Feature Flag AI Control Plane: What to Evaluate Before You Buy
A feature flag AI control plane is the runtime layer that decides which approved AI behavior is active for a user, account, environment, rollout stage, or incident state. It does not replace identity, model evaluation, observability, or security review. It makes those systems actionable by giving teams a targetable, auditable, reversible way to release prompts, model routes, retrieval profiles, agent tool modes, fallback paths, and experiments.
That is the buyer job behind the keyword. A team is not only asking whether a platform can turn a feature on or off. The team is asking whether feature flags can become the operating layer for AI-era release decisions.
What a feature flag AI control plane should mean
The phrase "AI control plane" can become too broad. For a feature flag platform, keep the definition narrow:
- It controls runtime exposure for AI behavior after deployment.
- It evaluates a deterministic decision before the prompt, model route, retrieval path, or agent capability runs.
- It targets by the context that changes risk: user, account, tenant, region, plan, workflow, environment, rollout cohort, or risk tier.
- It leaves evidence: who changed the control, which variation ran, what audience saw it, and which metrics or reviews informed the next step.
- It preserves rollback and cleanup so temporary AI controls do not become permanent release debt.
This definition is intentionally operational. NIST's AI Risk Management Framework is useful background because it frames AI risk management as ongoing governance, mapping, measurement, and management work across AI system design, development, deployment, and use. For release teams, the practical translation is that the control point must remain active after deployment, not only during pre-launch review.
Where the control plane sits
Feature flags should sit between hard boundaries and AI behavior. They should not be the hard boundary themselves.
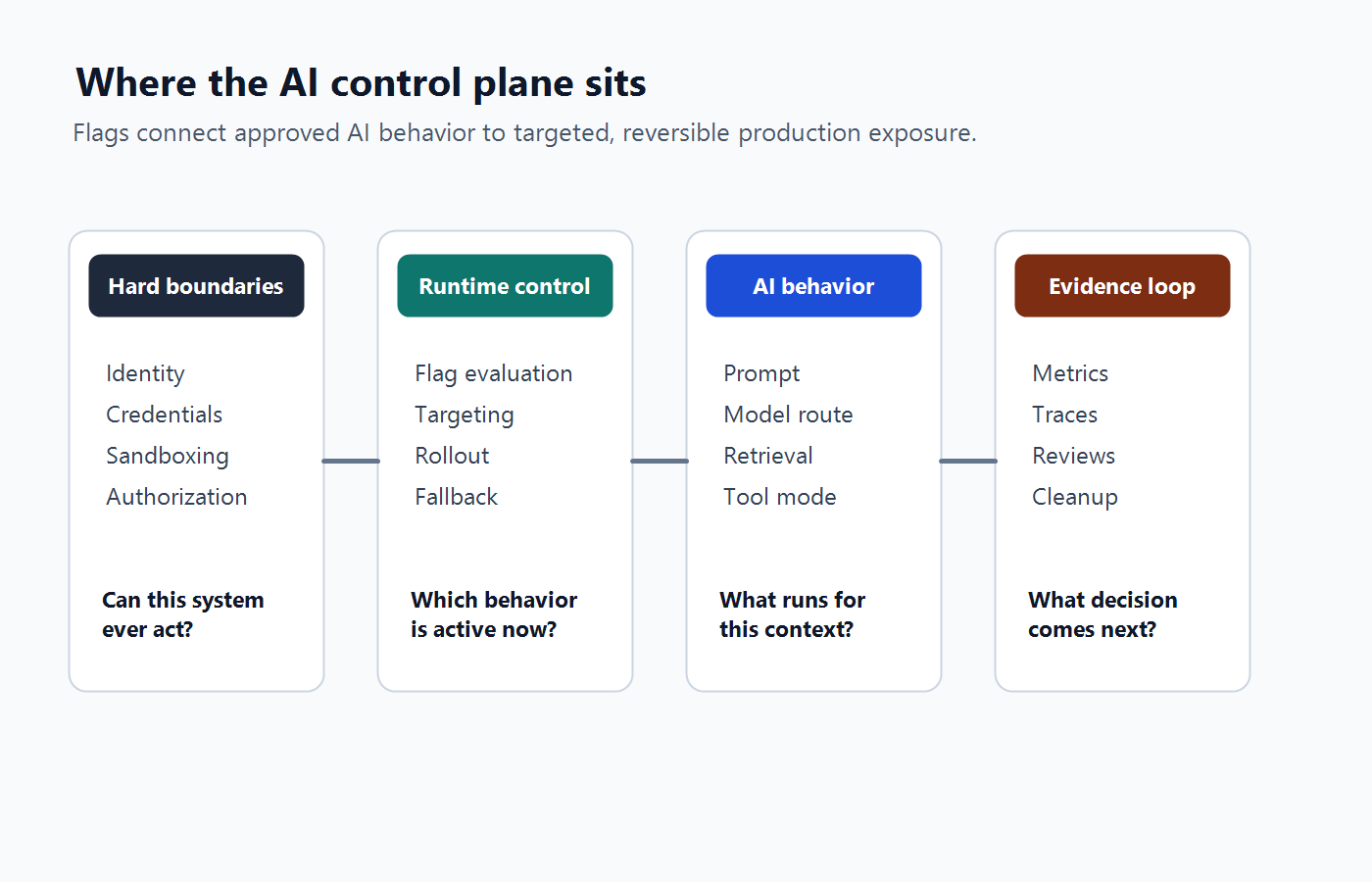
Use this four-layer model when evaluating a platform:
| Layer | Job | Example question |
|---|---|---|
| Hard boundaries | Define what the system can ever reach. | Can this service identity call this API at all? |
| Runtime control | Decide which approved behavior is active now. | Should this tenant get the candidate prompt route today? |
| AI behavior | Execute the selected prompt, model, retrieval, tool, or fallback path. | Which model profile and tool mode runs for this context? |
| Evidence loop | Decide whether to expand, pause, roll back, or clean up. | Did the exposed variation improve the outcome without breaking guardrails? |
OpenFeature's specification uses evaluation context as the data provided to a flag evaluation. That concept matters for AI control planes because AI risk is contextual. The same prompt, model, or agent tool can be low risk for internal users and unacceptable for a regulated customer segment.
The AI surfaces worth controlling with flags
Not every AI setting deserves a flag. Create a flag when a decision needs targeted exposure, rollback, audit, experiment assignment, or production evidence.
| AI surface | Useful flag pattern | Buyer question |
|---|---|---|
| AI feature availability | Boolean flag with environment and segment targeting | Can we enable the AI behavior only for internal users, beta tenants, or one region first? |
| Prompt profile | String variation such as stable, candidate, or restricted |
Can we route a candidate prompt without redeploying the application? |
| Model route | String or JSON variation for model, timeout, budget, and fallback | Can we shift a small cohort to a new model route and roll back quickly? |
| Retrieval profile | Variation for corpus, index, memory scope, or region-specific data source | Can we prevent one segment from using a risky retrieval path? |
| Guardrail mode | Variation such as standard, strict, fallback_first, or incident |
Can we tighten behavior during a live issue without disabling everything? |
| Agent tool mode | Variation such as observe, read_only, draft, approval_required, or limited |
Can we release tool authority in stages instead of granting broad access? |
| Experiment exposure | Multivariate flag with stable assignment and event tracking | Can we compare AI behavior using real exposure evidence? |
| Lifecycle state | Flag type, owner, review date, cleanup rule, and decision record | Can we tell which AI controls are temporary and which are permanent policy? |
OWASP's LLM application guidance is useful risk context because it names issues such as prompt injection, sensitive information disclosure, excessive agency, and overreliance. A feature flag does not solve those risks by itself. It can limit exposure, reduce authority, activate fallback, or stop expansion while the underlying problem is handled.
Buyer checklist for a feature flag AI control plane
When vendors talk about AI runtime control, do not stop at the product label. Ask whether the control plane can support the operating model you actually need.

1. Can it model AI control surfaces beyond one global switch?
A single ai_enabled flag is useful as an emergency switch, but it is too coarse for day-to-day AI release control. AI systems usually need separate decisions for availability, prompt profile, model route, retrieval profile, guardrail mode, tool authority, rollout scope, and incident fallback.
The platform should support boolean, string, number, and JSON variations so the flag can represent real AI configuration, not only on or off state.
2. Can evaluation happen server-side before behavior runs?
For AI releases, the flag decision should usually happen on the server side before the AI behavior runs or before an agent crosses an execution boundary. The model should not decide its own rollout cohort, permission mode, or fallback path from a prompt.
Client-side evaluation can still be useful for UI exposure, but sensitive AI routing, model choice, retrieval scope, tool access, and incident fallback should be enforced in the backend, orchestration service, or tool router.
3. Can targeting use the context that changes AI risk?
AI control planes need more than user ID targeting. Evaluate whether the platform can target by:
- user, account, tenant, and organization;
- environment, region, and data boundary;
- plan, contract tier, beta group, or internal segment;
- workflow, agent, model profile, or feature area;
- risk level, approval state, incident state, or support status.
FeatBit's documentation for targeting rules, user segments, and percentage rollouts describes the feature flag primitives behind this kind of staged exposure.
4. Can evidence join back to the evaluated variation?
A control plane is weak if it changes behavior without preserving evidence. For AI releases, the application should be able to connect each evaluated variation to:
- prompt, model, retrieval, or agent mode used;
- user, tenant, environment, region, and rollout cohort;
- AI quality review, eval score, human correction, or unsafe output report;
- latency, error rate, token cost, and downstream support signal;
- experiment events or release-decision metrics;
- rollback, pause, or cleanup decision.
FeatBit's Track Insights API, flag insights, and OpenTelemetry integration are relevant implementation references for connecting feature flag decisions to measurement and operations.
5. Can audit and approval reconstruct the release decision?
Auditability is not only a change log. For AI release control, a useful audit trail should help the team answer:
- Who changed the AI behavior?
- Which environment and audience changed?
- Which variation was active before and after?
- Was there an approval or release ticket?
- What evidence justified expansion?
- What happened when the team rolled back or narrowed exposure?
FeatBit's audit log, IAM overview, RBAC, and webhooks are the product areas to review when audit and approval are part of the buying decision.
6. Can the platform manage AI flag lifecycle?
AI teams create many temporary controls: prompt flags, model route flags, retrieval flags, guardrail flags, denylist flags, fallback flags, experiment flags, and incident flags. Without lifecycle rules, the control plane becomes confusing.
Evaluate whether the platform and your repository workflow can express:
- flag owner;
- flag type;
- expected review window;
- release decision;
- cleanup condition;
- permanent operational-control status when the flag should stay.
FeatBit's feature flag lifecycle management guidance is useful here because an AI control plane is not only a launch mechanism. It is a release memory system that needs cleanup after the decision.
What feature flags should not replace
A credible control plane has boundaries. If a vendor implies feature flags replace all AI governance or security controls, slow down.

Feature flags should not replace:
- identity, scoped credentials, authorization, and token validation;
- sandboxing for high-risk tools or code execution;
- model and data governance;
- privacy, legal, compliance, or domain expert review;
- AI evals, red teaming, and safety testing;
- observability, incident response, and post-incident review;
- human accountability for consequential decisions.
They should connect those controls to production exposure. For example, an eval system may decide that a candidate prompt is eligible for a small canary. A feature flag decides who receives that candidate in production. Observability and product metrics decide whether the release expands, pauses, rolls back, or gets cleaned up.
A practical implementation shape
Start with a small contract instead of a large rules engine.
ai_control_plane_contract:
behavior: support_assistant_answer_route
owner: support_platform
default_variation: stable
variations:
stable: prompt_v3_model_a_retrieval_v1
candidate: prompt_v4_model_b_retrieval_v1
fallback: search_only_answer_flow
first_audience: internal_support_users
excluded_contexts:
- regulated_region
- account_under_legal_hold
guardrails:
- answer_quality_review_score
- escalation_rate
- unsafe_output_report_rate
- p95_latency
- cost_per_resolved_case
rollback_action: serve_fallback_variation
cleanup_rule: remove_candidate_branch_after_release_decision
This contract makes the release decision reviewable. It separates the AI implementation from the runtime control question: which behavior is active for this context, under which evidence, with which rollback path?
How FeatBit fits the control-plane evaluation
FeatBit's point of view is that feature flags are release-decision infrastructure. For AI systems, that means prompts, model routes, retrieval profiles, guardrail modes, agent tool authority, rollout scope, experiments, fallback states, and cleanup rules should be controllable as production release decisions.
A practical FeatBit evaluation should include:
- AI control layer for the category framing around AI decision points as runtime control surfaces;
- safe AI deployment for internal-first, canary, metric-gated rollout, rollback, and full release patterns;
- AI governance and risk control for governance, audit, and approval context;
- feature flag lifecycle management for ownership, review windows, evidence, and cleanup;
- self-hosted feature flags when the control plane needs private deployment, data ownership, and infrastructure control;
- FeatBit docs for targeting, audit logs, Track Insights, and OpenTelemetry.
This is also where FeatBit differs from a narrow prompt-management or eval-only product category. FeatBit is not an LLM judge and should not be evaluated as one. It is the runtime release-control layer that makes an approved AI behavior targetable, observable, reversible, and governable.
Questions to ask in a proof of concept
Run the proof of concept around one real AI behavior, not a demo toggle. Good candidates include a support-answer prompt, a model route for summarization, a retrieval profile, or an agent tool mode.
Ask these questions during the proof of concept:
| Question | Pass signal |
|---|---|
| Can the application evaluate the flag before the AI behavior runs? | The backend receives a typed variation and selects the prompt, model, retrieval, or tool mode before execution. |
| Can the team target a narrow first audience? | Internal users, one tenant, one region, or a small percentage can receive the candidate while others stay stable. |
| Can rollback happen without deployment? | Operators can return to stable or fallback behavior through a flag change. |
| Can evidence attach to the variation? | Metrics, traces, review records, or experiment events include the flag key and variation. |
| Can approval and audit be reviewed later? | The team can reconstruct who changed exposure, when, and why. |
| Can the temporary control be cleaned up? | The repository and flag platform preserve owner, decision, and cleanup expectations. |
If a product cannot pass those checks, it may still be a useful feature flag tool. It is not yet a complete AI control plane for production release decisions.
Source notes
- AI risk-management context: NIST's AI Risk Management Framework is used as voluntary risk-management context, not as a certification claim.
- AI application risk context: OWASP's Top 10 for Large Language Model Applications is used to explain why AI systems need runtime containment beside hard security controls.
- Flag evaluation terminology: OpenFeature's specification is used for the evaluation context concept.
- Category language context: LaunchDarkly's AgentControl documentation and public AI control pages show that vendors are using runtime control language around prompts, models, guardrails, and agent behavior. This article does not make performance, security, pricing, or ranking claims about competitors.
- FeatBit implementation references: FeatBit documentation for targeting rules, percentage rollouts, audit logs, Track Insights, webhooks, IAM, RBAC, and OpenTelemetry supports the implementation checks above.
Image and Open Graph notes
Use /images/blogs/feature-flag-ai-control-plane/cover.png as the Open Graph image. The body images support the architecture map, buyer checklist, and control-boundary sections. The same concepts are explained in crawlable text, so the article does not depend on images for the main answer.