What Is a Cost Guardrail Flag? A Practical Definition for AI Releases
A cost guardrail flag is a feature flag that controls an AI behavior based on a predefined spend, token, or unit-cost boundary. It does not merely report that an LLM workflow is expensive. It decides what should happen before the next stage of exposure expands: keep the current route, pause rollout, switch to a cheaper profile, require approval, or roll back to a fallback.
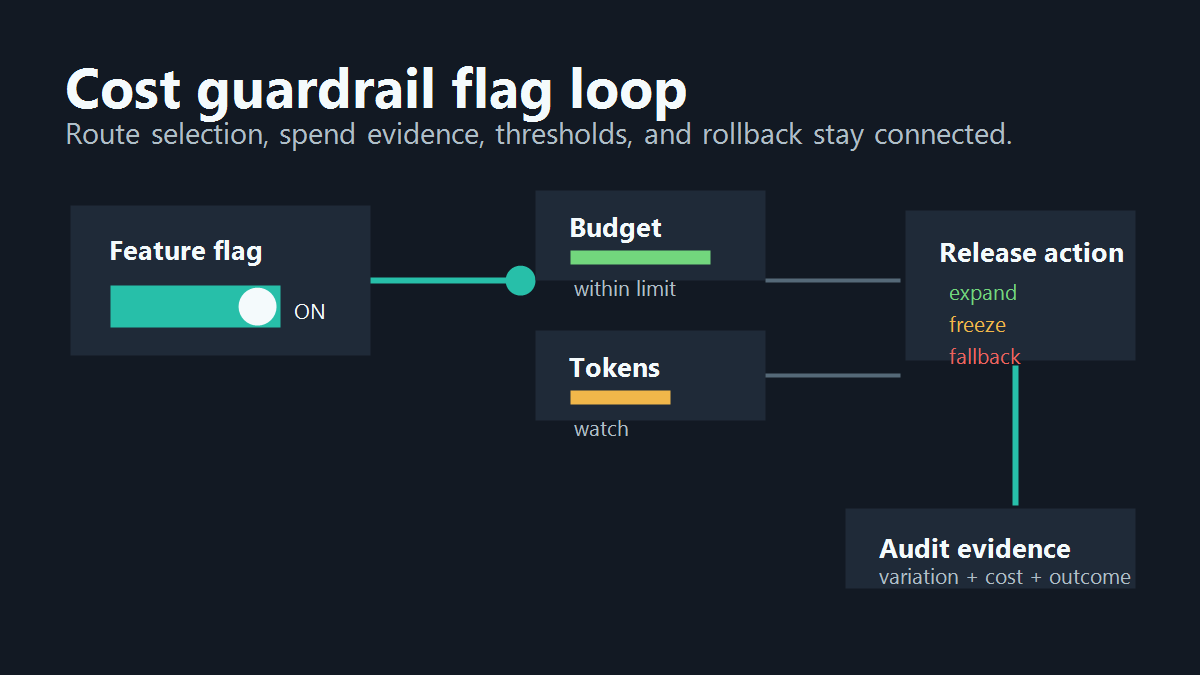
The useful mental model is simple: a billing dashboard tells you what happened; a cost guardrail flag gives the application a reversible control point before the budget problem spreads.
The Short Definition
A cost guardrail flag has four parts:
| Part | What it means | Example |
|---|---|---|
| Cost boundary | The budget, token, or unit-cost limit that must hold | p95 cost per resolved case must stay under the approved target |
| Controlled behavior | The AI route, prompt, retrieval depth, tool mode, or fallback that can change | support_ai_route = balanced_v2 |
| Evidence source | The usage and outcome events that prove whether the boundary holds | token count, provider charge estimate, route, account tier, outcome |
| Release action | The decision allowed when the boundary is crossed | pause rollout, reduce percentage, fall back, require approval |
This makes a cost guardrail flag different from a generic "AI cost alert." An alert asks someone to look at a dashboard. A flag gives the system and release owner a prepared action path.
When Teams Need One
Use a cost guardrail flag when an AI change can change spend faster than the normal release process can react.
Common examples include:
- moving a workflow from a smaller model to a stronger model;
- increasing retrieval depth or context window size;
- enabling an agent tool that can trigger more model calls;
- testing a prompt that improves quality but produces longer answers;
- expanding an AI assistant from internal users to paying customers;
- giving high-value accounts a premium route while keeping standard accounts on a lower-cost route.
OpenAI's production guidance separates cost monitoring from application design: teams can set notification thresholds and use usage dashboards, but production cost planning still depends on token utilization, traffic, interaction frequency, and model choice. A cost guardrail flag sits inside that application design. It turns the cost plan into runtime behavior instead of leaving it as a monthly review.
What It Should Control
The flag should not usually expose raw provider prices or arbitrary model names across the codebase. It should return a reviewed profile that the application can enforce.
| Flag variation | Intended behavior | Cost posture | Fallback |
|---|---|---|---|
control |
Existing stable AI route | Known baseline | Keep current route |
balanced_v2 |
Candidate prompt and model route | Allowed for canary traffic | Return to control |
economy_fallback |
Smaller model, shorter context, stricter tool budget | Used when guardrail is at risk | Disable premium route |
manual_review |
Human approval before expansion | Used for high-risk accounts | Hold rollout |
That profile can include model route, token budget, retrieval limit, timeout, cache policy, and fallback behavior. The important point is that the flag returns a named operating mode, not a loose bag of knobs that anyone can combine in unsafe ways.
A Practical Flag Contract
Write the guardrail contract before traffic moves. A release owner should be able to read the contract and understand what the flag controls, what evidence matters, and what action is allowed.

flag: support_ai_cost_guardrail
owner: platform-ai
controlled_behavior:
route: support_assistant_route
profile_values:
- control
- balanced_v2
- economy_fallback
assignment_unit: conversation
cost_boundary:
primary_guardrail: cost_per_resolved_case
warning_threshold: "10% above baseline for two consecutive hours"
rollback_threshold: "20% above baseline or monthly budget burn-rate breach"
evidence_fields:
- flag_variation
- route_profile
- model_family
- input_tokens
- output_tokens
- estimated_provider_cost
- conversation_id
- account_tier
- resolution_outcome
release_actions:
warning: freeze rollout percentage
breach: switch affected segment to economy_fallback
severe_breach: roll back to control and require owner approval
cleanup_rule: archive after route becomes default or rejected
The thresholds above are examples, not universal targets. The right boundary depends on your pricing model, margin, traffic shape, customer commitments, and whether cost should be judged per request, per successful task, per account, or per business outcome.
Where It Runs In The Request Path
Evaluate the cost guardrail flag before the expensive AI call. If the system waits until after the model call to decide that the route was too expensive, the flag becomes reporting metadata rather than a control.
A typical request path looks like this:
- The application receives the request with user, account, region, plan, workflow, and risk context.
- The server evaluates the cost guardrail flag and receives a reviewed route profile.
- The model gateway enforces token budget, retrieval depth, timeout, and fallback rules from that profile.
- The application records the served variation, estimated usage, outcome, latency, and fallback state.
- The release owner reviews guardrail evidence before expanding, freezing, or rolling back exposure.
This is why sensitive AI cost control usually belongs server-side. The browser can display the final experience, but provider spend, model routing, and fallback enforcement should be decided where the application can protect budgets and audit the result.
Cost Guardrail Flag Vs Related Controls
| Control | Main job | Why it is not enough by itself |
|---|---|---|
| Provider billing limit | Caps or alerts on account-level spend | Too coarse for per-feature rollout decisions |
| Rate limit | Controls request volume | May not reflect token usage, model route, or task value |
| Observability alert | Tells humans a threshold moved | Does not define the runtime action |
| Experiment guardrail metric | Detects harm during a test | Needs a flag or release workflow to change exposure |
| Cost guardrail flag | Connects cost evidence to exposure control | Still needs telemetry, ownership, and cleanup |
The flag should work with these controls, not replace them. Provider limits protect the account. Rate limits protect capacity. Observability tells the team what changed. The cost guardrail flag decides how the release should behave when cost evidence changes.
How FeatBit Fits This Pattern
FeatBit's angle is release-decision infrastructure: a feature flag should connect exposure, evidence, rollback, and lifecycle decisions. For cost guardrail flags, that means the flag is not just a remote setting. It is the runtime control point for who receives an AI route, which profile runs, how quickly exposure expands, and what rollback path is allowed.
In FeatBit, the relevant building blocks are:
- targeting users with flags to restrict a costly AI route by user, account, plan, risk segment, or percentage rollout;
- flag insights to observe variation exposure over time;
- Track Insights API to send feature flag variation results and custom metric events for analysis;
- audit logs to review who changed the flag and when;
- feature flag lifecycle management to keep temporary guardrail flags from becoming permanent release debt.
For AI releases, this also connects naturally to FeatBit's AI control layer, safe AI deployment, and measurement design guidance.
Design Questions Before You Create One

Before creating a cost guardrail flag, answer these questions:
- What is the unit of cost that matters: request, conversation, resolved case, account, workflow, or monthly budget burn rate?
- What is the business outcome that prevents false savings, such as task completion, resolution, conversion, or review acceptance?
- Which AI behavior can the flag change without redeploying?
- Which segments should be protected first if spend rises?
- Who can approve expansion after a warning threshold?
- What fallback is safe, tested, and acceptable to users?
- Which telemetry fields prove what variation actually ran?
- When should the flag be archived or converted into a normal configuration policy?
The outcome question matters. A route that cuts token cost by 30 percent but doubles escalations may be worse than the baseline. A cost guardrail should protect margin without silently damaging the product outcome.
Common Mistakes
Using monthly spend as the only signal. Monthly spend is important for finance, but it is often too late and too aggregated for release control. Use unit-level signals such as cost per successful task or cost per resolved case when possible.
Letting the flag return raw model names everywhere. This couples product logic to provider implementation. Use named route profiles so the application can change provider, model, timeout, or fallback policy behind the profile.
Forgetting assignment and exposure events. If you cannot join the flag variation to usage and outcome events, you cannot tell whether the candidate route actually caused the cost change.
Rolling back all users when only one segment breached. Cost problems are often segment-specific. Enterprise accounts, long documents, complex workflows, or one region may drive the breach. Targeted rollback keeps the rest of the release moving.
Leaving the flag alive forever. A cost guardrail flag needs an owner, decision date, and end state. Promote the chosen route into normal configuration, reject the candidate, or keep the guardrail as an explicit operational control with review rules.
FAQ
Is a cost guardrail flag only for LLMs?
No. It is most common in LLM and agent systems because token usage can change quickly, but the same pattern applies to any runtime behavior where a release can affect variable cost.
Is it the same as a kill switch?
No. A kill switch usually disables behavior. A cost guardrail flag can do that, but it can also reduce rollout percentage, switch to a cheaper route, require approval, or protect only the segment that breached the boundary.
Should the threshold be automatic?
Not always. Some thresholds can trigger an automatic fallback for low-risk traffic. Higher-risk or commercially sensitive changes may require owner approval before expansion or rollback. The contract should say which action is allowed.
Can one flag control quality and cost together?
Sometimes, if the values form one reviewed route profile. If cost, quality, safety, and latency can move independently, use a primary release flag plus separate guardrail metrics or separate operational flags.
Bottom Line
A cost guardrail flag is the bridge between AI cost evidence and release action. It helps teams spend intentionally: route the right users to the right AI profile, watch unit cost beside product outcome, and change exposure before a budget issue becomes an incident.
Source Notes
- OpenAI's production best practices were used for the distinction between provider-level usage limits, notification thresholds, usage dashboards, token utilization, and application-level cost planning: OpenAI production best practices.
- FeatBit product context came from official docs for targeting users with flags, flag insights, Track Insights API, and audit logs.
- Category context was checked against official feature flag documentation from PostHog and GrowthBook targeting conditions. The article does not make ranking, pricing, or superiority claims about those vendors.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it shows the core concept: a flag connecting budget, token, rollout, and fallback controls. - Use
cost-guardrail-loop.pngnear the opening because it explains why the flag is an action layer, not only a dashboard. - Use
cost-guardrail-contract.pngin the contract section because the reader needs a concrete schema for owner, thresholds, evidence, and release action. - Use
cost-guardrail-checklist.pngin the design section because it summarizes the questions a release owner should answer before creating the flag.