Server-Side Evaluation for AI Feature Flags: A Practical Playbook
Server-side evaluation for AI feature flags is the control point between a user request and an AI system change. The backend decides which model, prompt, retrieval strategy, guardrail, tool policy, or agent workflow should run before the expensive and risky AI call happens.
That placement matters. AI changes are rarely just visual UI variations. They affect cost, latency, answer quality, safety review burden, and downstream user behavior. If the flag is evaluated too late, or only in the browser, the team loses the clean exposure record needed to compare a variant against real outcomes.
This playbook is for engineering, platform, and product teams that need to evaluate AI changes against both quality signals and business outcomes. It does not replace offline evals. It connects offline evals to controlled production learning.
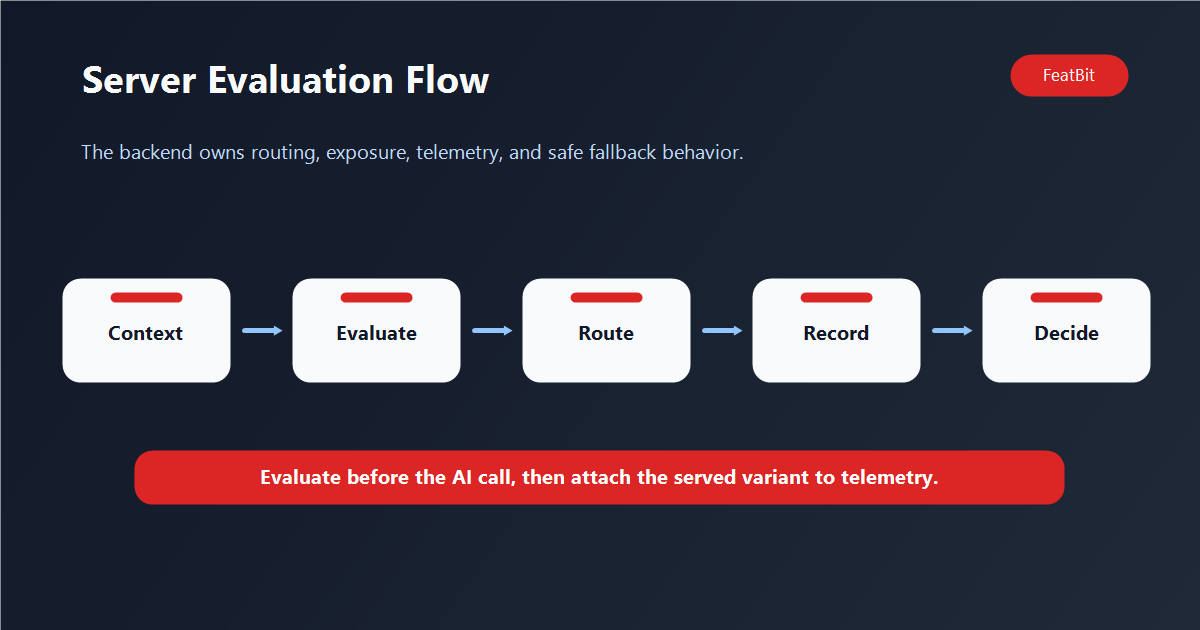
The short version
Evaluate AI feature flags on the server when the flag controls anything that happens before or inside the AI call.
Use server-side evaluation when the flag selects:
- A model provider or model version.
- A system prompt, prompt template, or tool instruction.
- A retrieval strategy for a RAG flow.
- A guardrail policy, moderation path, or fallback path.
- An agent tool, planning strategy, memory policy, or workflow step.
- Token budget, timeout, temperature, or other inference parameters.
The server should evaluate the flag once per request, store the served variant with the request or trace, execute the selected AI path, and emit outcome metrics with the same user and variant context. That is the minimum loop required to decide whether the AI change improved the product.
Why AI flags should often be evaluated on the server
Client-side flags are useful for visual experiences, lightweight UI changes, and situations where browser exposure is the point of the experiment. AI feature flags are different because the risky decision often happens before the user ever sees a response.
If the browser decides the variant, the backend may still need to re-check the decision before it chooses a model. That creates duplicate evaluation paths and makes exposure attribution harder. If the backend decides the variant, the AI call, telemetry, and business event can share one evaluation context.
A server-side AI flag gives you four useful properties:
- A single source of truth for routing. The backend chooses the model, prompt, retrieval path, or agent behavior that actually runs.
- A clean exposure event. The team can record exactly which user or account received which variant.
- A safer control surface. Secrets, provider routing, tool permissions, and policy decisions stay out of the browser.
- A better metric join. Quality, latency, token cost, conversion, retention, and support signals can be connected to the same variant decision.
OpenFeature describes the feature flag evaluation API as the developer-facing layer for resolving typed flag values independent of a control plane or vendor-specific UI. That same separation is useful for AI systems because the application can keep routing logic in the server path while the flag platform manages targeting and rollout rules.
What makes AI evaluation harder than normal feature evaluation
A normal product experiment often asks whether a user clicked, converted, retained, or churned. AI experiments still need those metrics, but they also need answer-quality and operational guardrails.
For example, a new prompt might:
- Increase task completion while also increasing token cost.
- Reduce average latency while worsening long-tail latency.
- Improve automated quality scores while frustrating power users.
- Improve one customer segment while hurting another.
- Pass offline evals while failing on production traffic distribution.
The lesson is not that offline evals are weak. Offline evals are necessary because they catch many failures before users see them. OpenAI's Evals tooling, for example, is built around creating evaluations that test model performance before and during iteration. The production flag layer answers a different question: what happened when this variant ran for real users in this product?
That question needs server-side evaluation, exposure capture, and outcome metrics in one loop.
A practical evaluation loop
For AI feature flags, use this five-step loop.
1. Define the AI decision that the flag controls
Keep each flag close to one decision. A flag named support-answer-model is easier to reason about than a flag that changes the model, retrieval strategy, prompt, and fallback behavior at the same time.
Good AI flag decisions include:
| Flag decision | Example variants | Primary question |
|---|---|---|
| Model version | current, candidate |
Does the new model improve quality without unacceptable cost or latency? |
| Prompt template | baseline, concise, step_by_step |
Which instruction format produces better user outcomes? |
| Retrieval path | keyword, vector, hybrid |
Which retrieval strategy improves answer grounding? |
| Agent workflow | single_step, planner, tool_first |
Which workflow completes the task reliably? |
| Guardrail policy | standard, strict, fallback_first |
Which policy reduces bad outputs without blocking valid work? |
For FeatBit users, this usually maps to a boolean or string flag. Boolean flags work for a single control and treatment. String flags are better when the AI system has multiple variants.
2. Evaluate the flag once in the server request path
The backend should build the user context, evaluate the flag, and pass the resolved variant into the AI service call. In this website repository, FeatBit integration follows the same pattern: flag evaluation happens once per request in a server component or server action, and evaluated values are passed downward instead of calling the SDK from client components.
The same idea applies to a backend AI service:
type AiVariant = "control" | "candidate_model" | "retrieval_hybrid";
async function answerSupportQuestion(request: SupportRequest) {
const user = {
keyId: request.accountId,
plan: request.plan,
region: request.region,
};
const variant = await featbitClient.stringVariation(
"support-answer-ai-path",
user,
"control"
) as AiVariant;
const traceContext = {
userKey: user.keyId,
flagKey: "support-answer-ai-path",
variant,
};
return runAiPath({
question: request.question,
variant,
traceContext,
});
}
The important part is not the specific SDK call. The important part is that the server evaluates the flag before choosing the AI path, and the selected variant becomes part of the request context.
3. Record exposure before the AI output is judged
An exposure is the fact that a user was served a variant. Do not wait until the user clicks, submits feedback, or completes the task. If you only record successful downstream actions, the experiment will ignore users who abandoned the flow.
At minimum, record:
- User or account key.
- Flag key.
- Variant served.
- Request or trace ID.
- Timestamp.
- Important targeting attributes such as plan, region, product area, or request type.
For teams using OpenTelemetry, the variant can be attached to traces as attributes or emitted as an event in the request span. OpenTelemetry defines traces, spans, events, and attributes as standard telemetry concepts, which makes them useful for joining AI request behavior with rollout context across observability tools.
4. Emit quality, guardrail, and business metrics
AI feature flag evaluation becomes useful when exposure is connected to outcome metrics. The metrics do not all need to live in the feature flag tool, but they do need to be joinable by user, request, trace, flag, and variant.
Use three metric groups.
| Metric group | Examples | Why it matters |
|---|---|---|
| Quality metrics | human rating, evaluator score, groundedness score, retry rate, edit distance, escalation rate | Shows whether the AI output was actually better. |
| Guardrail metrics | refusal rate, policy violation, fallback use, timeout, exception, P95 and P99 latency, token cost | Prevents a variant from winning on one metric while hurting reliability or cost. |
| Business metrics | task completion, conversion, retention, support deflection, paid activation, revenue event | Connects the AI improvement to the product outcome the business cares about. |
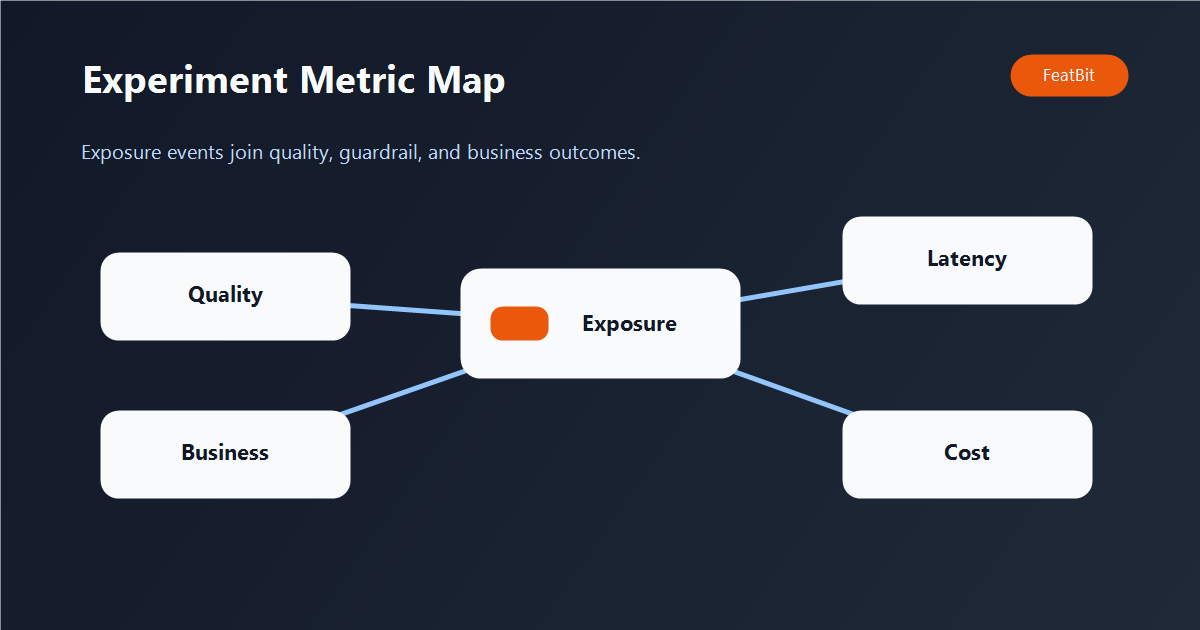
The point is not to collect every possible signal. The point is to pick one primary metric and a small set of guardrails before the rollout begins. Otherwise the team will look at the dashboard after the fact and choose the metric that supports the decision it already wanted to make.
5. Decide with a release rule, not a dashboard feeling
Before the experiment starts, define what will happen when the data arrives.
A useful decision rule might look like this:
- Promote the candidate model from 10 percent to 50 percent if task completion improves and P95 latency does not regress.
- Stop the rollout if token cost per successful task rises above the agreed guardrail.
- Keep the control if the quality score improves but the business metric does not move.
- Segment the decision if enterprise accounts improve but self-serve accounts regress.
This is where feature flags are more useful than a one-off experiment script. The same flag that evaluates the variant can also roll it forward, hold it for one segment, or roll it back.
Where FeatBit fits
FeatBit is an open source feature flag and experimentation platform. The relevant FeatBit pieces for this workflow are:
- Server-side SDK evaluation. Backend services can evaluate flags with user context before routing a request.
- Targeting and percentage rollout. Teams can expose AI variants by user, account, segment, or traffic percentage.
- Experimentation. FeatBit's docs describe A/B testing as a way to compare different features and make data-driven decisions.
- Public evaluation API. For architectures where an SDK is not the right fit, FeatBit also documents a public flag evaluation API pattern for server-side access.
- Self-hosting and data ownership. Teams that need control over feature flag and experimentation data can run FeatBit in their own environment.
For broader AI rollout patterns, read FeatBit's AI experimentation page and LLM canary release guide. For API-based server-side evaluation details, see FeatBit's Flag Evaluation API article.
Example: evaluating a prompt change against quality and business outcomes
Imagine a SaaS product with an AI support assistant. The team wants to replace a long prompt with a more structured prompt that asks the model to cite product documentation before answering.
The hypothesis is:
The structured prompt will improve grounded answers and reduce human escalation without increasing latency beyond the guardrail.
The server-side flag is:
Flag key: support-assistant-prompt
Variations: baseline, grounded_prompt
Initial rollout: 10 percent grounded_prompt
Audience: support assistant users in production
The server evaluates the flag when the support request arrives. The selected variant controls the prompt template. The request trace stores support-assistant-prompt=grounded_prompt or support-assistant-prompt=baseline.
The metric plan is:
| Metric role | Metric | Decision use |
|---|---|---|
| Primary | Resolved conversation without human escalation | Promote only if this improves. |
| Quality | Documentation citation accepted by evaluator | Check whether grounded answers improved. |
| Guardrail | P95 latency | Stop rollout if the new prompt is too slow. |
| Guardrail | Tokens per resolved conversation | Stop rollout if the prompt is too expensive. |
| Business | Trial account activation after support interaction | Check whether better support changes user behavior. |
This is a better release process than "the new prompt looked good in testing." It gives the team a controlled rollout, a rollback path, and an evidence trail.
Common mistakes
Evaluating the flag after the AI call
If the flag is evaluated after the AI response is generated, it cannot control the risky part of the system. Evaluate before model routing, retrieval, tool access, and prompt construction.
Measuring only the AI output
An evaluator score is useful, but it is not the whole product outcome. Pair output quality with user behavior and operational guardrails.
Mixing too many AI changes in one flag
If one flag changes the model, prompt, retrieval, and guardrail policy, the team will not know what caused the result. Split decisions unless the combined bundle is the actual product change being tested.
Forgetting sticky assignment
AI experiences can feel inconsistent if the same user receives different variants across a single task. Use stable user or account keys where possible so the experience remains coherent during the experiment window.
Treating rollout as the final decision
A rollout is not a decision by itself. The decision is whether the evidence supports promotion, rollback, segmentation, or another iteration.
A server-side evaluation checklist
Use this checklist before exposing an AI flag to production:
- The flag controls one clear AI decision.
- The backend evaluates the flag before the AI call.
- The fallback value is safe if FeatBit is unavailable.
- The selected variant is attached to the request, trace, or event context.
- Exposure is recorded even when the user does not complete the flow.
- The primary success metric is defined before rollout.
- Quality and guardrail metrics are defined before rollout.
- Rollout, rollback, and promotion criteria are written down.
- Segment-level analysis is planned for cohorts likely to behave differently.
- The previous AI path remains available until the decision is complete.
FAQ
Is server-side evaluation always required for AI feature flags?
No. If the flag only changes UI copy around an AI feature, client-side evaluation may be fine. Server-side evaluation is preferred when the flag controls model routing, prompt construction, retrieval, tool access, guardrails, cost, or telemetry attribution.
How is this different from offline AI evals?
Offline evals test a candidate change before production exposure. Server-side feature flag evaluation controls how that candidate reaches real users and connects the served variant to production metrics. Use both.
Should every AI model change be an experiment?
Not every change needs a long A/B test, but every meaningful AI behavior change should have a controlled exposure path and clear rollback criteria. Small internal changes may only need internal targeting. Customer-visible changes usually need stronger measurement.
Can this work with an OpenFeature architecture?
Yes. OpenFeature separates the application-facing evaluation API from the provider that resolves flag values. A server-side AI service can use that abstraction while FeatBit or another provider manages the underlying flag data.
Source notes
- FeatBit documentation overview: feature flags, targeting, rollout, and simple experimentation.
- OpenFeature specification: Flag Evaluation API and providers.
- OpenTelemetry specification overview: events and attributes as telemetry concepts.
- OpenAI API reference: Evals.
Image and Open Graph recommendations
- Cover image:
/images/blogs/server-side-evaluation-for-ai-feature-flags/cover.png, 1200 by 630, showing a backend service evaluating a flag before routing to AI variants. - Body image 1:
/images/blogs/server-side-evaluation-for-ai-feature-flags/server-evaluation-flow.png, showing request, server-side flag evaluation, AI routing, and metric collection. - Body image 2:
/images/blogs/server-side-evaluation-for-ai-feature-flags/experiment-metric-map.png, showing exposure events joined to quality, guardrail, and business metrics. - Open Graph image: use the cover image so the preview matches the article's server-side evaluation promise.