What Is an Offline Eval Gate? A Practical AI Release Definition
An offline eval gate is a pre-exposure release checkpoint for an AI change. It decides whether a candidate prompt, model, retrieval rule, classifier, or agent workflow has enough evidence to move toward production testing before any user sees the new behavior.
The gate does not prove business impact. It does not replace a shadow test, canary rollout, or A/B experiment. Its job is narrower and important: block preventable AI regressions before they become a production exposure problem.
For FeatBit readers, the useful framing is this: offline eval gates qualify a candidate; feature flags control exposure after the candidate qualifies.
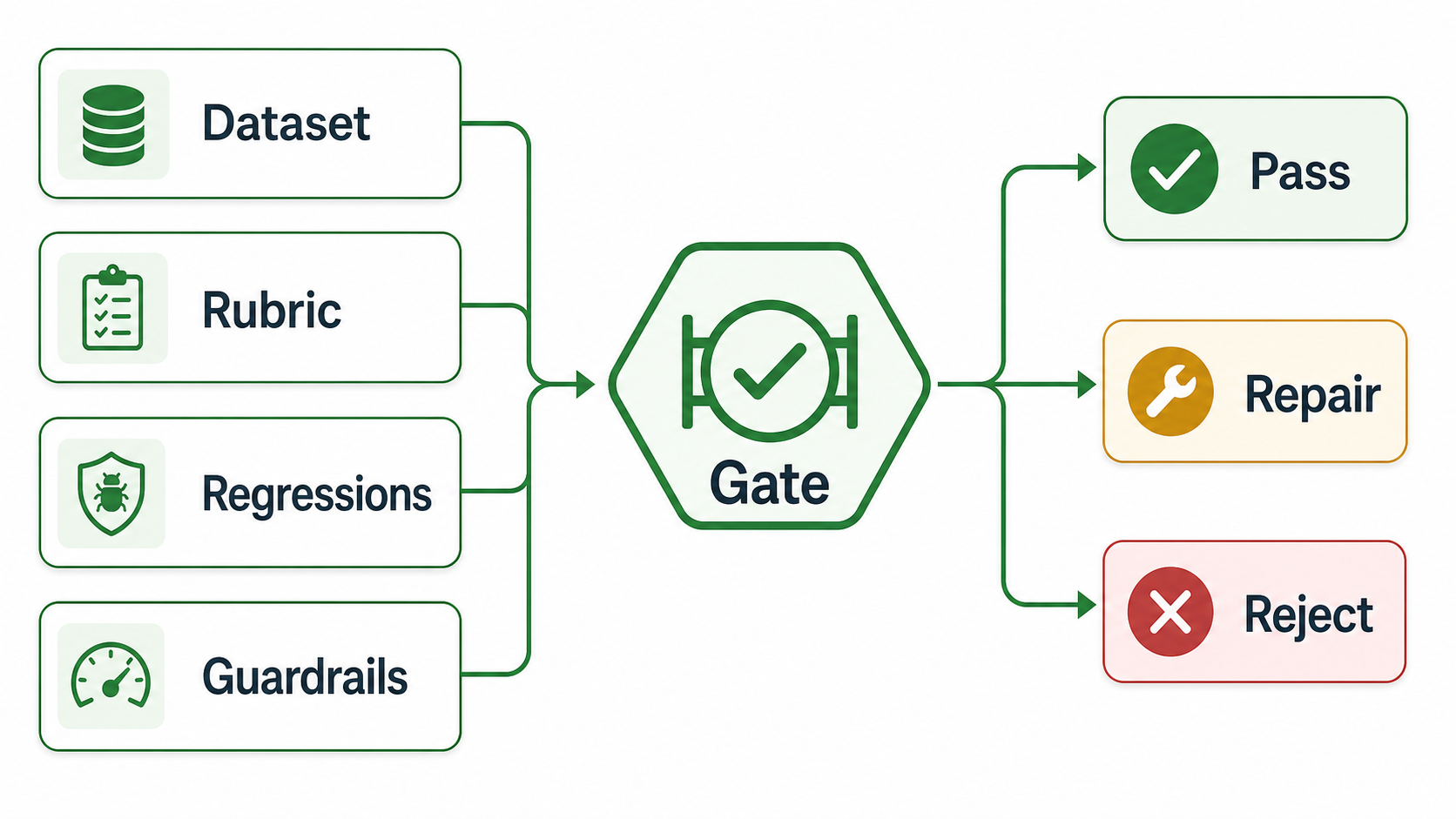
The Short Definition
An offline eval gate is a decision rule applied to evaluation results that were produced outside live user exposure.
It usually combines:
- a fixed or versioned test dataset;
- a baseline behavior and a candidate behavior;
- scoring rules, human review, deterministic assertions, model-graded rubrics, or a mix of methods;
- protected regression cases that must not fail;
- guardrails for latency, cost, safety, format, policy, or reliability;
- a release action: pass, repair, reject, or narrow the next stage.
The phrase "gate" matters. An eval report says what happened. A gate says what the team is allowed to do next.
What Problem It Solves
AI teams change behavior quickly. A small prompt edit can change tone, grounding, refusal behavior, citation quality, cost, latency, or tool selection. A model upgrade can improve average quality while hurting one protected workflow. A retrieval change can look better on common questions while breaking an enterprise account with unusual documents.
Without an offline gate, the team often makes one of two mistakes:
| Mistake | What happens |
|---|---|
| Ship from intuition | A candidate reaches production because it looked better in a few examples. |
| Treat the eval as a dashboard only | Scores exist, but no one knows whether the candidate can advance. |
The offline eval gate turns quality evidence into a release decision before live exposure starts.
What Counts As Offline Evidence
Offline evidence is evidence collected without showing the candidate behavior to users. The candidate may run in a notebook, CI job, evaluation service, staging environment, replay job, or internal review workflow. The key point is that real production users are not receiving the candidate output as their product experience.
Common evidence types include:
| Evidence type | Best use |
|---|---|
| Golden dataset | Compare candidate behavior against known examples and expected answers. |
| Regression set | Protect incident cases, high-risk prompts, contractual formats, and known failures. |
| Rubric scoring | Judge subjective qualities such as helpfulness, grounding, completeness, or tone. |
| Structured assertions | Check schema, required fields, forbidden fields, citations, or tool-call shape. |
| Human review | Catch domain-specific quality and policy issues that automated scoring misses. |
| Cost and latency estimates | Block candidates that are not viable enough to test safely. |
OpenAI's Evals API describes evaluations as structures with testing criteria and data sources that can be run against different model configurations. Google Cloud's generative AI evaluation guidance similarly treats evaluation as a development practice for model comparison, prompt editing, and other AI changes. Those references support the same operating idea: evals are useful when they are tied to the behavior you intend to ship.
What The Gate Should Decide
The gate should answer one release question:
Is this AI change eligible for controlled production evidence?
That is different from "is the change better?" or "should this become the default?" The offline gate should produce one of four actions:
| Gate outcome | Meaning | Next action |
|---|---|---|
| Pass | The candidate clears the pre-exposure bar. | Move to shadow test, internal exposure, canary, or experiment. |
| Repair | The candidate has fixable failures. | Update prompt, model route, retrieval config, tests, or instrumentation. |
| Reject | The candidate fails a hard requirement. | Keep the baseline and stop this candidate. |
| Narrow | The candidate is acceptable only for a limited scope. | Restrict the next stage by segment, workflow, language, account, or risk class. |
The "narrow" outcome is especially useful for AI systems. A candidate may be strong enough for internal users, low-risk support categories, or one language, but not ready for broad exposure.
A Practical Offline Eval Gate Template
Use a small written template before running the eval. The template keeps the gate from becoming a post-hoc debate.
offline_eval_gate:
change: support_assistant_prompt_v4
baseline: support_assistant_prompt_v3
owner: ai_platform_team
release_question: eligible_for_shadow_test
dataset:
source: historical_support_questions
coverage:
- routine_troubleshooting
- billing_questions
- account_security
- long_threads
- multilingual_examples
primary_quality_bar:
metric: rubric_pass_rate
decision_rule: candidate_must_not_be_worse_than_baseline
protected_regressions:
decision_rule: zero_severity_one_failures
guardrails:
- output_schema_valid
- citations_present_when_required
- p95_latency_within_budget
- estimated_cost_within_budget
outcomes:
pass: move_to_shadow_test
repair: fix_failures_and_rerun
reject: keep_baseline
narrow: restrict_to_low_risk_topics
Avoid universal numeric thresholds copied from another company. The right bar depends on the user journey, risk class, baseline quality, and whether the next stage is shadow testing or live exposure.
Where It Fits In The AI Release Path
An offline eval gate is the first serious release checkpoint, not the whole release process.
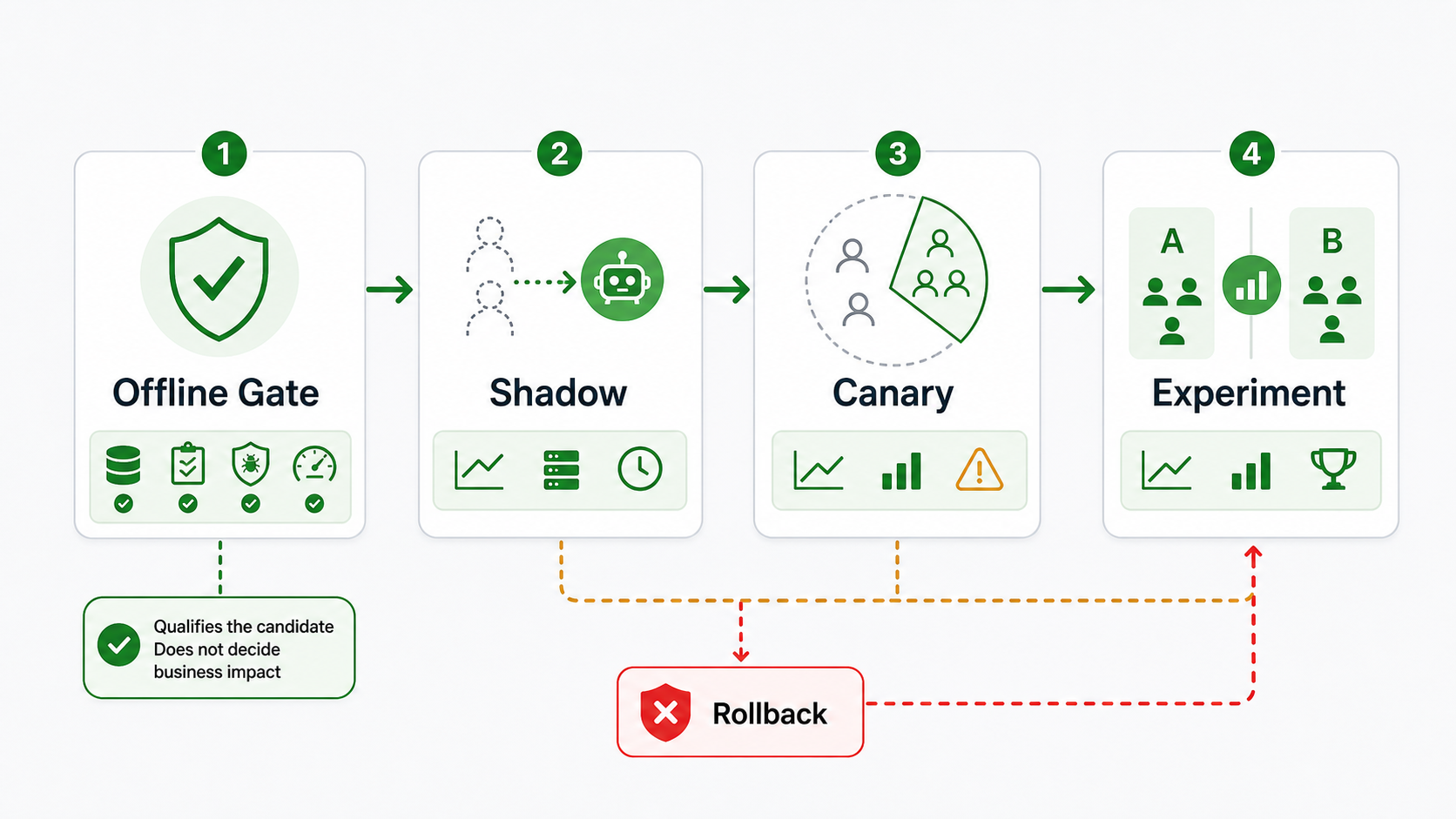
The release path usually looks like this:
| Stage | Main question | User exposure |
|---|---|---|
| Offline eval gate | Is the candidate good enough to test beyond curated cases? | None |
| Shadow test | Can the candidate handle production inputs without affecting users? | None, if side effects are blocked |
| Canary rollout | Is limited visible exposure safe enough to expand? | Small and reversible |
| A/B experiment | Does the candidate improve the committed outcome without guardrail harm? | Controlled treatment and control groups |
| Rollout decision | Should the candidate expand, hold, roll back, or become default? | Depends on evidence |
This is why a gate should not overclaim. It can make a candidate eligible for the next stage. It cannot prove user behavior, conversion lift, support deflection, retention, or customer trust because users have not experienced the candidate yet.
For the broader staged workflow, see FeatBit's guide to moving from offline eval to shadow test to canary rollout. This article is narrower: it explains the first gate in that chain.
What It Cannot Decide
An offline eval gate cannot decide:
- whether users prefer the candidate;
- whether the candidate improves conversion, retention, or support outcomes;
- whether production latency and cost hold under live traffic;
- whether one segment is harmed by a change that looks good on average;
- whether the candidate should receive 100 percent of traffic;
- whether the team can remove the fallback path.
Those decisions need controlled production evidence. Use a shadow test before an A/B test when production input shape is the risk. Use canary rollout when selected users need to see the change. Use an experiment when the question is product or business impact.
How Feature Flags Connect The Gate To Production
The offline eval gate should hand a clear decision to the runtime control layer.
For example:
- The eval gate passes
support_assistant_prompt_v4for English support chats only. - A feature flag keeps
prompt_v3as the default and makesprompt_v4a named variation. - FeatBit targeting rules expose the candidate first to internal users or a low-risk segment.
- Percentage rollout controls expansion.
- Metric events connect the evaluated variation to task completion, escalation, latency, cost, and quality review.
- Rollback returns traffic to the baseline without redeploying application code.
FeatBit's safe AI deployment, AI experimentation, targeting rules, percentage rollouts, and Track Insights API are the practical pieces behind that handoff.
The gate and the flag are not the same object. The gate decides eligibility. The flag controls who receives the eligible behavior.
Design Rules For A Useful Gate
Name the decision before the eval runs. "We will review the dashboard" is not a gate. "Move to shadow only if no severity-one regression appears and the candidate is not worse on the primary rubric" is a gate.
Compare against the current production behavior. A candidate does not need to be abstractly good. It needs to be good enough compared with the baseline it may replace.
Protect severe cases separately from averages. Average score can hide failures in account security, payment, medical-adjacent support, policy, privacy, or high-value customer workflows. Keep hard regression sets visible.
Separate quality from viability. A candidate can be high quality and still too slow, too expensive, too fragile, or too hard to observe for the next stage.
Produce a scoped next action. The best gate output is not only pass or fail. It should say whether the candidate should move to shadow, internal exposure, canary, a narrower segment, repair, or rejection.
Record the decision with the release artifact. Store the eval run, dataset version, candidate version, owner, and decision rule where future reviewers can find it. Otherwise, the gate becomes hard to audit and hard to learn from.
Common Anti-Patterns
Using one leaderboard metric as the gate. AI changes often move quality, cost, latency, safety, and business value in different directions. A single score can screen candidates, but it is rarely enough for a release gate.
Letting the model grade itself without review. Model-graded rubrics can be useful, but severe cases and policy-sensitive workflows often need deterministic checks, human review, or both.
Changing the gate after seeing the result. If the candidate fails, revise the candidate or revise the eval for a documented reason. Do not move the threshold because the team wants to ship.
Skipping the handoff to runtime control. A passed offline eval does not make production exposure safe. The candidate still needs targeting, rollout, observability, and rollback.
Leaving the release flag forever. After production evidence supports a decision, clean up temporary experiment and rollout flags or convert them into explicit long-lived operational controls. FeatBit's feature flag lifecycle management model helps keep release memory from becoming stale control logic.
FAQ
Is an offline eval gate the same as an AI eval?
No. An AI eval measures behavior. An offline eval gate is the decision rule that interprets the eval results and decides whether the candidate can advance.
Is an offline eval gate the same as a CI quality gate?
It can run in CI, but the content is different. A CI gate usually checks code, tests, static analysis, or build health. An offline eval gate checks AI behavior against datasets, rubrics, regressions, and AI-specific guardrails.
Should every AI change have an offline eval gate?
Every material AI behavior change should have some pre-exposure quality bar. The depth depends on risk. A typo fix in a low-risk prompt may need a small regression check. A model route, RAG policy, agent tool rule, or safety-sensitive workflow needs a stronger gate.
Can an offline eval gate automatically trigger rollout?
It can trigger the next controlled stage, but automatic broad rollout is risky. A safer pattern is to let a passed gate enable shadow testing, internal targeting, or a small canary behind a feature flag, then expand only when production evidence holds.
Bottom Line
An offline eval gate is the boundary between "this AI change looks promising in controlled evaluation" and "this AI change is eligible for controlled production evidence."
Use it to block preventable regressions, clarify the next release action, and keep live user exposure behind runtime controls. Then use feature flags, shadow tests, canaries, experiments, metrics, and rollback to decide what should actually stay in production.
Source Notes
- OpenAI evaluation context: the OpenAI Evals API reference describes evaluations as testing criteria and data-source configuration that can be run against model configurations.
- Google Cloud evaluation context: the Gen AI evaluation service overview describes evaluation support for tasks such as model comparison, prompt editing, and adaptive rubrics.
- Category context: Statsig's AI Evals overview distinguishes offline evals on a fixed test set before user exposure from production-serving workflows. This article uses that as category context, not as vendor ranking.
- Runtime control context: the OpenFeature flag evaluation specification provides vendor-neutral language for feature flag evaluation, and FeatBit docs explain targeting rules, percentage rollouts, and the Track Insights API.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it shows the candidate blocked by an offline gate before user exposure. - Use
offline-eval-gate-anatomy.pngnear the opening because it visualizes the required evidence inputs without replacing the crawlable definition. - Use
offline-to-production-handoff.pngin the release-path section because it shows the boundary between pre-exposure evaluation and production learning.