertions, judge models, or human review rules that evaluate an AI candidate before real users see it. They help a team answer a practical release question: is this prompt, model route, retrieval profile, classifier, or agent workflow good enough to move into a controlled next stage?
The grader is not the whole release decision. It produces pre-exposure quality evidence. FeatBit's angle is the handoff: offline graders qualify a candidate, while feature flags control who receives the qualified behavior, how rollout expands, which metrics are attached, and how rollback happens when production evidence disagrees.
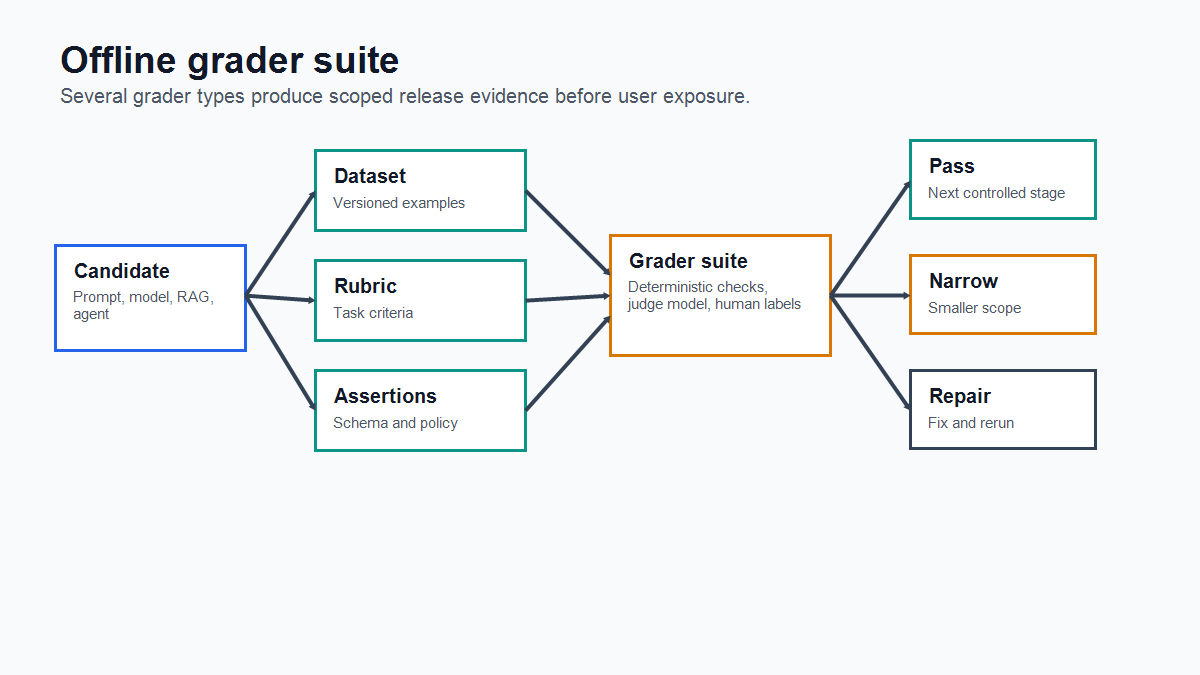
What Offline Graders Are
An offline grader evaluates AI behavior without serving the candidate output to production users.
The grader may run in CI, an eval service, a notebook, a replay job, a staging workflow, or a model gateway. The important boundary is exposure: the candidate can be scored against examples, historical inputs, references, rubrics, and known failures before it affects the user experience.
Public vendor terminology points in the same direction. Statsig's offline eval documentation describes grading model outputs on fixed test sets before real users are exposed. OpenAI's graders documentation describes grader types such as string checks, text similarity, score model graders, and Python graders. Google Cloud's judge model guidance describes using a configured model as a judge with customizable prompts. Those are evaluation primitives; a release team still has to decide what the score means operationally.
The Reader Job Behind "Offline Graders"
Teams usually search for offline graders when they already know that a simple "looks better" review is not enough.
They need to:
- compare a candidate against the current production baseline;
- protect known regressions and high-risk cases;
- score subjective qualities such as grounding, usefulness, tone, tool choice, or completeness;
- catch schema, citation, policy, latency, or cost failures before rollout;
- decide whether the candidate should pass, repair, reject, or move forward only for a narrow scope.
This is distinct from a definition of an offline eval gate. The gate is the decision boundary. Offline graders are the evidence-producing checks that feed that boundary.
Build A Grader Suite, Not One Score
A single offline grader is rarely enough for an AI release. AI changes can improve one dimension while damaging another. A prompt can sound clearer but omit required policy language. A model can answer more fully but cost too much. An agent can finish more tasks while choosing an unsafe tool in a protected workflow.
Use several grader types together:
| Grader type | Best use | Release risk it reduces |
|---|---|---|
| Exact or string checks | Required fields, required phrase, forbidden field, yes or no answer | Format and policy regressions |
| Reference similarity | Summaries, transformations, known-answer tasks | Drift from trusted outputs |
| Structured assertions | JSON schema, tool-call shape, citation presence, permission boundary | Broken integration behavior |
| Model-graded rubric | Grounding, relevance, completeness, tone, reasoning quality | Subjective quality gaps at scale |
| Human labels | Severe cases, domain judgment, policy-sensitive workflows | False confidence from automation |
| Cost and latency checks | Token use, response time, provider fallback, timeout behavior | Operational rollout failure |
| Event join simulation | Exposure and outcome identifiers before launch | Inconclusive online experiments |
The suite should compare the candidate to the baseline. "High score" is weaker than "not worse than the baseline on the primary quality bar, with no severe protected-case regression."
Design The Grader Around The Release Question
Start with the release action the grader may unlock. A grader that gates a shadow test can use a different threshold from a grader that gates visible canary exposure.
offline_grader_contract:
candidate: support_answer_prompt_v4
baseline: support_answer_prompt_v3
owner: ai_platform_team
release_question: eligible_for_internal_shadow_test
dataset_version: support_eval_set_2026_06
grader_versions:
schema: support_answer_schema_v2
grounding: policy_grounding_judge_v1
protected_cases: billing_security_regression_v3
primary_quality_bar:
rule: candidate_must_not_be_worse_than_baseline
hard_failures:
- missing_required_citation
- unsafe_account_security_advice
- invalid_output_schema
guardrails:
- estimated_cost_per_answer
- p95_latency_estimate
allowed_actions:
pass: move_to_shadow_test
narrow: internal_support_only
repair: fix_and_rerun
reject: keep_baseline
Avoid universal thresholds. The right bar depends on the use case, traffic risk, current baseline quality, and next exposure stage. A code agent, support assistant, sales copilot, search RAG flow, and pricing recommendation should not share one generic grader threshold.
Calibrate Before Trusting A Model Grader
Model-graded rubrics can scale subjective evaluation, but they need calibration. OpenAI's grader guidance calls out risks such as grader hacking, where a model can score well on a model grader while performing poorly under expert human evaluation. The practical release response is to test the grader itself.
Before using a model grader to advance a candidate:
- Collect human-labeled examples for clear passes, clear failures, boundary cases, and known regressions.
- Run the grader against those examples.
- Check false passes separately from false failures.
- Review disagreement by criterion, segment, workflow, and risk class.
- Keep a holdout set that is not used to tune the grader prompt.
- Version the rubric, judge prompt, judge model, and threshold.
For high-impact workflows, do not let the model grader be the only authority. Use deterministic assertions for hard requirements and human review for severe or domain-specific failures.
Connect Offline Graders To Controlled Exposure
The offline grader should produce a scoped next action, not a broad launch permission slip.
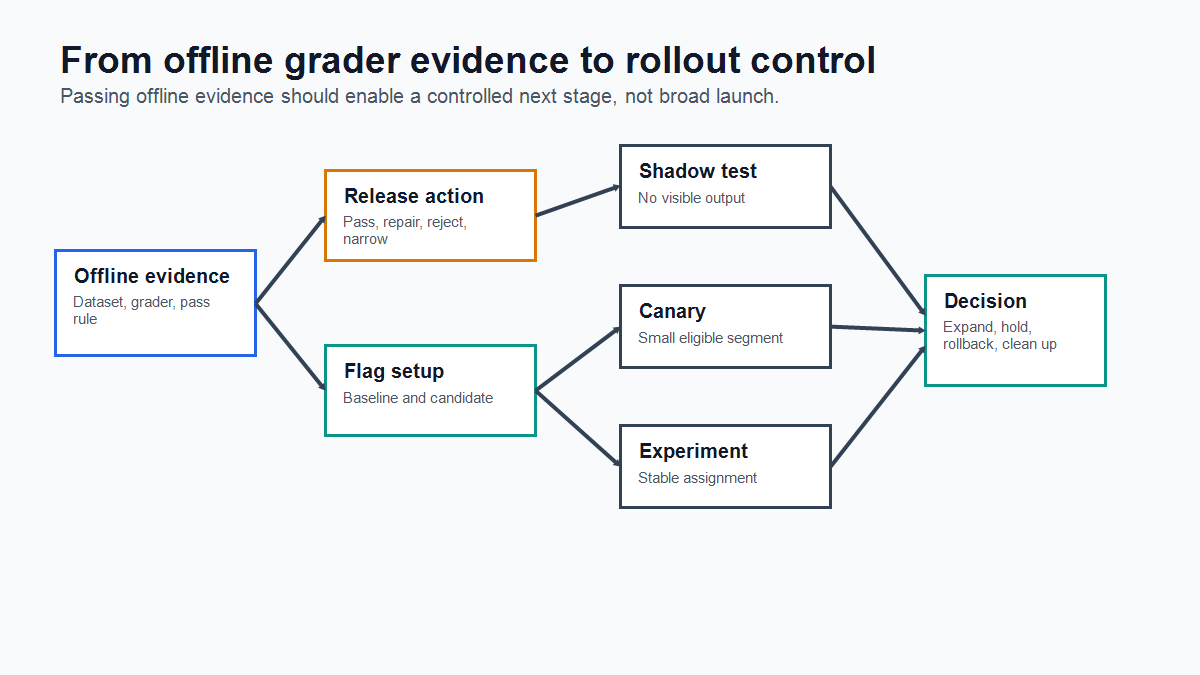
A practical handoff looks like this:
- The offline grader passes
support_answer_prompt_v4for English support chats, but not for account-security cases. - The release owner records the dataset version, grader version, failures, uncertainty, and next-stage scope.
- A FeatBit flag keeps
support_answer_prompt_v3as the fallback and addssupport_answer_prompt_v4as a candidate variation. - Targeting rules expose the candidate first to internal support users or a low-risk segment.
- Percentage rollout expands only when production guardrails remain healthy.
- Track events connect the served variation to task completion, escalation, quality review, latency, cost, and fallback rate.
- The team decides whether to expand, narrow, roll back, repair, or clean up temporary branches.
FeatBit's AI experimentation, safe AI deployment, targeting rules, percentage rollouts, and Track Insights API are the practical pieces behind that handoff.
Example: Offline Graders For A Support Assistant
Imagine a team wants to replace a support assistant prompt and retrieval profile. The expected benefit is fewer escalations. The risk is that the assistant may give unsupported account guidance, cite stale policy, or increase handling time.
The offline grader suite could include:
| Release concern | Offline grader |
|---|---|
| Routine answer quality | Model-graded rubric for correctness, grounding, and usefulness |
| Billing and account-security regressions | Protected case set with human review for failures |
| Required citations | Deterministic assertion that every policy answer includes an allowed source |
| Output contract | JSON schema check for answer, citation, confidence, and fallback reason |
| Retrieval behavior | Reference check that cited documents are in the allowed retrieved set |
| Production readiness | Estimated latency, token cost, and fallback path checks |
| Future experiment quality | Simulated exposure and outcome join by account and conversation |
If the candidate passes routine cases but fails two account-security examples, the right action is repair or narrow. If quality passes but the exposure and outcome events cannot join, the right action is to fix instrumentation before any online experiment. If the candidate passes the offline suite, it becomes eligible for shadow testing or a small canary, not automatic full rollout.
What Offline Graders Cannot Prove
Offline graders are valuable because they catch preventable regressions early. They are limited because users, live traffic, production latency, product incentives, support workflows, and segment behavior have not fully interacted with the candidate.
An offline grader cannot prove:
- conversion, retention, revenue, support deflection, or customer satisfaction impact;
- live traffic cost and latency under real load;
- whether users prefer the candidate;
- whether one customer segment is harmed by a change that looks good on average;
- whether a fallback path works during a production incident;
- whether the winning candidate should become permanent.
That evidence comes later through shadow tests, canaries, online eval flags, experiments, observability, and release review. The companion guide on online eval flags explains the live-control object that connects production exposure to evidence.
Common Mistakes
Using the grader as the release owner. A grader can recommend pass, fail, or narrow. A release owner still decides the next stage, scope, rollback rule, and cleanup path.
Optimizing only for the model-graded score. If a candidate learns to satisfy the grader while hurting users, the offline score becomes misleading. Keep human-labeled holdouts and outcome metrics in the loop.
Mixing rubric versions without labeling them. A score from grounding_judge_v1 should not be compared directly with grounding_judge_v2 unless the team has documented compatibility.
Ignoring severe cases because the average improved. Protected regressions should have hard gates. A high average score should not override a severe failure.
Forgetting the production handoff. Offline graders qualify a candidate. They do not target users, ramp exposure, emit outcome events, or roll back behavior. The handoff to runtime control must be explicit.
Leaving temporary controls behind. After production evidence supports a decision, remove losing prompt branches, retire obsolete grader gates, or convert the control into an intentional long-lived operating flag. FeatBit's feature flag lifecycle management guidance helps prevent release evidence from becoming stale control logic.
Offline Grader Checklist
Before an AI candidate moves beyond offline evaluation, confirm:
- the release question and next stage are written;
- the candidate and baseline are versioned;
- the dataset includes routine, edge, segment, and protected cases;
- grader types match the real failure modes;
- model graders are calibrated against human labels where judgment matters;
- deterministic assertions protect hard requirements;
- thresholds and hard failures are defined before results are reviewed;
- grader version, dataset version, and rubric version are recorded;
- exposure and outcome events can be joined for the next stage;
- a FeatBit flag or equivalent runtime control can serve the candidate and rollback baseline;
- the owner, review point, and cleanup path are documented.
Bottom Line
Offline graders turn AI quality review into release evidence. They are most useful when they combine task-specific rubrics, deterministic checks, regression cases, calibrated judge models, and human review for severe cases.
Do not treat a passing offline grader as proof that the AI change should reach everyone. Treat it as eligibility for controlled production learning. Then use feature flags, targeting, staged rollout, experiments, guardrails, and rollback to decide whether the candidate should expand, narrow, pause, or disappear.
Source Notes
- Category context: Statsig's offline eval documentation describes fixed test sets and pre-exposure grading of model outputs.
- Grader primitives: OpenAI's graders documentation describes string checks, text similarity, score model graders, Python graders, and grader hacking risk.
- Judge model context: Google Cloud's judge model evaluation documentation describes using a configured model as a judge with customizable prompts.
- Feature flag context: OpenFeature's evaluation context specification provides vendor-neutral language for contextual data used during flag evaluation.
- FeatBit implementation context: AI experimentation, safe AI deployment, feature flag lifecycle management, targeting rules, percentage rollouts, and the Track Insights API support the release-control workflow described here.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it shows offline graders feeding a release gate before rollout. - Use
grader-suite-map.pngnear the opening because it separates candidate behavior, grader inputs, and scoped outcomes. - Use
offline-to-rollout-handoff.pngin the controlled-exposure section because it shows the handoff from offline evidence to FeatBit-style rollout decisions.