Edge Evaluation for AI Feature Flags: Control AI Changes Before the Model Call
Edge evaluation for AI feature flags means deciding the AI behavior at the earliest safe point in the request path, before the application calls a model, prompt, retrieval profile, or agent tool. The goal is not to move every decision to a CDN or edge function. The goal is to make the runtime control point close enough to the user journey that the team can target exposure, attach the right context, record the variation, and roll back before an AI change expands.
For AI products, that matters because the risky unit is often not a deployed binary. It is a runtime choice: which model answers, which prompt version runs, which retrieval index is searched, whether an agent can use a write tool, or whether a high-cost fallback is allowed. A feature flag evaluated near that decision point becomes a release gate, an experiment assignment, and a telemetry label.
This article is for platform engineers, AI product engineers, and engineering leaders who need to evaluate AI changes against both quality and business outcomes without adding avoidable latency or losing auditability.
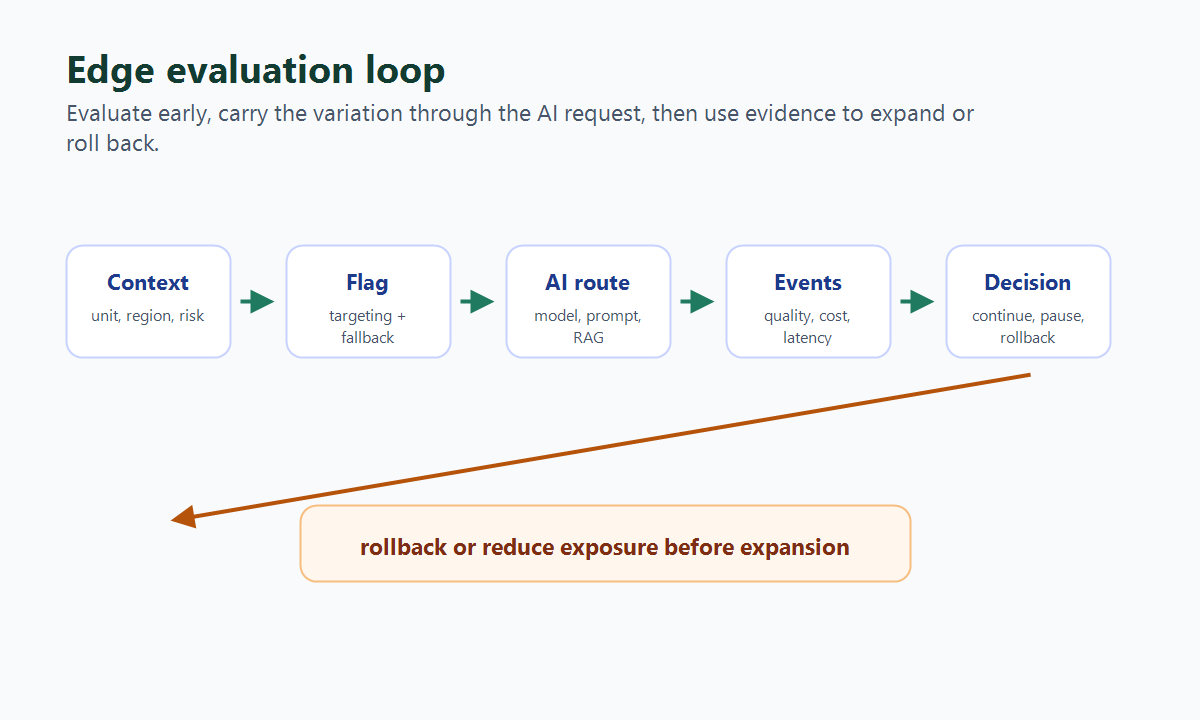
What Edge Evaluation Means For AI Flags
"Edge" can mean a CDN worker, edge middleware, an API gateway, a regional service, or simply the first backend service that has enough context to make the decision safely. For AI feature flags, the useful definition is operational:
| Evaluation point | Good fit | Watch out for |
|---|---|---|
| CDN or edge middleware | coarse routing, locale, plan, beta segment, emergency block | limited access to account state, privacy constraints, SDK support differences |
| API gateway | request-level eligibility, rate tier, region, experiment entry | may not know product outcome or workflow state |
| Backend service | model route, prompt variant, retrieval profile, agent mode | later in the request path, but usually richer context |
| Agent or AI orchestration service | tool policy, autonomy level, fallback mode | must not let the agent bypass the control decision |
The right place is the earliest point that has the required evaluation context and can emit reliable telemetry. OpenFeature describes evaluation context as contextual data used during flag evaluation, such as user, application, host, or other ambient data. For AI flags, that context often includes account tier, region, workflow, risk level, model route, prompt family, retrieval source, and incident mode.
Do not confuse edge evaluation with offline AI evaluation. Offline evals and model benchmarks decide whether a candidate is eligible for exposure. Edge evaluation decides which live request receives which AI behavior, and it preserves the variation key needed to compare outcomes later.
Why AI Changes Need Request-Path Control
AI behavior can vary even when application code stays unchanged. A single production request may depend on several runtime choices:
- prompt version;
- model provider or model size;
- retrieval index, reranker, or source allowlist;
- temperature or tool-choice configuration;
- agent autonomy level;
- fallback behavior when quality, latency, or cost guardrails fail.
If those choices are buried in application config, the team often gets two bad options: deploy a change to everyone, or keep the change out of production until confidence is high. Edge evaluation creates a third option. The team can expose a small, targeted segment, measure the result, and reduce exposure without redeploying.
FeatBit's AI control layer frames every AI decision point as a control surface. Edge evaluation is the request-path version of that idea: put the flag decision before the AI system does work that is expensive, risky, user-visible, or hard to reverse.
Design The Evaluation Context Before The Flag
The most important design step is not naming the flag. It is deciding which context attributes are allowed to influence the AI behavior.
For a support assistant model route, the context might look like this:
{
"key": "account_1842",
"userId": "user_927",
"accountPlan": "enterprise",
"region": "us",
"workflow": "support_chat",
"locale": "en-US",
"riskTier": "standard",
"incidentMode": false
}
That context can support a controlled decision:
| Attribute | Why it matters |
|---|---|
accountPlan |
keep early exposure away from contracts or tiers that need stricter review |
region |
respect deployment, data, and support boundaries |
workflow |
avoid mixing unrelated tasks in one AI experiment |
locale |
prevent rollout where evaluation evidence is weak |
riskTier |
keep high-risk journeys on the baseline behavior |
incidentMode |
force conservative behavior during an operational event |
Keep the context minimal. Do not send sensitive data just because a rule might need it later. If the edge layer lacks a needed attribute, either evaluate later in the backend service or add a safe derived attribute, such as riskTier, instead of exposing raw data.
Use Flags To Control AI Surfaces, Not Just Features
An AI feature flag should represent a release decision the team may need to reverse. The variation should name behavior, not implementation trivia.
Examples:
| AI control surface | Flag variation examples | Outcome to measure |
|---|---|---|
| Prompt version | baseline_prompt, concise_prompt, guided_prompt |
accepted answer, correction rate, escalation |
| Model route | current_model, candidate_model, fallback_model |
successful task, latency, cost per success |
| Retrieval profile | baseline_search, reranker_v2, restricted_sources |
answer acceptance, citation errors, no-result rate |
| Agent mode | read_only, approval_required, limited_write |
task completion, intervention, reversal rate |
| Safety mode | normal, conservative, blocked |
unsafe output reports, blocked valid requests |
This differs from a normal UI flag. The flag may control behavior that users never see directly but that changes cost, quality, and downstream work. That is why every AI flag should have a default, fallback behavior, owner, metric plan, and cleanup path.
FeatBit implementation paths for this pattern include targeting rules, percentage rollouts, experimentation, and the Track Insights API. The flag controls exposure. The events decide whether the exposure was worth expanding.
Attach Exposure Telemetry At The Evaluation Point
The evaluation result should travel with the request. If the flag decides candidate_model, the model call, logs, traces, product analytics, and outcome events should all know that the request used candidate_model.
{
"event": "ai_flag_exposure",
"flagKey": "support_ai_route",
"variation": "candidate_model",
"unitId": "account_1842",
"workflow": "support_chat",
"edgeDecisionPoint": "api_gateway",
"timestamp": "2026-06-03T09:20:00Z"
}
Then join that exposure to the outcome:
{
"event": "support_case_resolved",
"flagKey": "support_ai_route",
"variation": "candidate_model",
"unitId": "account_1842",
"resolvedWithoutEscalation": true,
"latencyMs": 1780,
"estimatedCostUsd": 0.018
}
Without this join, edge evaluation becomes a routing trick. With it, the team can compare quality and business outcomes across AI behavior. That is the difference between "we turned on the new model for some traffic" and "we know whether the new route improved the release decision metric while staying inside guardrails."
OpenAI's Evals documentation and Google Cloud's generative AI evaluation overview are useful references for pre-production model assessment. They do not replace exposure and outcome telemetry in production. Use offline evals to qualify the candidate. Use edge evaluation and experiment events to decide what real users should keep receiving.

A Practical Edge Evaluation Workflow
Use this workflow before exposing an AI behavior change:
-
Define the release decision. Name the AI behavior, eligible audience, primary metric, guardrails, rollback rule, and expected decision window.
-
Choose the evaluation point. Use the earliest layer that has enough context and can emit exposure telemetry. If the edge layer lacks reliable context, evaluate in the backend service.
-
Model the flag variations. Use behavior names such as
baseline,candidate,fallback, orapproval_required. Avoid names that only make sense to one implementation team. -
Attach context carefully. Include stable identity and relevant derived attributes. Avoid sending raw sensitive values through layers that do not need them.
-
Record exposure when the AI behavior is actually used. Do not count a page view as exposure if the request never calls the model, prompt, retrieval path, or agent.
-
Connect outcome and guardrail events. Use the same unit ID, flag key, and variation so analysis can connect the decision to task completion, quality, latency, cost, and support impact.
-
Expand, pause, or roll back from evidence. The edge flag should support quick exposure reduction, but the decision should come from metrics and guardrails, not from dashboard optimism.
This workflow pairs naturally with FeatBit's safe AI deployment and AI experimentation guidance. Safe deployment controls exposure. Experimentation decides whether the exposed behavior should continue.
Common Mistakes
Evaluating too early with too little context. A CDN edge function may know locale and device, but not account risk, entitlement, or workflow state. If the missing context matters, evaluate later.
Letting the agent evaluate its own permissions. Evaluate the flag before the agent receives a tool mode or autonomy level. The agent should receive the result, not a way to query around the policy boundary.
Treating request-level randomization as harmless. For chat, support, onboarding, and agent workflows, changing behavior per request can confuse users and corrupt the experiment. Prefer user, account, session, conversation, or workflow assignment.
Logging the flag after the model call. Exposure telemetry should record the evaluated variation that caused the behavior. If it is added after fallback, retry, or provider routing, the result may not describe what the user experienced.
Using edge evaluation as a substitute for lifecycle management. Temporary AI flags still need an owner, review date, final decision, and cleanup plan. FeatBit's feature flag lifecycle management model helps teams avoid keeping old prompt, model, or agent branches forever.
When Edge Evaluation Is The Wrong Fit
Edge evaluation is not always the best answer.
Use backend evaluation when:
- the decision needs sensitive account, entitlement, policy, or workflow data;
- the flag controls a high-risk side effect such as writes, payments, notifications, or external tool calls;
- the application needs a rich audit record before the AI behavior runs;
- edge runtime constraints make the SDK, cache, or telemetry path unreliable;
- the experiment unit is a long-running workflow that is easier to control inside the orchestration service.
Use edge or gateway evaluation when:
- the decision is coarse and safe, such as internal-only exposure, region gating, or emergency blocking;
- early rejection can avoid unnecessary AI cost;
- the gateway can attach a stable variation label to all downstream traces;
- the rollout needs fast exposure control before requests reach the AI service.
The decision is architectural, not ideological. The best evaluation point is the one that preserves context, privacy, telemetry quality, and rollback control.
How FeatBit Fits The Decision Loop
FeatBit is useful for edge evaluation when the AI change is a runtime release decision. A team can use feature flags to target eligible users, assign stable variations, run percentage rollouts, connect exposure to metrics, and roll back without redeploying the application.
For self-hosted teams, FeatBit also supports a control model where flag data, user context, and evaluation telemetry can stay under the team's own infrastructure boundary. That matters when AI release decisions involve sensitive account context, regulated workflows, or internal model-routing policy.
The important constraint is scope: FeatBit does not replace model evaluation tools, observability, or product analytics. It connects them at the release-control point. Offline evals screen the candidate. Edge or backend flag evaluation controls exposure. Metric events decide whether the change improves quality and business outcomes. Lifecycle rules clean up the control after the decision.
Setup Checklist
Before implementing edge evaluation for AI feature flags, confirm:
- the AI behavior is a reversible runtime decision;
- the evaluation point has enough context to make the decision safely;
- the assignment unit matches the user journey;
- sensitive data is minimized or represented as derived attributes;
- every exposure event includes flag key, variation, unit ID, and decision point;
- outcome events can be joined to exposure events;
- guardrails cover quality, latency, cost, safety, and operational load;
- rollback can reduce exposure without redeploying;
- the flag has an owner, review date, and cleanup path.
Edge evaluation for AI feature flags is not about putting every flag at the network edge. It is about evaluating AI release decisions before risk becomes broad, then preserving the evidence needed to expand, pause, roll back, or learn.
Source Notes
- OpenFeature's evaluation context documentation is used for the general concept that flag evaluation depends on contextual data.
- LaunchDarkly's SDK type documentation and server-side evaluation rules documentation provide category context on server-side and edge SDK evaluation. They are not used as vendor rankings.
- OpenAI's Evals documentation and Google Cloud's generative AI evaluation overview are cited for the distinction between model assessment and production release decisions.
- FeatBit implementation context comes from the linked FeatBit AI control, safe deployment, experimentation, targeting, percentage rollout, Track Insights API, and lifecycle management pages in this article.
Image And Open Graph Notes
- Use
/images/blogs/edge-evaluation-ai-feature-flags/cover.pngas the Open Graph image because it summarizes the request-path control theme. - Use
edge-evaluation-loop.pngnear the opening because it shows how request context, flag evaluation, AI routing, telemetry, and rollback connect. - Use
decision-matrix.pngin the architecture section because it supports the reader's decision about where to evaluate the flag without replacing the crawlable table.