Monitor AI Guardrails for Latency, Cost, Quality, and Safety
Monitoring AI guardrails means watching the signals that can stop, narrow, or reverse an AI release before the rollout becomes too broad. For most production AI teams, the useful guardrail set starts with latency, cost, quality, and safety because those four signals decide whether a prompt, model route, retrieval profile, guardrail mode, or agent workflow can keep expanding.
The dashboard is only useful when it is tied to release action. A latency chart, cost chart, quality score, or safety counter can describe what happened. A guardrail dashboard should also tell the release owner what to do next: continue, pause, narrow exposure, switch to approval, fall back, or roll back.
This article focuses on that operational dashboard and alert loop. It is distinct from a broad AI Insights overview: the reader job here is to define thresholds, owners, alert routing, and release actions for the four guardrails that usually decide whether an AI rollout is safe enough to continue.

The Guardrail Dashboard Should Answer One Question
The dashboard should answer: "Is this AI behavior still safe enough for the current rollout stage?"
That question is narrower than "Is the AI system healthy?" A model provider may be available while the product experience is too slow. A prompt may score well in an offline eval while live users reject the answer. A cheaper route may reduce spend while lowering task completion. A safety filter may block risky outputs but create too many false positives for one workflow.
Use the dashboard to connect each signal to a rollout decision:
| Guardrail | What to monitor | Why it matters | Typical release action |
|---|---|---|---|
| Latency | p95 or p99 response time, timeout rate, queue delay, provider retry time | AI changes often move tail latency before average latency looks bad | pause expansion, reduce traffic, switch to faster route |
| Cost | tokens, tool calls, provider spend estimate, cost per successful task | A candidate can improve quality while becoming uneconomical at scale | cap exposure, route high-cost segments to baseline, review budget |
| Quality | reviewer rejection rate, correction rate, evaluator score, fallback rate, complaint rate | Average quality can hide severe failures or segment harm | hold rollout, repair prompt or retrieval, run a narrower canary |
| Safety | policy violations, unsafe output reports, approval bypasses, high-risk false negatives | Some failures require containment even when product metrics look good | roll back, require approval, disable risky mode or tool |
FeatBit's view is that these are release signals, not passive analytics. The served flag variation, rollout stage, audience, owner, and rollback path should appear beside the metric so operators can act without guessing which change caused the signal.
Start With A Guardrail Contract
Write the monitoring contract before the first external user sees the AI change. The contract does not need to be complicated. It should name the behavior, the rollout stage, the four guardrails, the owner, and the action attached to each breach.
ai_guardrail_monitoring:
release_question: should_support_assistant_v4_expand_from_5_to_25_percent
flag_key: support_assistant_route
candidate_variation: citation_first_v4
baseline_variation: stable_support_v3
assignment_unit: account_id
current_stage: canary_5_percent
owner: support_ai_release_owner
latency:
monitor: p95_response_ms
action: pause_expansion_and_route_new_sessions_to_baseline
cost:
monitor: cost_per_resolved_case
action: cap_candidate_to_low_risk_segment
quality:
monitor: human_correction_rate
action: keep_canary_and_repair_prompt_or_retrieval
safety:
monitor: confirmed_unsafe_output
action: immediate_rollback_to_baseline
audit:
record:
- flag_key
- variation
- rollout_stage
- guardrail_signal
- operator
- decision
- rollback_or_cleanup_state
The exact thresholds belong to the team operating the product. This article should not invent universal limits. The important part is that each signal has a predefined interpretation. If a safety breach always rolls back but a latency regression only pauses expansion, write that before the alert fires.
For metric design, FeatBit's measurement design guidance is a useful companion because it separates primary outcomes from guardrails before exposure begins.
Join Every Signal Back To The Served Variation
Guardrail monitoring fails when the metric cannot be tied to the AI behavior that ran. If operators see "latency increased," they still need to know whether the affected traffic saw the stable route, the candidate prompt, a fallback model, a stricter guardrail mode, or an approval-required workflow.
At minimum, each guardrail event should carry:
| Field | Why it belongs |
|---|---|
flagKey |
Names the release control that selected the AI behavior |
variation |
Identifies the prompt, model route, retrieval profile, guardrail mode, or bundled AI profile |
assignmentUnit and unitId |
Joins exposure, outcome, guardrail, and rollback evidence |
rolloutStage |
Distinguishes internal, canary, experiment, and broad rollout traffic |
surface and workflow |
Explains where the AI behavior ran |
latencyMs |
Supports tail-latency and timeout analysis |
estimatedCost |
Supports cost-per-request and cost-per-success analysis |
qualitySignal |
Captures review, correction, evaluator, fallback, or complaint evidence |
safetySignal |
Captures policy violation, approval bypass, unsafe report, or high-risk miss |
releaseAction |
Records continue, pause, narrow, approval, fallback, rollback, or cleanup |
OpenTelemetry's public documentation now points generative AI semantic conventions to a dedicated GenAI semantic conventions repository, which is a reminder that AI telemetry naming is still becoming standardized across tools. Keep the local contract explicit even when you also export traces, spans, and metrics to an observability platform.
FeatBit's Track Insights API can record flag evaluation and custom metric events, while flag insights help teams inspect variation delivery. Use those signals with your observability stack, not instead of it.
Separate Alert Severity From Release Action
Do not make every alert a rollback. Guardrail monitoring should support proportional action.
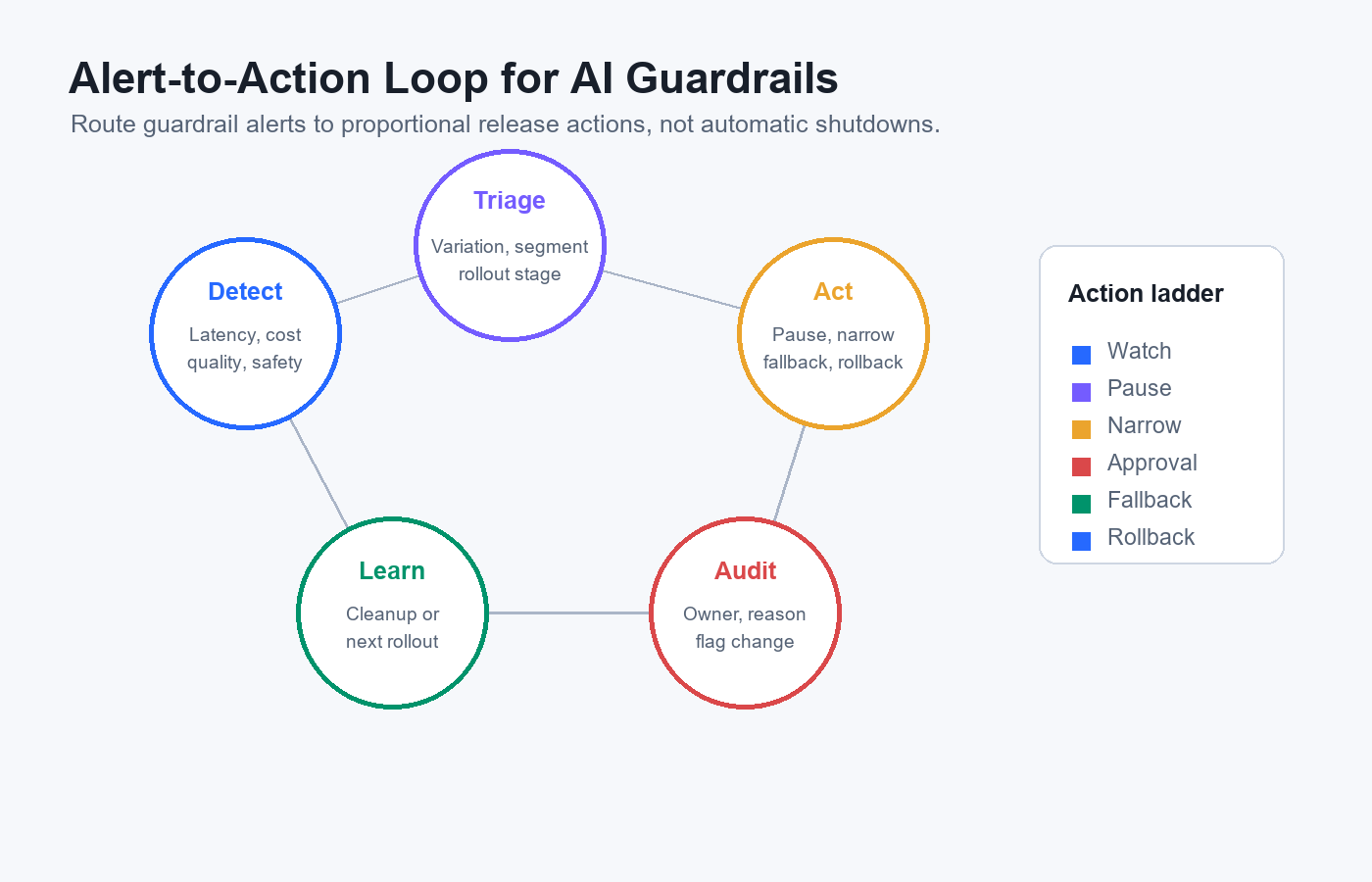
| Severity | Example signal | First action | Why |
|---|---|---|---|
| Watch | Cost is trending upward but still inside budget | keep current stage, add review note | Avoid interrupting a healthy rollout for noise |
| Pause | p95 latency crosses the agreed rollout gate | freeze expansion, keep current audience stable | Stop broader exposure while the team investigates |
| Narrow | Quality regression appears in one segment | exclude affected segment or reduce percentage | Limit blast radius without discarding all evidence |
| Approval | Safety confidence is uncertain for a high-risk workflow | switch that workflow to approval-required mode | Keep useful behavior while adding human review |
| Fallback | Provider or retrieval path is unreliable | route new sessions to stable baseline | Preserve service continuity while retaining evidence |
| Rollback | Confirmed unsafe output or severe quality failure appears | return affected audience to baseline immediately | Some failures should not wait for more data |
This ladder makes the dashboard useful during real operations. A release owner should not have to choose between ignoring an alert and shutting everything down. Feature flags let the team take smaller actions: target a safer segment, lower the rollout percentage, switch a route, require approval, or activate fallback.
Monitor Each Guardrail At The Right Level
Latency, cost, quality, and safety should not be monitored at only one aggregate level. AI failures are often uneven across account tier, region, language, workflow, risk class, prompt route, retrieval source, model provider, or agent mode.
Use this practical split:
| Level | Useful for | Example view |
|---|---|---|
| Request or generation | fast incident detection | timeout rate, token count, model error, unsafe-output flag |
| Conversation or workflow | multi-step quality and cost | task completed, fallback used, reviewer correction, total cost |
| User or account | blast-radius control | exposed accounts, complaints, support contacts, segment harm |
| Rollout stage | release governance | internal, canary, experiment, production default |
| Variation | causal diagnosis | baseline versus candidate versus fallback |
For AI chat, agent, and support workflows, request-level signals alone are usually too noisy. A single request can be slow but the workflow can still complete successfully. A single output can pass a safety classifier but still require a human correction later. The dashboard should let operators drill from a release stage to a variation, then to the affected workflow and segment.
Use Feature Flags As The Action Layer
An observability system can detect a latency spike. A product analytics system can show cost per successful task. A review tool can capture quality labels. A safety system can identify policy violations. The release owner still needs an action layer.
FeatBit belongs in that action layer:
- The application evaluates a FeatBit flag before selecting the AI route.
- The selected variation names the prompt profile, model route, retrieval profile, guardrail mode, approval mode, or fallback.
- Telemetry records the evaluated variation when the AI behavior actually runs.
- Guardrail events join back to the same variation and assignment unit.
- The release owner changes targeting, percentage, variation, or fallback state when a guardrail requires action.
- Audit logs and webhooks preserve who changed the rollout and why.
- Lifecycle rules decide whether the temporary control is removed or kept as a permanent operational flag.
FeatBit implementation paths include targeting rules, percentage rollouts, audit logs, webhooks, and the OpenTelemetry integration. For the broader AI release pattern, see FeatBit's AI control layer, safe AI deployment, and AI rollback strategy.
Dashboard Views Release Owners Actually Need
A useful guardrail dashboard does not need dozens of charts. It needs a few views that map to decisions.
| View | What it shows | Decision it supports |
|---|---|---|
| Rollout health | current stage, exposed audience, candidate versus baseline guardrails | continue, pause, or expand |
| Guardrail breaches | active alerts by severity, segment, variation, and owner | triage and assign action |
| Variation comparison | latency, cost, quality, and safety by variation | decide whether the candidate is releasable |
| Segment impact | account tier, region, workflow, plan, risk class | narrow or exclude affected traffic |
| Action history | flag changes, approvals, rollback actions, notes | audit review and post-incident learning |
| Cleanup queue | temporary flags, losing routes, stale guardrails | remove release debt after the decision |
The action-history view matters more than teams expect. NIST describes the AI Risk Management Framework as voluntary guidance for improving risk management across design, development, use, and evaluation of AI systems. In product operations, that means the team should preserve enough evidence to explain why a rollout expanded, paused, or rolled back.
Common Monitoring Mistakes
Monitoring AI calls without release context. Token counts and latency are useful, but they do not explain which flagged behavior caused the signal.
Using only average latency. AI changes often hurt tail latency first. Monitor p95 or p99 for user-facing workflows.
Treating cost as finance-only data. Cost per successful task is a release guardrail. If the candidate is too expensive at scale, it may not be releasable even when quality improves.
Collapsing quality into one score. Keep severe failures, reviewer correction, fallback, complaint, and business outcome separate enough to support a decision.
Letting safety alerts stop at notification. A safety alert should map to a prepared action such as approval-required mode, fallback, segment exclusion, or rollback.
Forgetting cleanup. Temporary AI monitoring and guardrail flags can become permanent release debt. FeatBit's feature flag lifecycle management model helps keep owner, evidence, decision, and cleanup visible.
Guardrail Monitoring Checklist
Before expanding an AI rollout, confirm:
- The release question names the AI behavior, audience, stage, and owner.
- Latency, cost, quality, and safety guardrails are defined before exposure.
- Each guardrail has a predefined action, not only a chart.
- Exposure events fire when the AI behavior actually runs.
- Guardrail events carry the same flag key, variation, assignment unit, and rollout stage.
- Tail latency and timeout signals are visible by variation and segment.
- Cost is monitored per request and per successful workflow.
- Quality signals include severe failures and human correction, not only average scores.
- Safety signals can trigger approval, fallback, narrowing, or rollback.
- Audit evidence records who changed the rollout, why, and what happened next.
- Temporary candidate routes and guardrail flags have cleanup rules.
The bottom line: monitor AI guardrails as release controls. Latency, cost, quality, and safety should not live in separate dashboards that operators interpret after the fact. They should connect to the flagged AI behavior that ran, the audience that saw it, the action the team can take, and the evidence needed to explain the release decision later.
Source Notes
- FeatBit implementation context: Track Insights API, flag insights, targeting rules, percentage rollouts, audit logs, webhooks, OpenTelemetry integration, AI control layer, safe AI deployment, AI rollback strategy, measurement design, and feature flag lifecycle management.
- Standards context: NIST's AI Risk Management Framework is cited as voluntary risk-management context for AI systems, not as a claim that this article provides compliance guidance.
- Observability context: OpenTelemetry's Generative AI semantic conventions page currently points readers to the dedicated GenAI semantic conventions repository. This article uses that as category context for telemetry naming, not as a requirement for FeatBit users.
- Market context: PostHog's AI Observability documentation describes capturing traces, generations, and spans for AI products and links setup guides for usage, cost, and latency. GrowthBook's feature flag documentation references safe rollouts and guardrail monitoring. LaunchDarkly's AgentControl monitoring documentation is used as category context for AI configuration performance monitoring. These sources are cited for terminology, not for vendor ranking.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it frames latency, cost, quality, and safety as release guardrails. - Use
guardrail-dashboard.pngnear the opening because it shows the four guardrail categories tied to release actions. - Use
decision-loop.pngin the alert severity section because it shows how signals become triage, action, audit, and cleanup.
Next Step
Choose one AI behavior currently in canary, beta, or internal rollout. Write the guardrail contract before expanding it: flag key, variation, assignment unit, latency signal, cost signal, quality signal, safety signal, owner, action on breach, audit fields, and cleanup rule.