Should AI Feature Flag Evaluation Run Client-Side or Server-Side?
Evaluate AI feature flags on the server by default when the flag controls prompts, model routes, retrieval settings, tool permissions, cost limits, safety rules, or experiment assignment. Use client-side evaluation for presentation-only choices where the browser can safely know the rule result. Use a hybrid pattern when the server makes the authoritative AI decision and passes a minimal, already evaluated value to the client.
That answer is more useful than "server-side is secure" or "client-side is faster." AI feature flags sit on a decision boundary. The placement of evaluation decides what data moves across the network, who can inspect the rollout logic, whether exposure events are trustworthy, and how quickly you can roll back when a model or prompt behaves badly.

What Evaluation Placement Really Means
Feature flag evaluation is the moment your application asks, "For this context, which variation should run?" In an AI system, the variation might select:
- a prompt bundle;
- a model provider or model version;
- a retrieval profile;
- a guardrail threshold;
- an agent tool permission;
- a fallback path;
- an experiment allocation.
Client-side evaluation means that a browser, mobile app, desktop app, or embedded client receives enough information or an evaluated result to decide the user experience locally. Server-side evaluation means the backend service evaluates the flag for a user, account, conversation, workflow, or request before the AI behavior runs.
FeatBit's SDK documentation draws the same architectural line: server-side SDKs are designed for multi-user systems and evaluate locally, while client-side SDKs are designed for single-user contexts and rely on the server to evaluate flags. The practical decision is not about which SDK is more modern. It is about where the authoritative decision belongs.
The Short Decision Rule
Use this table when you need a fast answer.
| Flag controls | Recommended evaluation location | Why |
|---|---|---|
| Prompt version, model route, retrieval profile, tool access, guardrail threshold | Server-side | Keeps sensitive behavior, provider choice, cost routing, and safety control outside the client |
| Experiment assignment for an AI behavior | Server-side or edge-side | Creates authoritative exposure evidence and avoids client-side tampering |
| AI response rendering, empty state, tooltip, onboarding copy, UI layout | Client-side | The browser can safely know and apply the variation |
| Server-rendered page that depends on AI eligibility | Server-side, then hydrate client with the result | Avoids flicker and keeps assignment consistent |
| Low-latency personalization at CDN or edge | Edge-side with constrained context | Reduces latency while keeping the decision outside the user's device |
| Mobile or offline UX fallback | Client-side with cached evaluated values | Preserves experience when the network is unreliable |
The default for AI behavior is server-side. The default for cosmetic or presentation behavior is client-side. The default for mixed experiences is hybrid: evaluate once in the trusted runtime, then pass only the value the client needs.
Why AI Flags Raise The Evidence Bar
Ordinary UI flags often change what a user sees. AI flags can change what the system does, how much it costs, which data is retrieved, which tool is called, and which output the user trusts.
That changes the evaluation placement decision in four ways.
First, AI flags often touch sensitive configuration. Prompt names, model routes, retrieval profiles, safety thresholds, and agent tool policies may reveal product strategy or risk controls. Even if none of that is a legal secret, it rarely belongs in a downloadable browser payload.
Second, AI flags often require authoritative context. A backend service usually has the account tier, region, compliance boundary, risk class, conversation ID, and current entitlement state. The client may have only a partial view, and client-provided attributes can be incomplete or manipulated.
Third, AI flags often drive expensive work. If a flag selects a model route, a retrieval depth, or an agent workflow, the evaluation result can change token cost, provider load, latency, and downstream support work. That decision should be made where budgets, rate limits, and fallbacks are enforced.
Fourth, AI flags often become experiment exposure. If the goal is to evaluate quality and business outcomes, the team needs a reliable record of which unit saw which variant. Server-side exposure logging is usually easier to trust because it can be emitted at the same moment the AI behavior actually runs.
Client-Side Evaluation Is Still Useful
Client-side evaluation is not wrong. It is just the wrong default for AI behavior that changes backend execution.
Use client-side evaluation when the flag controls a browser-local experience:
- showing an AI beta entry point;
- changing the position of an assistant button;
- testing onboarding copy for an AI feature;
- hiding an AI panel from users who are not eligible;
- choosing a client-only layout for a generated summary.
These flags may still matter to product metrics, but they do not choose the prompt, model, retrieval path, or tool permission. The client can safely receive the evaluated value because the consequence is mostly presentation.
Client-side evaluation also helps mobile or desktop clients that need cached behavior during poor network conditions. In that case, keep the flag scope narrow. The client can decide how to render the experience, while the backend still rechecks any AI action that has security, cost, or data-access impact.
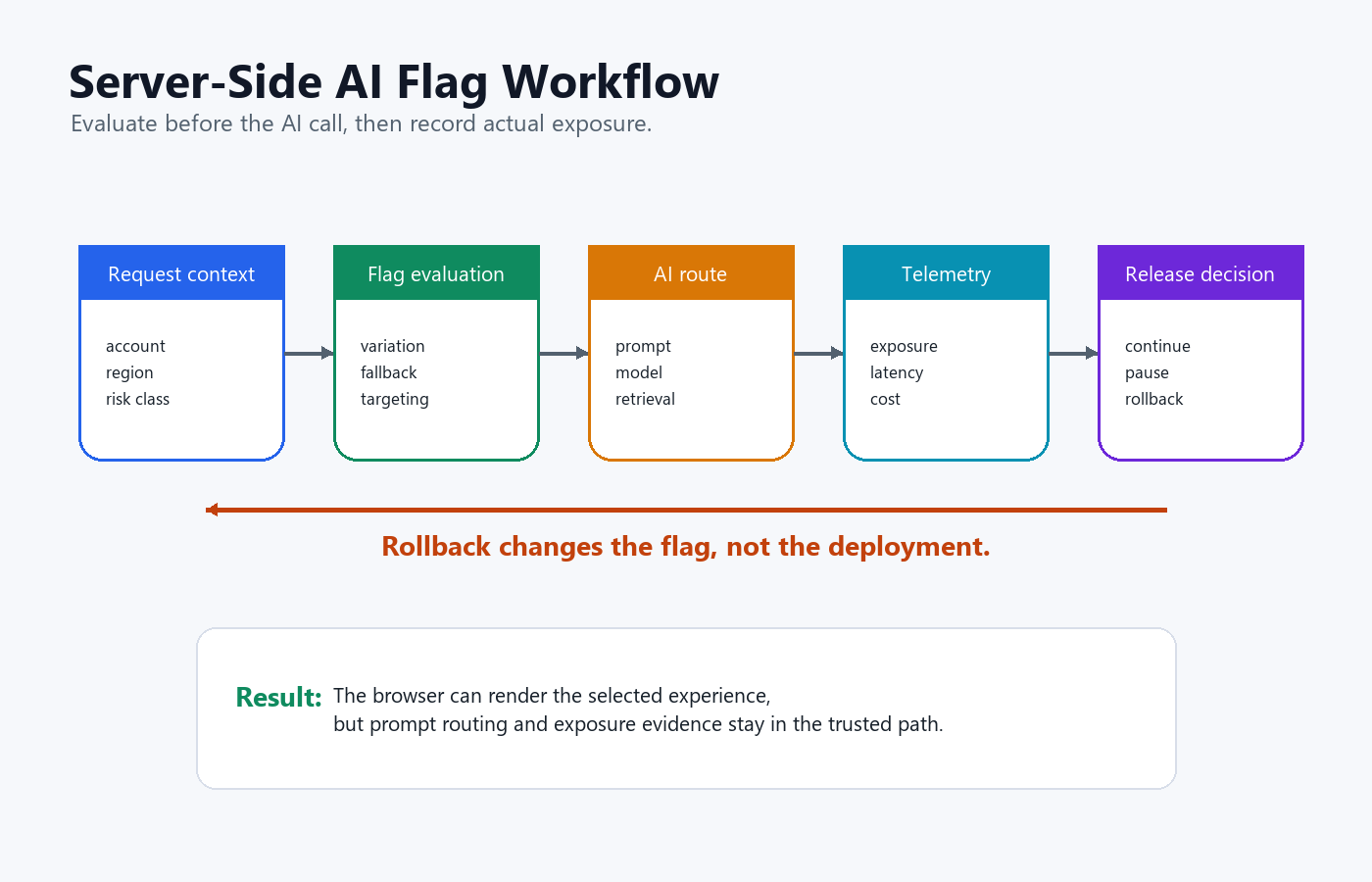
Server-Side Evaluation Should Control AI Behavior
When an AI flag changes real behavior, evaluate it where the behavior is executed.
For a support assistant, the backend should evaluate support_prompt_route before calling the model. For a coding agent, the service should evaluate write_tool_enabled before exposing the tool. For a RAG application, the API should evaluate retrieval_profile before it fetches documents. For model cost control, the server should evaluate model_tier before spending tokens.
That server-side boundary gives the team five operating advantages:
| Need | Why server-side helps |
|---|---|
| Confidential rollout logic | The client receives only the outcome it needs, not the rule set |
| Trustworthy context | The backend can use authoritative account, region, entitlement, and risk attributes |
| Cost control | Token budgets, provider routing, and fallback behavior are enforced before the AI call |
| Audit and rollback | Flag changes and evaluated behavior can be tied to backend logs and release records |
| Experiment evidence | Exposure events can be emitted when the AI route actually runs |
This is also where FeatBit's release-control model fits naturally. The flag is not a UI preference. It is a runtime control for exposure, rollback, and learning. FeatBit's AI control layer and AI experimentation pages expand that operating model.
Edge Evaluation Is A Server-Side Variant
Edge evaluation is useful when latency matters and the decision can be made with a small, safe context. For example, an edge runtime may choose whether a signed-in user is eligible for an AI search beta before a page reaches the origin service.
Treat edge evaluation as a constrained server-side pattern, not as client-side evaluation. The decision still runs outside the user's device. The difference is that it runs closer to the user with stricter limits on data access, package size, connection reuse, and runtime APIs.
Edge evaluation works best when:
- the flag needs low-latency gating before the first render;
- the context is small and already available at the edge;
- the result can be forwarded to the origin or page renderer;
- the full AI behavior still runs in a backend service;
- rollback can propagate quickly enough for your incident model.
Avoid edge evaluation when the flag requires heavy user lookup, sensitive policy joins, detailed experiment writes, or complex AI routing that belongs in the application service.
The Hybrid Pattern For Web Apps
Most web applications should use a hybrid pattern:
- Evaluate the AI behavior flag on the server.
- Execute or authorize the AI behavior on the server.
- Emit exposure and outcome events from the trusted path.
- Send a minimal evaluated value to the browser for rendering.
In a Next.js application, this often means evaluating flags in a Server Component, route handler, or server action, then passing evaluated values into client components as props. That keeps the browser from calling the SDK directly for sensitive AI decisions, while still letting the UI render without a second flag request.
type AiRoute = "control" | "candidate_prompt" | "disabled";
export async function SupportAssistantShell({
accountId,
userId,
}: {
accountId: string;
userId: string;
}) {
const aiRoute = await evaluateAiFlag<AiRoute>("support-assistant-route", {
key: accountId,
custom: {
userId,
surface: "support_chat",
},
}, "control");
return <SupportAssistantClient aiRoute={aiRoute} />;
}
The client receives candidate_prompt, not the targeting rule, SDK credential, prompt body, model provider secret, or experiment allocation logic. The server remains responsible for making the real AI call and recording the exposure.
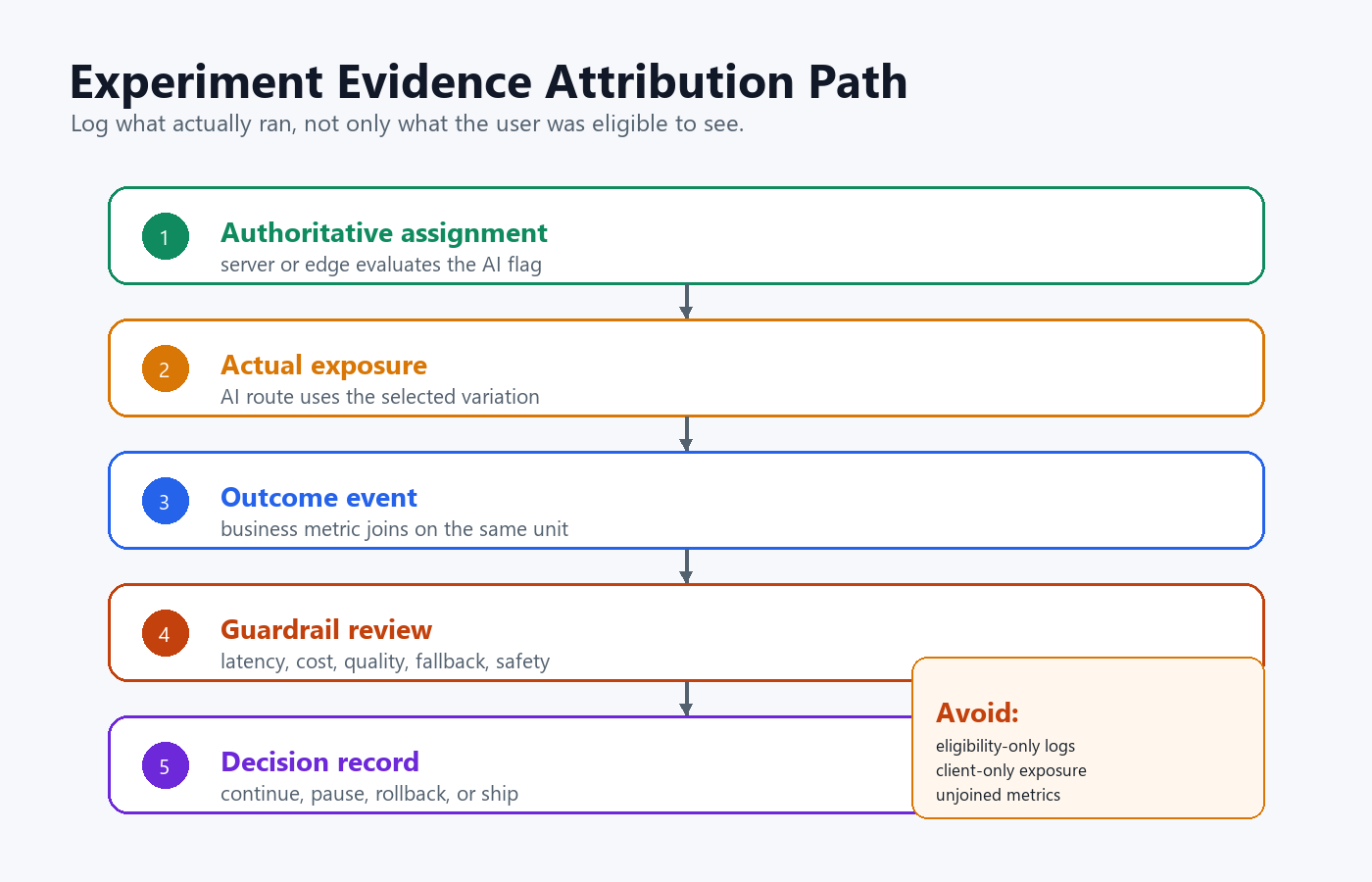
How Evaluation Placement Affects Experiments
The tracker question belongs to experimentation and evaluation because placement changes the quality of the result.
If an AI experiment is assigned client-side but the AI behavior executes server-side, the team can end up with mismatched evidence. The browser may record that a user was eligible for a variant, while the backend silently falls back to the control path because of policy, quota, provider failure, or missing context. The experiment then analyzes intended exposure, not actual exposure.
For AI experiments, log exposure where the behavior is used:
{
"event": "ai_flag_exposure",
"flagKey": "support-assistant-route",
"unitId": "account_1842",
"variation": "candidate_prompt",
"surface": "support_chat",
"evaluationLocation": "server",
"timestamp": "2026-06-05T09:15:30Z"
}
Then join outcome events to the same unit, flag, and variation:
{
"event": "support_case_resolved",
"unitId": "account_1842",
"variation": "candidate_prompt",
"resolvedWithoutEscalation": true,
"latencyMs": 1860,
"estimatedCostUsd": 0.012
}
FeatBit's Track Insights API supports sending feature flag variation results and custom metrics for analytics and experimentation. FeatBit's measurement design guidance is the companion decision step: define the primary metric and guardrails before exposure begins.
Security And Privacy Checks
Evaluation placement is a security and privacy design decision even when the article is not about compliance.
Before putting AI flag evaluation on the client, ask:
- Would the flag payload reveal prompt names, model routes, internal segments, pricing tiers, or risk rules?
- Can a user alter the context and receive a different AI behavior?
- Does the flag result authorize data access, tool access, or provider spend?
- Does the client have enough context to make a correct decision without sending extra personal data?
- Would client-side exposure logging be accepted as evidence during an incident review?
If any answer is uncomfortable, move the authoritative evaluation to the server and let the client consume only a safe result.
Do not put server-side SDK credentials, management API tokens, provider keys, or broad environment secrets in browser code. If a client-side SDK or client-side API path is used, scope it to the client use case and keep privileged decisions behind your backend.
A Practical Architecture Checklist
Use this checklist before shipping an AI feature flag.
| Question | Better answer |
|---|---|
| What does the flag actually control? | Name the AI surface: prompt, model, retrieval, tool, guardrail, UI, or experiment |
| Who owns the authoritative context? | Evaluate where account, entitlement, region, risk, and experiment unit are trustworthy |
| Can the client safely know the rule result? | If not, evaluate on server or edge and pass a minimal value |
| Is this an experiment? | Log exposure where the AI behavior actually runs |
| Does the flag affect cost or data access? | Enforce it before the AI call, not after rendering |
| What is the fallback? | Keep the previous behavior available until the release decision is settled |
| How will rollback happen? | Use targeting, percentage reduction, or flag disablement without redeploying |
| What happens after the decision? | Clean up temporary experiment flags or convert them into intentional operational controls |
This placement decision also connects to flag lifecycle management. A temporary prompt experiment should not become a permanent branch just because it was evaluated server-side. FeatBit's feature flag lifecycle management model helps teams record owner, evidence, decision, and cleanup path.
Common Mistakes
Using client-side evaluation for model routing. The browser can request the assistant UI, but the backend should decide which model route actually runs.
Logging eligibility instead of exposure. A user who was eligible for a variant did not necessarily receive it. Log exposure when the AI behavior executes.
Passing too much context to the client. If client evaluation requires sending account risk, entitlement, compliance, or pricing attributes to the browser, the boundary is probably wrong.
Evaluating the same flag twice in different places. If the server and client can disagree, users see inconsistent behavior and experiment analysis becomes noisy. Evaluate once per request path and reuse the result.
Treating edge as unlimited backend compute. Edge runtimes are useful for low-latency gating, but complex AI decisions usually need the application service.
Removing the fallback too early. AI behavior can pass an offline eval and still fail production guardrails. Keep rollback available until production evidence supports the release decision. For the broader relationship between evals and rollout control, see Can Feature Flags Replace AI Evals?.
The FeatBit Perspective
FeatBit treats feature flags as release-decision infrastructure. For AI systems, that means the flag should sit where the release decision is real.
If the decision changes backend behavior, evaluate it in a trusted backend or edge runtime. If the decision changes only presentation, client-side evaluation is fine. If the user experience spans both, evaluate the AI control server-side and pass the minimal result to the client.
That operating model gives product and engineering teams a clean chain:
- the flag controls runtime AI behavior;
- the evaluation context carries the right assignment unit;
- the exposure event records the actual variant served;
- the outcome event measures quality and business impact;
- the release owner can continue, pause, roll back, or ship with evidence.
The bottom line: AI feature flag evaluation should run where the risk is controlled and the evidence is trustworthy. For most AI behavior, that is server-side.
FAQ
Should AI feature flag evaluation run client-side or server-side?
Run it server-side by default when the flag controls AI behavior, cost, data access, model routing, prompt selection, retrieval, tool access, or experiment assignment. Use client-side evaluation for safe presentation flags.
Is client-side evaluation ever acceptable for AI features?
Yes. It is acceptable for UI-only choices such as showing an AI beta button, changing onboarding copy, or rendering an assistant panel. Recheck any real AI action on the server.
Should a Next.js app evaluate AI flags in Server Components?
Often, yes. Evaluate sensitive AI flags in a Server Component, route handler, or server action, then pass the evaluated value to client components. That avoids duplicate SDK calls and keeps privileged logic out of the browser.
Is edge evaluation client-side or server-side?
Edge evaluation is a server-side variant. It runs outside the user's device, closer to the user, and is useful for low-latency gating when the context is small enough for the edge runtime.
Where should exposure events be logged for AI experiments?
Log exposure where the AI behavior actually runs. If the backend selects a model route or prompt, the backend should record the evaluated variation and the assignment unit.
Source Notes
- FeatBit implementation context: SDK overview, Retrieve feature flags with API, Track Insights API, percentage rollouts, AI control layer, AI experimentation, measurement design, and feature flag lifecycle management.
- Feature flag standard context: OpenFeature's flag evaluation specification and evaluation context specification support the distinction between flag evaluation, targeting context, and evaluation metadata.
- Category context: LaunchDarkly's SDK type documentation, Statsig's client vs server SDK documentation, GrowthBook's feature flag platform page, and Optimizely's Feature Experimentation documentation show that modern flag platforms commonly support client, server, mobile, edge, or hybrid SDK patterns. They are cited for category context, not vendor ranking.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the client, server, edge, and hybrid placement decision. - Use
evaluation-placement-map.pngnear the opening because it gives readers a fast decision frame without hiding the guidance outside crawlable text. - Use
server-side-ai-flag-workflow.pngin the server-side section because it shows where prompt, model, retrieval, metrics, and rollback connect. - Use
evidence-attribution-path.pngin the experiment section because it reinforces actual exposure and outcome attribution.