Model A/B Testing: What It Is and When to Use It
Model A/B testing is the practice of comparing two or more AI model routes with controlled real-user exposure, stable assignment, outcome metrics, guardrails, and rollback. It answers a release question: should this candidate model become the default for this product workflow?
That makes it different from an offline benchmark, a model leaderboard, or a prompt playground comparison. Those can qualify a model before production. Model A/B testing decides whether the model improves the product under real traffic without creating unacceptable quality, latency, cost, safety, or support risk.
For FeatBit, the important point is operational: model A/B testing is a release-control workflow. A feature flag assigns eligible users, accounts, conversations, or workflows to a model route. Exposure and outcome events create the evidence trail. Guardrails and rollout rules keep the decision reversible while the team is still learning.
The Short Definition
A model A/B test compares a control model route against a candidate model route in production, using comparable traffic and predefined metrics.
The minimum shape is:
model_ab_test:
decision: should candidate_model become the default support answer model?
control: current_support_model_route
candidate: support_model_b_route
assignment_unit: conversation
eligible_scope: paid support chat
primary_metric: resolved_without_human_escalation
guardrails:
- p95_latency
- cost_per_resolved_case
- fallback_rate
- human_correction_rate
rollback: route candidate traffic back to control
The word "route" matters. In many AI systems, the user-visible behavior is not only the model name. It may include a prompt version, retrieval profile, tool policy, temperature setting, fallback policy, or provider route. If those change together, the test is a model-route A/B test. Calling it a pure model test can mislead the team about what actually caused the result.
What Model A/B Testing Is Not
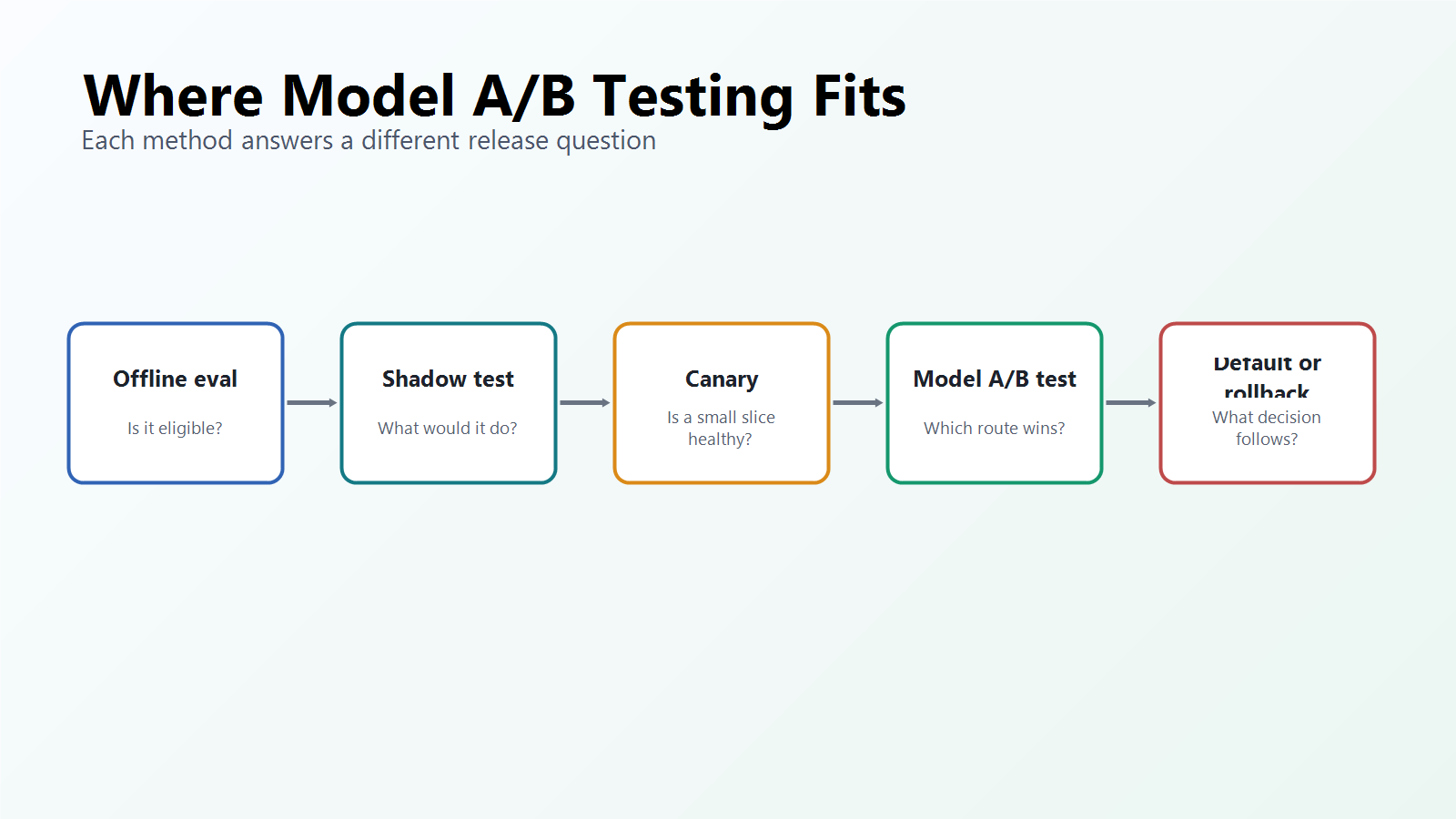
Teams often use several evaluation methods before a model reaches broad traffic. Model A/B testing belongs in that sequence, but it should not replace every other method.
| Method | What it answers | What it does not answer |
|---|---|---|
| Offline eval | Does the candidate perform well on curated tasks, examples, or rubrics? | Whether real users and real workflows improve. |
| Shadow test | What would the candidate have produced without affecting users? | Whether users behave differently when they actually receive the output. |
| Canary rollout | Is a small visible slice healthy enough to expand? | Whether the candidate beats the control on a planned outcome. |
| Model A/B test | Which model route performs better for the release decision? | Whether the model is safe for every future segment or use case. |
| Monitoring | Is production behavior healthy after rollout? | The counterfactual result from a controlled comparison. |
This taxonomy keeps expectations clean. OpenAI's evals documentation describes evals as a way to define and run structured model assessments before or around deployment. That is useful, but a production model A/B test has a different job: compare user outcomes after real exposure. NIST's AI Risk Management Framework also frames AI work around mapping, measuring, managing, and governing risk; for model releases, the A/B test is one measurement input inside a broader release-risk decision.
When To Use A Model A/B Test
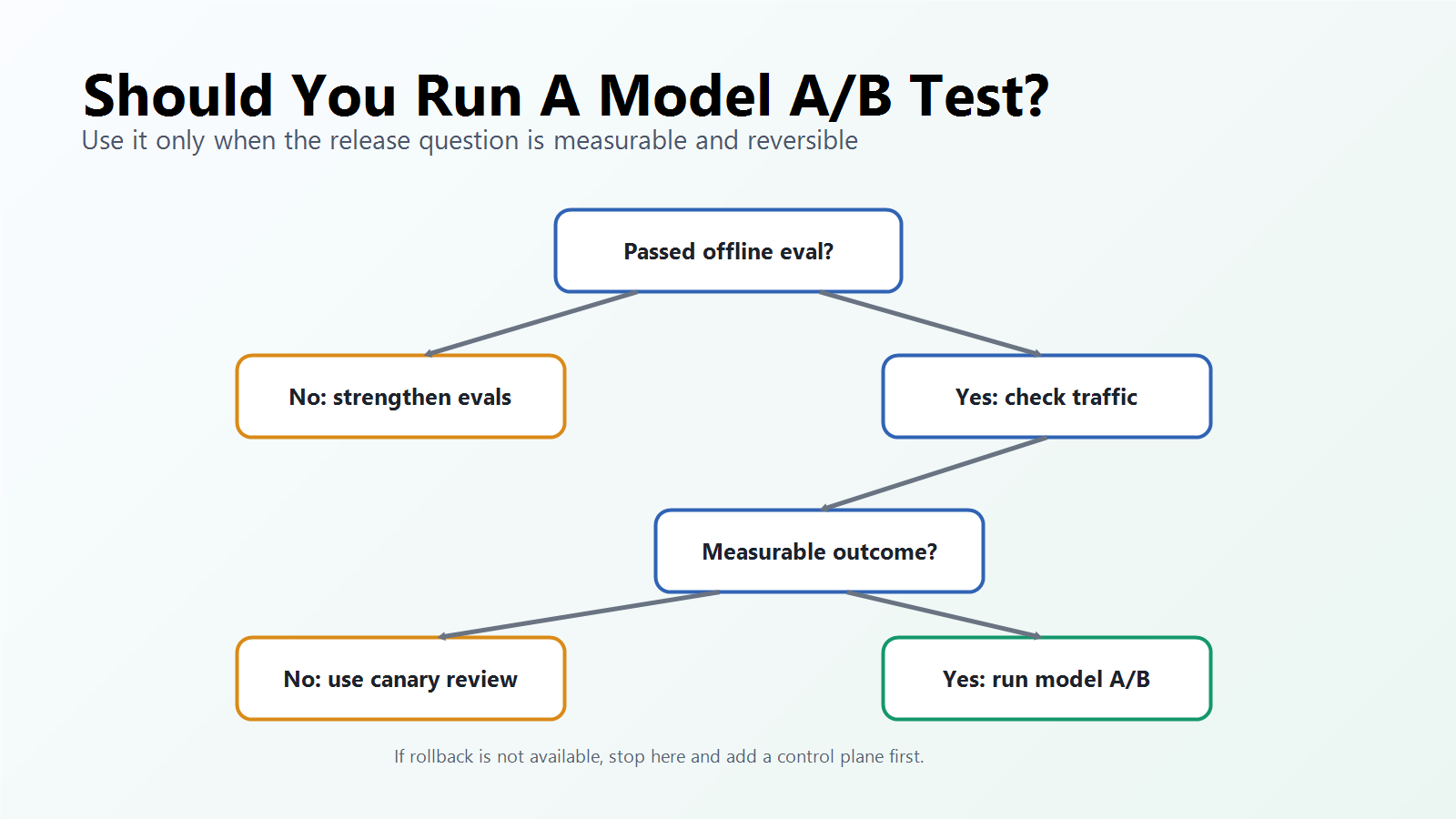
Use model A/B testing when five conditions are true:
- The candidate model has passed offline evaluation or review for severe failures.
- The product outcome can be measured from real traffic.
- The assignment unit can stay stable during the experiment.
- The model route can be rolled back without redeploying the application.
- The team has enough traffic, time, and event quality to make the comparison meaningful.
Do not use it as the first safety screen for a risky model. Start with offline evals, human review, red-team cases, or shadow testing. Do not use it when the traffic volume is too low to support the decision. In that case, a canary with qualitative review, segment-by-segment rollout, or a stronger offline evaluation set may be more honest.
The key test is whether the team has a real release decision to make. If the question is "which model looks better in examples?", run evals. If the question is "can this model route survive a small visible slice?", run a canary. If the question is "does the candidate improve the product outcome enough to replace or expand the control?", run a model A/B test.
Design The Release Decision Before Traffic
A model A/B test should start with a release decision, not a dashboard.
Write down:
| Decision field | Example |
|---|---|
| Candidate change | Route eligible support conversations to model B. |
| Current behavior | Route those conversations to model A. |
| Expected improvement | More conversations resolved without escalation. |
| Eligible population | Paid accounts using English support chat. |
| Assignment unit | Conversation, because multi-turn continuity matters. |
| Decision window | 14 days or until the agreed exposure target is reached. |
| Rollback trigger | Severe quality failure, missing telemetry, high fallback rate, or breached latency target. |
| Cleanup expectation | Promote the winning route or remove the temporary candidate branch. |
FeatBit's measurement design guidance uses the same discipline: define the primary metric, guardrails, and event design before exposure starts. That prevents the common failure mode where a team ships the model first and then searches for a metric that makes the result look acceptable.
Use Feature Flags For Assignment And Rollback
The assignment layer should be visible and reversible. A hidden random function inside a model gateway can split traffic, but it usually does not give product, engineering, and operations teams a shared control point for targeting, rollout, audit, and rollback.
OpenFeature's flag evaluation specification describes a vendor-neutral model for evaluating typed flags with a flag key, default value, evaluation context, and optional evaluation details. That shape maps naturally to model A/B testing because the application needs a stable model-route decision for a specific user, account, conversation, or workflow.
In a FeatBit-style implementation, a multivariate flag can select the route:
type ModelRoute = {
model: string;
promptVersion: string;
retrievalProfile: string;
};
const route = await flags.getJson<ModelRoute>(
'support_answer_model_route',
{
key: conversation.id,
custom: {
assignmentUnit: 'conversation',
accountId: account.id,
plan: account.plan,
locale: conversation.locale
}
},
{
model: 'current_support_model',
promptVersion: 'support_v3',
retrievalProfile: 'baseline'
}
);
const answer = await runSupportModelRoute(route, conversation);
The flag should be evaluated close to the model call, not on a page view that may never trigger the AI behavior. Exposure should be recorded when the assigned route actually runs.
FeatBit implementation primitives for this workflow include A/B testing with feature flags, targeting rules, percentage rollouts, and the Track Insights API. The flag controls assignment. Track events connect exposure to product outcomes.
Build The Evidence Trail
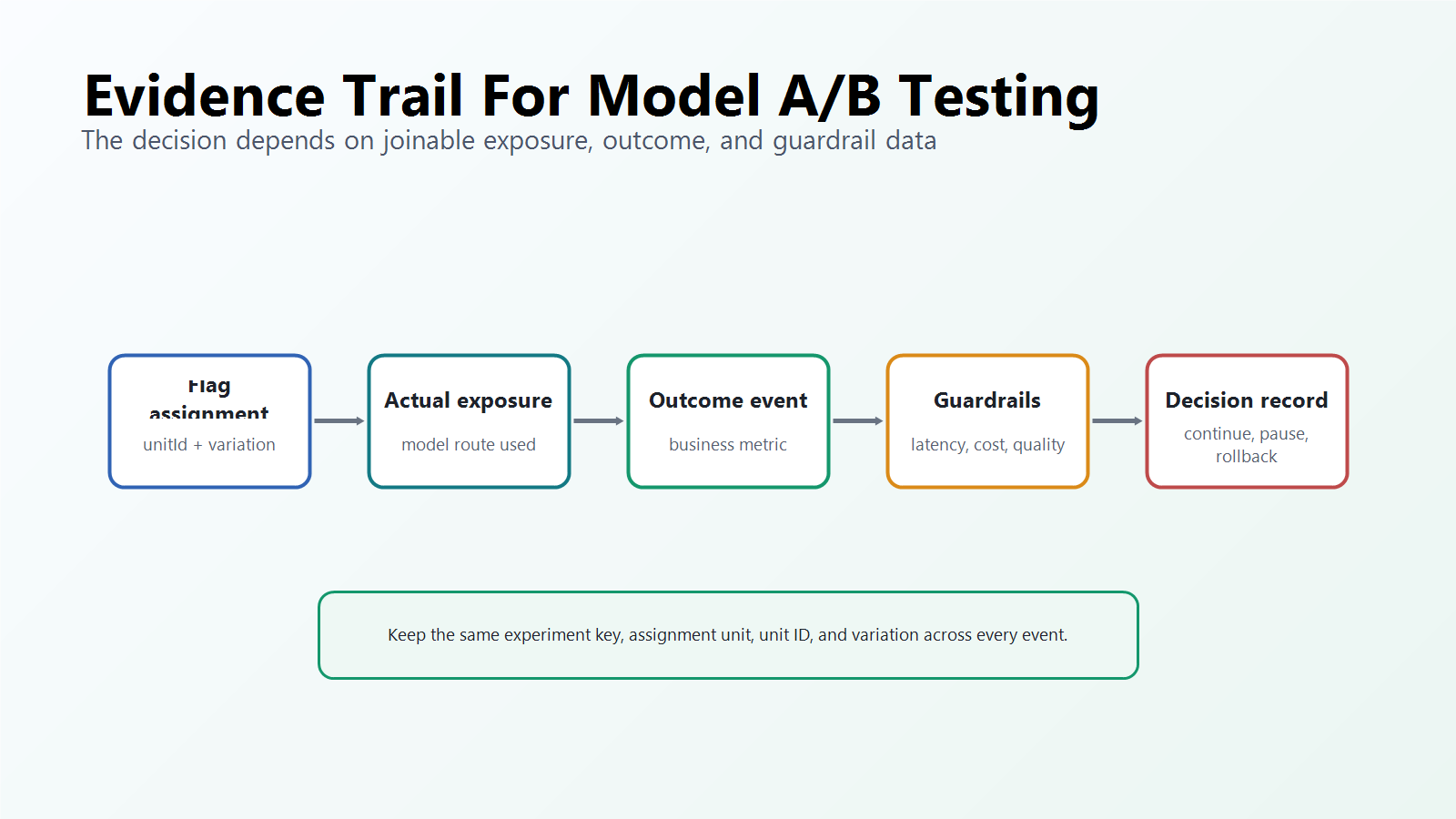
Every model A/B test needs two event families:
- Exposure events record which model route actually served the unit.
- Outcome events record what happened later in the user or workflow journey.
At minimum, keep these fields joinable:
| Field | Why it matters |
|---|---|
flagKey or experimentKey |
Names the release decision. |
assignmentUnit |
Explains whether the unit is user, account, conversation, request, or workflow. |
unitId |
Joins exposure, outcome, guardrail, and rollback evidence. |
variation |
Names the assigned control or candidate route. |
modelRoute |
Records the actual execution path, not only the intended assignment. |
promptVersion |
Prevents prompt drift from being mistaken for model impact. |
fallbackUsed |
Shows when candidate traffic did not actually receive candidate behavior. |
latencyMs and estimatedCost |
Turns performance and cost into guardrails. |
Optimizely's Feature Experimentation documentation says every experiment needs at least one metric and distinguishes primary metrics from secondary or monitoring metrics. That category language is useful for model A/B testing too. The primary metric decides the release question; guardrails and monitoring metrics decide whether the experiment is safe enough to continue.
For AI models, common primary metrics include resolved case without escalation, successful task completion, accepted answer, qualified reply, or cost per successful task. Common guardrails include latency, provider errors, fallback rate, human correction rate, unsafe-output reports, support complaints, and cost.
Choose The Right Assignment Unit
The assignment unit is the thing that should remain consistently assigned during the test.
| Assignment unit | Good fit | Watch out for |
|---|---|---|
| User | Personal assistants, search, recommendations, copilots | A single user may perform unrelated tasks. |
| Account | B2B support, admin workflows, enterprise assistants | Fewer units can slow learning. |
| Conversation | Chat, tutoring, support flows, multi-turn experiences | Returning users may later enter another conversation. |
| Workflow | Agent tasks, document generation, coding workflows | The system needs a durable workflow ID. |
| Request | Stateless routing or backend inference optimization | Users may see inconsistent behavior across turns. |
For a multi-turn AI experience, conversation or workflow assignment is often cleaner than request assignment. For B2B products, account assignment may match the business decision better than user assignment. The goal is not to maximize sample size at any cost. The goal is to compare comparable experience.
The related guide on AI experiment randomization by user or conversation goes deeper on this choice. If the main uncertainty is shadow exposure versus visible exposure, use shadow testing vs A/B testing for models as the decision guide.
Treat Rollback As Part Of The Test
Rollback should be written into the test design before exposure starts.
rollback_when:
severe_quality_issue: any confirmed harmful or materially wrong answer
missing_telemetry: exposure or outcome events stop arriving
latency_guardrail: p95 latency breaches the agreed service target
fallback_guardrail: candidate fallback rate exceeds the planned threshold
segment_harm: priority segment shows unacceptable degradation
rollback_action:
immediate: set default route back to control
scoped: exclude affected segment from candidate eligibility
aftercare: preserve evidence and decide whether to restart, revise, or stop
The exact thresholds should come from the team running the release. The important principle is that the operator can reduce exposure or return to the control model without waiting for a redeploy.
FeatBit's progressive rollout patterns page covers staged exposure patterns such as internal-first, canary, percentage-based rollout, and segment-targeted rollout. Model A/B testing often sits in the middle of that path: after the candidate is safe enough to compare, before it becomes the default.
Common Mistakes
Calling a route test a model-only test. If the model, prompt, retrieval profile, and fallback policy changed together, the result belongs to the route bundle.
Using offline evals as the production decision. Offline evals qualify a model for exposure. They do not prove business impact under real user behavior.
Recording intended assignment instead of actual exposure. If candidate traffic falls back before producing output, the exposure event should say so.
Randomizing at request level for a multi-turn product. The sample size may look larger, but the user experience and causal readout can get worse.
Ignoring guardrails when the primary metric improves. A model can improve resolution while making latency, cost, or correction workload unacceptable.
Leaving experiment flags behind after the decision. A temporary model test should end with a recorded release decision and a cleanup plan. FeatBit's feature flag lifecycle management guidance helps teams separate temporary experiment controls from permanent operational controls.
How This Article Differs From The Deeper Guides
This page is the terminology and decision-frame entry point for model A/B testing. If you already know you need to run the test, use the more specific guides:
- How to A/B test AI models for business impact for metric design, guardrails, and business outcome framing.
- A/B for models: production experiment architecture for runtime architecture, exposure events, and control-plane boundaries.
- AI benchmarks vs real-user outcomes for the case where offline scores and production outcomes disagree.
- AI-native experimentation and feature flags for broader AI changes across prompts, retrieval, tools, agents, and configuration.
The bottom line: model A/B testing is not just splitting traffic between two models. It is a controlled release decision. Use offline evals to qualify candidates, feature flags to assign and roll back model routes, production metrics to compare outcomes, and guardrails to stop expansion before a narrow issue becomes a broad release problem.
Source Notes
- External evaluation context: OpenAI's Evals documentation is cited for structured model evaluation before or around deployment.
- AI risk context: NIST's AI Risk Management Framework is cited for the general risk-management framing around mapping, measuring, managing, and governing AI risk. This article does not make compliance claims.
- Feature flag standard context: OpenFeature's flag evaluation specification is cited for vendor-neutral flag evaluation language.
- Experimentation category terminology: Optimizely's Feature Experimentation metrics documentation is cited for primary, secondary, and monitoring metric concepts. It is not used as a vendor ranking.
- FeatBit implementation context: A/B testing with feature flags, targeting rules, percentage rollouts, Track Insights API, measurement design, progressive rollout patterns, and feature flag lifecycle management support the release-control workflow described here.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes model A/B testing as a release decision with assignment, metrics, guardrails, and rollback. - Use
model-testing-map.pngnear the opening because it explains where model A/B testing fits relative to offline evals, shadow tests, canaries, and monitoring. - Use
use-model-ab-testing-decision-tree.pngin the timing section because it helps readers decide whether the method fits their current model-release stage. - Use
model-ab-evidence-trail.pngin the evidence section because it visualizes the connection between flag assignment, exposure, outcomes, guardrails, and release decisions.