What Is an Online Eval Flag? A Practical Definition for AI Releases
An online eval flag is a feature flag that controls live exposure for an AI behavior while the team evaluates that behavior with production evidence.
It can route eligible users, accounts, conversations, or workflows to a candidate prompt, model, retrieval profile, tool policy, or agent strategy. It also gives telemetry a stable variation key so quality reviews, user behavior, cost, latency, and business outcomes can be joined back to the exact AI behavior that ran.
The useful definition is simple: an online eval flag is the runtime control point for evaluating AI changes after offline checks, during controlled production exposure, and before the release decision becomes permanent.
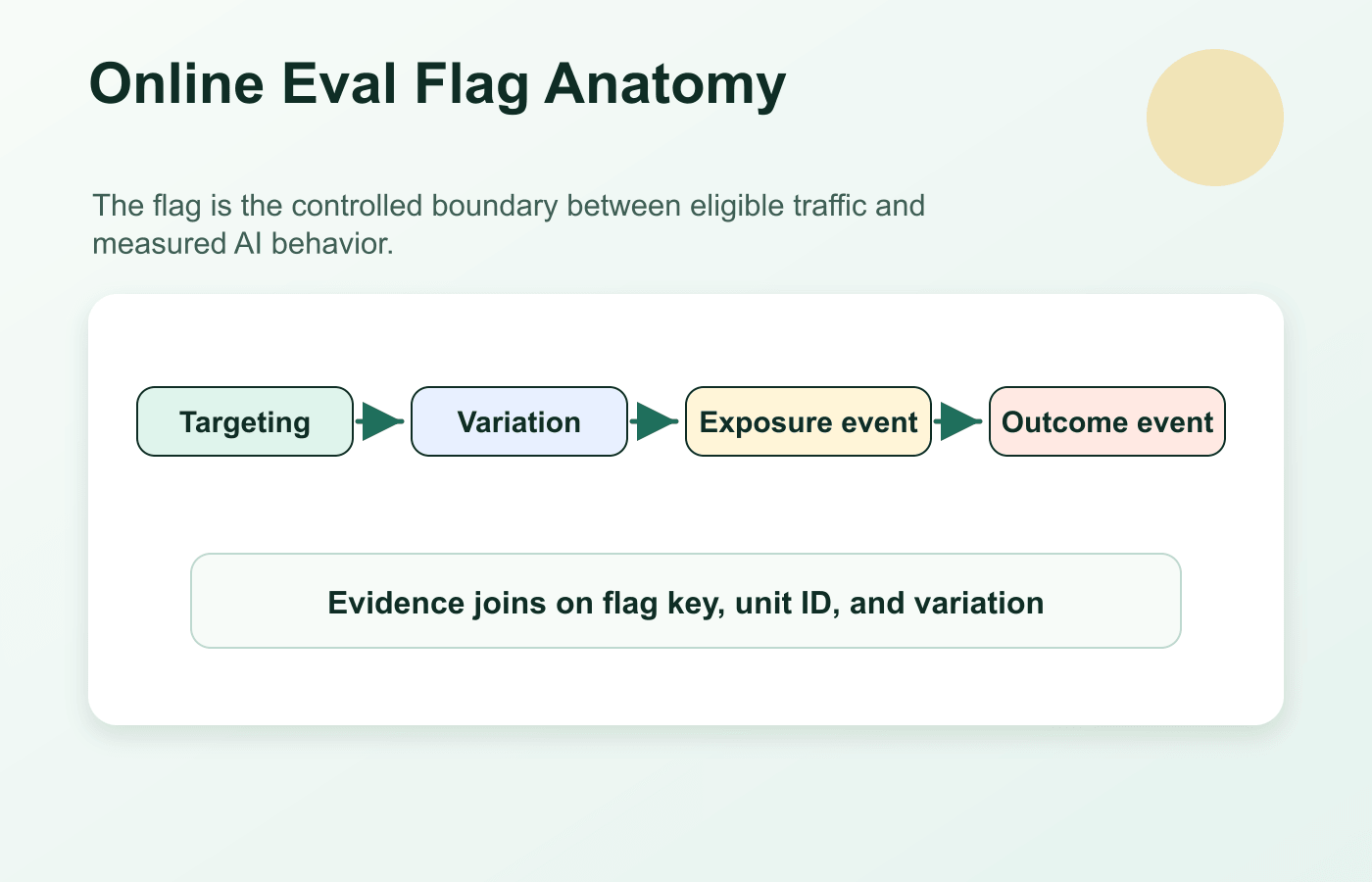
The Short Definition
An online eval flag is not only a boolean switch. It is usually a multivariate or structured flag that answers three questions at request time:
| Question | What the flag controls |
|---|---|
| Who is eligible? | target segment, account, environment, risk tier, region, or workflow |
| Which AI behavior runs? | prompt version, model route, retrieval profile, tool policy, guardrail setting, or fallback |
| How is evidence attributed? | variation key, evaluation context, exposure event, and decision record |
That makes it different from an offline eval gate. An offline gate decides whether a candidate is eligible for production testing. An online eval flag controls which production traffic receives the candidate and how the result is measured.
For teams using vendor-neutral flagging concepts, the OpenFeature specification describes typed flag evaluation with a flag key, default value, evaluation context, and optional detailed evaluation metadata. That metadata is useful for telemetry and troubleshooting when the evaluated variation needs to be connected to later evidence.
Why AI Teams Need This Term
AI changes often sit between two familiar practices:
- offline evaluation, where prompts, models, or agents are tested against datasets, rubrics, regression cases, or graders before users see the change;
- online experimentation, where real production exposure reveals whether the change improves user behavior, task completion, cost, trust, or business outcomes.
The gap between those practices is operational. A team may have an eval score and an experiment dashboard, but still lack a clean runtime object that says who receives the candidate, what fallback remains available, which exposure event was emitted, and who can stop the rollout.
That runtime object is the online eval flag.
Statsig's AI Evals documentation separates offline evals on fixed test sets from online evals that grade model output in production on real-world use cases. LaunchDarkly's AgentControl experimentation documentation makes a related distinction between monitoring config performance and running experiments to measure effects on end-user behavior. Those category signals point to the same release problem: live AI behavior needs both evaluation and exposure control.
FeatBit's angle is release-decision infrastructure. The flag is not the grader and it is not the whole experiment. It is the controllable production boundary that lets evaluation evidence become an actionable release decision.
Where It Fits In The AI Release Path
Use an online eval flag after the candidate has passed enough pre-exposure review to justify controlled production evidence.
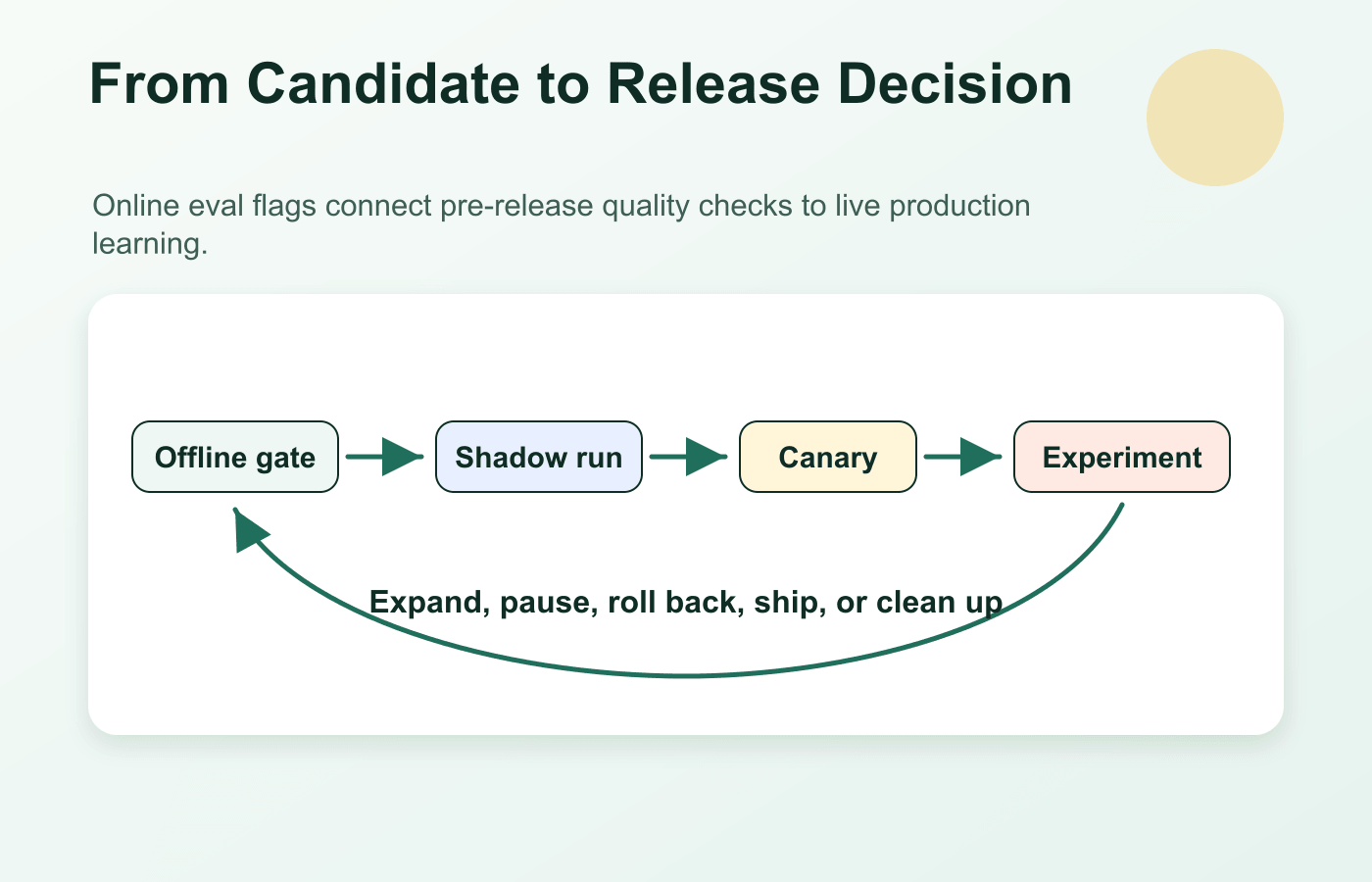
| Stage | Main question | Role of the flag |
|---|---|---|
| Offline eval gate | Is the candidate eligible for controlled production evidence? | Not the main decision point, but the future variation can be prepared. |
| Shadow test | Can the candidate handle production inputs without affecting users? | Route shadow traffic and label candidate outputs without user-visible exposure. |
| Internal or canary exposure | Is limited visible exposure safe enough to expand? | Target a small segment and keep rollback available. |
| Online eval or experiment | Does the candidate improve quality or business outcomes under real use? | Assign stable variations and connect exposure to outcomes. |
| Release decision | Should the candidate expand, pause, roll back, or become default? | Change rollout state and preserve the decision record. |
| Cleanup | Should temporary release logic remain? | Remove experiment branches or convert the flag to a long-lived operational control. |
This is why an online eval flag should be designed before the first production exposure. If the team waits until the experiment is live to decide the assignment unit, event schema, guardrails, and rollback rule, the evidence may be impossible to trust.
What It Should Control
The flag should represent the smallest runtime decision that can be evaluated cleanly.
Good online eval flag targets include:
- a prompt version, such as
support_answer_prompt_v4; - a model route, such as
current_modelversuscandidate_model_b; - a retrieval profile, such as baseline search versus a reranker;
- an agent tool policy, such as read-only mode versus approval-required write mode;
- a guardrail setting, such as conservative refusal behavior versus a more permissive workflow;
- a fallback path, such as stable provider versus candidate provider.
Avoid packing too many AI surfaces into one variation unless the release question is honestly a route test. If the prompt, model, retrieval policy, and tool permissions all change at the same time, the online eval can still be useful, but the result should not be attributed to only one component.
A Practical Flag Template
An online eval flag should make the production decision explicit.
online_eval_flag:
key: support_assistant_answer_route
type: string
owner: ai_platform_team
release_question: should_candidate_route_expand_to_paid_support_chat
assignment_unit: account_id
variations:
control: prompt_v3_model_a_baseline_retrieval
candidate: prompt_v4_model_b_reranker_v2
fallback: prompt_v3_model_a_baseline_retrieval
eligible_scope:
environment: production
segment: paid_accounts_english_support_chat
exclusions:
- regulated_accounts
- high_priority_incidents
rollout:
start: internal_users
next: 5_percent_canary
experiment: 50_50_control_candidate
primary_outcome: case_resolved_without_escalation
guardrails:
- p95_latency
- cost_per_resolved_case
- human_correction_rate
- complaint_rate
- fallback_rate
rollback_when:
- severe_quality_failure
- telemetry_missing
- guardrail_breach
cleanup:
after_decision: remove_losing_route_or_promote_winner
The template is not meant to be universal. The important part is that the flag names the behavior, the eligible population, the evidence, the rollback rule, and the cleanup path before live exposure starts.
How Evidence Should Flow
An online eval flag creates useful evidence only when exposure and outcome events can be joined.
The exposure event should fire when the AI behavior actually runs:
{
"event": "ai_online_eval_exposure",
"flagKey": "support_assistant_answer_route",
"unitId": "account_1842",
"variation": "candidate",
"surface": "answer_route",
"promptVersion": "prompt_v4",
"modelRoute": "model_b",
"timestamp": "2026-06-07T09:15:30Z"
}
The outcome event should carry the same flag key, unit ID, and variation:
{
"event": "support_case_outcome",
"flagKey": "support_assistant_answer_route",
"unitId": "account_1842",
"variation": "candidate",
"resolvedWithoutEscalation": true,
"latencyMs": 1860,
"estimatedCostUsd": 0.012,
"humanCorrection": false
}
The join is the product. Without it, the team has traffic control and telemetry, but not decision evidence.
FeatBit implementation primitives for this pattern include targeting rules, percentage rollouts, experimentation, the Track Insights API, and flag insights. The flag controls assignment and exposure. The events make the release decision measurable.
Which Metrics Belong With The Flag
Online evaluation should not collapse into one generic quality score. AI behavior can improve one dimension while damaging another.
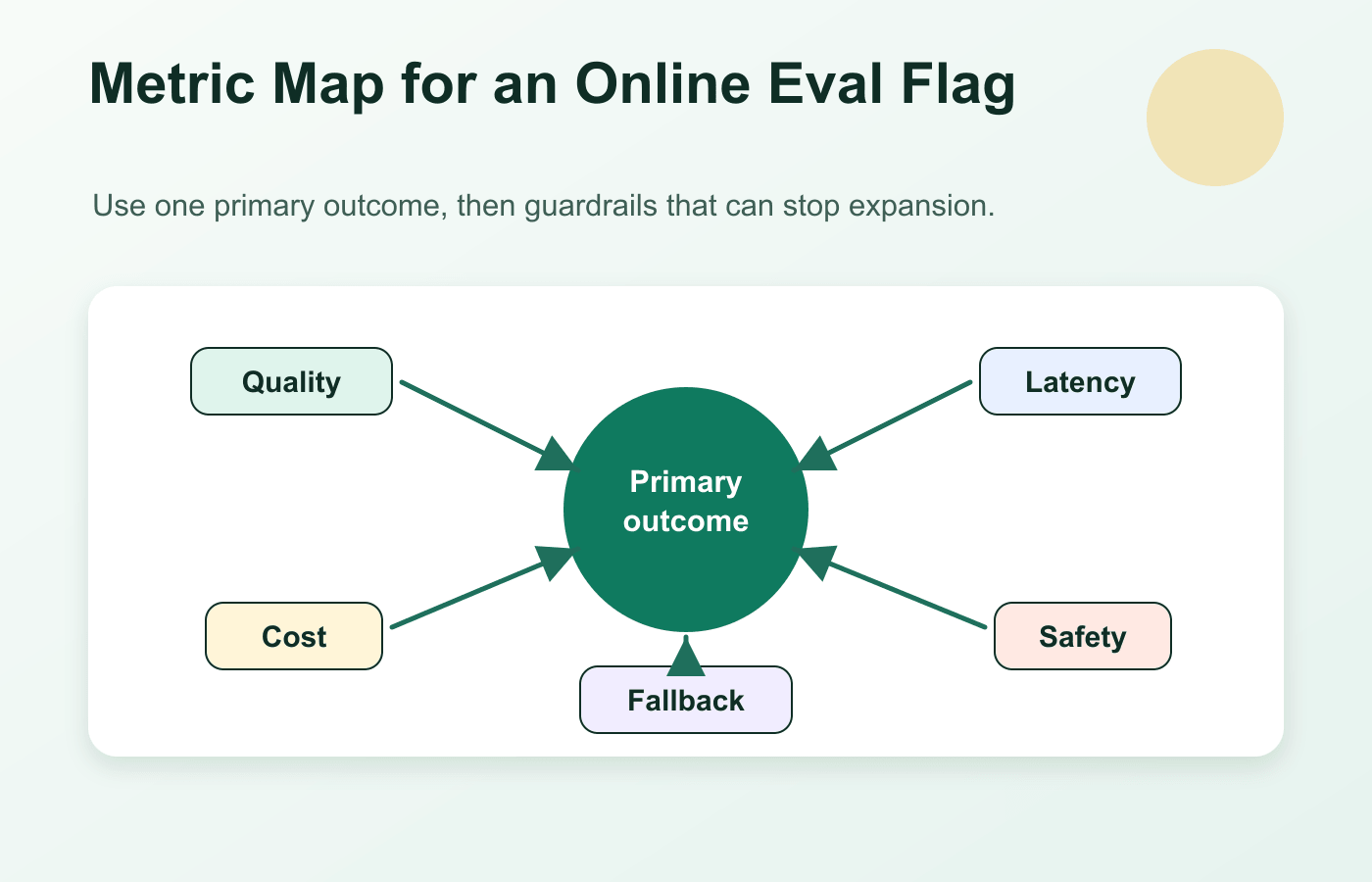
Use one primary outcome and several guardrails:
| AI change | Primary outcome | Guardrails |
|---|---|---|
| Support prompt | resolved case without escalation | correction rate, complaint rate, latency, cost |
| Model route | successful task per session | fallback rate, provider errors, cost per success |
| RAG profile | accepted answer or useful citation | no-answer rate, hallucination review, unsafe source rate |
| Agent tool policy | workflow completed without takeover | wrong-tool rate, approval queue size, incident count |
| Classification prompt | correct downstream routing | manual reroute rate, confidence drift, high-risk false positives |
The primary outcome decides whether the candidate is worth expanding. Guardrails decide whether the team should pause or roll back even if the primary outcome improves.
FeatBit's measurement design guidance uses the same separation. It keeps the release decision from being rewritten after the team sees whichever metric looks best.
Online Eval Flag Vs Related Terms
| Term | What it decides | What it does not decide |
|---|---|---|
| Offline eval gate | Whether a candidate can advance beyond pre-exposure testing | Who receives live production behavior |
| Shadow test flag | Whether a candidate can run against production inputs without affecting users | Whether visible user outcomes improve |
| Canary flag | Whether limited visible exposure is healthy enough to expand | Whether the candidate has proven product value |
| Experiment flag | Whether a variation improves a defined metric under controlled assignment | Whether the candidate passed pre-exposure quality checks |
| Online eval flag | Which live traffic receives an AI behavior while quality and outcome evidence is collected | The final decision unless the evidence and guardrails are predefined |
These terms can overlap in one implementation. A single FeatBit flag might start as a shadow route, become a canary, support an experiment, and then become a temporary release decision record. The naming matters because each stage answers a different question.
Common Mistakes
Using the flag as the eval. A flag can expose and label behavior. It does not judge answer quality unless the team connects graders, human review, product metrics, or other evaluation systems to the exposure.
Randomizing at the wrong unit. Request-level assignment can corrupt chat, support, coding, and agent workflows where continuity matters. Choose user, account, conversation, session, or workflow assignment based on the product journey.
Tracking exposure too early. A page view is not an AI exposure if the model route never ran. Emit exposure when the assigned AI behavior is actually used.
Ignoring fallback rate. If candidate traffic frequently falls back to control, the candidate may look safer or cheaper than it really is.
Letting the flag become permanent by accident. After the release decision, remove the losing branch, promote the winner, or intentionally convert the flag into a long-lived operational control. FeatBit's feature flag lifecycle management model helps keep the release record from becoming stale code.
A Setup Checklist
Before using an online eval flag, confirm:
- The candidate passed offline evaluation or a documented risk review.
- The release question names the AI behavior and the user outcome.
- The flag variation represents one clean runtime decision.
- The assignment unit matches the user journey.
- Targeting excludes ineligible segments and high-risk workflows.
- Exposure events fire only when the AI behavior runs.
- Outcome events carry the same unit ID and variation.
- The primary metric and guardrails are defined before exposure.
- Rollback can return users to the baseline without redeploying.
- The owner and cleanup rule are written before the flag expands.
FAQ
Is an online eval flag the same as an experiment flag?
Not always. An experiment flag usually emphasizes controlled comparison between variations and a metric readout. An online eval flag emphasizes the full live-evaluation control point for AI behavior: eligibility, assignment, quality evidence, guardrails, rollback, and cleanup. It may become an experiment flag when the release question requires A/B comparison.
Is an online eval flag visible to users?
Sometimes. It can support shadow evaluation with no user-visible candidate output, or it can support visible canary and experiment exposure. The important point is that production inputs or production users are involved, and the flag controls that involvement.
Can offline evals automatically turn on an online eval flag?
They can trigger a prepared next stage, but broad automatic rollout is risky. A safer pattern is to let a passed offline gate enable internal targeting, shadow traffic, or a small canary, then expand only when production evidence and guardrails remain acceptable.
What is the difference between online eval and monitoring?
Monitoring tells you what happened to the live system. Online evaluation connects what happened to a controlled AI variation and a release decision. Monitoring is necessary, but the online eval flag adds assignment, attribution, rollback, and decision state.
Bottom Line
An online eval flag is the production control point that lets AI teams evaluate live behavior without guessing.
Use offline eval gates to block weak candidates before exposure. Use online eval flags to route eligible candidates, collect joinable evidence, compare quality and business outcomes, watch guardrails, and decide whether to expand, pause, roll back, or clean up.
For FeatBit teams, this is the practical operating model: AI behavior should be targetable, measurable, reversible, and owned through the whole release decision.
Source Notes
- AI eval category context: Statsig's AI Evals overview distinguishes offline evals on fixed test sets from online evals that grade production model output on real-world use cases. This article uses that distinction as category context, not as a vendor ranking.
- Experimentation category context: LaunchDarkly's AgentControl experimentation documentation describes measuring how config variations affect end-user behavior through metrics, and GrowthBook's feature flag documentation connects flags with targeting, gradual rollout, and experiments.
- Feature flag standard context: the OpenFeature flag evaluation specification is cited for typed flag evaluation, evaluation context, and detailed evaluation metadata that can support telemetry.
- FeatBit implementation context: AI experimentation, safe AI deployment, measurement design, feature flag lifecycle management, targeting rules, percentage rollouts, experimentation, Track Insights API, and flag insights support the release-control workflow described here.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the article's central live-evaluation control point. - Use
online-eval-flag-anatomy.pngnear the opening because it shows the flag as exposure control plus evidence attribution. - Use
online-eval-release-loop.pngin the release-path section because it distinguishes offline gating, shadow testing, canary exposure, online evaluation, decision, and cleanup. - Use
online-eval-metric-map.pngin the metrics section because it reinforces the primary outcome versus guardrail structure.