Open Source AI Feature Flags: How to Evaluate Runtime Control for AI Releases
Open source AI feature flags are not just free toggles for an AI button. For teams shipping prompts, model routes, retrieval profiles, agent tool modes, guardrail policies, and fallback paths, the real question is whether an open-source feature flag platform can act as a runtime control layer: target the right audience, expose changes gradually, keep data inside the right boundary, preserve release evidence, and roll back without redeploying.
This article is for platform teams, AI product engineers, and engineering leaders who are evaluating open-source feature flags for AI-era software delivery. The goal is not to rank vendors. The goal is to define the evaluation criteria that matter when AI behavior changes faster than traditional release processes can review it.
What Makes An AI Feature Flag Different
A normal feature flag often controls whether a product surface is visible. An AI feature flag can control behavior behind that surface:
| AI control surface | Example variations | Why a flag helps |
|---|---|---|
| Entry point | hidden, internal, beta, public |
Limit who can start the AI flow. |
| Prompt profile | baseline, candidate, citation_first |
Change instructions without redeploying. |
| Model route | stable, candidate, low_cost, fallback |
Shift traffic across model routes gradually. |
| Retrieval profile | verified_docs, tenant_scoped, expanded |
Control grounding, data scope, and source risk. |
| Agent tool mode | disabled, read_only, draft, approval_required |
Stage autonomy before allowing side effects. |
| Guardrail mode | standard, strict, incident |
Tighten behavior for high-risk cohorts or incidents. |
| Fallback path | baseline, human_queue, off |
Keep the product usable when AI behavior fails. |
| Experiment route | control, candidate_a, candidate_b |
Join live exposure to outcome evidence. |
The flag is useful only if it is evaluated before the AI behavior runs. If the application chooses a prompt, calls retrieval, selects a model, or invokes a tool before evaluating the flag, the flag cannot control cost, latency, data exposure, or blast radius.
OpenFeature's documentation describes feature flags as runtime controls that can alter application behavior without deploying new code, and it defines evaluation context as data used for dynamic decisions. That matters for AI systems because the same prompt or model route can be acceptable for one user segment and too risky for another.
Why Open Source Changes The Evaluation
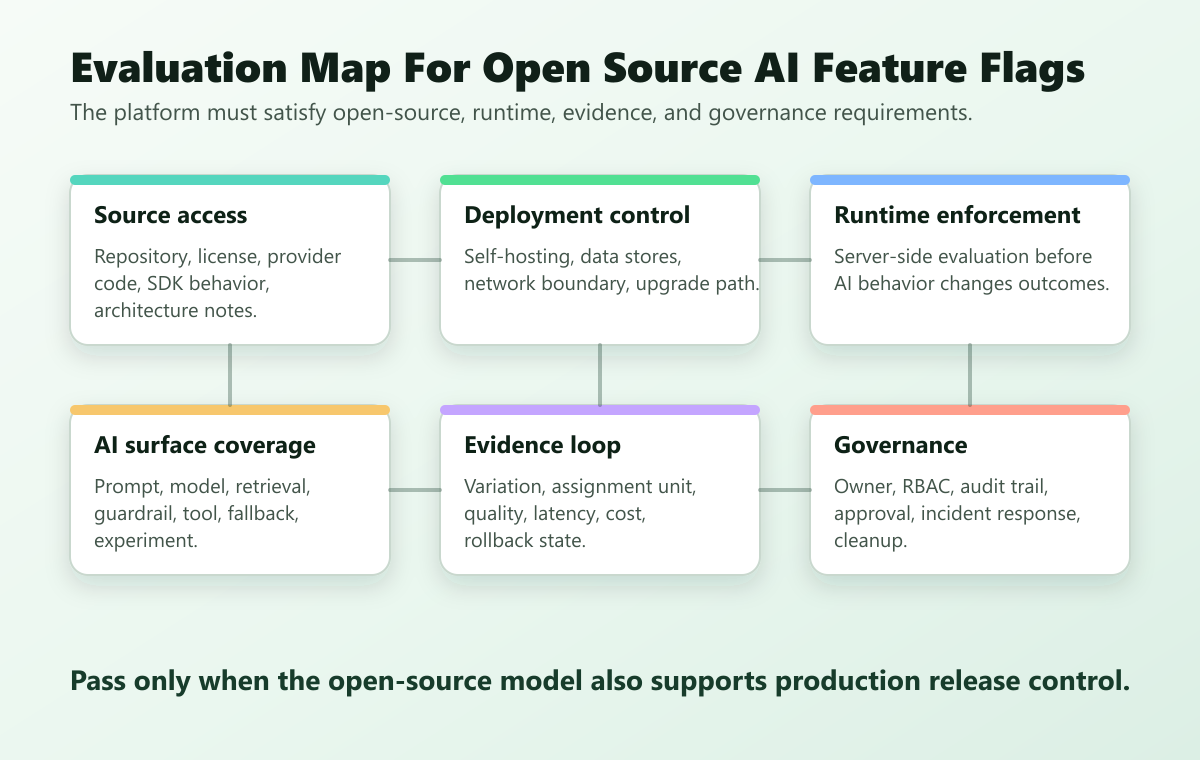
Open source matters for AI feature flags because AI release control often touches data, deployment boundaries, automation, and governance. The value is not only license cost. The value is the ability to inspect, self-host, integrate, extend, and operate the control plane under your own constraints.
Use this decision frame:
| Evaluation question | Why it matters for AI releases | What to inspect |
|---|---|---|
| Can the platform run in your infrastructure? | AI telemetry, user context, and rollout data may need to stay inside a private boundary. | Deployment artifacts, data stores, network topology, upgrade path. |
| Can source and behavior be inspected? | Platform teams need confidence in evaluation, streaming, audit, and data flow behavior. | Repository activity, license, architecture docs, SDK behavior, provider code. |
| Can flags model AI behavior beyond on/off? | Prompts, models, retrieval profiles, guardrails, and tool modes need typed variations. | Boolean, string, numeric, and structured variations. |
| Can evaluation happen in trusted runtimes? | Sensitive AI routing and tool authority should not depend on browser-side logic. | Server-side SDKs, evaluation APIs, edge or gateway patterns. |
| Can rollout evidence be joined to outcomes? | AI releases need quality, latency, cost, safety, and business signals tied to the served variation. | Tracking APIs, insights, data export, observability hooks. |
| Can governance reconstruct the decision? | AI changes need ownership, audit, approval, and cleanup records. | RBAC, audit logs, webhooks, flag lifecycle metadata. |
FeatBit's GitHub repository is the starting point for inspecting the open-source platform itself. FeatBit's self-hosted feature flags hub is the product evaluation path when data ownership, deployment control, or predictable operating cost is part of the decision.
The Architecture Boundary To Check First
For AI releases, evaluate where the feature flag decision is enforced. Open source does not help much if the flag is only a UI toggle while the real AI route is decided somewhere else.
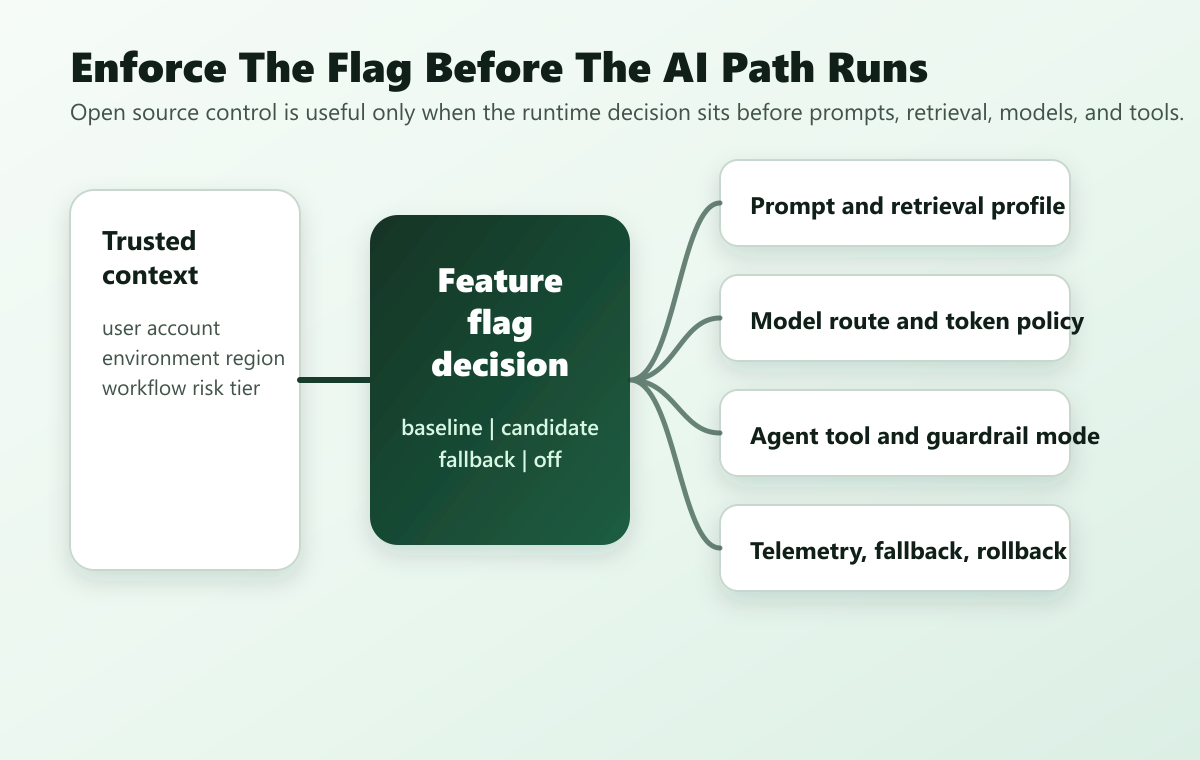
A reliable AI flag architecture has five boundaries:
- The application builds a trusted evaluation context from server-known facts such as user, account, environment, region, workflow, and risk tier.
- The feature flag is evaluated before prompt assembly, retrieval, model routing, tool invocation, or fallback selection.
- The selected variation maps to an approved AI behavior profile.
- Exposure and outcome events preserve the flag key, variation, assignment unit, and AI behavior profile.
- Operators can reduce exposure, switch to fallback, or turn off the route without redeploying.
That pattern keeps release control outside the model. A prompt should not decide its own rollout cohort. An agent should not grant itself a broader tool mode. A model route should not continue serving a risky cohort after operators have paused the release.
OpenFeature Fit: Useful, But Not A Substitute For Operations
OpenFeature is useful in this category because it provides a vendor-agnostic API for feature flagging and a provider model that lets teams plug in different flag management systems. It can reduce application coupling to one vendor-specific SDK surface.
For open source AI feature flags, check three things:
- Does the platform provide or support an OpenFeature provider in the runtime you need?
- Does the provider preserve enough evaluation detail for exposure tracking, diagnostics, and rollout evidence?
- Does the operations layer still provide targeting, percentage rollout, audit, RBAC, environments, and lifecycle cleanup?
FeatBit maintains OpenFeature provider repositories, including a Node.js server-side provider. That is useful for application portability. It does not remove the need to evaluate platform behavior: where flags are hosted, how rules are updated, how user context is handled, how events are tracked, and how rollback is performed.
A Practical Evaluation Checklist
Use this checklist before adopting an open-source feature flag platform for AI releases.
1. Control Surfaces
Ask whether the platform can model the AI decisions you actually need:
- prompt profile;
- model route;
- retrieval profile;
- token budget or latency mode;
- guardrail policy;
- tool authority;
- fallback route;
- experiment assignment;
- incident mode;
- cleanup state.
If the platform only supports simple boolean toggles, it may still hide an AI feature, but it will be weak at controlling AI behavior. Multivariate and structured flags are often necessary when a single release decision maps to a prompt, retrieval scope, model route, and fallback profile.
2. Trusted Evaluation
Decide where each flag should run. Browser-side flags can control visibility and lightweight UI behavior. AI routing, retrieval scope, tool access, and fallback decisions usually belong in a trusted backend, model gateway, orchestration service, or tool router.
FeatBit's SDK overview and Flag Evaluation API are relevant when a team needs to decide between SDK-based evaluation and direct HTTP evaluation for a platform or runtime.
3. Targeting And Progressive Rollout
AI behavior is contextual. The platform should support targeting by:
- user, account, tenant, or organization;
- environment and region;
- plan, beta group, or internal cohort;
- workflow or product area;
- risk tier or approval state;
- stable percentage rollout.
FeatBit documents targeting users with flags and percentage rollouts, including deterministic assignment based on user keys. For AI releases, deterministic assignment is important because evidence becomes hard to trust if the same user, account, or conversation keeps switching variations.
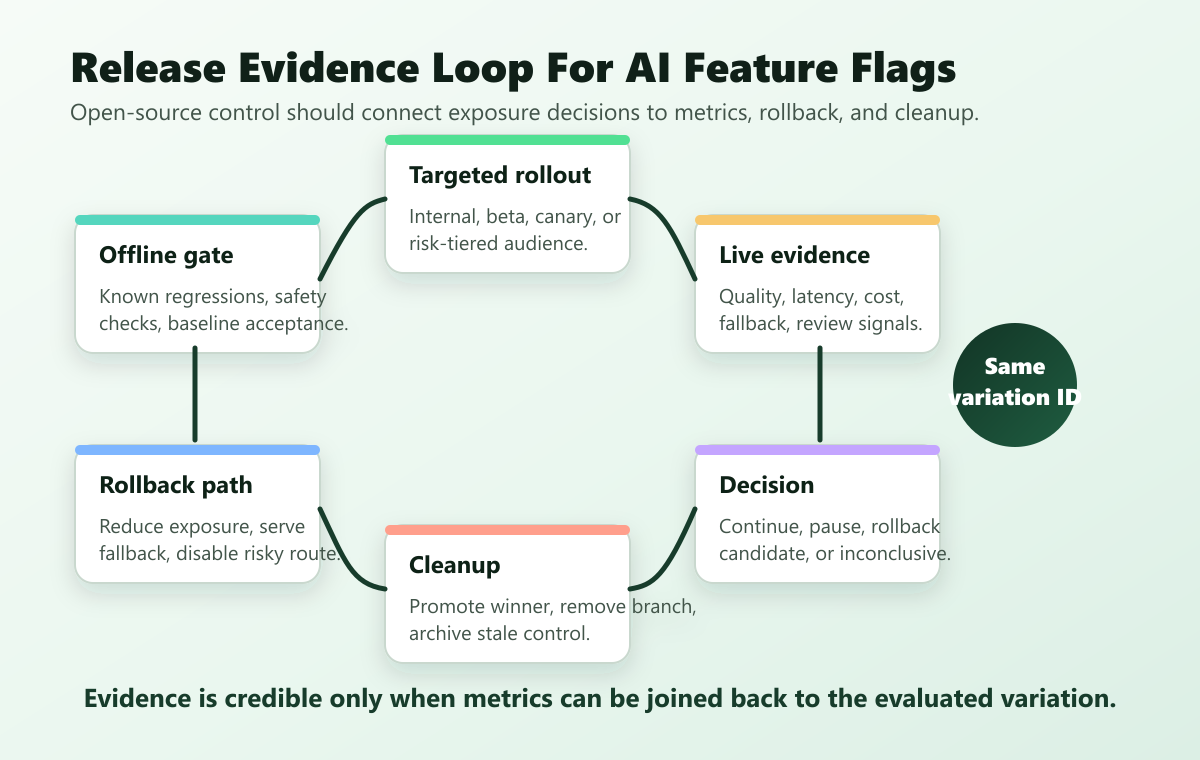
4. Evidence And Observability
An AI feature flag should not only decide behavior. It should help the team learn whether the behavior should expand, pause, roll back, or be removed.
Capture at least:
| Evidence field | Example |
|---|---|
| Flag decision | support_answer_route=candidate |
| Assignment unit | account_id, user_id, or conversation_id |
| AI behavior profile | prompt version, retrieval profile, model route, tool mode |
| Quality signal | acceptance, correction, escalation, review score |
| Reliability signal | latency, timeout, fallback rate, error rate |
| Cost signal | tokens per completed task, cost per workflow |
| Decision state | continue, pause, rollback candidate, cleanup ready |
FeatBit's Track Insights API, flag insights, and observability integrations can be part of this loop. The exact metric system can vary, but the evaluated variation must be visible in the evidence trail.
A Minimal Implementation Pattern
The application pattern is straightforward. Evaluate first, route second, record exposure when the AI path actually runs, and keep a safe default.
type AiRoute = "baseline" | "candidate" | "fallback" | "off";
type AiReleaseContext = {
userId: string;
accountId: string;
environment: "production" | "staging";
region: string;
workflow: "support_answer";
riskTier: "standard" | "high";
};
async function answerSupportQuestion(question: string, context: AiReleaseContext) {
const route = await flags.string<AiRoute>(
"support_answer_route",
{
key: context.accountId,
userId: context.userId,
accountId: context.accountId,
environment: context.environment,
region: context.region,
workflow: context.workflow,
riskTier: context.riskTier,
},
"fallback"
);
if (route === "off") {
return handoffToSupportQueue(question);
}
const profile = aiProfiles[route] ?? aiProfiles.fallback;
const response = await runAiAnswerPipeline(question, profile);
await telemetry.track("ai_answer_exposed", {
flagKey: "support_answer_route",
variation: route,
accountId: context.accountId,
userId: context.userId,
workflow: context.workflow,
promptProfile: profile.promptProfile,
retrievalProfile: profile.retrievalProfile,
modelRoute: profile.modelRoute,
});
return response;
}
The key point is not the exact SDK method. The key point is control order. The flag decision happens before the AI path changes user outcomes.
Governance Questions Specific To Open Source
Open source gives platform teams more control, but it also gives them more responsibility. Before you choose a platform, decide who will own these operating questions:
| Governance area | Question to answer |
|---|---|
| Ownership | Who can create, approve, modify, and archive AI release flags? |
| Environment separation | Can staging, production, and regional environments be managed independently? |
| Audit trail | Can operators reconstruct who changed an AI behavior, when, and for which audience? |
| RBAC | Can high-risk AI controls require stricter access than ordinary UI flags? |
| Incident response | Can alerts or runbooks turn down exposure quickly? |
| Lifecycle cleanup | Can temporary prompt, model, or experiment flags be reviewed and removed? |
| Data boundary | Where are user context, evaluation events, and metric events stored? |
FeatBit's feature flag lifecycle management guidance is relevant because AI teams can create many temporary controls. Without owner, review window, evidence rule, and cleanup expectation, an open-source control plane can become difficult to operate.
Common Mistakes
Avoid these mistakes when evaluating open-source AI feature flags:
- Treating "open source" as the only requirement. You still need targeting, audit, rollout, observability, and lifecycle management.
- Using one global
ai_enabledflag for every AI behavior. It hides the product surface but does not control prompt, retrieval, model, tool, or fallback risk. - Evaluating flags after the AI call. That preserves UI control but loses cost, latency, and blast-radius control.
- Measuring outcomes without recording the evaluated variation. The team will not know which behavior produced the result.
- Randomizing at the wrong unit. A request-level split can corrupt a multi-turn AI conversation; an account-level split may be better for enterprise workflows.
- Keeping temporary AI flags forever. Old prompt and model flags become release debt when the decision is finished.
- Assuming OpenFeature standardization replaces platform operations. It standardizes application integration, not rollout policy, governance, or evidence design.
Where FeatBit Fits
FeatBit's point of view is that feature flags are release-decision infrastructure. For AI-era software, that means runtime controls should help teams decide who sees a prompt, model route, retrieval profile, tool mode, or fallback path; observe what happened; and reverse the decision when the evidence is weak.
For teams evaluating open-source AI feature flags, FeatBit is relevant when the evaluation includes:
- open-source inspection and self-hosted deployment;
- server-side and API-based evaluation;
- targeting rules, user segments, and percentage rollout;
- flag insights and event tracking;
- audit logs, IAM, webhooks, and automation;
- lifecycle management for temporary release controls;
- OpenFeature provider support for application portability.
If you want the broader architecture view, start with FeatBit's AI control layer. If your immediate job is placing flags inside a generative AI application, read feature flags for generative AI applications. If the buying driver is infrastructure ownership, continue with self-hosted feature flags.
Source Notes
- OpenFeature documentation for vendor-agnostic feature flag API, evaluation context, providers, hooks, and events.
- OpenFeature specification for conformance and stability terminology.
- FeatBit GitHub repository for the open-source platform.
- FeatBit percentage rollout documentation for deterministic rollout behavior.
- FeatBit Flag Evaluation API and Track Insights API for evaluation and event collection paths.