A/B Testing for AI Models: How to Compare Business Impact Safely
A/B testing for AI models is not just asking which model has a higher offline evaluation score. The useful question is narrower and more operational: when real users see model A or model B under controlled exposure, which one improves the business outcome without breaking quality, latency, cost, or trust guardrails?
For AI products, that answer needs a release-control loop. You need a hypothesis, a reversible rollout, exposure tracking, metric events, guardrails, and a decision rule before traffic reaches the new model. FeatBit's view is that model selection is a runtime release decision, so the experiment should be controlled through feature flags instead of being hidden inside a one-way deployment.
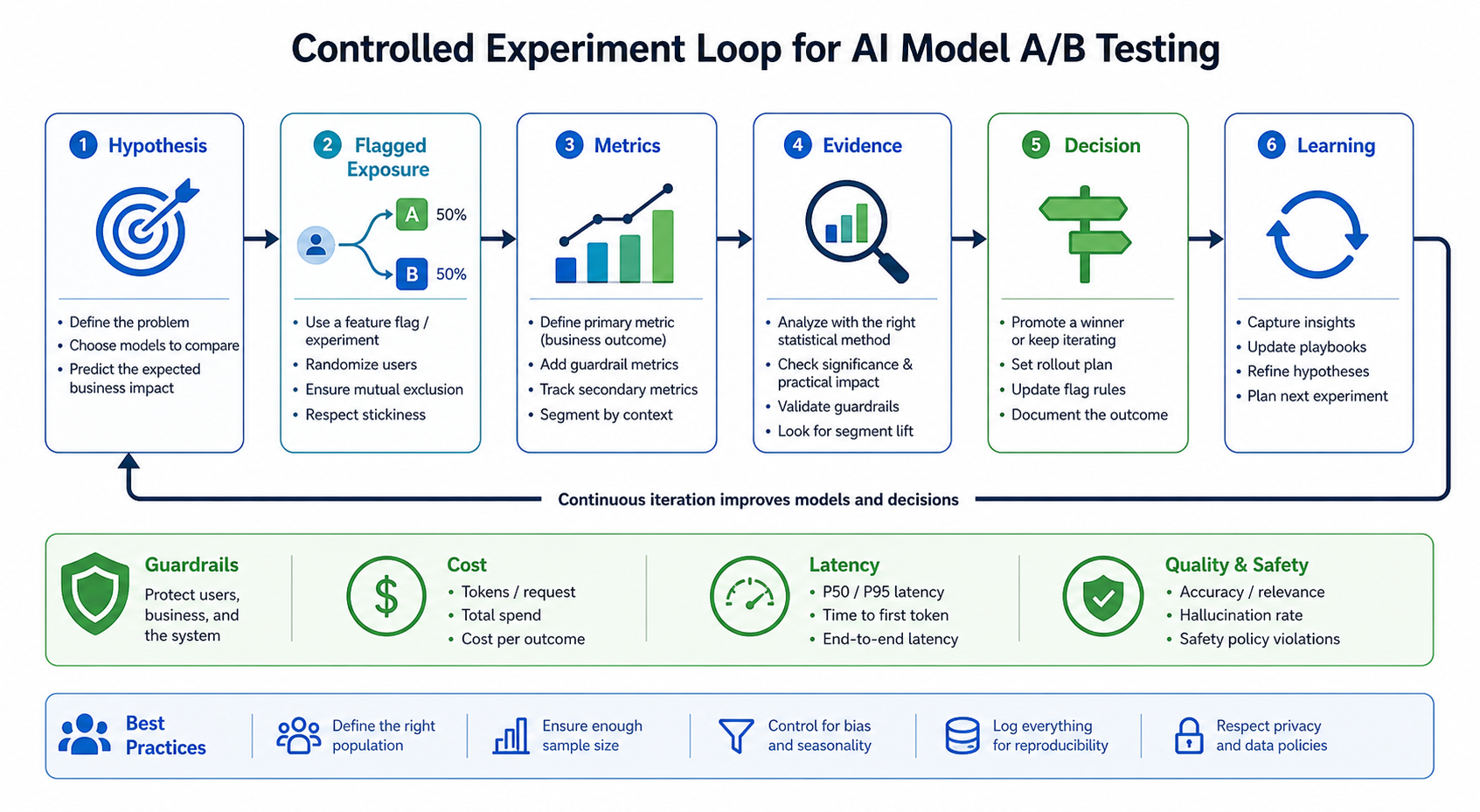
What AI model A/B testing needs to prove
An AI model experiment should prove business impact, not only model preference. Offline evals, benchmark suites, prompt tests, and human review are useful before production, but they do not fully answer whether a model improves a product outcome for your audience.
A good AI model A/B test usually answers four questions:
| Question | Why it matters |
|---|---|
| Does the new model improve the primary user or business metric? | A better answer quality score is not enough if conversion, task completion, retention, or agent resolution does not improve. |
| Does it stay inside guardrails? | A variant can win the main metric while increasing latency, token cost, escalation rate, unsafe outputs, or manual review load. |
| Can exposure be reversed quickly? | Model behavior can fail in narrow segments, so rollback must be available without redeploying code. |
| Is the result explainable enough to act on? | Teams need to know whether to continue, pause, roll back, or run a more specific follow-up test. |
This is where AI model testing differs from many traditional feature experiments. A UI experiment often compares two stable experiences. An AI model experiment compares probabilistic behavior that can vary by prompt, user segment, retrieval context, tool choice, language, traffic mix, and time.
Start with a release hypothesis
Do not start with "GPT-4.1 versus Model X" or "small model versus large model." Start with the release decision you need to make.
A useful hypothesis looks like this:
For support-ticket summarization, routing 10 percent of eligible production traffic to Model B will improve successful first-response drafting by 8 percent, while keeping median latency under 2 seconds, average inference cost within the weekly budget, and human escalation rate unchanged.
That hypothesis gives the team a clear experiment shape:
- The decision point is support-ticket summarization.
- The compared variants are Model A and Model B.
- The exposure boundary is eligible production traffic.
- The primary metric is successful first-response drafting.
- The guardrails are latency, cost, and escalation rate.
- The outcome is a release decision, not a dashboard screenshot.
FeatBit's release decision framework uses this same pattern: intent, hypothesis, reversible exposure, measurement, evidence, decision, and learning. For AI models, that loop prevents teams from treating a model swap as a normal deploy.
Use feature flags as the model assignment layer
Model A/B testing needs stable assignment. If the same user or request class bounces between variants randomly, you can contaminate the result and create a poor experience.
A feature flag can assign traffic to model variants at runtime:
const modelVariant = await flags.getString('support-summary-model', user, 'model-a');
const response = await summarizeTicket({
model: modelVariant,
ticket,
customerContext,
});
The flag is not just a switch. It becomes the experiment control plane:
- Target internal users before customers see the variant.
- Send a small percentage of eligible traffic to the candidate model.
- Exclude risky segments from the first wave.
- Roll back to the baseline model if guardrails fail.
- Keep model assignment visible to product, engineering, and operations teams.
This is why FeatBit describes feature flags as an AI control layer. The model can change without redeploying the application, but the change still has owner, targeting, auditability, and rollback behavior.
Choose metrics that reflect the product job
AI model experiments fail when the metric is disconnected from the product job. "Better answer" is too vague. "Higher evaluation score" may be useful in pre-production, but it is not always the business outcome.
Pick one primary metric that maps to the user job:
| AI use case | Primary metric examples | Guardrail examples |
|---|---|---|
| Support assistant | Resolved without escalation, time to first useful answer, agent acceptance rate | Hallucination report rate, latency, token cost, CSAT drop |
| Search or RAG | Successful search session, click-through to relevant result, reformulation rate | Empty-answer rate, source-citation error rate, retrieval cost |
| Coding assistant | Accepted suggestion rate, successful task completion, review pass rate | Defect rate, build failure rate, security finding rate |
| Sales or onboarding copilot | Qualified next step, completed setup task, assisted conversion | Off-policy response rate, manual override rate, response time |
Then add guardrails. Guardrails are not secondary decorations. For AI model tests, guardrails often decide whether a winning primary metric is actually releasable.
FeatBit's measurement design guide is a useful next step when a team needs to turn product intent into a primary metric, event design, and guardrails before the experiment starts.
Run the experiment as staged exposure
A model A/B test should expand only when evidence stays healthy. A practical sequence is:
- Offline evaluation: compare model outputs against task-specific examples, human review rubrics, and known failure cases.
- Internal dogfood: expose employees or a test segment through a flag.
- Limited production traffic: assign a small percentage of eligible users or requests.
- Guardrail review: inspect latency, cost, quality reports, support load, and operational alerts.
- Decision: continue, pause, roll back, or create a narrower follow-up test.

This staged approach is important because model failures are often uneven. A candidate model may perform well for English support tickets but poorly for long technical logs. It may improve answer quality while making latency unacceptable for chat. It may reduce human work in one segment and increase review load in another.
FeatBit's safe AI deployment guidance applies here: do not expose a model change to everyone before you have a way to target, observe, and reverse it.
Separate model quality from release readiness
AI teams often have two separate questions but mix them together.
The first question is model quality:
- Does the candidate model follow instructions?
- Does it solve representative tasks?
- Does it handle known edge cases?
- Does it reduce hallucination or unsafe outputs in reviewed samples?
The second question is release readiness:
- Does the candidate model improve the product metric in production?
- Does it stay within latency and cost limits?
- Does it behave acceptably for protected or high-risk segments?
- Can the team detect and roll back a bad release quickly?
Offline evaluation helps with the first question. A/B testing helps with the second. The two should be connected, but one should not replace the other.
OpenAI's Evals documentation describes evals as a way to test model behavior against defined tasks and criteria. Google Cloud's generative AI evaluation documentation similarly frames evaluation as a way to assess model responses with metrics and datasets. Those sources are useful for pre-production model assessment, while a production A/B test answers the business impact question under real exposure.
Common mistakes in AI model experiments
The most common mistake is comparing models without stable exposure tracking. If you cannot tell which user, request, prompt version, retrieval configuration, or model variant produced an outcome, the experiment becomes hard to trust.
Other avoidable mistakes include:
- Changing the prompt and model at the same time without treating the combination as a variant.
- Running the test without a kill switch.
- Looking only at aggregate conversion while ignoring latency, cost, unsafe output reports, or manual review load.
- Ending the test because one metric moved early, before checking segment-level behavior.
- Declaring a model "better" when the result only proves that it passed an offline rubric.
- Forgetting to clean up the experiment flag after the release decision is made.
The cleanup point matters. A model experiment flag should have an owner, expected decision date, and end state. If the winning model becomes permanent, remove stale code paths and archive the flag according to your feature flag lifecycle management rules.
How FeatBit fits the workflow
FeatBit is useful for AI model A/B testing because model selection is a runtime decision. A team can use a multivariate feature flag to route eligible traffic across model variants, target specific segments, start with internal users, expand by percentage, and roll back when guardrails fail.
That does not mean the feature flag platform replaces model evaluation tools, observability, or product analytics. It connects them. The flag controls who sees which model. Evaluation and analytics decide whether the variant is good enough. Observability tells the team whether the system is healthy. The release decision loop turns that evidence into action.
For implementation details, start with FeatBit's docs on A/B testing with feature flags, targeted progressive delivery, and feature flag insights. If your team is designing experiments for prompts, retrieval settings, or agent behavior, FeatBit's AI experimentation page gives the broader release-control context.
A practical checklist
Before you start an AI model A/B test, confirm these items:
- The business decision is clear: continue, pause, roll back, or expand.
- The primary metric maps to the product job.
- Guardrails cover quality, latency, cost, safety, and operational load.
- Feature flags assign stable model variants.
- Exposure starts with a safe segment and expands gradually.
- The team records model version, prompt version, retrieval configuration, and flag variation.
- Rollback does not require redeploying the application.
- The experiment has an owner, review date, and cleanup plan.
The goal is not to run more experiments. The goal is to make model changes measurable, reversible, and useful to the business.
Source and image notes
- OpenAI Evals documentation: https://platform.openai.com/docs/guides/evals
- Google Cloud generative AI evaluation overview: https://cloud.google.com/vertex-ai/generative-ai/docs/models/evaluate-overview
- NIST AI Risk Management Framework: https://www.nist.gov/itl/ai-risk-management-framework
- FeatBit product and implementation context: linked FeatBit pages and docs throughout this article.
- Open Graph recommendation: use
/images/blogs/ab-testing-ai-models/cover.pngas the social preview image. The body diagrams visualize the experiment loop and release decision matrix in crawlable-supporting form; the article keeps the primary guidance in Markdown text.