Optimizely Model A/B Testing: A Buyer Guide for AI Release Decisions
If you searched for Optimizely model A/B testing, clarify the word "model" first. It can mean Optimizely's statistical model for analyzing A/B tests, or it can mean an AI or machine learning model that your product team wants to compare in production.
Those are related but different buying questions. Optimizely has public documentation for Web Experimentation, Feature Experimentation, A/B tests, Bayesian analysis, and adaptive traffic allocation. An AI model release adds another layer: runtime model routing, actual exposure logging, quality and business metrics, guardrails, rollback, and cleanup after the decision.
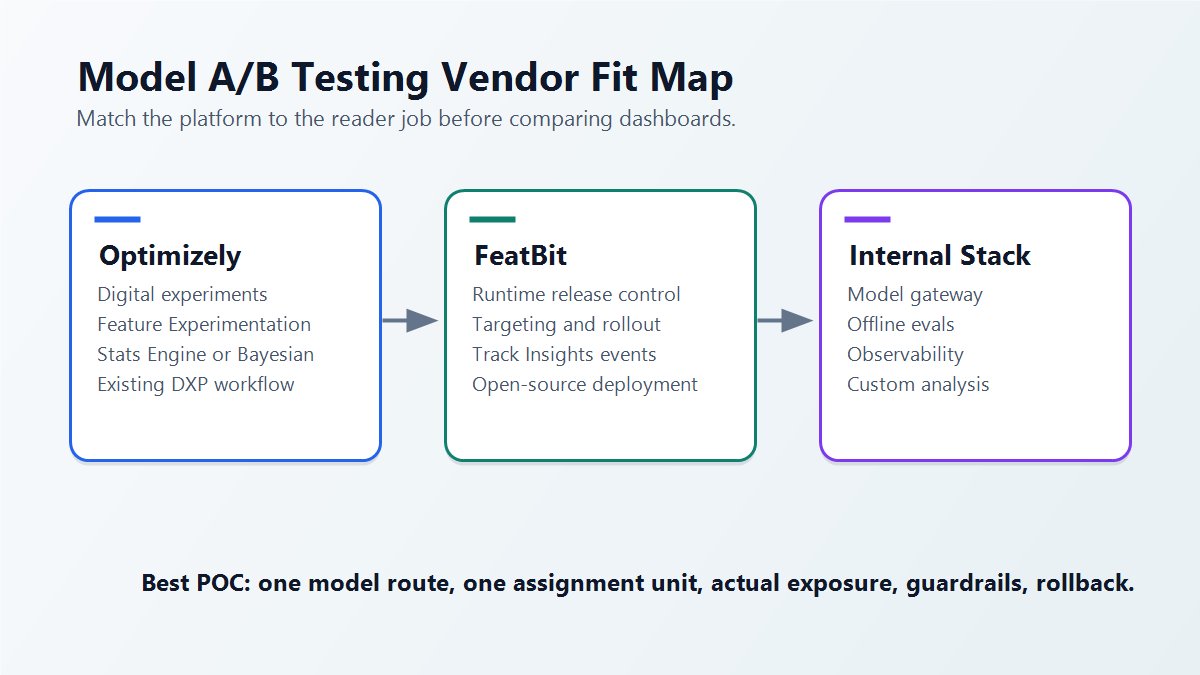
This guide is for product, platform, and AI engineering teams that are evaluating whether Optimizely fits that model A/B testing workflow, and when an open-source release-control platform such as FeatBit should be considered instead.
Short Answer
Use Optimizely as a first evaluation when the main job is web or digital experience experimentation, feature experimentation inside an existing Optimizely stack, or a statistical experiment workflow that your marketing, product, and experimentation teams already operate.
Use FeatBit as a first evaluation when the main job is release control for AI behavior: target who sees a model route, ramp exposure, record the served variation, connect custom metric events, roll back without redeploying, and keep the control plane open-source or self-hosted.
For AI model A/B testing, do not compare vendors only by whether they can split traffic. Compare whether the platform can answer the release question:
| Release question | Why it matters for model tests |
|---|---|
| Who is eligible for the candidate model route? | A model can be safe for one segment and risky for another. |
| What assignment unit stays stable? | Users, accounts, conversations, workflows, and requests produce different evidence. |
| Did the candidate model actually run? | Intended assignment is not enough when fallback, timeout, prompt drift, or routing changes can happen. |
| Which metric decides the release? | A quality score, conversion metric, task outcome, latency, cost, and support load can disagree. |
| Can exposure be reduced immediately? | AI regressions may need rollback before an experiment reaches a clean statistical result. |
| What gets cleaned up after the decision? | Temporary model routes and experiment flags become release debt if they never end. |
What Optimizely Covers
Optimizely's public Feature Experimentation documentation describes a feature flagging and experimentation platform for websites, mobile apps, chatbots, APIs, smart devices, and other connected applications. It says teams can deploy code behind feature flags, run A/B tests, and use targeted deliveries to roll out or roll back flags.
That matters because AI model A/B testing usually needs both pieces: a runtime control that chooses the model route and an experiment readout that compares outcomes.
Optimizely also documents a basic Feature Experimentation A/B test workflow: create a flag, handle user IDs, create an A/B test rule, integrate the generated decision code, test in a non-production environment, discard QA events, and enable the experiment in production. For teams already using Optimizely Feature Experimentation, this is the starting point to validate whether a model route can be represented as a feature variation.
Optimizely Web Experimentation is a different surface. Its public product page emphasizes website and digital experience testing, AI-generated variation ideas, AI summaries, automated traffic distribution, custom metrics, analytics views, and A/B, multivariate, and multi-armed bandit tests. That can be useful for conversion experiments, but it is not the same as proving that a backend AI model route is safe, measurable, and reversible.
Optimizely also publishes statistical configuration guidance, including Bayesian A/B tests for Feature Experimentation and distribution methods such as Stats Accelerator and multi-armed bandits. Treat these as analysis and allocation options. They do not remove the need to design the runtime model route, assignment unit, exposure event, outcome event, and rollback action.
The Ambiguity Behind "Model A/B Testing"
The phrase "model A/B testing" can point in three directions:
| Meaning | Reader task | What to verify |
|---|---|---|
| Statistical model for A/B testing | Understand how Optimizely interprets experiment results. | Stats Engine, Bayesian configuration, false discovery controls, decision thresholds, and reporting workflow. |
| AI model route experiment | Compare model A against model B in production. | Assignment unit, model route metadata, exposure timing, quality metrics, cost, latency, fallback, and rollback. |
| Web personalization or recommendation model test | Test digital experiences or recommendation strategies. | Web surface, data source, audience rules, traffic allocation, conversion metrics, and operational ownership. |
The mistake is assuming that one meaning covers the others. A statistical model can help interpret experiment data, but it does not guarantee that the application routed the same conversation to the same AI model. A web A/B testing surface can compare page variations, but it may not be the right control point for backend model behavior. A feature flag can assign a model route, but it still needs metrics and guardrails to support the release decision.
What AI Model A/B Testing Adds
An AI model A/B test is not only a two-variation experiment. It is a production release decision around a behavior that can change quality, latency, cost, safety, and downstream human workload.
For example:
model_ab_test:
release_question: should_support_chat_use_candidate_model_route
control: model_a_prompt_v3_retrieval_baseline
candidate: model_b_prompt_v3_retrieval_baseline
assignment_unit: conversation_id
eligible_scope:
environment: production
segment: english_support_chat
exclusions:
- incident_accounts
- regulated_accounts
primary_metric: resolved_without_human_escalation
guardrails:
- p95_latency
- fallback_rate
- human_correction_rate
- estimated_cost_per_resolved_case
rollback: route new conversations back to control
cleanup: remove losing route or promote winner after decision
That structure makes the vendor evaluation concrete. The question is no longer "Can the tool run A/B tests?" The question is "Can the tool operate this release contract without hiding assignment, exposure, fallback, or rollback?"

A Proof Of Concept To Run In Optimizely
If Optimizely is already in your stack, run a proof of concept before deciding that it fits AI model releases. Use one model route experiment and require it to pass the full operational path.
1. Represent The Model Route
Ask whether the control and candidate can be represented as clear variations, not vague labels.
Good variation names:
support_model_a_prompt_v3_baselinesupport_model_b_prompt_v3_baselinesupport_model_a_safe_fallback
Weak variation names:
oldnewtesttreatment
The variation name should be understandable to engineering, product, data, and incident responders. If the model, prompt, retrieval profile, or fallback policy changes, name the route honestly. Otherwise the result may look like a pure model comparison when it was really a bundle of AI behavior changes.
2. Choose The Assignment Unit
AI tests often fail when they randomize at the wrong unit. Request-level assignment can be acceptable for stateless backend inference, but it can corrupt multi-turn experiences. A support chatbot, tutor, coding assistant, or agent workflow often needs conversation-level or workflow-level assignment. A B2B product may need account-level assignment if the release decision is made at tenant scope.
Validate that the chosen unit appears consistently in:
- the feature or experiment decision call;
- the model route execution log;
- the exposure event;
- the outcome event;
- guardrail and rollback reports;
- exported data or downstream analytics.
3. Log Actual Exposure
For model tests, exposure should be recorded when the application actually uses the assigned route. A page view is too early if the model call never happens. Intended assignment is not enough if the candidate route times out and falls back before serving a response.
At minimum, record:
| Field | Purpose |
|---|---|
experimentKey or flagKey |
Names the model release decision. |
assignmentUnit |
Explains whether the unit is user, account, conversation, workflow, or request. |
unitId |
Joins exposure to outcome and guardrails. |
variation |
Names the assigned route. |
actualModelRoute |
Records what really ran. |
promptVersion |
Prevents prompt drift from being mistaken for model impact. |
fallbackUsed |
Shows whether candidate traffic actually received candidate behavior. |
latencyMs and estimatedCost |
Makes performance and cost visible as guardrails. |
4. Separate Primary Metric From Guardrails
Optimizely's Feature Experimentation metrics documentation emphasizes that experiments need metrics and distinguishes metric roles. For AI model releases, apply the same discipline but make the guardrails explicit.
Use one primary metric to decide the release. Use several guardrails to decide whether the experiment should pause, narrow, or roll back.
Examples:
| Product workflow | Primary metric | Guardrails |
|---|---|---|
| Support assistant | Resolved without escalation | latency, fallback rate, complaint rate, human correction rate |
| RAG search | Accepted answer or successful click-through | no-answer rate, hallucination review, retrieval failure, cost |
| Sales assistant | Qualified reply or meeting booked | unsubscribe rate, manual edit rate, policy review, latency |
| Coding assistant | Accepted change without extra rework | failed tests, review churn, security review findings, rollback |
5. Prove Rollback
Rollback should be demonstrated during the proof of concept, not assumed. The release owner should be able to:
- return all new eligible traffic to the control route;
- exclude a risky segment;
- reduce candidate allocation;
- preserve exposure and outcome evidence;
- explain who changed exposure and when;
- decide what happens to the temporary route after the test.
If rollback requires a redeploy, a model gateway change, or a support ticket to another team, the experiment is not yet release-ready.
When Optimizely May Be The Better Fit
Optimizely may be the better first evaluation when:
- your organization already standardizes on Optimizely Experimentation;
- the experiment owner is a web, commerce, conversion, or digital experience team;
- visual variation creation, personalization, multivariate testing, or traffic optimization is central to the workflow;
- Feature Experimentation already owns your application flags and experiment metrics;
- your team wants Optimizely's statistical analysis and reporting workflow as the primary decision surface;
- procurement, data flow, and platform administration already fit your organization.
The important boundary is evidence. For a backend AI model route, require the proof of concept to show actual model execution, fallback state, custom outcome events, and rollback authority. Do not accept a dashboard-only demo where the application behavior is treated as an implementation detail.
When FeatBit Should Be Evaluated
FeatBit should be evaluated when the primary need is a release-control layer for AI-era software rather than a web optimization suite.
FeatBit is relevant when teams need to:
- target model, prompt, retrieval, or agent behavior by user, account, region, plan, environment, or risk tier;
- ramp a candidate model route through internal traffic, canary, A/B test, and broader rollout;
- connect flag evaluation to custom metric events through the Track Insights API;
- use targeting rules, percentage rollouts, and A/B testing with feature flags;
- keep release evidence connected to measurement design, progressive rollout patterns, and feature flag lifecycle management;
- operate an open-source FeatBit deployment or a self-hosted feature flag platform when infrastructure control, data ownership, or auditability matters.
FeatBit is not positioned here as a replacement for every analysis method inside Optimizely. It is the runtime control plane that can make model release evidence operational: who sees the candidate, how far exposure expands, which events prove the outcome, who can roll back, and how the temporary control ends.
Vendor Evaluation Checklist
Use the same checklist for Optimizely, FeatBit, or an internal platform.
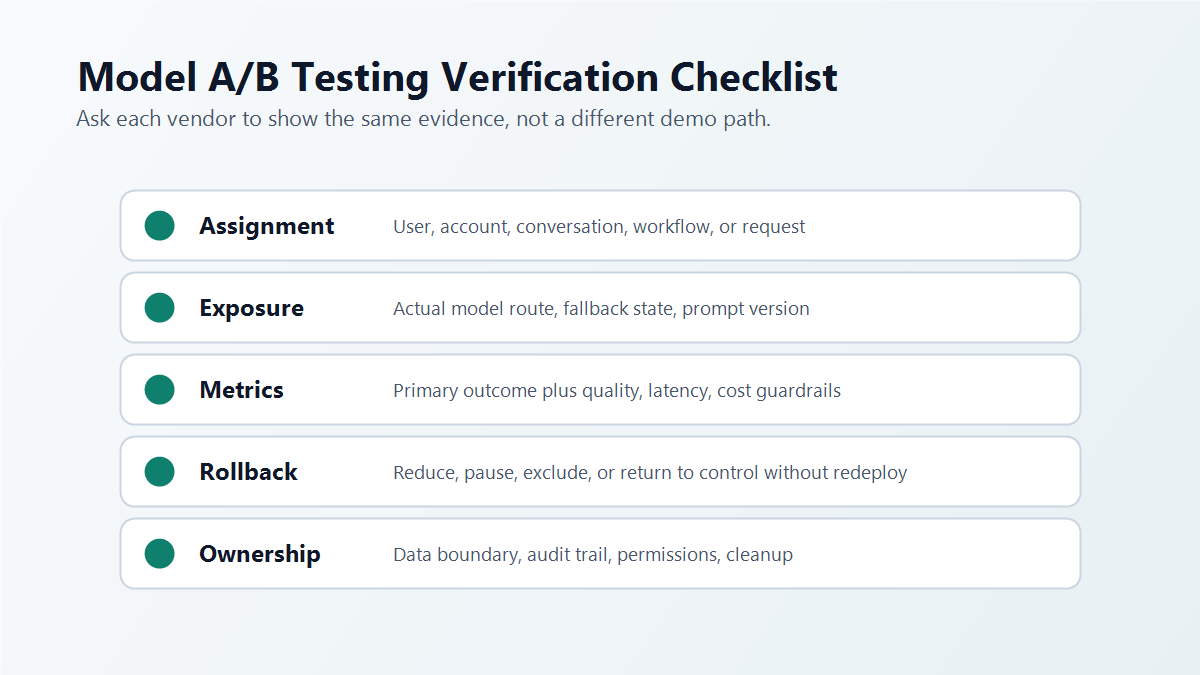
| Area | Verification question |
|---|---|
| Experiment surface | Is this a web experiment, feature experiment, backend model route test, or recommendation strategy test? |
| Assignment | Can the platform assign by user, account, conversation, workflow, request, or another custom unit? |
| Runtime placement | Is the decision evaluated where the AI behavior actually runs? |
| Exposure evidence | Can the event record actual model route, fallback state, prompt version, and variation? |
| Metrics | Can primary outcomes, quality signals, latency, cost, and support guardrails be joined to exposure? |
| Rollback | Can a release owner reduce, pause, exclude, or roll back without redeploying? |
| Data boundary | Where do prompts, outputs, scores, user identifiers, and event payloads travel and persist? |
| Governance | Who can edit variations, targeting, metrics, rollout percentage, and rollback rules? |
| Cleanup | What happens to losing routes, temporary flags, old prompts, and event schemas after the decision? |
Common Mistakes
Treating Optimizely's statistical model as the whole model test. Statistical analysis helps interpret results. It does not prove the application served the right AI model route to the right unit.
Using Web Experimentation for a backend AI decision without a runtime contract. Web tests are valuable for digital experiences. Backend model routes need assignment, execution, telemetry, and rollback where the model call occurs.
Recording assignment instead of actual exposure. If candidate traffic falls back to control, the event should say so. Otherwise the candidate may look safer or better than it was.
Randomizing per request for a multi-turn product. Chat, tutoring, support, and agent workflows often need conversation or workflow consistency.
Letting metric choice happen after the test starts. Write the primary metric, guardrails, and decision rule before production exposure.
Forgetting cleanup. When the decision is made, remove the losing route or convert the flag into an intentional long-lived operational control with an owner.
Bottom Line
Optimizely model A/B testing can mean several things: a statistical method, a web or feature experiment, or a real production comparison between AI model routes. The practical evaluation is not whether the vendor can run an A/B test. It is whether your team can create a trustworthy release path from assignment to actual exposure, outcome evidence, guardrail review, rollback, and cleanup.
Choose Optimizely when its experimentation products fit your existing digital experience, feature experimentation, and analysis workflow. Evaluate FeatBit when the decisive need is open-source or self-hosted runtime release control for AI model behavior, with targeted exposure, reversible rollout, custom events, auditability, and lifecycle cleanup.
Source Notes
- Optimizely Feature Experimentation context: Optimizely's Feature Experimentation introduction is cited for feature flags, A/B tests, targeted deliveries, rollback, client-side SDKs, server-side SDKs, and supported feature experimentation functionality.
- Optimizely A/B test workflow context: Optimizely's Run A/B tests in Feature Experimentation documentation is cited for the basic A/B test configuration path and implementation steps.
- Optimizely Web Experimentation context: Optimizely's Web Experimentation product page is cited for public positioning around web A/B testing, multivariate testing, AI-driven variation ideas, traffic distribution, and analytics.
- Optimizely statistics context: Optimizely's Bayesian A/B test documentation and experimentation distribution methods are cited for public statistical configuration and traffic allocation context.
- FeatBit implementation context: A/B testing with feature flags, targeting rules, percentage rollouts, Track Insights API, measurement design, progressive rollout patterns, feature flag lifecycle management, self-hosted feature flags, and the FeatBit GitHub repository support the release-control workflow described here.
- This article compares public documentation signals and evaluation criteria. It does not claim private roadmap details, pricing advantage, benchmark results, security rankings, compliance status, or customer outcomes for Optimizely or FeatBit.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the Optimizely model A/B testing query as a release-decision evaluation. - Use
vendor-fit-map.pngnear the opening because it separates Optimizely, FeatBit, and internal systems by experiment surface, runtime control, evidence, and rollback. - Use
model-ab-poc-loop.pngin the proof-of-concept section because it shows the path from offline gate to exposure, decision, rollback, and cleanup. - Use
model-testing-checklist.pngbeside the checklist because it gives buyers a concrete verification path for demos and proofs of concept.