Warehouse-Native Measurement for AI Feature Flags: Keep Release Evidence Joinable
Warehouse-native measurement means the evidence for a release decision can be analyzed where the team's product, revenue, support, quality, and operations data already live.
For AI feature flags, that is more than a reporting preference. A prompt, model route, retrieval profile, agent tool policy, or fallback mode can change quality, latency, cost, support workload, and business outcomes at the same time. If the flag assignment lives in one tool and the outcome evidence lives somewhere else, the release owner may not be able to explain whether the AI behavior should expand, pause, roll back, or be cleaned up.
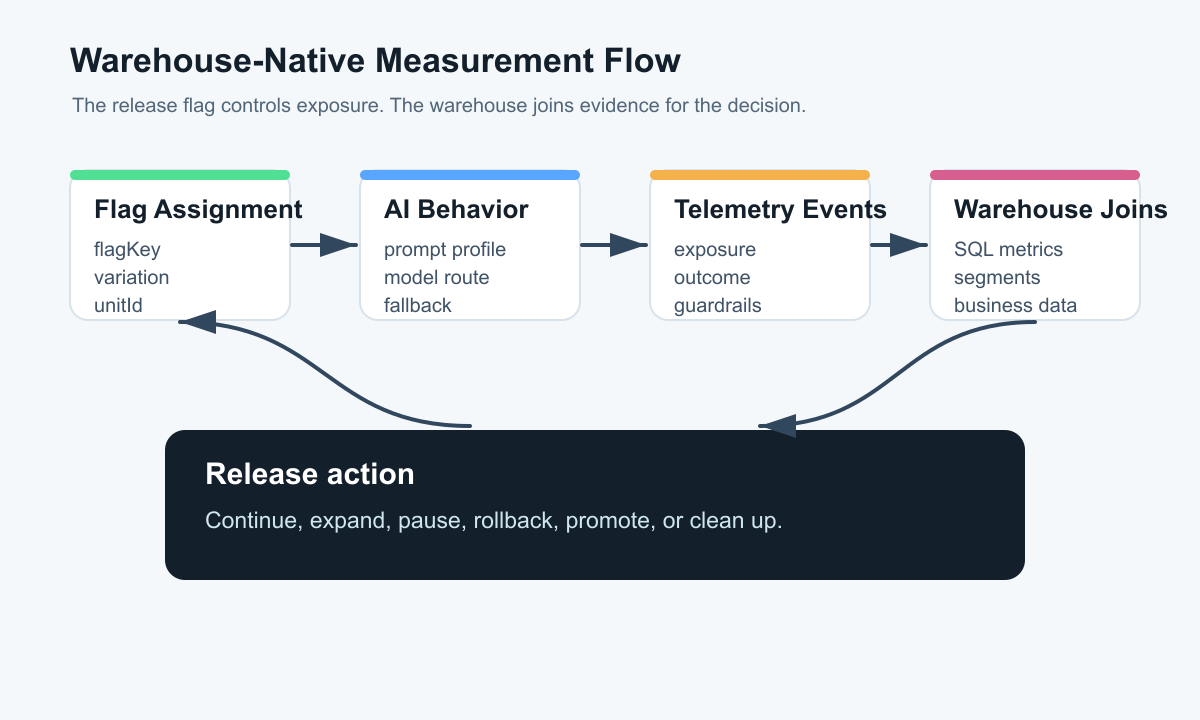
The useful reader job is architecture: design the measurement contract so assignment, exposure, outcome, guardrail, and rollback evidence can be joined in a warehouse or warehouse-like analytical store without turning the feature flag tool into the only source of truth.
What Warehouse-Native Measurement Means
Warehouse-native measurement is the practice of keeping analysis close to the organization's analytical source of truth. In experimentation, it usually means exposure data and metric data are queryable in the warehouse, or can be connected to it, so the team can use existing business definitions, joins, cohorts, and governance rules.
GrowthBook uses the phrase prominently in its positioning. Its warehouse-native architecture page describes querying data in a warehouse with visible SQL, and its docs describe paths such as managed warehouse, event forwarder, and bring-your-own warehouse for experiment data. Those public materials are useful category context, not a requirement that every release-control platform must work identically.
FeatBit's angle is release-decision infrastructure. The feature flag is the runtime control point: who is eligible, which AI behavior runs, what variation was served, and how exposure can be reduced or rolled back. Warehouse-native measurement is the evidence design around that control point: can the team join the flag decision to the product outcome, operational guardrails, and business context that decide the release?
Why AI Feature Flags Need Joinable Evidence
Traditional feature experiments often measure a visible UI change against a conversion event. AI features are messier.
An AI release may change:
| AI surface | Measurement risk if data is not joinable |
|---|---|
| Prompt profile | Quality reviews may not map back to the prompt variation that generated the answer. |
| Model route | Cost, latency, fallback, and business outcome may live in separate systems. |
| Retrieval profile | A success metric may improve while citation coverage or no-answer rate gets worse. |
| Agent tool policy | A workflow may complete faster while approval overrides or incident risk increase. |
| Guardrail mode | A safer configuration may reduce risk while damaging task completion or support load. |
For these releases, a dashboard that only says "candidate received traffic" is not enough. The release owner needs a join path from flag evaluation to actual AI execution to the outcome and guardrails.
FeatBit's measurement design guidance separates the primary success metric from guardrails. Warehouse-native measurement extends that discipline into the data model: every event that matters should carry enough shared identifiers to support the decision.
The Minimum Measurement Contract
Before an AI feature flag moves beyond internal traffic, write a measurement contract. It does not need to be complex, but it must make the join keys explicit.

At minimum, the contract should name:
| Contract field | Why it matters |
|---|---|
flagKey |
Names the release decision being evaluated. |
variation |
Identifies control, candidate, fallback, or policy mode. |
assignmentUnit |
Defines whether the experiment unit is user, account, conversation, session, workflow, or request. |
unitId |
Joins assignment, exposure, outcome, and guardrail events. |
behaviorProfile |
Names the prompt, model route, retrieval profile, agent policy, or fallback that actually ran. |
timestamp |
Supports windows, freshness checks, delayed outcomes, and incident review. |
environment |
Keeps production evidence separate from staging or internal test data. |
decisionState |
Records continue, expand, pause, rollback, promote, or cleanup. |
The important rule is that the same assignment unit appears everywhere. If the flag is evaluated by conversation, the outcome event should not be recorded only by user. If the release decision is by account, support tickets, revenue impact, and guardrails should be joinable to that account assignment.
A Practical Event Shape
For a support assistant prompt rollout, the feature flag might select a behavior profile:
flag:
key: support_assistant_profile
assignmentUnit: conversation
variations:
control:
promptProfile: support_v3
modelRoute: stable
retrievalProfile: baseline
candidate:
promptProfile: support_v4
modelRoute: stable
retrievalProfile: citation_first
fallback:
promptProfile: support_v3
modelRoute: stable
retrievalProfile: baseline
The exposure event should fire when the AI behavior actually runs, not when the page loads:
{
"event": "ai_feature_exposure",
"flagKey": "support_assistant_profile",
"assignmentUnit": "conversation",
"unitId": "conv_83921",
"accountId": "acct_1729",
"variation": "candidate",
"promptProfile": "support_v4",
"modelRoute": "stable",
"retrievalProfile": "citation_first",
"fallbackUsed": false,
"environment": "production",
"timestamp": "2026-06-23T09:15:30Z"
}
The outcome and guardrail events should carry the same join fields:
{
"event": "support_conversation_outcome",
"flagKey": "support_assistant_profile",
"assignmentUnit": "conversation",
"unitId": "conv_83921",
"accountId": "acct_1729",
"variation": "candidate",
"resolvedWithoutEscalation": true,
"humanCorrection": false,
"latencyMs": 1840,
"estimatedCostUsd": 0.014,
"timestamp": "2026-06-23T09:18:44Z"
}
This shape works whether analysis happens inside an experimentation system, in a warehouse, in a BI tool, or in a notebook. The contract keeps the release decision portable.
FeatBit's Track Insights API supports sending feature flag variation results and custom metric events for analytics and experimentation. For teams that need warehouse-side analysis, FeatBit's data export documentation describes how feature flag usage data and experiment events can be extracted from ClickHouse or MongoDB, depending on deployment edition.
Where The Warehouse Fits
The warehouse should not be asked to control production behavior. It should help explain production behavior after the runtime decision has happened.
Keep the responsibilities separate:
| Layer | Owns | Should not own alone |
|---|---|---|
| Feature flag control plane | targeting, percentage rollout, variation assignment, rollback, audit history | full business metric definitions |
| Application or AI gateway | prompt assembly, model call, retrieval, fallback, exposure event emission | hidden experiment assignment with no release owner |
| Warehouse or analytics store | joins across exposure, outcome, revenue, support, quality, and operational data | runtime rollback or targeting |
| Experiment analysis | metric readout, segment review, confidence, decision recommendation | production control without a flag owner |
| Observability stack | traces, logs, errors, latency, cost, incident context | the final product release decision |
This boundary is especially important for AI features because fallback behavior can make intended assignment different from actual exposure. A candidate route may be assigned, then timeout and fall back to control. The warehouse event model should preserve that distinction.
FeatBit Implementation Path
FeatBit does not need to own every analytical workflow to support warehouse-native measurement. It needs to make the release decision visible, reversible, and measurable.
A practical path looks like this:
- Create a typed flag for the AI behavior profile, such as a string or JSON variation.
- Evaluate the flag where the AI behavior is selected: server, model gateway, workflow service, or agent runtime.
- Use an assignment unit that matches the user journey: account, user, conversation, session, workflow, or request.
- Emit exposure only when the assigned behavior actually runs.
- Send custom metric events through FeatBit when the release owner needs in-product experiment analysis.
- Export or sync event data when the data team needs warehouse joins with revenue, support, product usage, or quality-review tables.
- Record rollback, pause, expand, and cleanup decisions alongside the evidence.
FeatBit's GrowthBook integration documentation shows one concrete pattern: connect FeatBit ClickHouse data to GrowthBook, add experiment assignment queries, add metric SQL, and analyze an existing experiment. That is not the only possible architecture. It is evidence that FeatBit flag events can participate in an external analysis workflow when the team wants warehouse-style SQL analysis.
For broader release-control context, connect this article to FeatBit's AI experimentation, safe AI deployment, AI control layer, and feature flag lifecycle management pages.
Decision Checklist
Use warehouse-native measurement when the release decision depends on data that already lives outside the feature flag tool.

It is usually worth the extra event design when:
- the AI feature affects revenue, support workload, quality review, compliance workflow, or operational cost;
- the data team already owns metric definitions in SQL;
- outcomes are delayed or spread across several systems;
- the rollout needs segment-level review by account, plan, region, risk tier, or workflow;
- the team wants to reproduce surprising results outside the vendor dashboard;
- self-hosted or private deployment makes data locality important.
It may be overkill when:
- the flag is a short-lived internal toggle with no user impact;
- the only metric is simple feature usage inside one application;
- the decision can be made from operational health alone;
- no one owns the downstream warehouse model or event quality.
The deciding question is simple: if the candidate wins or fails, can the team explain why using the data system it already trusts?
Common Failure Modes
Tracking assignment but not actual exposure. AI systems can skip, timeout, degrade, or fall back. Record what actually served the request.
Changing the assignment unit midstream. Moving from request-level assignment to conversation-level assignment during an experiment can corrupt the result. Choose the unit before exposure.
Leaving metrics as dashboard-only configuration. If the data team cannot reproduce the metric definition or join it to business context, the release decision may not be trusted.
Sending sensitive prompt or transcript text into every analytics event. Store sensitive text in governed systems of record. Measurement events usually need behavior profile names, join keys, outcomes, and guardrails, not full content.
Treating warehouse analysis as rollback. Analysis can explain risk. The release flag still needs a prepared rollback or scoped exclusion path.
Ignoring cleanup. After the decision, remove losing branches, archive temporary flags, or document long-lived operational controls. FeatBit's lifecycle model keeps warehouse evidence from becoming stale runtime logic.
Bottom Line
Warehouse-native measurement for AI feature flags is not a slogan. It is an event and ownership contract.
Use the flag to control assignment, exposure, targeting, and rollback. Use telemetry and warehouse joins to explain what happened to quality, cost, latency, support load, and business outcomes. Use the release decision to expand, pause, roll back, promote, or clean up.
That separation keeps AI release work honest: runtime control stays reversible, measurement stays reproducible, and the evidence can travel to the analytical system the organization already trusts.
Source Notes
- Category context: GrowthBook's warehouse-native architecture page describes querying warehouse data with visible SQL, and GrowthBook's data path documentation describes managed warehouse, event forwarder, and bring-your-own warehouse options. This article uses those sources to explain market language, not to rank vendors.
- Experimentation context: GrowthBook's running experiments documentation describes feature flag experiments, server-side experiments, custom assignment, and analysis when exposure information is available in a warehouse.
- FeatBit implementation context: FeatBit's Track Insights API, data export documentation, GrowthBook integration documentation, measurement design, AI experimentation, safe AI deployment, AI control layer, and feature flag lifecycle management support the workflow described here.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes warehouse-native measurement as a joinable evidence layer for AI feature flags. - Use
measurement-flow.pngnear the opening because it shows the end-to-end path from flag assignment to warehouse analysis and release action. - Use
measurement-contract.pngin the measurement contract section because it turns the abstract join-key guidance into a concrete data model. - Use
decision-checklist.pngin the checklist section because it helps readers decide whether warehouse-native measurement is necessary for a specific AI release.