AI Software Solution: A Buyer Checklist for Runtime Control
An AI software solution should do more than add a model, prompt editor, or agent workflow to your product. It should give your team a controlled way to release AI behavior: who sees it, which version runs, what evidence proves it worked, how operators pause it, and how the team rolls back without redeploying.
That is the buying frame this article uses. If you are evaluating an AI software solution for production use, look for runtime release control around prompts, models, retrieval, guardrails, agent authority, experimentation, observability, auditability, and cleanup. FeatBit's point of view is that AI behavior should be managed as release-decision infrastructure, not as a hidden configuration change inside a model gateway.
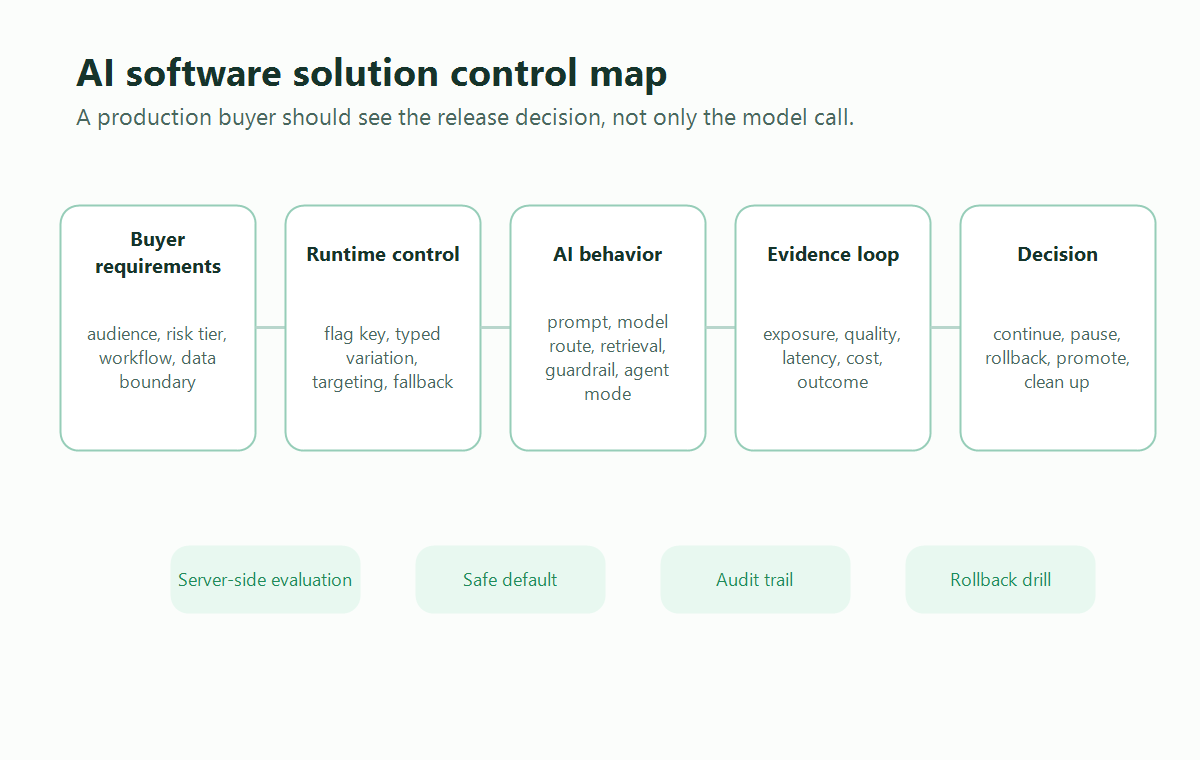
What Buyers Usually Mean By AI Software Solution
"AI software solution" is broad market language. A buyer may mean a support assistant, coding assistant, recommendation system, document workflow, AI search experience, internal agent, model gateway, prompt management tool, or feature-management layer that can control AI behavior.
The useful question is not only "Does it use AI?" The useful question is "Can we operate this AI behavior safely in production?"
For a product, platform, or engineering leader, that means the solution should answer six operating questions:
| Buyer question | Why it matters |
|---|---|
| What can change at runtime? | Prompts, models, retrieval profiles, guardrails, and agent modes often need updates after deployment. |
| Who receives each behavior? | AI changes should start with internal users, beta cohorts, safe accounts, or small traffic percentages. |
| What evidence is collected? | Operators need exposure, quality, latency, cost, fallback, and outcome data tied to the active variation. |
| How precise is rollback? | A bad prompt or model route should not require disabling the entire product. |
| Who can change production AI behavior? | Permissions, approval flow, audit logs, and environment boundaries matter once AI affects users. |
| What happens after the decision? | Temporary AI rollout flags need owners, review windows, and cleanup paths. |
Feature flag vendors and experimentation platforms already frame flags around deploy-release separation, targeting, gradual rollout, and A/B testing. GrowthBook's feature flag documentation, for example, describes controlling application behavior without deploying new code, targeting users, gradually rolling out changes, and running A/B tests. For AI software, those same controls need to extend to AI-specific behavior surfaces.
The Runtime Controls An AI Solution Should Expose
A production AI feature rarely has only one switch. A useful control model separates the surfaces that change risk.
| Control surface | AI example | Recommended control |
|---|---|---|
| Availability | Turn an AI answer feature on for eligible accounts | Boolean release flag with environment and segment targeting |
| Prompt profile | Use a citation-first support prompt | String or JSON variation with fallback prompt profile |
| Model route | Compare baseline and candidate model routes | Multivariate flag or experiment assignment |
| Retrieval profile | Use a narrower index for regulated accounts | Targeted rule by account, region, data tier, or workflow |
| Guardrail mode | Standard, strict, or fallback behavior | Runtime mode flag with explicit owner and decision rule |
| Agent authority | Observe-only, draft, approval-required, or autonomous | Capability-tier flag plus backend enforcement |
| Incident state | Disable one risky behavior during investigation | Kill switch, denylist, or fallback-mode flag |
Do not let a vendor demo collapse these into one global "AI enabled" toggle. A global switch is useful during an incident, but it is too coarse for everyday operations. Buyers should ask whether each risky behavior can be targeted, measured, paused, and rolled back independently.
This is where FeatBit's AI control layer and safe AI deployment pages fit the buyer journey. They turn AI behavior into named runtime decisions: internal targeting first, canary exposure next, metric gates before expansion, and rollback available from the beginning.
A Buyer Checklist For Runtime Release Control
Use this checklist before standardizing on an AI software solution, model gateway, prompt platform, or feature-management layer.
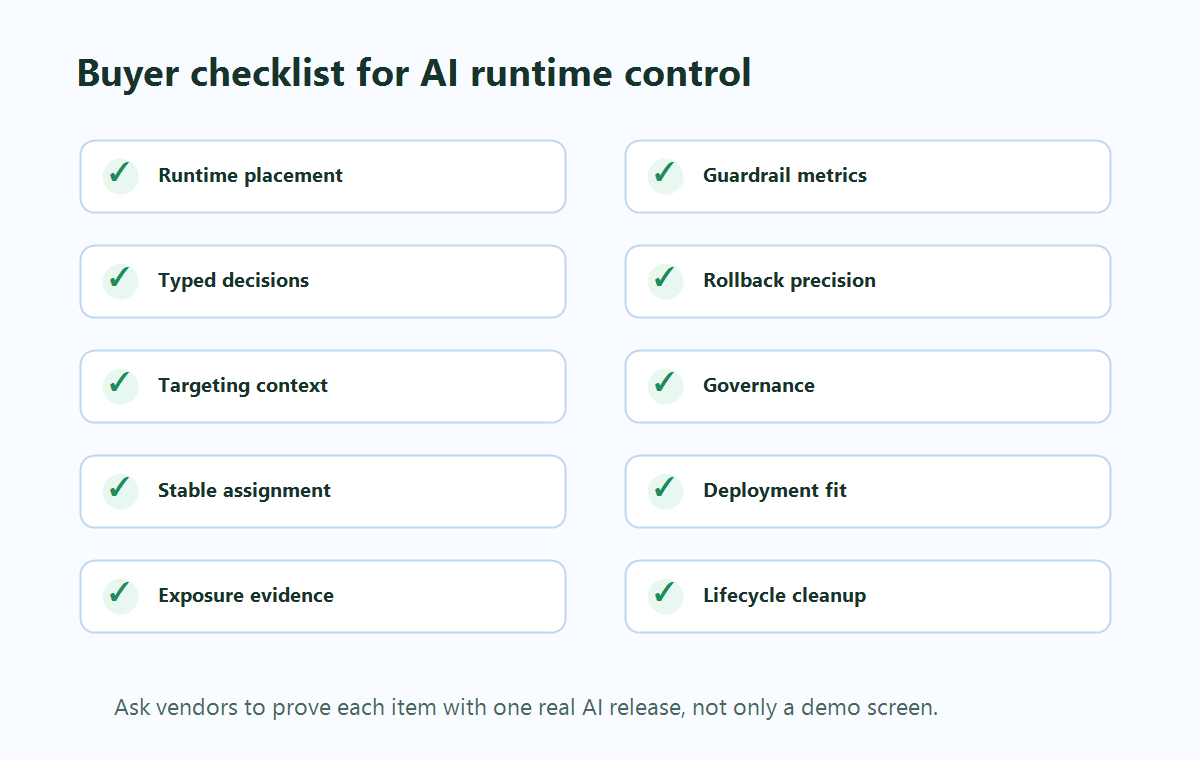
| Evaluation area | What to verify | Weak answer to watch for |
|---|---|---|
| Runtime placement | The decision is evaluated where AI behavior actually runs. | "The dashboard has a setting, but the app decides later." |
| Typed decisions | Variations can represent prompt profiles, model routes, retrieval profiles, guardrail modes, and fallback states. | "Use a text field and parse it however you want." |
| Targeting context | Rules can use user, account, tenant, plan, environment, region, workflow, and risk class. | "We only support all users, beta users, or a random percentage." |
| Stable assignment | Experiments and rollouts stay stable for the right unit: user, account, conversation, or workflow. | "The model gateway randomly chooses per request." |
| Exposure evidence | Events record the flag key, variation, route, fallback state, and assignment unit. | "We only log that the feature was on." |
| Guardrail evidence | Quality, latency, cost, errors, support impact, and fallback rate can stop expansion. | "You can inspect model logs manually." |
| Rollback precision | Operators can reduce, pause, exclude, or return one behavior to baseline without redeploying. | "Turn off the whole AI feature." |
| Governance | Permissions, approval workflow, audit log, environments, and API access fit production change control. | "Any admin can change the production prompt." |
| Deployment model | The control plane fits data ownership, private infrastructure, cost, and operations requirements. | "Everything must run in our hosted account." |
| Lifecycle cleanup | Temporary controls have owners, review dates, and expected end states. | "We clean up flags later when someone remembers." |
The checklist is deliberately operational. It asks for proof that the AI software solution can carry one real production change from intent to targeted exposure to evidence to decision to cleanup.
How Feature Flags Fit Without Becoming The Whole AI Stack
A feature flag platform should not replace every part of the AI stack. It should control the release decision around the parts that already exist.
| System | Role in the AI software solution |
|---|---|
| Model provider | Executes inference and model-specific behavior. |
| Prompt repository or prompt tool | Stores reviewed prompt versions and metadata. |
| Retrieval system | Controls indexes, filters, reranking, memory, and source boundaries. |
| Evaluation harness | Qualifies candidates before production exposure. |
| Observability stack | Stores traces, metrics, logs, user feedback, and quality review data. |
| Authorization and tool router | Enforces hard permissions and side-effect boundaries. |
| Feature flag control plane | Evaluates who receives which behavior, records release evidence, and supports rollback. |
OpenFeature's public specification is useful context here because it describes vendor-agnostic typed flag evaluation with a flag key, default value, evaluation context, and evaluation details. Buyers do not need to adopt OpenFeature for every project, but the concept is important: the application should call a stable runtime decision point before AI behavior runs.
In FeatBit, that runtime decision can be a boolean flag, string variation, JSON variation, rollout rule, segment, or experiment. The AI service then maps the evaluated variation to approved prompts, model routes, retrieval profiles, guardrail modes, or fallback behavior.
type AiReleaseContext = {
userId: string;
accountId: string;
environment: "staging" | "production";
region: string;
workflow: "support_answer" | "contract_review" | "code_assist";
riskTier: "standard" | "sensitive";
};
type AiRoute = {
route: "baseline" | "citation_first" | "fallback";
promptProfile: string;
retrievalProfile: string;
guardrailMode: "standard" | "strict";
};
async function selectAiRoute(ctx: AiReleaseContext): Promise<AiRoute> {
return flags.json("support_ai_route", ctx, {
route: "fallback",
promptProfile: "support_baseline_v1",
retrievalProfile: "verified_docs",
guardrailMode: "strict",
});
}
The exact SDK or provider can vary. The operating principle should not: evaluate the release decision server-side, keep a safe default, record actual exposure, and make rollback independent from redeploying application code.
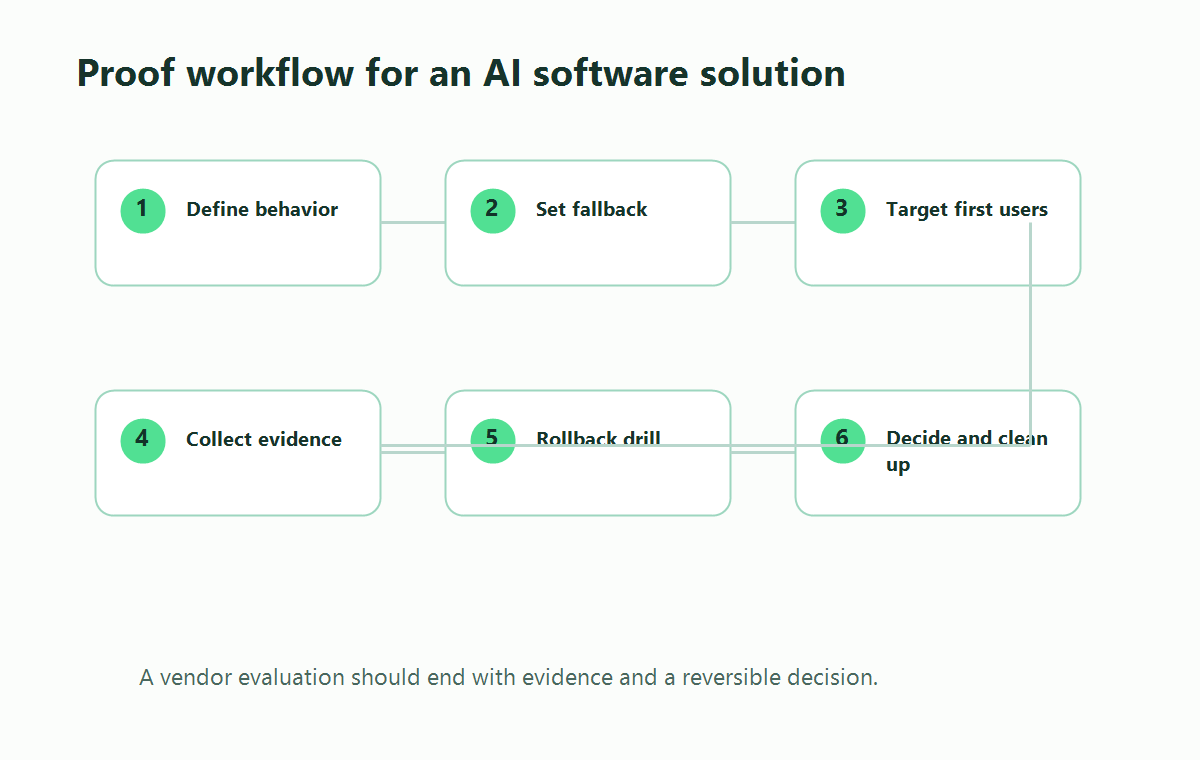
Proof Of Production Readiness
Procurement checklists often focus on features. A production AI software solution needs a proof exercise.
Pick one upcoming AI change and require the solution to run through this path:
-
Define the controlled behavior. Name the prompt, model route, retrieval profile, guardrail mode, tool tier, or fallback path that will change.
-
Define the fallback. Identify the stable behavior that runs when evaluation fails, guardrails trip, or operators roll back.
-
Define the first audience. Start with internal users, a test account, a beta cohort, or a low-risk segment before broad exposure.
-
Define the assignment unit. Decide whether the rollout is stable by user, account, conversation, workflow, or request.
-
Define the evidence. Record exposure events and outcome events with enough context to connect behavior to quality, latency, cost, errors, fallback, and business outcome.
-
Run a rollback drill. Prove that operators can return the affected audience to baseline without a code deploy.
-
Decide and clean up. Promote the winning behavior, pause the rollout, roll back, or keep a long-lived operational control with an owner and review rule.
FeatBit's progressive rollout patterns, measurement design, and feature flag lifecycle management pages expand those steps into a release-decision loop. For implementation details, FeatBit docs cover targeting rules, percentage rollouts, flag insights, audit logs, and the Track Insights API.
Governance Questions For AI Software Buyers
AI governance can sound abstract until the solution reaches production. NIST's AI Risk Management Framework is voluntary guidance, but it is useful buyer context because it frames AI risk management across the design, development, use, and evaluation of AI products, services, and systems.
Translate that into practical release-control questions:
- Who can change prompts, model routes, retrieval profiles, guardrail modes, and rollout percentages in production?
- Does the approval path differ between staging and production?
- Can high-risk workflows require human approval or stricter guardrails?
- Can regulated accounts, enterprise tenants, or sensitive regions receive a safer route?
- Can operators reconstruct which AI behavior ran for a user, account, workflow, and time window?
- Can rollout evidence support continue, pause, rollback, or cleanup decisions?
- Does the control plane need to run in your own infrastructure for data, audit, or operations reasons?
This is where FeatBit's self-hosted and open-source positioning matters. Some teams want a hosted AI-specific workflow. Others want their feature flag and release-control plane closer to their own infrastructure, data boundaries, audit processes, and automation stack. If that is part of the buying decision, evaluate FeatBit's self-hosted feature flag platform, API access tokens, webhooks, and OpenTelemetry integration as part of the solution fit.
Common Mistakes When Buying An AI Software Solution
Buying a prompt editor when the real need is release control. Prompt storage is useful, but buyers still need targeting, rollout, evidence, rollback, and audit history.
Hiding assignment inside the model gateway. If traffic splitting is invisible to product and platform teams, the rollout loses auditability and rollback precision.
Skipping actual exposure events. Intended assignment is not the same as executed behavior. Record what actually ran, including fallback state.
Treating the flag as the security boundary. Feature flags can decide which approved behavior is active. Identity, authorization, sandboxing, scoped credentials, and tool-router enforcement still need to block forbidden actions.
Ignoring lifecycle cleanup. AI teams change prompts, models, guardrails, and retrieval settings quickly. Each temporary control should have an owner, decision rule, and cleanup condition.
Assuming every AI feature needs the same deployment model. A public marketing assistant, internal coding agent, regulated account workflow, and enterprise self-hosted deployment may need different control-plane boundaries.
Where FeatBit Fits
FeatBit fits the AI software solution decision when the buyer wants runtime release control for AI behavior rather than a single-purpose AI configuration UI.
Use FeatBit to control:
- prompt profile, model route, retrieval profile, guardrail mode, fallback path, and agent authority variations;
- internal, beta, segment, percentage, environment, region, and account-based rollout;
- release evidence through insights, custom metric events, experimentation, and observability integrations;
- rollback through kill switches, targeted exclusions, percentage reductions, and fallback variations;
- production governance through environments, IAM, audit logs, API tokens, webhooks, and self-hosted deployment options;
- lifecycle ownership so temporary AI rollout controls become decisions instead of permanent debt.
Do not expect FeatBit to replace the model provider, prompt repository, vector database, evaluation harness, or authorization layer. The stronger architecture keeps those systems specialized and uses FeatBit as the runtime control plane for release decisions.
Bottom Line
The best AI software solution is not the one with the longest AI feature list. It is the one your team can operate in production: targeted, observable, reversible, governed, and clean after the release decision is made.
Before buying or building, choose one real AI change and prove the path. If the solution can define the controlled behavior, target a safe audience, collect trustworthy evidence, roll back precisely, and leave a clear lifecycle trail, it can become part of your production AI operating model. If it cannot, you are buying runtime risk with a better demo.
Source Notes
- GrowthBook category context: GrowthBook's feature flag documentation is used as evidence that feature flag platforms commonly position around deploy-release separation, targeting, gradual rollout, and A/B testing.
- Vendor-neutral flag context: OpenFeature's homepage and flag evaluation specification are cited for vendor-agnostic feature flag APIs, typed evaluation, default values, evaluation context, and evaluation details.
- AI governance context: NIST's AI Risk Management Framework is cited as broad AI risk-management context. This article translates that context into release-control buyer questions and does not claim certification or compliance.
- FeatBit implementation context: AI control layer, safe AI deployment, progressive rollout patterns, measurement design, feature flag lifecycle management, self-hosted feature flags, targeting rules, percentage rollouts, flag insights, audit logs, and Track Insights API support the operating model described here.
Image And Open Graph Notes
- Use
/images/blogs/ai-software-solution-runtime-control/cover.pngas the Open Graph image because it frames the article as a buyer checklist for AI release control. - Use
solution-control-map.pngnear the opening to summarize the control-plane relationship between buyer requirements, runtime flags, AI behavior, evidence, rollback, and cleanup. - Use
buyer-checklist.pngbeside the checklist section because it gives evaluators a scannable summary of the decision criteria already available in crawlable text. - Use
proof-workflow.pngin the proof section because it visualizes how a vendor evaluation should move from contract to rollout evidence and cleanup.