A/B for Models: A Production Architecture for Real-Traffic Experiments
A/B for models is the production practice of assigning real traffic to competing AI model routes, measuring the outcome that matters to the product, and keeping the release reversible while the evidence is still uncertain.
The hard part is not the 50/50 split. The hard part is building a trustworthy path from assignment to exposure to outcome to rollback. A model experiment can look clean in a dashboard while the application silently falls back, mixes prompts, changes retrieval settings, or records outcomes under the wrong variation. For platform and AI engineering teams, the useful reader job is architecture: how should the runtime, telemetry, and release controls fit together so the experiment can support an actual model decision?
This article focuses on that production architecture. For metric selection and business-impact framing, use the companion guide on how to A/B test AI models for business impact.
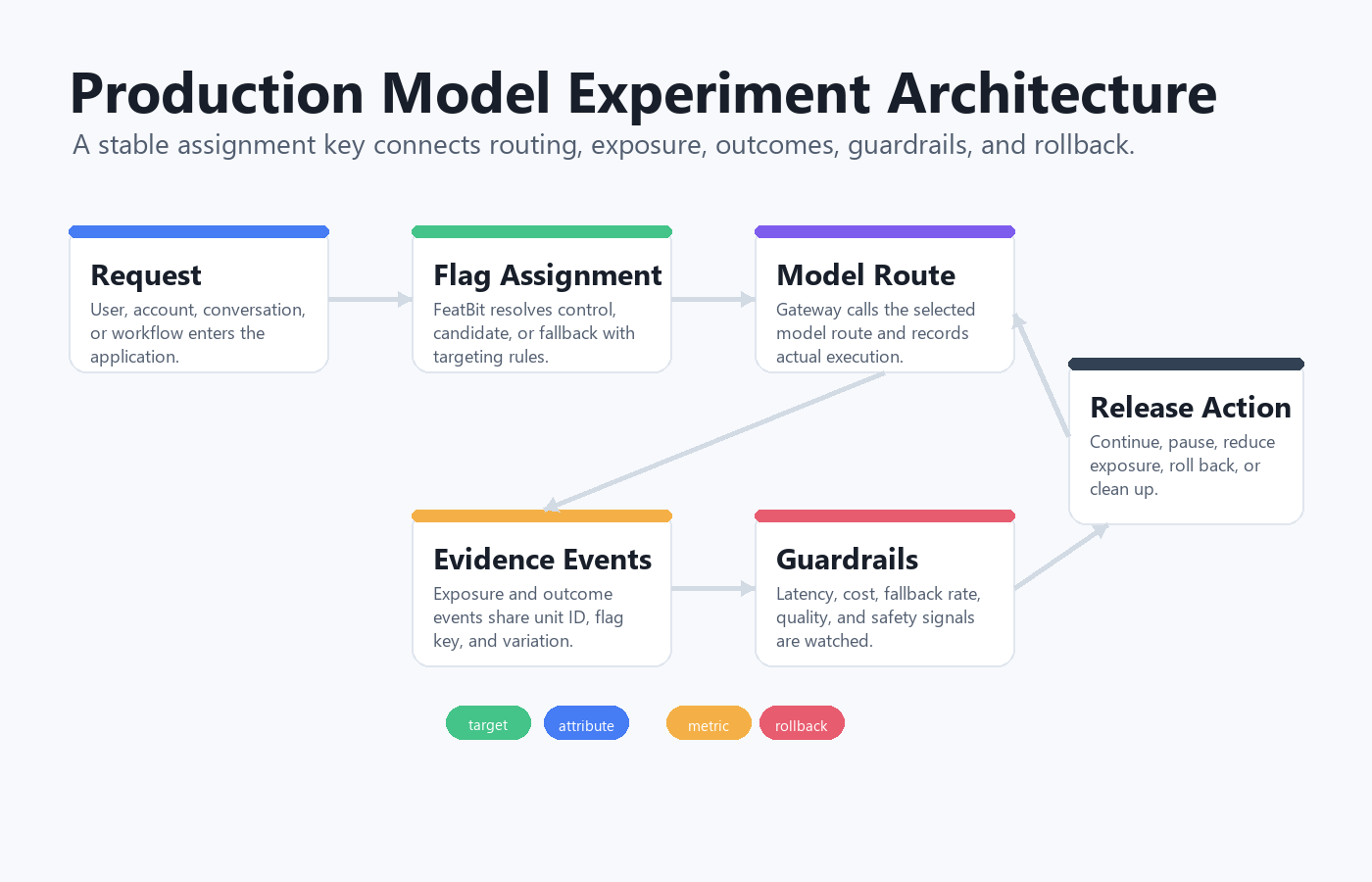
What The Architecture Must Prove
A real-traffic model experiment should prove more than "model B received traffic." It should prove that each eligible unit received a stable variation, the assigned model behavior actually ran, outcomes were attributed to the same variation, and operators could contain harm before the experiment reached too much traffic.
That gives the architecture four jobs:
| Job | Production question | Failure if ignored |
|---|---|---|
| Assignment | Which user, account, conversation, or workflow belongs to each variation? | The same unit can drift between models and contaminate the result. |
| Execution | Which model route, prompt, retrieval profile, or fallback actually ran? | The dashboard may analyze intended exposure instead of actual behavior. |
| Evidence | Which outcome and guardrail events connect back to the variation? | The team cannot explain why a model won, lost, or should pause. |
| Control | Who can reduce exposure, exclude a segment, or roll back? | A bad model keeps spreading while the team investigates. |
FeatBit's point of view is that this is release-decision infrastructure. The flag is not the whole experiment, but it is the runtime control point that makes the experiment targetable, measurable, auditable, and reversible.
Use A Flag As The Assignment Contract
The model assignment should be a named production control, not a hidden random function inside the model gateway. A feature flag gives the model route a stable key, targeting rules, variation names, rollout percentages, default behavior, and audit history.
For model experiments, prefer a string or JSON variation when the route contains more than one field:
flag:
key: support_answer_model_route
type: json
owner: ai_platform
variations:
control:
modelRoute: support_model_a
promptVersion: support_v3
retrievalProfile: baseline
candidate:
modelRoute: support_model_b
promptVersion: support_v3
retrievalProfile: baseline
fallback:
modelRoute: support_model_a
promptVersion: support_v3
retrievalProfile: safe_fallback
assignment:
unit: conversation_id
eligibleSegment: paid_support_chat
exclusions:
- incident_accounts
- regulated_accounts
rollback:
defaultVariation: fallback
This makes the experiment honest about what is changing. If the model and prompt both change, the variation is a route test, not a pure model test. That is acceptable, but the release decision should name the route, not claim the result belongs only to the model.
OpenFeature's flag evaluation specification describes typed flag evaluation with a flag key, default value, evaluation context, and optional detailed evaluation metadata. That vendor-neutral model is useful here because the model experiment needs a stable flag key and a context object that represents the assignment unit.
Put The Assignment Unit In The Runtime Path
The application service or model gateway should evaluate the model-route flag immediately before the model call. Evaluate with the unit that matches the experiment decision: user, account, conversation, session, request, or workflow.
For many AI products, conversation or workflow assignment is cleaner than request assignment because multi-turn behavior needs continuity. For durable personal experiences, user or account assignment may be better. The detailed decision is covered in AI experiment randomization by user or conversation, but the architecture rule is simple: the same assignment key must appear in flag evaluation, exposure events, outcome events, and rollback reports.
type ModelRoute = {
modelRoute: string;
promptVersion: string;
retrievalProfile: string;
};
async function answerSupportConversation(input: {
conversationId: string;
userId: string;
accountId: string;
locale: string;
question: string;
}) {
const route = await featbit.variation<ModelRoute>(
'support_answer_model_route',
{
key: input.conversationId,
custom: {
assignmentUnit: 'conversation',
userId: input.userId,
accountId: input.accountId,
locale: input.locale
}
},
{
modelRoute: 'support_model_a',
promptVersion: 'support_v3',
retrievalProfile: 'safe_fallback'
}
);
const response = await runModelRoute(route, input.question);
await recordExposureAndOutcome({
flagKey: 'support_answer_model_route',
unitId: input.conversationId,
variation: route.modelRoute,
promptVersion: route.promptVersion,
retrievalProfile: route.retrievalProfile,
response
});
return response;
}
Do not evaluate the flag in a page view if the model call may never happen. Exposure should be recorded when the candidate behavior actually runs.
Design The Evidence Contract Before Traffic Starts
The evidence contract is the minimum event schema that makes the experiment analyzable. It should be written before the flag expands beyond internal traffic.
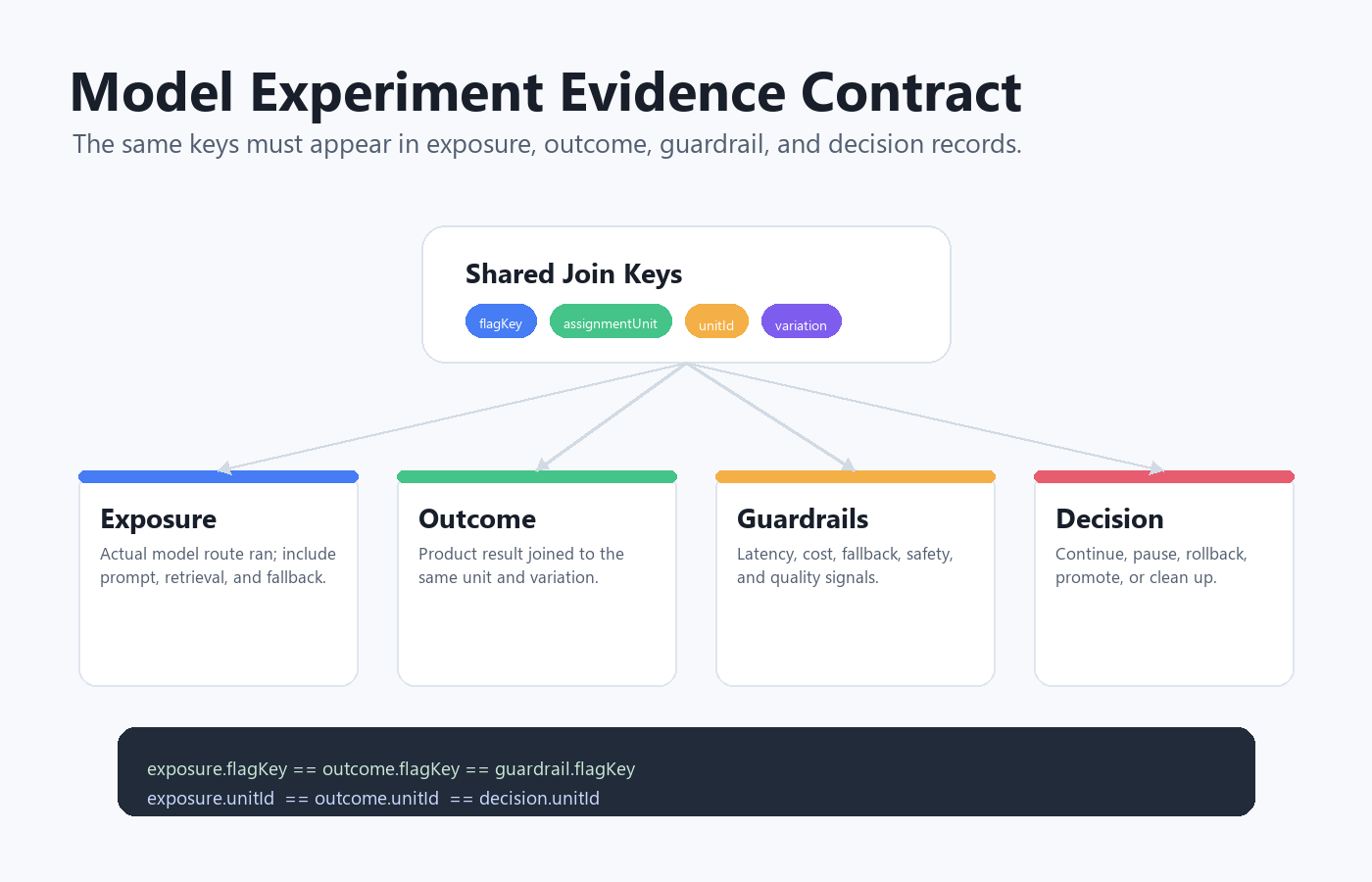
At minimum, capture these fields:
| Field | Why it belongs |
|---|---|
experimentKey or flagKey |
Names the release decision being tested. |
assignmentUnit |
Tells analysis whether the unit is user, account, conversation, workflow, or request. |
unitId |
Joins exposure, outcome, guardrail, and rollback evidence. |
variation |
Names the resolved control, candidate, or fallback route. |
modelRoute |
Records the actual model policy used by the application. |
promptVersion |
Prevents prompt drift from being mistaken for model impact. |
retrievalProfile |
Captures RAG changes that can affect the same outcome. |
fallbackUsed |
Shows when candidate traffic did not actually receive candidate behavior. |
latencyMs and estimatedCost |
Turns performance and cost into guardrails, not afterthoughts. |
A clean exposure event might look like this:
{
"event": "ai_model_route_exposure",
"flagKey": "support_answer_model_route",
"assignmentUnit": "conversation",
"unitId": "conv_98271",
"variation": "candidate",
"modelRoute": "support_model_b",
"promptVersion": "support_v3",
"retrievalProfile": "baseline",
"fallbackUsed": false,
"timestamp": "2026-06-07T10:15:30Z"
}
The outcome event should carry the same join keys:
{
"event": "support_conversation_outcome",
"flagKey": "support_answer_model_route",
"unitId": "conv_98271",
"variation": "candidate",
"resolvedWithoutEscalation": true,
"humanCorrection": false,
"latencyMs": 1840,
"estimatedCost": 0.014
}
FeatBit's Track Insights API supports tracking feature flag evaluations and custom metric events. FeatBit's measurement design guidance is the companion step: choose the primary metric and guardrails before exposure starts.
Separate The Model Gateway From The Release Decision
A model gateway can enforce provider credentials, rate limits, retry policy, fallback behavior, prompt assembly, and request logging. The release decision still needs a higher-level control plane that product and engineering can inspect.
Keep the boundary explicit:
| Layer | Owns | Should not own alone |
|---|---|---|
| Feature flag control plane | eligibility, rollout, targeting, variation names, rollback, audit | provider secrets or raw prompts |
| Application service or model gateway | model call, fallback, prompt assembly, telemetry emission | hidden experiment assignment with no product visibility |
| Experiment analysis | metric readout, guardrail review, segment analysis | production exposure control |
| Observability stack | traces, logs, latency, errors, cost signals | the release decision itself |
This boundary prevents two common failure modes. First, a model gateway should not become an invisible experiment platform that no release owner can roll back. Second, a feature flag should not become a place to store sensitive prompts, provider secrets, or large policy documents. Use the flag to select a named route; keep the detailed execution logic in the service that owns the model call.
FeatBit's AI control layer expands this operating model: runtime flags control exposure and behavior changes, while observability and evaluation systems provide the evidence.
Progress Through Safe Exposure States
Do not jump from offline evaluation to a broad 50/50 production split. A real-traffic model experiment should move through states that each answer a different question.

| State | Question | Example release action |
|---|---|---|
| Offline gate | Is the candidate good enough for controlled production evidence? | Prepare the variation but keep production exposure at zero. |
| Internal traffic | Does the route work with real integrations and telemetry? | Target employees and verify events, fallback, and traces. |
| Canary | Is a small visible slice healthy? | Expose 1-5 percent of eligible traffic and watch guardrails. |
| A/B experiment | Does the candidate improve the primary outcome? | Split eligible traffic and keep guardrails active. |
| Decision | Should the candidate expand, pause, roll back, or become default? | Promote, continue, reduce exposure, or return to fallback. |
| Cleanup | What temporary code and flag state should remain? | Remove losing route or convert the flag into an intentional operational control. |
This sequence makes the article's keyword practical. "A/B for models" is not one dashboard state. It is one stage in a release path that starts before exposure and ends only when the flag, model route, and code path have a clear end state.
What Category Tools Agree On
Experimentation platforms use different terminology, but the category pattern is consistent: flags, gates, rollouts, metrics, and experiments are connected.
GrowthBook's feature flag documentation describes controlling application behavior without deploying new code, targeting users, gradual rollout, and A/B tests. Statsig's guide on feature gates versus experiments distinguishes gradual rollout from quantified multi-variant comparison, while noting that the two can work together. LaunchDarkly's experiment flag documentation describes temporary boolean or multivariate flags paired with metrics. Optimizely's Feature Experimentation documentation emphasizes choosing metrics for experiment decisions.
The lesson for AI models is not that every vendor works the same way. The lesson is that model assignment and measurement have to be designed together. AI model changes make that coordination more important because one variation can change quality, latency, cost, fallback rate, safety review, and human workload at the same time.
Rollback Rules Belong In The Experiment Design
Rollback should be a prepared release action, not an emergency meeting. Write the rollback rule as part of the experiment design:
rollback_when:
severe_quality_issue: any confirmed unsafe or materially wrong answer in production
telemetry_missing: exposure or outcome events fail for more than 10 minutes
latency_guardrail: p95 latency breaches the agreed service target
fallback_guardrail: candidate fallback rate rises above the agreed threshold
segment_harm: any protected or high-value segment shows unacceptable degradation
rollback_action:
immediate: set support_answer_model_route default to fallback
scoped: exclude affected segment from candidate eligibility
aftercare: preserve evidence, review traces, decide whether to restart
The exact thresholds should come from the team, not from this article. The architecture requirement is that the release owner can execute the action without redeploying the application.
FeatBit's safe AI deployment and progressive rollout patterns pages give the broader rollout context for staged exposure and rollback.
Common Architecture Mistakes
Recording intended assignment instead of actual exposure. If the candidate route times out and falls back before producing output, the exposure record should say that.
Changing prompt, retrieval, and model while calling it a model-only test. Bundle changes when the product decision is a route decision. Split changes when the team needs causal clarity.
Randomizing at request level for a multi-turn experience. The sample size may look attractive, but users can see inconsistent behavior and the result can be hard to interpret.
Letting the model gateway own rollback alone. Incident responders need a visible release control with targeting, audit, and ownership.
Ignoring cleanup. When the model decision is made, remove stale branches or intentionally convert the flag into a permanent operational control. FeatBit's feature flag lifecycle management guidance helps keep release evidence from becoming long-term flag debt.
A Production Checklist
Before starting an A/B test for models, confirm:
- The flag variation represents the model route being tested.
- The assignment unit matches the product experience and metric window.
- The application evaluates the flag where the model behavior actually runs.
- Exposure events record actual model execution, prompt version, retrieval profile, fallback, and variation.
- Outcome and guardrail events carry the same unit ID and variation.
- The primary metric and guardrails are written before traffic starts.
- Operators can roll back globally or by segment without redeploying.
- The model gateway keeps secrets and prompt assembly outside the flag value.
- Segment readouts are reviewed before expansion.
- The experiment has an owner, decision date, and cleanup rule.
The bottom line: A/B for models is a production architecture problem before it is an analysis problem. Use feature flags to assign and control model routes, telemetry to connect exposure with outcomes, observability to watch guardrails, and release governance to decide whether to expand, pause, roll back, or clean up.
Source Notes
- FeatBit implementation context: A/B testing with feature flags, targeting rules, percentage rollouts, Track Insights API, AI experimentation, AI control layer, measurement design, and feature flag lifecycle management.
- Feature flag standard context: the OpenFeature flag evaluation specification is cited for typed flag evaluation, evaluation context, detailed evaluation metadata, and default-value behavior in abnormal execution.
- Experimentation category context: GrowthBook's feature flag documentation, Statsig's feature gates versus experiments guide, LaunchDarkly's experiment flags documentation, and Optimizely's metrics documentation are cited for category context, not vendor ranking.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the production architecture: assignment, model route, evidence, guardrails, and release action. - Use
production-model-experiment-architecture.pngnear the opening because it shows the full runtime path from user request to model routing and rollback. - Use
model-evidence-contract.pngin the evidence section because it reinforces the shared event keys that make analysis trustworthy. - Use
model-experiment-decision-dashboard.pngin the exposure-state section because it shows how A/B testing fits inside a broader release decision path.