Online Graders for AI Evaluation: From Quality Scores to Release Decisions
Online graders are automated evaluators that score AI outputs while the system is running against production traffic or production-like inputs. They can judge whether an answer is grounded, relevant, safe, complete, correctly formatted, or aligned with a task-specific rubric.
The useful release question is not "did the grader return a good score?" It is "should this prompt, model route, retrieval profile, or agent behavior continue, pause, roll back, or become the default?"
For FeatBit readers, the practical frame is simple: online graders are evidence sources. Feature flags control exposure. Business metrics and guardrails decide whether the graded AI behavior should expand.
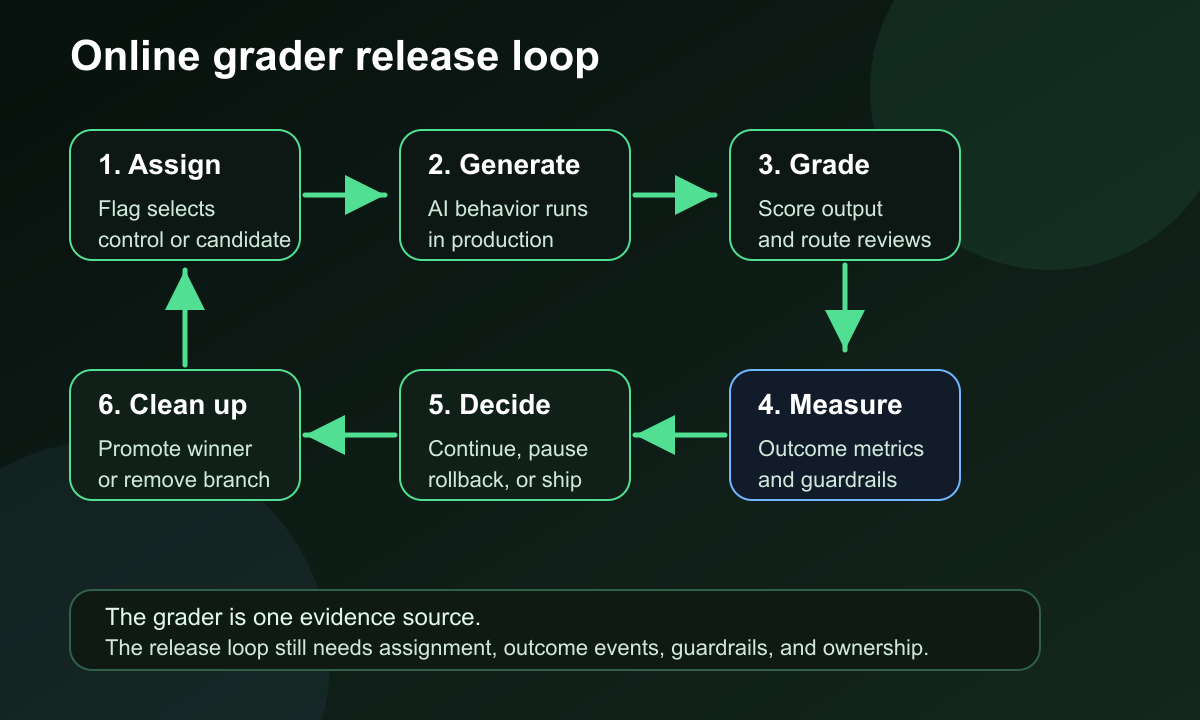
What Online Graders Are
An online grader is a scoring function applied after an AI behavior runs on real inputs. The grader may be deterministic code, a rubric-based LLM judge, a text similarity check, a structured assertion, a human review workflow, or a combination of those methods.
In AI evaluation terminology, a grader is different from the model behavior being evaluated:
| Object | Job |
|---|---|
| Prompt, model, retrieval profile, or agent policy | Produces the AI behavior users or internal systems experience. |
| Online grader | Scores that behavior against a quality rule, rubric, assertion, or review standard. |
| Feature flag | Controls which users, accounts, conversations, or workflows receive each behavior. |
| Experiment or release decision | Uses quality, outcome, guardrail, and rollout evidence to decide what happens next. |
Statsig's AI Evals documentation describes online evals as grading production model output on real-world use cases and scoring completions with graders. OpenAI's graders documentation describes several grader types, including string checks, text similarity, score model graders, code execution, and multigraders. LaunchDarkly's AgentControl documentation uses related "judge" terminology for LLM-as-a-judge quality scoring in online evaluations.
Those vendor terms point to the same operating problem: AI teams need a way to evaluate live behavior without confusing a quality score with a full release decision.
Why Online Graders Are Not Enough By Themselves
An online grader can tell you that a candidate answer scored 0.82 for relevance or failed a citation requirement. It cannot, by itself, prove that the candidate improves the product.
Online graders are especially useful for questions like:
- Did the assistant answer with the required structure?
- Did the response stay grounded in retrieved context?
- Did the agent choose the expected tool?
- Did the classifier return a valid label?
- Did the generated answer trigger a safety, tone, or policy concern?
Release teams still need separate evidence for questions like:
- Did the user complete the task?
- Did support escalation decrease?
- Did the candidate increase latency, token cost, complaints, or fallback rate?
- Did one customer segment get worse results?
- Can the team roll back without redeploying?
- Should the temporary candidate route be removed after the decision?
This is why FeatBit's measurement design guidance separates the primary outcome from guardrails. The grader may become one guardrail or one quality layer, but it should not silently replace the business metric.
Where Online Graders Fit In The Release Path
Use online graders after the AI change has passed enough pre-exposure review to justify production evidence. That might mean an offline eval gate, a shadow test, internal exposure, or a small canary.
The release path usually looks like this:
| Stage | Main question | Role of online graders |
|---|---|---|
| Offline evaluation | Is the candidate good enough to try beyond curated cases? | Usually not online; use fixed datasets, rubrics, regression cases, or human review. |
| Shadow test | Can the candidate handle production input shape without user-visible exposure? | Grade live and candidate outputs side by side. |
| Internal or canary exposure | Is limited visible exposure safe enough to expand? | Score sampled outputs and watch severe failures. |
| Online experiment | Does the candidate improve the committed outcome without guardrail harm? | Provide quality evidence that can be joined to variation and outcome data. |
| Release decision | Should the candidate continue, pause, roll back, or ship? | Feed the decision, but do not own it alone. |
| Cleanup | Should temporary release logic remain? | Preserve learning, then remove the losing branch or document a long-lived control. |
FeatBit's safe AI deployment and AI experimentation pages cover the broader rollout pattern. This article is narrower: it is about designing the grader as one trustworthy evidence source inside that pattern.
A Practical Online Grader Contract
The grader should be versioned and named before production evidence starts. Otherwise the team can change the scoring rule after seeing the result, which makes the release decision hard to trust.
online_grader:
name: support_answer_grounding_v2
owner: ai_platform_team
evaluated_behavior: support_assistant_answer_route
grading_stage: shadow_and_canary
input_fields:
- user_question
- retrieved_context
- model_output
- cited_sources
scoring_method:
type: rubric_llm_judge
scale: 0_to_1
pass_threshold: 0.82
hard_failures:
- missing_required_citation
- unsupported_account_security_instruction
- answer_contains_private_data
calibration:
human_review_sample: 50_outputs_per_week
grader_version_locked_during_experiment: true
release_action:
severe_failure: rollback_to_control
score_drop_with_clean_telemetry: pause_expansion
healthy_quality_and_outcomes: expand_candidate
The exact fields can change. The discipline should not. A useful online grader contract names the behavior, stage, inputs, scoring method, threshold, hard failures, calibration plan, and release action before the dashboard fills with data.
Connect Grader Scores To Flag Variations
Online grader data becomes decision evidence only when it can be joined to the runtime behavior that produced it.
For AI releases, the application should evaluate a flag before selecting the prompt, model, retrieval route, or agent policy. The same evaluated variation should be attached to the grader result and the outcome event.
{
"event": "ai_online_grader_result",
"flagKey": "support_assistant_answer_route",
"variation": "candidate_prompt_v4",
"unitId": "account_1842",
"conversationId": "conv_91",
"grader": "support_answer_grounding_v2",
"score": 0.87,
"hardFailure": false,
"timestamp": "2026-06-08T08:20:30Z"
}
The outcome event should carry the same assignment keys:
{
"event": "support_case_outcome",
"flagKey": "support_assistant_answer_route",
"variation": "candidate_prompt_v4",
"unitId": "account_1842",
"conversationId": "conv_91",
"resolvedWithoutEscalation": true,
"humanCorrection": false,
"latencyMs": 1720,
"estimatedCostUsd": 0.011
}
FeatBit implementation primitives for this pattern include targeting rules, percentage rollouts, A/B testing, the Track Insights API, and flag insights.
The important point is not the exact event schema. The important point is joinability. If grader scores cannot be connected to the evaluated variation and the product outcome, the team has quality telemetry but not release evidence.
Build A Scorecard Around The Grader
An online grader should sit inside a larger scorecard. That scorecard prevents the team from promoting a candidate because one quality dimension improved while the product outcome or guardrails got worse.

| Scorecard layer | Example signal | Release use |
|---|---|---|
| Grader quality | grounding score, relevance score, valid format, severe failure rate | Decide whether the candidate is acceptable enough to continue exposure. |
| Business outcome | resolved case, accepted answer, completed workflow, conversion, retention | Decide whether the candidate is worth expanding. |
| Operational guardrails | latency, cost, provider errors, fallback rate, complaint rate | Pause or roll back even if quality looks better. |
| Segment guardrails | enterprise account impact, region, language, risk tier, plan type | Narrow exposure when averages hide harm. |
| Lifecycle evidence | owner, decision state, cleanup rule, audit trail | Remove temporary branches or convert them into explicit controls. |
For a broader version of this model, see the AI evals scorecard. Online graders are one layer in that scorecard, not a replacement for it.
Common Online Grader Mistakes
Letting the candidate optimize for the grader. A model can improve on the measured rubric while becoming less useful to users. Keep human spot checks, outcome metrics, and protected regression cases in the loop.
Changing the grader during the experiment. If the grader changes, record a new version and treat old scores carefully. Mixing versions can make a candidate look better or worse for reasons unrelated to the AI behavior.
Using one grader for every task. A support answer, a RAG citation, a classification decision, and an agent tool call need different rubrics. One generic helpfulness score is rarely enough.
Ignoring cost and latency. Online graders can add model calls, review queues, or storage. Sample deliberately and decide which surfaces need continuous grading.
Tracking output without assignment. A score without flagKey, variation, and assignment unit cannot explain which release decision caused the behavior.
Treating online grading as user impact. A candidate can score higher while users still abandon the workflow, escalate to a human, or lose trust. Grade quality and measure outcomes separately.
When To Use Online Graders
Use online graders when the AI behavior is frequent enough, variable enough, or risky enough that manual review cannot keep up.
Good use cases include:
- support assistants where answer grounding and escalation behavior matter;
- RAG applications where citations, source coverage, and no-answer behavior need monitoring;
- agent workflows where tool choice, argument shape, and approval decisions need review;
- classification or routing systems where severe false positives require fast detection;
- prompt or model candidates moving from shadow testing into canary exposure.
Do not start with online graders when deterministic checks are enough, traffic volume is too low to interpret, or the team has not defined the release question. In those cases, start with offline regression cases, human review, or a smaller online eval flag that controls exposure and telemetry first.
A Setup Checklist
Before relying on online graders for an AI release, confirm:
- The release question names the candidate behavior and the next action.
- The feature flag controls who receives the candidate behavior.
- The grader is versioned and locked for the evaluation window.
- The grading rubric matches the product task, not a generic quality label.
- Severe failure cases are tracked separately from average score.
- Grader scores include
flagKey, variation, assignment unit, and timestamp. - Outcome events can be joined to the same assignment unit.
- Sampling, cost, and latency are acceptable for the evaluated surface.
- Human review calibrates the grader on difficult or high-risk cases.
- Rollback and cleanup rules are written before expansion.
FeatBit's feature flag lifecycle management model is useful after the decision. A temporary prompt, model, retrieval, or grader experiment should not remain in code forever just because it once supported a release.
Bottom Line
Online graders help AI teams evaluate live behavior with more discipline than manual sampling alone. They are especially useful when prompt, model, retrieval, or agent changes need quality evidence under real production conditions.
But an online grader is not the release system. It scores behavior. The release system still needs controlled exposure, stable variation assignment, outcome events, guardrails, rollback, ownership, and cleanup.
Use FeatBit to keep that runtime decision reversible and measurable. Use online graders to make quality visible. Use the scorecard to decide what should actually ship.
Source Notes
- Vendor terminology context: Statsig's Online Evals documentation describes grading model output in production on real-world use cases and scoring completions with graders.
- Grader taxonomy context: OpenAI's Graders documentation describes string check, text similarity, score model, code execution, and multigrader patterns for evals and fine-tuning.
- Category context: LaunchDarkly's online evals tutorial and config variation documentation describe LLM-as-a-judge scoring and judge-style AgentControl configurations.
- FeatBit implementation context: AI experimentation, safe AI deployment, measurement design, feature flag lifecycle management, targeting rules, percentage rollouts, A/B testing, Track Insights API, and flag insights support the release-control workflow described here.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it shows the full production flow from runtime control to grader evidence and outcome dashboards. - Use
online-grader-loop.pngnear the opening because it distinguishes grading from assignment, outcome measurement, release decisions, and cleanup. - Use
grader-scorecard.pngin the scorecard section because it visualizes the four evidence groups that should surround an online grader.