What the Khan Academy AI Experiment Teaches About Evaluating AI Changes
Khan Academy's public AI experimentation story is useful because it avoids the fantasy that an AI product becomes safe or effective after one offline benchmark. Their work on Khanmigo, an AI tutor and teaching assistant, shows a more realistic path: start with intuition, add structured review, create automated evaluations, and then validate changes with production experiments.
That path matters for any team changing prompts, model versions, retrieval settings, agent tools, or AI user experiences. A model can look better in a lab and still make the product worse. A prompt can improve correctness while increasing latency. A tutor-style assistant can feel more helpful while reducing the behavior the product actually wants, such as independent problem solving.
This article turns the Khan Academy AI experiment example into a practical evaluation playbook for product, platform, and AI engineering teams. It is not a comparison of experimentation vendors. The useful lesson is the operating model: define the learning outcome, control the rollout, collect trustworthy evidence, and keep a rollback path open while the data is still uncertain.
Why this example matters
The search query "Khan Academy AI experiment" usually points to one question: what did Khan Academy learn about evaluating an AI tutor, and what can other teams copy?
GrowthBook's recap of Khan Academy's experimentation journey describes a progression from early GPT-4 access and manual prompt checks to production A/B testing for generative AI features. The recap highlights three hard problems that apply beyond education:
- AI output quality is not deterministic.
- Product metrics alone do not explain whether the AI is doing the right job.
- A trustworthy AI experiment needs both quality evaluation and business or user outcome measurement.
Khan Academy's own responsible AI materials make the same point from a risk perspective. They state that AI is not always accurate or entirely safe, and describe mitigation practices such as prompt engineering, monitoring, red teaming, user feedback, and ongoing evaluation.
For most teams, the takeaway is not "copy Khan Academy's metrics." A tutoring product has domain-specific goals. The reusable idea is to build an evaluation stack that can answer four questions before a wider release:
- Did the AI change improve the task it was supposed to improve?
- Did it harm any important guardrail?
- Did the result hold up on real users, not only curated examples?
- Can the team stop, roll back, or narrow exposure if the evidence changes?
The evaluation ladder behind the story
Khan Academy's journey is best understood as an evaluation ladder. Each level solves a weakness in the level before it.
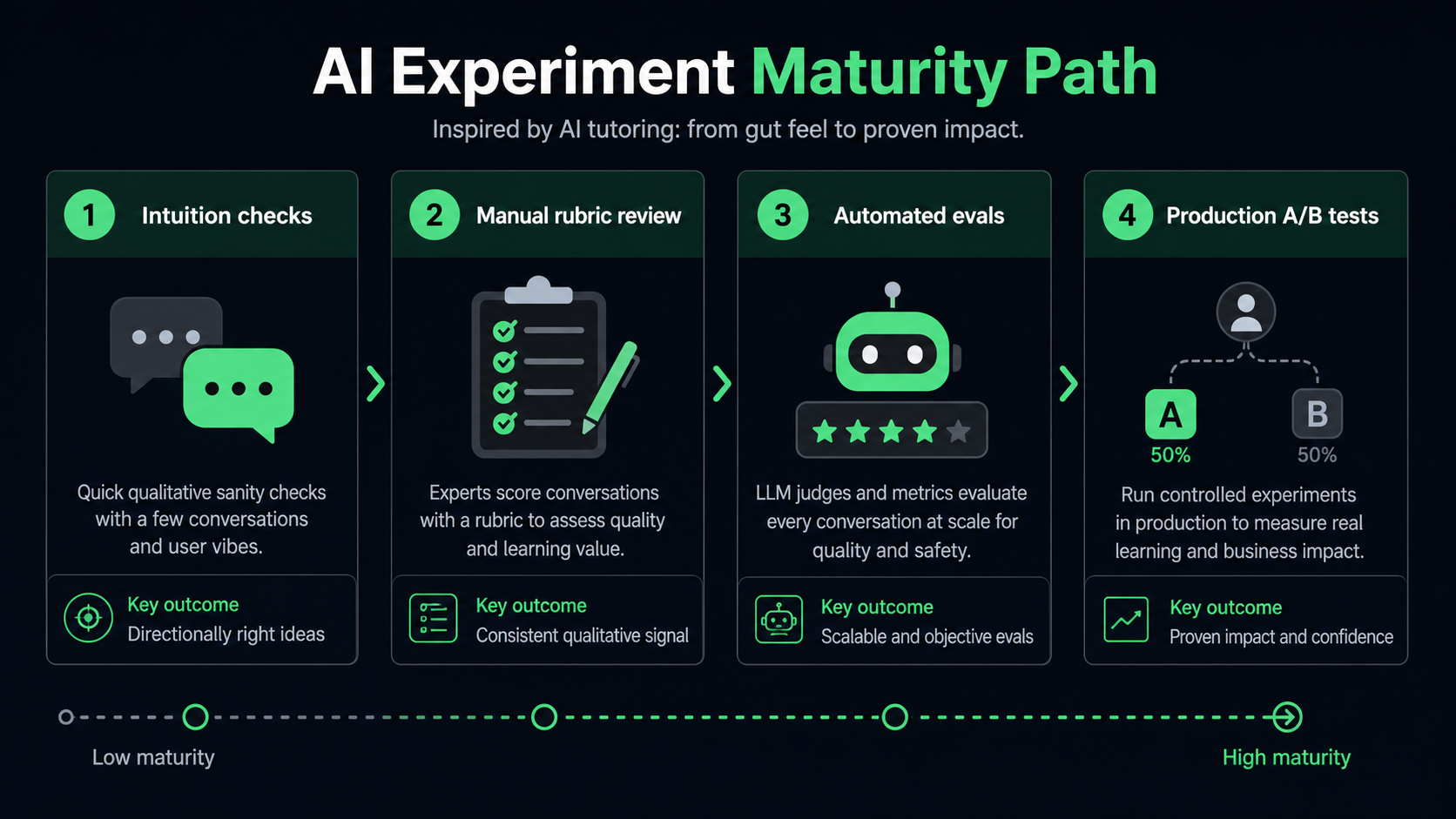
1. Intuition checks
Early AI work often starts with people trying prompts, reading outputs, and deciding whether the system feels promising. This is useful for discovery. It is not enough for launch decisions.
The failure mode is obvious: a few examples can hide systematic problems. For an AI tutor, one impressive answer does not prove the tutor will support learning across ages, subjects, skill levels, and problem types.
Use this stage to identify candidate behaviors, not to approve production exposure.
2. Structured manual review
The next step is a repeatable rubric. Instead of asking "does this look good?", reviewers judge outputs against explicit criteria.
For an AI tutoring flow, criteria might include:
- Does the assistant guide the learner instead of giving away the final answer?
- Does it detect a misconception?
- Does it keep the student engaged without drifting off topic?
- Does it avoid unsafe, inappropriate, or misleading content?
- Does it respond at a speed that keeps the experience usable?
This stage creates shared language. Product managers, subject experts, engineers, and risk reviewers can disagree against a rubric instead of trading opinions.
3. Automated evals
Manual review does not scale to every prompt, model release, retrieval change, or production transcript. Automated evaluations help teams run checks more often, compare variants faster, and catch regressions before wider exposure.
OpenAI's evaluation guidance recommends defining the evaluation objective, collecting datasets, defining metrics, running comparisons, and continuously evaluating as the application changes. That pattern is broadly useful even when the model provider, eval harness, or judge model differs.
The important warning is that automated evals need calibration. If an LLM-as-judge is used, it should be compared against human labels or domain-expert judgments. Otherwise, the team may only be measuring what the judge model prefers, not what users or experts need.
4. Production experiments
Offline evals reduce risk, but they cannot fully answer whether an AI change improves the product. Real users bring different tasks, incentives, environments, and failure modes.
A production experiment connects the AI variant to outcome metrics. For a tutor, that might include learning progress, return usage, student persistence, or teacher adoption. For another AI product, it might be task completion, support deflection, conversion, retention, escalation rate, or successful human handoff.
This is where feature flags become more than release switches. They become the control plane for who sees the AI change, what variant they receive, how quickly exposure expands, and how fast the team can stop the experiment.
What AI teams should measure before shipping
AI experiments fail when they only measure one attractive metric. The Khan Academy example is useful because it points toward a multi-metric decision, not a single score.

A practical AI experiment should include one primary success metric and several guardrails.
Primary metric
The primary metric should match the user job. It should not merely measure whether users clicked the AI feature.
Examples:
- An AI tutor: increase successful independent problem solving.
- A support assistant: increase resolved cases without reopening tickets.
- A coding assistant: increase accepted changes that pass tests.
- A sales assistant: increase qualified next-step completion, not just generated emails.
If the team cannot define the outcome, the experiment is not ready. A vague metric creates a vague decision.
Quality metrics
AI quality metrics should describe the behavior the system must produce. For generative AI, useful quality measures often combine automated checks, expert review, and user feedback.
Examples:
- Correctness or factual consistency.
- Helpfulness for the intended task.
- Grounding against approved content.
- Instruction following.
- Tone and clarity.
- Rubric score from expert reviewers.
- Pairwise preference against the current production behavior.
Do not rely on a single quality number when the product has multiple dimensions of value. A model can be more concise and less accurate. A tutor can be more encouraging and less educational. A support assistant can be faster and less complete.
Guardrail metrics
Guardrails define what must not get worse while the primary metric improves.
Common AI guardrails include:
- Latency and timeout rate.
- Cost per successful task.
- Safety moderation triggers.
- Escalation to a human.
- User complaint rate.
- Sensitive data exposure risk.
- Hallucination or unsupported-answer rate.
- Drop-off during critical flows.
NIST's AI Risk Management Framework describes risk management as part of the design, development, use, and evaluation of AI systems. In product terms, guardrails are how that idea becomes operational during rollout.
Segment analysis
An AI change can help one cohort and hurt another. That matters when the user population is diverse.
For an education product, segment analysis could include age range, subject, proficiency level, district context, language setting, or teacher versus student workflow. For a SaaS product, it might include plan, role, account size, region, data sensitivity, or workflow complexity.
The experiment plan should define important segments before launch. If segmentation is invented only after results arrive, it is too easy to overfit the story.
Turn the lesson into an experiment design
Here is a practical design template for teams evaluating a prompt, model, retrieval, or agent workflow change.
Hypothesis
Write the hypothesis in product language.
Weak:
GPT-5 should perform better than the current model.
Stronger:
The new tutoring prompt will increase successful first-attempt problem solving for algebra learners without increasing direct-answer leakage, latency, or moderation events.
The stronger version defines the user, the expected improvement, and the guardrails.
Variants
Keep variants understandable. If a variant changes the model, prompt, retrieval, temperature, and UI at once, the team may learn that "B won" without knowing why.
Useful variants include:
- Current production prompt versus revised prompt.
- Current model versus new model with the same prompt.
- Current retrieval strategy versus reranked retrieval.
- AI answer-first flow versus hint-first flow.
- Agent workflow with one tool set versus a narrower tool set.
Use a feature flag or experiment flag to assign users consistently. The same user should not bounce between variants unless the experiment intentionally tests session-level randomization.
Exposure
Start with the smallest exposure that can answer the current risk question.
For a high-risk AI change, the first production exposure might be internal users, staff accounts, beta customers, or a narrow account segment. For a lower-risk copy or summarization change, the first exposure can be larger.
The key is to separate three decisions:
- Is the variant technically working?
- Is it safe enough for limited external exposure?
- Is it good enough to expand?
Each decision can use a different evidence threshold.
Instrumentation
Before launch, make sure every exposure can be joined to downstream events.
For each AI interaction, capture:
- Flag key and variant.
- User or account identifier, according to the product's privacy model.
- Prompt or configuration version.
- Model or provider version when available.
- Retrieval or tool configuration when relevant.
- Latency, error, timeout, and fallback state.
- User feedback or task outcome events.
- Safety or moderation events when relevant.
OpenFeature's specification defines detailed flag evaluation fields such as flag key, value, variant, reason, and error handling behavior. Those details are useful because experiment analysis depends on knowing which variant a user actually received.
Decision rules
Define the decision before the experiment starts.
Good decision rules sound like this:
- Ship if the primary metric improves and no guardrail crosses its threshold.
- Hold if the primary metric is neutral but quality review shows meaningful improvement for a strategic segment.
- Roll back if latency, safety triggers, or complaint rate crosses the stop threshold.
- Split the rollout if one segment improves and another segment regresses.
Bad decision rules sound like this:
- Ship if the demo looks better.
- Ship if one metric improves.
- Keep testing until the result looks positive.
- Ask leadership after the data comes in.
AI systems need pre-registered decision rules because their results are often ambiguous. A change may improve quality while increasing cost. It may help experts and hurt beginners. It may improve short-term engagement while weakening the outcome the product exists to create.
Where feature flags fit
FeatBit's view of AI experimentation is simple: the release control and the measurement control should be connected. The flag that routes users to a model, prompt, retrieval strategy, or agent workflow should also provide the exposure record needed for analysis.
That gives teams a clean operating loop:
- Register the AI variant as a flag value.
- Target internal users, beta cohorts, or a small percentage of traffic.
- Record exposure and outcome events.
- Watch quality, latency, safety, and cost guardrails.
- Expand, pause, roll back, or split by segment.
This is the same operating model behind experimentation for AI systems, AI release engineering, and LLM canary releases. For prompt-specific workflows, connect the experiment to AI prompt versioning so the team can explain exactly which prompt version was evaluated.
For self-hosted teams, this connection matters even more. AI interactions can contain sensitive context, and some organizations cannot send raw event streams or user attributes through a third-party experimentation service. A self-hosted feature flag and experimentation stack lets the organization keep rollout control and data ownership closer to its own infrastructure.
That does not remove the need for careful privacy design. It means the team can decide which attributes are needed for targeting and analysis, which events should be aggregated, and which raw fields should never leave the application boundary.
A practical launch checklist
Use this checklist before expanding an AI experiment beyond a narrow cohort.
Evaluation readiness
- The hypothesis names the user, AI change, primary outcome, and guardrails.
- The offline eval set includes typical cases, edge cases, and known failure modes.
- Expert or human review has calibrated any automated judge.
- The team knows which metric is primary and which metrics are guardrails.
- The experiment can detect regressions by important segment.
Release readiness
- The AI change is behind a feature flag.
- The flag has a default value that preserves the current production behavior.
- The rollout can target internal, beta, account, percentage, and emergency-off cohorts.
- The team has a rollback owner and stop threshold.
- The flag key, variant, and configuration version are recorded with events.
Product readiness
- The user experience explains AI limitations where users need that context.
- The system has a human handoff or fallback path for important failures.
- The launch plan accounts for latency, cost, and provider instability.
- The team has a review process for user feedback and unexpected behavior.
- The experiment decision can be made without relying on a single anecdote.
The Khan Academy AI experiment story is valuable because it shows that AI quality is not a one-time approval gate. It is a loop. The teams that build this loop can move faster because they are not guessing in production. They are controlling exposure, measuring real outcomes, and keeping the ability to reverse course.
Source notes
- GrowthBook's recap, How Khan Academy optimizes AI tutoring with experimentation, is used as the source for the described evaluation maturity path and the Khanmigo experimentation context.
- GrowthBook's Khan Academy customer page, Khan Academy's Path to Customized Experimentation, is used for the public description of Khan Academy's experimentation and privacy requirements.
- Khan Academy's help center article, What is Khan Academy's approach to responsible AI development?, is used for responsible AI context and risk-mitigation examples.
- NIST's AI Risk Management Framework is used as a source for the importance of risk management in AI design, development, use, and evaluation.
- OpenAI's evaluation best practices are used for the general eval workflow: objectives, datasets, metrics, comparisons, and continuous evaluation.
- OpenFeature's flag evaluation specification is used for the flag evaluation details that support trustworthy exposure logging.
Image and Open Graph recommendations
- Use
/images/blogs/khan-academy-ai-experiment/cover.pngas the Open Graph image for this article. - Use
/images/blogs/khan-academy-ai-experiment/evaluation-maturity.pngnear the evaluation ladder section to make the maturity path understandable in search and AI summaries. - Use
/images/blogs/khan-academy-ai-experiment/ai-experiment-decision-matrix.pngnear the metrics section to make the primary metric and guardrail model easy to scan.