LaunchDarkly vs GrowthBook for AI Feature Flags: Which Operating Model Fits?
If you are comparing LaunchDarkly vs GrowthBook for AI feature flags, the useful question is not simply which tool can turn an AI feature on. Both vendors connect feature flags to rollout and experimentation, but their public materials point to different operating models.
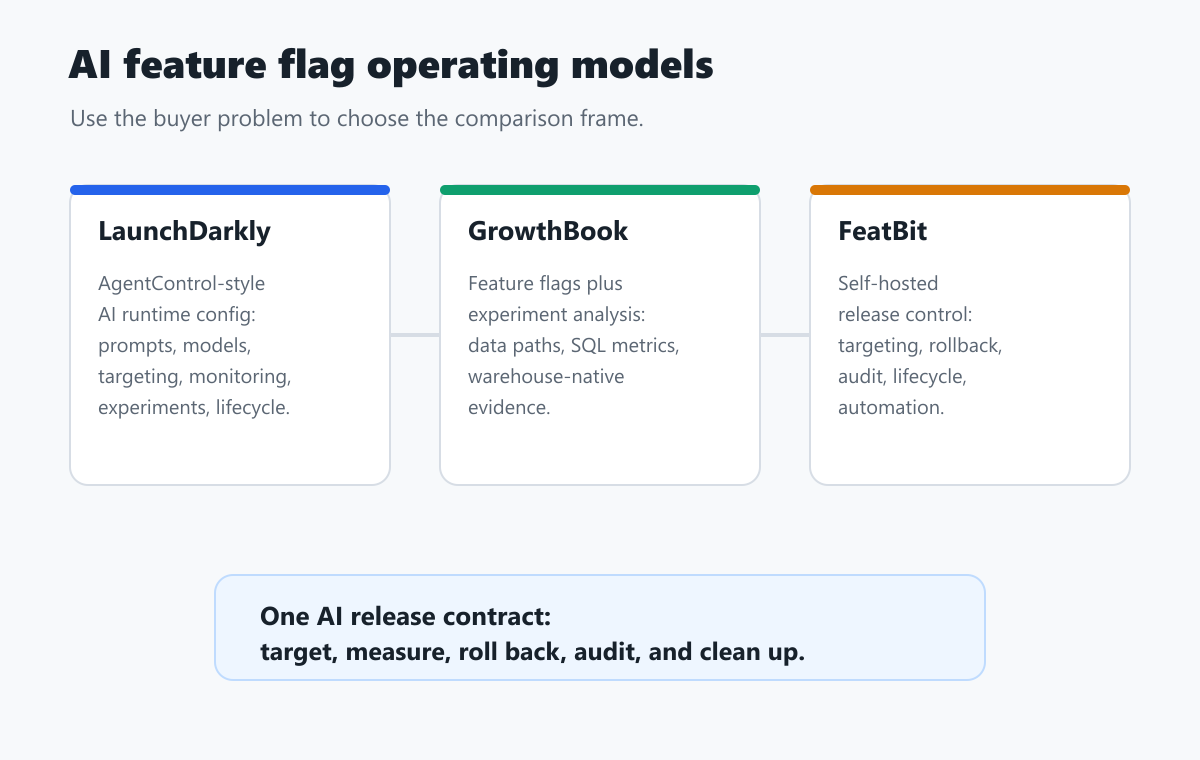
LaunchDarkly is the stronger public reference when the buyer is looking for an AI-specific runtime configuration surface. Its AgentControl documentation describes configs for prompts, instructions, model settings, variations, targeting rules, monitoring, experimentation, and lifecycle management.
GrowthBook is the stronger public reference when the buyer is looking for experimentation and measurement close to the data warehouse. Its docs describe feature flags, experiments, SDK connections, and data paths including managed warehouse, event forwarder, and bring-your-own warehouse options.
For AI feature flags, that distinction matters. A prompt, model route, retrieval profile, tool policy, fallback, or guardrail is not only a configuration value. It is a production release decision. The right comparison is therefore: do you need a managed AI runtime-control workflow, a warehouse-native experiment analysis workflow, or a self-hosted release-control layer around your existing AI stack?
Short Answer
Choose the comparison frame before choosing the vendor.
| Buyer need | LaunchDarkly public fit | GrowthBook public fit | FeatBit fit |
|---|---|---|---|
| AI-specific runtime configuration | Stronger fit when AgentControl matches your architecture, plan, SDK path, and data model. | Possible through flags and experiments, but GrowthBook's public differentiation is less centered on AI config workflow. | Fits when AI execution stays in your app and FeatBit controls release decisions through flags, targeting, rollback, audit, and self-hosting. |
| Warehouse-native analysis | LaunchDarkly has warehouse-native metrics docs, but AgentControl is the clearer AI-specific surface. | Stronger fit when your experiment evidence should be queried in your warehouse or connected data path. | Fits when FeatBit exposure and metric events need to feed an external analysis workflow or a trusted warehouse. |
| Self-hosted release control | Verify current hosting, plan, and data requirements directly with LaunchDarkly. | GrowthBook has self-hosted and warehouse-native positioning to evaluate. | Core FeatBit angle: open-source, self-hosted feature flags, experimentation, audit, lifecycle, APIs, and automation. |
| AI agent or prompt rollout | AgentControl docs are directly relevant. | Evaluate whether flags, feature flag experiments, and data-path choices cover the rollout need. | Use FeatBit as the release-decision layer around prompts, model routes, retrieval, tools, fallbacks, and experiments. |
This is not a ranking. It is a buyer map. LaunchDarkly and GrowthBook solve overlapping but different parts of the AI feature flag problem. FeatBit enters the decision when the team wants release control, data ownership, and automation in a self-hosted or open-source operating model.
What AI Feature Flags Actually Need To Control
AI feature flags are often described as "turning AI on or off." That is too narrow for production systems.
The release decision may be:
- which prompt profile runs for a user, account, conversation, or workflow;
- which model route, provider, fallback, timeout, or cost profile is active;
- which retrieval source, reranker, memory scope, or citation rule is used;
- whether an agent runs in observe-only, search-only, draft, approval-required, or autonomous mode;
- which guardrail threshold, refusal path, or human escalation rule applies;
- which experiment variation receives production traffic;
- which audience should be excluded until legal, security, support, or customer success review is complete.
That means an AI feature flag platform should be evaluated on five jobs:
- Select the right AI behavior before it runs.
- Target the first audience deliberately.
- Record which behavior actually served the request.
- Decide with quality, cost, latency, safety, and business evidence.
- Roll back precisely and clean up temporary controls.
FeatBit's AI control layer and safe AI deployment pages use this release-control frame: expose AI behavior gradually, keep rollback available, and connect the rollout to evidence before broader release.
LaunchDarkly: AI Runtime Configuration Is The Public Center
LaunchDarkly's public AgentControl documentation, reviewed on June 23, 2026, says AgentControl is used to customize, test, and roll out new LLMs in generative AI applications. It describes an AgentControl config as a resource for controlling how an application uses large language models, including prompts, instructions, model settings, variations, targeting rules, monitoring, experimentation, and lifecycle management.
The same documentation distinguishes completion mode from agent mode. Completion mode configures prompts using messages and roles for single-step model responses. Agent mode configures structured, multi-step workflows using instructions. LaunchDarkly also states that tool usage depends on the application and SDK implementation, not only the selected configuration mode.
That gives buyers a clear interpretation: LaunchDarkly is a direct comparison point when the search phrase "AI feature flags" really means "AI Configs" or "AgentControl-style runtime AI configuration."
Evaluate LaunchDarkly first when:
- your team already uses LaunchDarkly for feature management;
- you want an AI-specific config workflow inside that vendor platform;
- prompts, model settings, config variations, targeting, monitoring, experiments, and lifecycle need one managed surface;
- your proof of concept can confirm SDK fit, data flow, plan access, audit needs, and operational ownership;
- the team prefers a managed vendor workflow over assembling release control from separate systems.
The main proof point should not be a demo prompt. It should be a real AI release path: baseline profile, candidate profile, first audience, metric guardrails, rollback rule, audit owner, and cleanup condition.
GrowthBook: Experiment Evidence And Warehouse Context Are The Public Center
GrowthBook's public docs position feature flags and experiments as connected product-development tools. Its feature flag docs route readers through SDK connections, feature basics, environments, targeting, scheduling, and related feature management topics. Its experiment docs describe running experiments and also note that GrowthBook can analyze experiments using custom assignment or another experimentation system when exposure or assignment information is available in a data warehouse.
GrowthBook's warehouse-native architecture page is especially relevant for AI feature flags. It describes querying data where it already lives, using SQL transparency, reproducing results, defining metrics with SQL, and keeping sensitive customer data in the organization's environment depending on deployment and data path.
Its data path docs give a practical architecture split:
- managed warehouse for teams without existing warehouse infrastructure;
- event forwarder for teams that own a warehouse but want GrowthBook to write exposure and custom events into it;
- bring your own warehouse for teams with existing pipelines and analytics infrastructure.
That gives buyers a different interpretation: GrowthBook is a direct comparison point when the search phrase "AI feature flags" really means "How do we run and measure AI experiments using our existing data?"
Evaluate GrowthBook first when:
- the central problem is trustworthy experiment readout, not only runtime configuration;
- product, revenue, support, quality, or operational outcomes already live in a warehouse;
- the data team owns metric definitions in SQL;
- AI rollout evidence needs joins across exposure, outcome, cost, latency, support, and business tables;
- the team wants feature flag experiments or third-party assignment analysis with warehouse-visible data.
For AI behavior, the key requirement is not only feature flag creation. It is whether assignment, exposure, actual AI execution, outcome events, and guardrails can be joined without losing the release decision.

The Comparison That Matters For AI Releases
Use a controlled AI behavior as the comparison unit. For example:
release_decision:
flag_key: support_answer_profile
baseline: support_baseline_v3
candidate: citation_first_v4
controlled_surfaces:
- prompt_profile
- retrieval_profile
- fallback_behavior
assignment_unit: account
first_audience: internal_support_users
rollout_path:
- internal
- 5_percent_beta_accounts
- 25_percent_eligible_accounts
primary_metric: resolved_without_escalation
guardrails:
- citation_failure_rate
- p95_latency
- fallback_rate
- estimated_cost_per_case
rollback: return_targeted_accounts_to_support_baseline_v3
cleanup: promote_winner_or_remove_candidate_after_decision
Then ask each platform to prove the same contract.
| Evaluation area | Why it matters | What to verify |
|---|---|---|
| Evaluation point | The AI behavior must be selected before prompt assembly, retrieval, model routing, or tool execution. | Can your application evaluate the control in the trusted runtime that owns the AI call? |
| Targeting context | AI behavior often varies by account, plan, region, environment, workflow, risk tier, or segment. | Can the platform target the contexts your rollout actually needs? |
| Structured variation | AI flags usually need string, number, or JSON profiles, not only boolean states. | Can the returned value express a reviewed behavior profile with a safe fallback? |
| Evidence loop | AI releases need quality, latency, cost, fallback, correction, support, and business evidence. | Can variation assignment be joined to the events that decide continue, pause, rollback, or cleanup? |
| Rollback precision | A bad prompt or retrieval profile should not force the whole AI system off. | Can one audience or behavior return to baseline without redeployment? |
| Governance | AI config changes can affect customer trust and operational policy. | Can reviewers reconstruct who changed what, when, why, and which audience was affected? |
| Lifecycle cleanup | Temporary prompt, model, and experiment flags can become production debt. | Does the platform help define owner, expected lifetime, decision rule, and cleanup path? |
This contract makes the comparison concrete. LaunchDarkly may fit if the AgentControl workflow owns enough of the AI runtime configuration job. GrowthBook may fit if the warehouse-native evidence loop is the harder problem. FeatBit may fit if the team wants a self-hosted release-control layer around an AI stack it already owns.
Where FeatBit Fits Beside Both
FeatBit should not be described as LaunchDarkly AgentControl or as GrowthBook's warehouse-native experimentation product. The stronger positioning is simpler: FeatBit is release-decision infrastructure for teams that want feature flags, experimentation, progressive rollout, rollback, auditability, lifecycle management, APIs, automation, and self-hosted control in one operating model.
For AI feature flags, that means FeatBit can sit around your existing AI execution layer:
- Your application or AI gateway owns prompts, model calls, retrieval, tools, guardrails, and fallbacks.
- FeatBit evaluates the release decision: which approved profile should run for this user, account, environment, workflow, or percentage.
- The application records the served variation and execution facts.
- FeatBit insights, Track Insights events, experiments, observability integrations, or exported data help the team decide.
- Operators expand, pause, roll back, or clean up through the same release-control loop used for ordinary software.
That model is useful when:
- AI config metadata or rollout history should stay close to your infrastructure;
- platform teams want one governance model for AI and non-AI releases;
- the organization already has a prompt registry, model gateway, observability stack, or data warehouse;
- rollout and rollback matter more than a dedicated prompt-editing UI;
- AI coding agents need API, CLI, MCP, or skill-based automation around flag work;
- temporary AI controls need lifecycle rules before they multiply.
For implementation context, see FeatBit docs for create flag variations, targeting rules, percentage rollouts, flag insights, Track Insights API, and feature flag lifecycle management.
A Practical Trial Plan
Do not compare LaunchDarkly, GrowthBook, and FeatBit with a generic feature checklist. Use one real AI behavior and test the release loop.
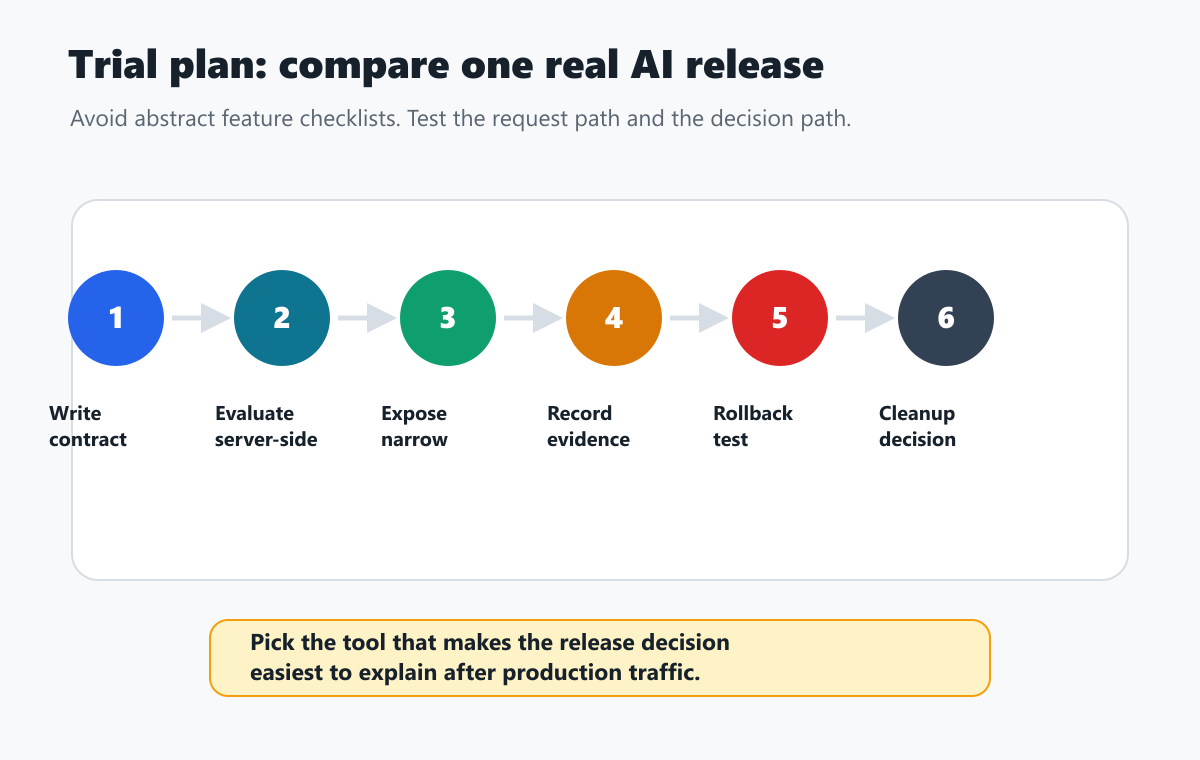
- Pick one AI behavior that is meaningful but not tied to regulated data access, billing, permissions, or irreversible side effects.
- Write the release-control contract: controlled surface, fallback, assignment unit, first audience, rollout stages, primary metric, guardrails, rollback, and cleanup.
- Implement server-side evaluation before the AI behavior runs.
- Record exposure only when the AI path actually uses the selected behavior.
- Send or join outcome evidence: quality, latency, cost, fallback, correction, support, and business signals.
- Test rollback for one audience without redeploying code.
- Review audit history and operational ownership.
- Decide which operating model felt natural: managed AI runtime config, warehouse-native measurement, or self-hosted release control.
The winning tool is the one that makes the release decision easier to explain after production traffic has seen the candidate behavior.
Common Mistakes In This Comparison
Comparing landing page language instead of request-path control. AI feature flags matter at the point where the application chooses a prompt, model route, retrieval profile, tool policy, or fallback.
Treating experiment readout as rollback. Analysis can tell you a candidate is risky. The release-control layer still needs a prepared rollback path.
Using one global AI switch. A kill switch is useful during incidents, but normal rollout needs narrower controls for prompt profile, model route, retrieval, tool authority, fallback, and experiment exposure.
Ignoring assignment units. AI experiments can assign by user, account, conversation, session, workflow, or request. Choose the unit before rollout and keep it consistent in exposure and outcome events.
Forgetting data boundaries. Prompt metadata, config changes, evaluation traces, audit history, and outcome events can contain sensitive operational context. Decide where those records should live before standardizing on a hosted, self-hosted, or hybrid workflow.
Leaving AI controls forever. Temporary release flags need owners, evidence rules, and cleanup conditions. Otherwise the control plane becomes release debt.
Bottom Line
LaunchDarkly vs GrowthBook for AI feature flags is not one simple feature-by-feature contest.
LaunchDarkly is the clearer public comparison point when the buyer wants an AI-specific runtime configuration workflow through AgentControl. GrowthBook is the clearer public comparison point when the buyer wants experimentation and warehouse-native measurement around feature flags and product outcomes.
FeatBit is the evaluation path when the team wants a self-hosted release-control layer around AI behavior: targeted rollout, structured variations, audit, rollback, experimentation, lifecycle cleanup, APIs, and automation without moving the whole AI execution stack into a single vendor-specific AI config product.
The practical decision is this: pick the platform whose operating model can make one real AI release targetable, measurable, reversible, auditable, and clean after the decision.
Source Notes
- LaunchDarkly vendor context: LaunchDarkly's AgentControl documentation, reviewed June 23, 2026, is used for public claims about configs, completion mode, agent mode, prompts, model settings, variations, targeting rules, monitoring, experimentation, lifecycle management, and application-side tool implementation.
- LaunchDarkly solution context: LaunchDarkly's Control AI Agents solution page is used as category context for runtime control language around production AI agents.
- GrowthBook vendor context: GrowthBook's feature flag documentation, experiment documentation, warehouse-native architecture page, and choose your data path documentation are used for public claims about feature flags, experiments, custom assignment analysis, warehouse-native positioning, and data-path options.
- FeatBit implementation context: FeatBit's AI control layer, safe AI deployment, AI experimentation, self-hosted feature flags, feature flag lifecycle management, Track Insights API, and targeting rules support the release-control workflow described here.
- Related FeatBit reading: which feature flag platform supports AI Configs, LaunchDarkly AI Configs alternative, warehouse-native measurement for AI feature flags, and vendor-agnostic AI feature flags.
- This article avoids unsupported comparative claims about performance, pricing, security, compliance, customer outcomes, or market rank. It compares public product positioning and practical evaluation criteria.
Image And Open Graph Notes
- Use
/images/blogs/launchdarkly-vs-growthbook-for-ai-feature-flags/cover.pngas the Open Graph image because it frames the page as a vendor comparison for AI feature flag operating models. - Use
operating-model-map.pngnear the opening because it shows the managed AI runtime configuration, warehouse-native measurement, and self-hosted release-control split. - Use
decision-checklist.pngin the comparison section because it summarizes the buyer criteria. - Use
trial-workflow.pngnear the trial plan because it turns the comparison into an implementation test.