PostHog vs GrowthBook for AI Experimentation: A Release-Control Comparison
If you are comparing PostHog and GrowthBook for AI experimentation, the real decision is not only "which tool runs A/B tests?" It is which operating model will help your team expose AI changes safely, connect them to quality and business outcomes, and roll back before a weak prompt, model route, retrieval change, or agent workflow becomes the default experience.
PostHog is easiest to evaluate as an all-in-one product engineering suite: analytics, feature flags, experiments, session replay, error tracking, surveys, AI observability, and PostHog AI live in one product surface. GrowthBook is easiest to evaluate as a warehouse-native experimentation and feature flag platform: metrics are defined from your data, experiments can use advanced statistical methods, and flags can become experiments in the same release workflow.
FeatBit's angle is different. For teams shipping AI behavior, experimentation is a release decision. The control plane should decide who sees a candidate, keep assignment stable, record exposure, connect outcomes and guardrails, and preserve rollback until the decision is complete.
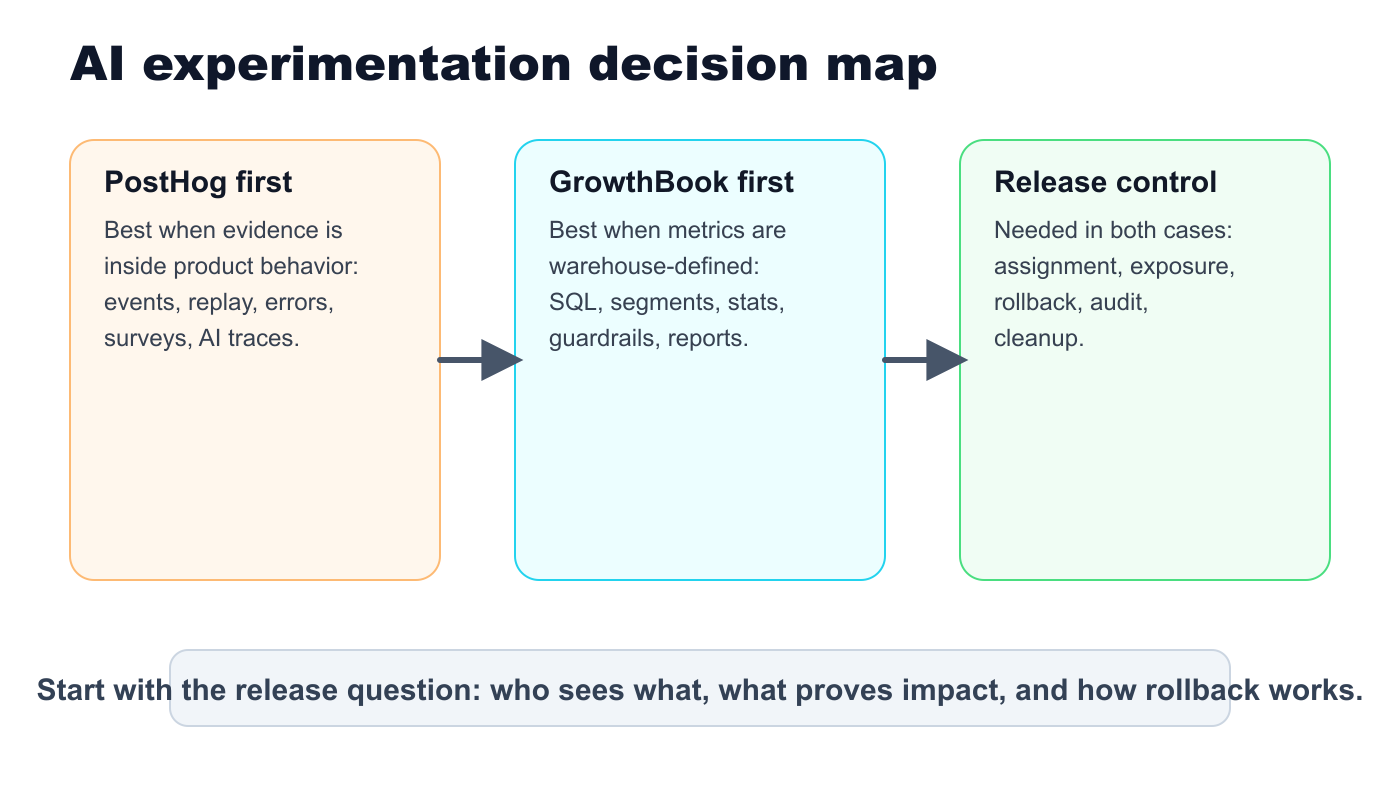
The Reader Job Behind This Vendor Query
The keyword looks like a vendor comparison, but the reader task is usually more specific:
- "Should we use PostHog or GrowthBook to test an AI product change?"
- "Do we need product analytics, warehouse-native experimentation, or runtime release control?"
- "How do we compare AI quality with business impact instead of only watching model traces?"
- "Where do feature flags, exposure events, guardrails, and rollback fit?"
That makes this a comparison of operating models, not a generic ranking. Both PostHog and GrowthBook publicly position feature flags and experiments as connected capabilities. PostHog's feature flag documentation describes flags as the foundation for safe rollouts, A/B testing, and remote configuration. GrowthBook's experimentation product page emphasizes SQL-based metrics, Bayesian or frequentist analysis, guardrails, and workflow controls.
For AI experimentation, those category capabilities need one more layer: a release-control loop that can handle model routes, prompts, RAG profiles, agent tools, latency, cost, quality review, and cleanup.
Quick Comparison For AI Experimentation
Use this table as a first-pass decision guide. It uses public vendor positioning and documented capabilities as category context, not as a claim that one vendor is universally better.
| Evaluation question | PostHog fit | GrowthBook fit | FeatBit release-control lens |
|---|---|---|---|
| Where does product evidence live? | Strong fit when product analytics, session replay, error tracking, surveys, and AI observability should live in one product suite. | Strong fit when the data warehouse and shared metric definitions are the source of truth. | The flag and exposure record should connect to whichever evidence stack the team trusts. |
| How are experiments created? | Experiments are part of the PostHog product stack, and PostHog AI says it can create multivariate experiments and feature flags with natural language. | Experiments can be deployed by feature flag, visual editor, or URL redirect, with SQL metrics and statistical analysis. | Start with a release hypothesis, then create the flag, metric events, guardrails, and rollback rule together. |
| What makes it AI-specific? | PostHog documents AI observability for traces, generations, and spans, and positions PostHog AI across its product surface. | GrowthBook positions agent-ready development through MCP and REST workflows for flags, experiments, analytics, winner decisions, and stale-code cleanup. | AI changes need stable assignment, exposure events, quality and business metrics, and reversible rollout. |
| Who should own the workflow? | Product engineers who want experimentation close to user behavior, replay, errors, and feedback. | Data, experimentation, and platform teams that want warehouse-native metrics and a rigorous stats engine. | Release owners who need targeting, audit, rollout state, rollback, and lifecycle cleanup. |
| What is the main risk to check? | Do AI quality and business outcomes map cleanly from product events and observability traces to the experiment readout? | Do warehouse metrics arrive quickly and accurately enough for rollback decisions, not only final analysis? | Can the team reduce exposure, pause, roll back, or clean up without redeploying? |
Where PostHog Is Usually Strong
PostHog is compelling when AI experimentation is close to product behavior. If the team wants to see feature exposure, user paths, session recordings, errors, surveys, funnels, and AI observability inside one product engineering workspace, PostHog's all-in-one model is the obvious reason to evaluate it.
That matters for AI products because quality failures often show up in messy product signals:
- a user retries the same prompt several times;
- a support answer leads to escalation;
- an agent workflow increases error tracking noise;
- a session replay shows confusion after a generated answer;
- a survey response explains why a model output felt wrong.
PostHog's AI observability documentation covers traces, generations, and spans for AI and LLM products. Its homepage also says PostHog AI can create multivariate experiments and feature flags with natural language. Those are useful signals if the buyer wants AI-assisted product engineering inside the analytics suite.
The evaluation question is whether that integrated stack gives your team enough release discipline. For AI experimentation, product analytics alone is not enough. You still need stable assignment, exposure logging when the AI behavior actually runs, predefined guardrails, and a rollback path.
Where GrowthBook Is Usually Strong
GrowthBook is compelling when the experimentation program should sit on top of the warehouse. Its documentation states that experimentation should work with existing data and metrics, and its product pages emphasize SQL-defined metrics, visible queries, statistical engines, guardrails, and self-hosted or cloud deployment.
That matters when AI outcomes are not fully visible inside one product analytics tool. For example:
- support resolution may live in a help desk system;
- revenue, retention, and account health may live in the warehouse;
- human review labels may be stored outside the product event stream;
- model cost may be joined from provider logs;
- segment analysis may depend on account or entitlement data.
GrowthBook's feature flag product page says feature flags can become A/B tests and use metrics from the existing warehouse. Its AI-native development page frames agents as able to create flags, configure ramps, query analytics, conclude winners, and clean up stale code through MCP or REST.
The evaluation question is operational speed. Warehouse-native analysis can be powerful, but AI rollout decisions may need near-term guardrails. If a candidate model causes severe quality issues, high fallback rate, or unacceptable latency, the release owner should not wait for a polished final experiment report before reducing exposure.
The Missing Layer: Release-Control Design
PostHog and GrowthBook can both be reasonable choices depending on where evidence lives. The missing layer is the release-control design that makes the experiment safe enough to run.
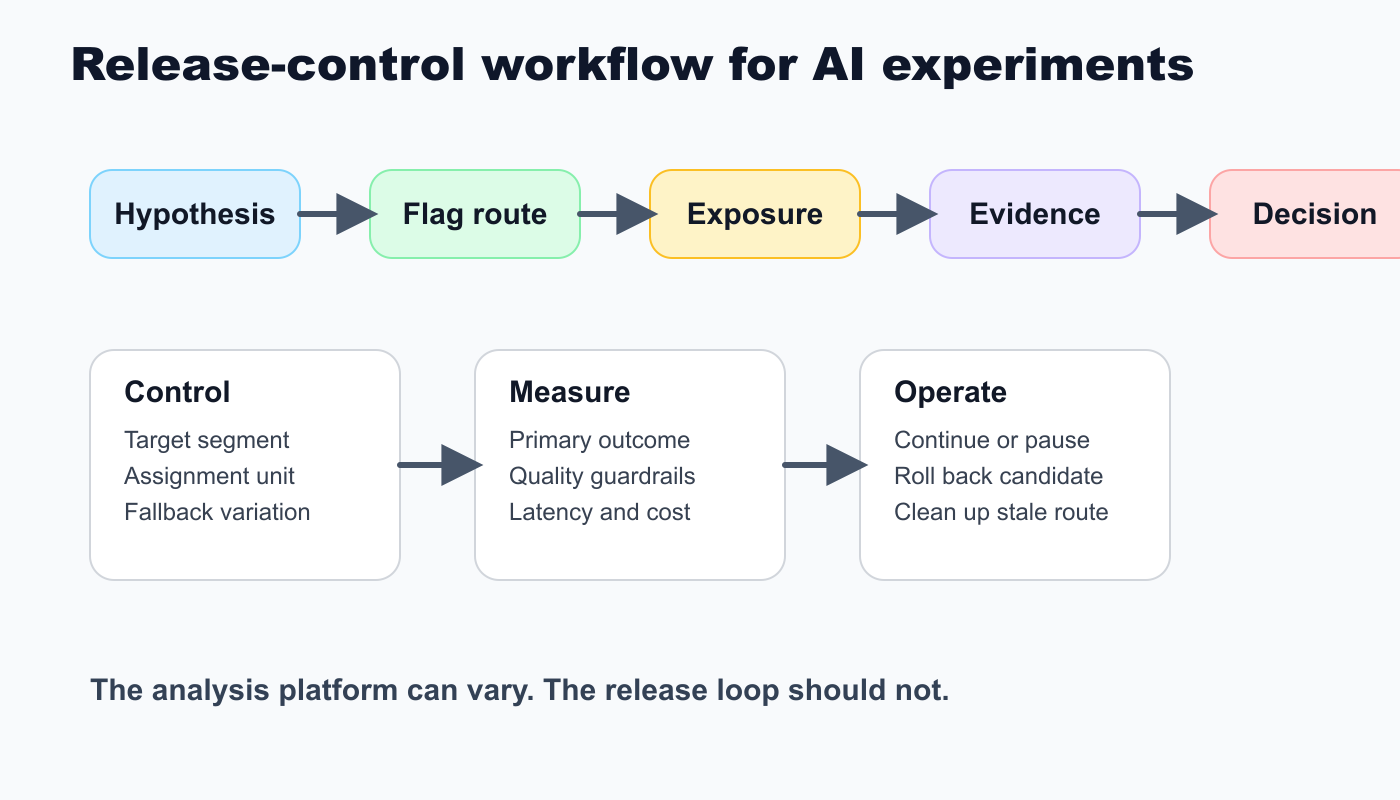
Before comparing vendors, define these release objects:
| Release object | Why it matters for AI experimentation |
|---|---|
| Release hypothesis | Names the AI behavior, eligible audience, expected outcome, decision window, and fallback. |
| Assignment unit | Keeps user, account, conversation, workflow, or request assignment consistent. |
| Runtime flag | Controls prompt, model route, retrieval profile, agent mode, tool policy, or fallback without redeploying. |
| Exposure event | Records the exact variation when the AI behavior actually runs. |
| Outcome event | Connects the assigned variation to business and product impact. |
| Guardrail metrics | Stops expansion when quality, cost, latency, safety, support load, or fallback rate degrades. |
| Rollback rule | Lets the release owner reduce exposure or return to control quickly. |
| Cleanup rule | Prevents temporary experiment flags and model routes from becoming stale control debt. |
FeatBit's release decision framework uses this loop: intent, hypothesis, reversible exposure, measurement, evidence, decision, and learning. The same loop applies whether the analysis screen is PostHog, GrowthBook, FeatBit, a warehouse notebook, or an internal evaluation service.
A Practical AI Experiment Example
Assume a support product wants to test a new AI answer route. The candidate changes the model and retrieval profile, so the team should call it a route experiment rather than a pure model test.
release_hypothesis:
question: should the support assistant use candidate_route_b by default?
expected_outcome: more conversations resolved without human escalation
eligible_scope: paid accounts using English support chat
assignment_unit: conversation_id
decision_window: 14 days
fallback: current_route_a
The runtime flag should represent the route:
flag:
key: support_assistant_answer_route
type: string
variations:
control: current_route_a
candidate: candidate_route_b
fallback: current_route_a
rollout:
internal: employees
canary: 5_percent_eligible_conversations
experiment: 50_50_control_candidate
The exposure event should fire when the route actually runs:
{
"event": "ai_answer_route_exposure",
"flagKey": "support_assistant_answer_route",
"unitId": "conv_1842",
"variation": "candidate",
"modelRoute": "candidate_route_b",
"fallbackUsed": false
}
The outcome event should carry the same join keys:
{
"event": "support_conversation_outcome",
"flagKey": "support_assistant_answer_route",
"unitId": "conv_1842",
"variation": "candidate",
"resolvedWithoutEscalation": true,
"latencyMs": 1840,
"humanCorrection": false
}
PostHog may be the natural place to analyze user behavior, replay, error, and AI trace context. GrowthBook may be the natural place to analyze warehouse-defined outcomes and experiment statistics. FeatBit's measurement design guidance focuses on the pre-work: choose the primary outcome and guardrails before exposure starts.
Decision Checklist: PostHog, GrowthBook, Or FeatBit

Choose or prioritize PostHog when:
- product engineers need analytics, session replay, error tracking, surveys, experiments, and AI observability in one place;
- the main experiment questions are close to user behavior inside the product;
- PostHog AI-assisted setup fits how the team wants to create flags or experiments;
- the team can still define rollback, assignment, and cleanup outside the analytics view.
Choose or prioritize GrowthBook when:
- the data warehouse is the trusted source for metrics and segments;
- experiment rigor, SQL transparency, guardrails, and statistical analysis are central requirements;
- product outcomes need to join across product events, revenue, support, account, or review-label data;
- agent-accessible workflows through MCP or REST are important for the experimentation lifecycle.
Evaluate FeatBit when:
- the primary need is runtime release control for prompts, model routes, retrieval settings, agent modes, or AI-generated code;
- self-hosted or open-source control is part of the platform decision;
- feature flags should carry targeting, rollout state, audit history, rollback, and lifecycle ownership;
- experimentation needs to be connected to progressive rollout, release governance, and cleanup.
This is not an either-or architecture. Some teams use one platform for analytics, another for warehouse experiments, and a flag control plane for release state. The important rule is that one release record should connect assignment, exposure, metrics, guardrails, decision, rollback, and cleanup.
Common Mistakes In AI Experimentation Tool Selection
Comparing dashboards before defining the release question. A dashboard cannot fix a vague hypothesis. Define the AI behavior, audience, outcome, guardrails, and fallback first.
Treating AI observability as experiment evidence by default. Traces, generations, and spans help diagnose behavior. They do not replace stable assignment and outcome attribution.
Waiting for final analysis before rollback. Some AI failures should stop expansion immediately. Guardrails should be connected to rollout state, not only final reports.
Changing too many AI surfaces at once without naming it. If prompt, model, retrieval, and tool policy all change, call it a route experiment and interpret it as a route decision.
Leaving temporary experiment controls in production. After the winning behavior ships, remove the losing route or intentionally convert the flag into an operational control. FeatBit's feature flag lifecycle management model helps keep experiment flags from becoming stale code.
Bottom Line
PostHog is a strong candidate when AI experimentation belongs inside a broad product engineering and analytics suite. GrowthBook is a strong candidate when warehouse-native metrics, transparent SQL, and experimentation rigor are the center of the decision. FeatBit is worth evaluating when the hardest part is not the analysis screen, but the runtime release-control loop: target, expose, measure, decide, roll back, and clean up.
For AI changes, choose the tool stack only after you can answer one operational question: if the candidate behavior starts harming quality, cost, latency, safety, or business outcomes, who can reduce exposure, what evidence will they trust, and how will the team close the release decision?
Source Notes
- PostHog vendor context: PostHog's feature flag documentation, experiments documentation, AI observability documentation, and homepage are used for public positioning around product analytics, flags, experiments, AI observability, and PostHog AI. This article does not claim comparative performance, pricing, security, or market rank.
- GrowthBook vendor context: GrowthBook's documentation overview, experimentation product page, feature flags product page, and AI-native development page are used for public positioning around warehouse-native experimentation, feature flags, guardrails, MCP, REST, and self-hosting. This article does not claim comparative performance, pricing, security, or market rank.
- FeatBit implementation context: AI experimentation, safe AI deployment, release decision framework, measurement design, Bayesian A/B testing for builders, self-hosted feature flags, feature flag lifecycle management, targeting rules, percentage rollouts, experimentation, and the Track Insights API support the release-control workflow described here.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it frames the article as a vendor comparison plus release-control decision guide. - Use
decision-map.pngnear the opening because it shows the difference between analytics-first, warehouse-native, and release-control-first evaluation. - Use
release-control-workflow.pngin the workflow section because it reinforces the loop from hypothesis to cleanup. - Use
evaluation-checklist.pngnear the decision checklist because it turns vendor comparison into a concrete operating-model review.