Which Feature Flag Platform Supports AI Evals?
If you are asking which feature flag platform supports AI Evals, first define what you mean by support. Some platforms now publish native AI evaluation features, such as offline evals, online evals, prompt grading, or judge metrics. Other platforms support the operational workflow around AI evals: controlled exposure, stable assignment, product metrics, guardrails, rollback, audit history, and lifecycle cleanup.
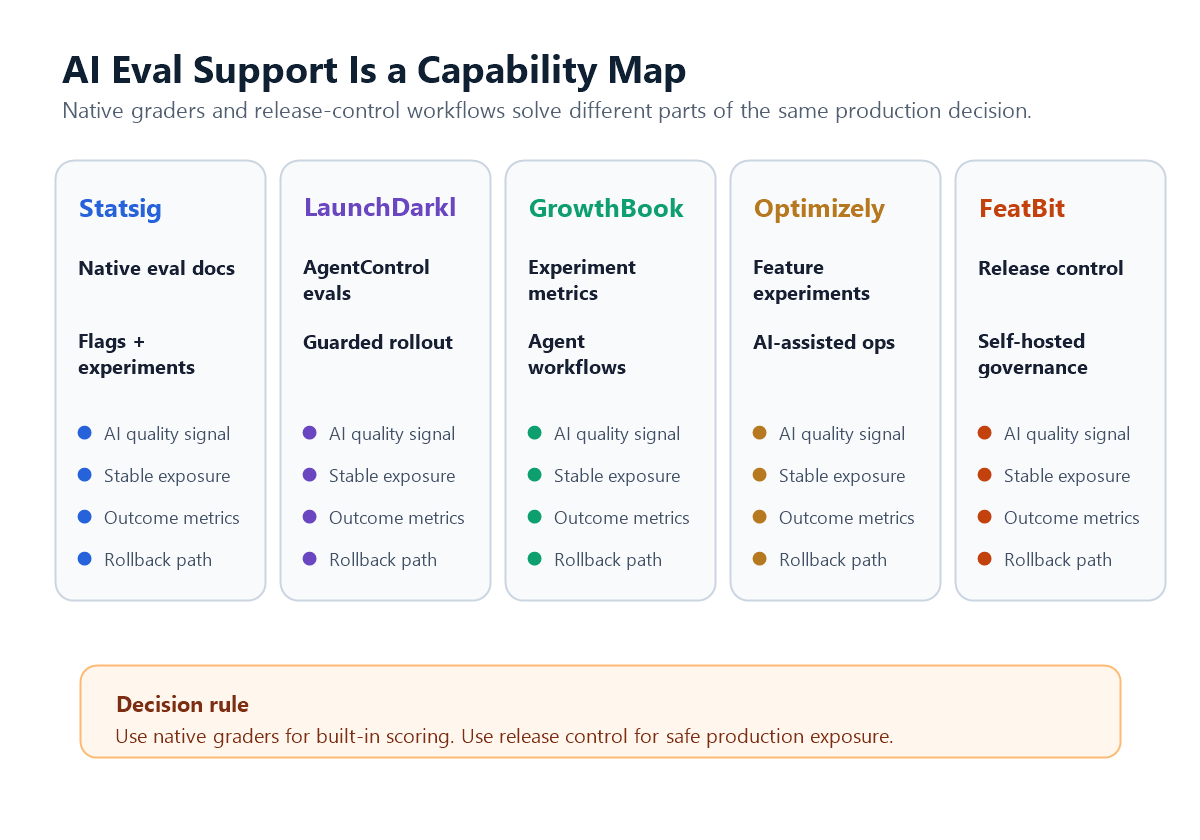
Based on public documentation checked on June 7, 2026, Statsig and LaunchDarkly publish the clearest native AI eval features inside their feature-management or AI-config ecosystems. GrowthBook and Optimizely publish strong feature flag and experimentation capabilities, plus AI-assisted workflows, but their public feature-experimentation pages are more focused on rollout, metrics, agents, and experiment operations than on native AI eval graders. FeatBit fits the release-control side: it helps teams evaluate AI changes through flags, experiments, telemetry, rollback, governance, and self-hosted control, while AI-specific graders or eval suites can sit beside it.
The Short Answer
Use this distinction when comparing platforms:
| What you need | Platform capability to verify |
|---|---|
| Native AI evals | Offline datasets, online grading, judges, rubric scores, prompt or model version tracking |
| Production exposure control | Feature flags, multivariate configs, targeting, percentage rollout, stable assignment |
| Business impact measurement | Experiment metrics, exposure events, outcome events, guardrails, segment analysis |
| Operational safety | Rollback, kill switches, audit logs, approval rules, environment separation |
| Governance and data control | Deployment model, retention controls, self-hosting, API access, lifecycle ownership |
That means the answer is not a single vendor name. If your requirement is "the feature flag platform itself must grade AI outputs," shortlist vendors with explicit AI eval documentation. If your requirement is "the platform must help us evaluate AI changes safely in production," include platforms that provide strong release control and experimentation even when the AI grader is external.
For the broader boundary between evals and release control, see FeatBit's guide to whether feature flags can replace AI evals. This article is narrower: it is a buyer checklist for the platform question.
What Counts as AI Eval Support?
AI eval support can mean several different jobs:
- Run an offline eval against a fixed dataset before users see a prompt, model, retrieval, or agent change.
- Run an online eval against production outputs using human labels, deterministic checks, or model-based judges.
- Compare prompt or model variations against quality metrics.
- Connect eval scores to rollout decisions, guarded rollouts, or experiments.
- Attribute business outcomes to the exact AI variation that ran.
- Preserve enough release memory to explain why the candidate expanded, paused, rolled back, or became default.
OpenAI's eval documentation describes evals as structured tests that use data sources and testing criteria to judge model outputs against expected behavior. That is the evaluation layer. A feature flag platform becomes relevant when the evaluated behavior needs production exposure, stable assignment, metrics, and rollback.
The practical buyer question is therefore:
Can this platform connect AI quality evidence to a reversible production release decision?
If the answer is only "it can show an eval score," the release workflow is incomplete. If the answer is only "it can roll out a flag," the quality workflow may still be incomplete.
Public Platform Signals to Check
The table below is intentionally conservative. It summarizes public documentation signals, not private roadmap claims, sales promises, or a ranking.
| Platform | Public signal for AI eval support | What to verify before buying |
|---|---|---|
| Statsig | Statsig documents AI Evals with prompts, offline evals, online evals, LLM-as-a-judge, Feature Gates, Experiments, and Analytics. The docs state AI Evals are in beta and no longer accepting new beta customers at the time checked. | Current availability, pricing, grader customization, data flow, production sampling cost, and how eval scores connect to rollout or experiment decisions. |
| LaunchDarkly | LaunchDarkly documents AgentControl online evaluations with built-in judges for accuracy, relevance, and toxicity, plus evaluation metrics usable in guarded rollouts and experiments for AgentControl configs. | Whether your AI workflow fits AgentControl completion mode or needs direct judge evaluation, where model-provider calls run, cost controls, data handling, and feature availability. |
| GrowthBook | GrowthBook documents feature flags, experiments, guardrail-triggered rollbacks, warehouse-native metrics, and agent-ready workflows through MCP and REST. Its public pages emphasize flags, experiments, product metrics, and agent operations rather than native AI output graders. | Whether you need native eval grading or can connect external eval results to GrowthBook metrics and experiments. Also verify warehouse access, metric definitions, and agent permissions. |
| Optimizely | Optimizely Feature Experimentation documents flags, experiments, metrics, scorecards, gradual rollout, rollback, AI-assisted experiment operations, and a Remote MCP Server for querying and managing experimentation workflows. | Whether native AI eval grading is required, how AI-specific quality labels enter metrics, and how feature experiments connect to your model, prompt, or agent telemetry. |
| FeatBit | FeatBit supports the release-control and experimentation workflow around AI evals: flags, targeting, percentage rollout, experiments, auditability, insights, APIs, OpenTelemetry integration, open source, and self-hosted deployment. | Use FeatBit when runtime control, self-hosting, governance, and measurable release decisions are the priority. Pair it with your eval framework when you need specialized graders or offline datasets. |
Native Graders Are Useful, But They Are Not the Whole Platform
Native AI eval features can reduce integration work. A platform that already understands prompt versions, model configs, judges, offline datasets, and online sampling can give AI teams a faster path from candidate behavior to quality signals.
That value is real, but it is not the whole release decision.
A prompt can score higher on an evaluator and still increase support escalations. A model route can improve relevance and break latency budgets. An agent tool policy can look successful in a task harness and still create a governance problem when exposed to a high-risk segment. A platform that supports AI evals should therefore be judged on the full decision loop:
- What behavior is being evaluated?
- Who receives the behavior?
- What quality signal is collected?
- What business outcome is measured?
- What guardrail can stop expansion?
- Who can change exposure?
- How quickly can the team roll back?
- What happens to the flag, prompt, model route, or experiment after the decision?
This is where feature flags become more than toggles. They are the control surface that turns an eval result into a production action.
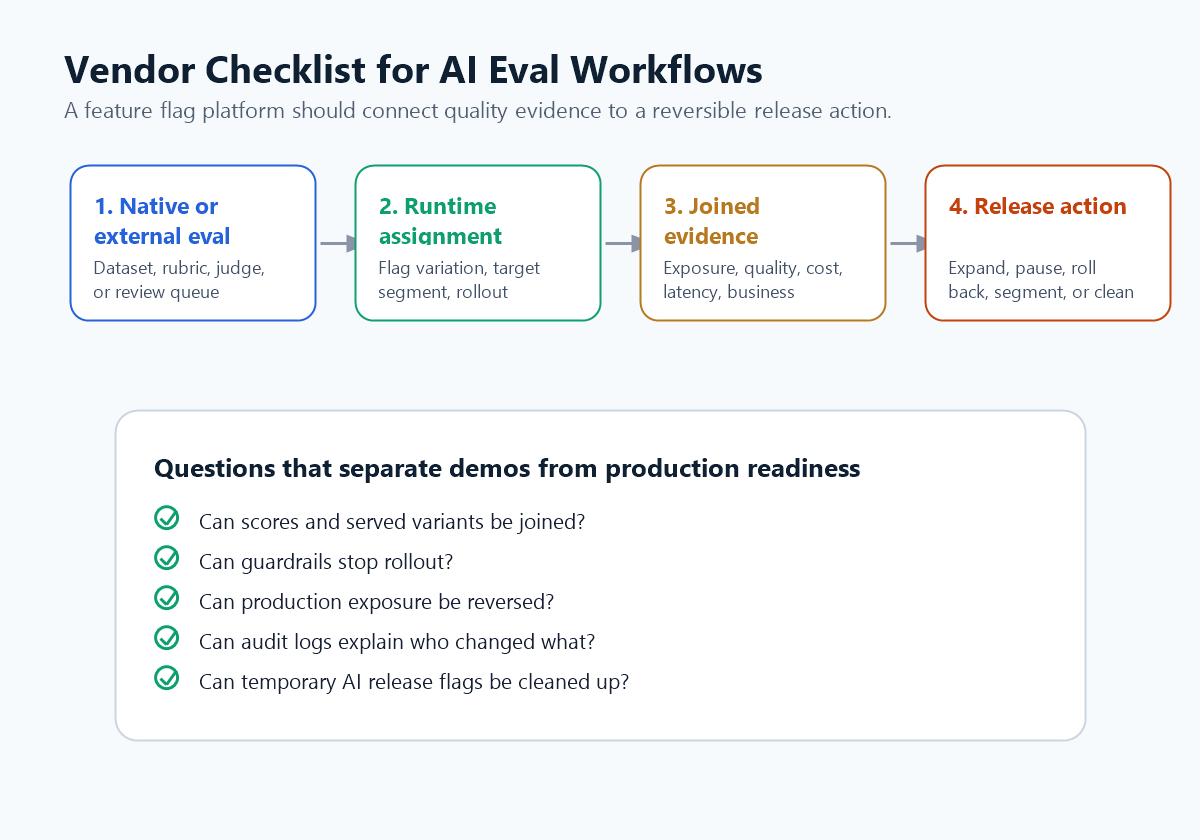
A FeatBit-Oriented Evaluation Workflow
FeatBit's angle is release-decision infrastructure. In an AI eval workflow, FeatBit is not the judge that decides whether an answer is grounded, accurate, helpful, or safe. It is the runtime control layer that decides who receives the evaluated behavior and how the release decision remains reversible.
A practical workflow looks like this:
-
Run an offline eval gate in your eval framework. The candidate prompt, model, retrieval profile, or agent strategy must clear the minimum quality bar before user-visible exposure.
-
Represent the candidate as a flag variation. Use a boolean, string, or multivariate flag to choose the AI behavior at runtime. Keep the baseline as the fallback.
-
Start with targeted exposure. Use internal users, beta customers, low-risk accounts, or a small percentage rollout before broader traffic sees the candidate.
-
Track exposure and outcomes. Attach the evaluated variation to telemetry, quality labels, cost, latency, task success, and business events. FeatBit's Track Insights API, flag insights, and experimentation documentation are relevant implementation paths.
-
Decide with primary metrics and guardrails. Use FeatBit's measurement design framing to separate the metric that decides the release from the guardrails that can stop expansion.
-
Preserve the decision and clean up. Temporary AI eval flags should not become permanent release debt. Use feature flag lifecycle management to define ownership, evidence, expected end state, and cleanup.
That workflow makes FeatBit useful even when the AI eval grader is OpenAI Evals, a custom rubric service, a human review queue, a model-observability tool, or an internal data platform.
What to Ask Vendors
Ask these questions before treating "AI Evals" as a checked box.
Evaluation Capabilities
- Does the platform support offline evals, online evals, or both?
- Can it compare prompts, models, retrieval profiles, tool policies, and agent strategies?
- Are graders deterministic, human-reviewed, model-graded, or configurable?
- Can teams inspect the rubric, score, reasoning, and sample context?
- Can severe failures block release before user exposure?
Release Control
- Can AI behavior be selected at runtime without redeploying?
- Can the platform target by user, account, environment, region, plan, workflow, or risk class?
- Does it support percentage rollout and stable assignment?
- Can operators roll back one AI behavior without disabling unrelated features?
- Are production changes audited and permissioned?
Experiment and Metric Design
- Can exposure events be joined to business outcomes?
- Can eval scores be used beside conversion, task success, support deflection, cost, latency, and error metrics?
- Does the platform support guardrails that pause, revert, or block expansion?
- Can the assignment unit be user, account, conversation, workflow, or request?
- Can the analysis explain when evidence is incomplete?
Operating Model
- Where do prompts, responses, eval scores, and model-provider calls live?
- Does the platform proxy model traffic or run inside your application context?
- How does sampling affect cost?
- Can the platform be self-hosted or integrated with private infrastructure if data control matters?
- Can AI assistants or MCP tools read or change the platform safely?
For implementation detail on the live-control object, read FeatBit's explainer on what an online eval flag is. For a broader platform checklist, read what to look for in a production AI experimentation platform.
When FeatBit Is a Good Fit
FeatBit is worth evaluating when your AI eval requirement is really a production release-control requirement:
- You already have or plan to build your own eval suite.
- You need open-source or self-hosted feature flag infrastructure.
- You want flags, targeting, experiments, audit history, APIs, and observability integration in one operating layer.
- You need to control prompts, models, retrieval paths, or agent modes without redeploying.
- You care about rollback, ownership, lifecycle cleanup, and release evidence as much as the eval score.
FeatBit should not be described as a native AI eval grader unless your team has integrated a grader through your application, telemetry, or experiment events. The stronger and more accurate claim is that FeatBit helps make AI eval results operational: it controls exposure, records the served variation, measures outcomes, supports rollback, and keeps the release decision visible.
FAQ
Which feature flag platform supports AI Evals?
If you mean native AI eval grading, Statsig and LaunchDarkly publish the clearest public AI eval documentation among the platforms reviewed here. If you mean production evaluation workflow, also compare FeatBit, GrowthBook, and Optimizely for rollout control, experiments, metrics, rollback, governance, and integrations.
Does FeatBit run AI eval graders?
FeatBit is best understood as the release-control and experimentation layer. It can route AI variants, target audiences, track events, support experiments, and help teams roll back or expand. Specialized AI grading can be handled by your eval framework and connected to FeatBit-controlled exposure.
Is a native AI eval feature required?
Not always. Native evals are useful when you want a single platform to manage prompt versions, graders, online sampling, and quality scores. They are less critical when your team already has an eval framework and needs a reliable feature flag platform to control exposure and measure production outcomes.
What is the most important platform requirement?
The most important requirement is joinability. The platform must connect the evaluated AI behavior, the exposure event, the user or account context, the quality signal, the business outcome, and the rollback action. Without that chain, eval support becomes a report rather than a release decision.
Source Notes
- Statsig documents AI Evals with prompts, offline evals, online evals, and LLM-as-a-judge, while noting beta availability limits: Statsig AI Evals overview.
- LaunchDarkly documents AgentControl online evaluations, built-in judges, sampling, monitoring metrics, and use of evaluation metrics in guarded rollouts and experiments: LaunchDarkly online evaluations.
- GrowthBook documents feature flags with guardrail-triggered rollbacks and AI-native agent workflows through MCP and REST: GrowthBook feature flags and GrowthBook AI-native development.
- Optimizely documents Feature Experimentation capabilities, scorecards, AI-assisted experiment workflows, and Remote MCP Server operations: Optimizely Feature Experimentation.
- OpenAI's eval documentation provides category context for data sources, testing criteria, and model-output evaluation: OpenAI Evals guide.
- FeatBit implementation context: experimentation documentation, Track Insights API, feature flag lifecycle management, and self-hosted feature flags.
Image and Open Graph Recommendation
Use /images/blogs/feature-flag-platforms-ai-evals/cover.png as the Open Graph image. The body diagrams should remain supporting visuals; the platform criteria, vendor caveats, and decision workflow are all present as crawlable text in the article.