AI Output Quality Guardrails: A Control Plane for Safer AI Releases
An AI output quality guardrail is the control system that decides whether a generated answer, summary, recommendation, classification, or response is allowed to reach a user, needs human approval, should fall back to a safer path, or should be rolled back for a specific audience.
The useful buying question is not "do we have a content filter?" A production AI team needs to know which output quality signals are checked, where the decision happens, who can override it, what evidence is recorded, and how a risky output path can be narrowed without redeploying the application.
FeatBit's angle is that output quality should be governed like a release decision. Offline evals, judges, classifiers, policy checks, and human review provide signals. Runtime flags decide which behavior is active for each user, account, environment, region, plan, rollout stage, and risk class.
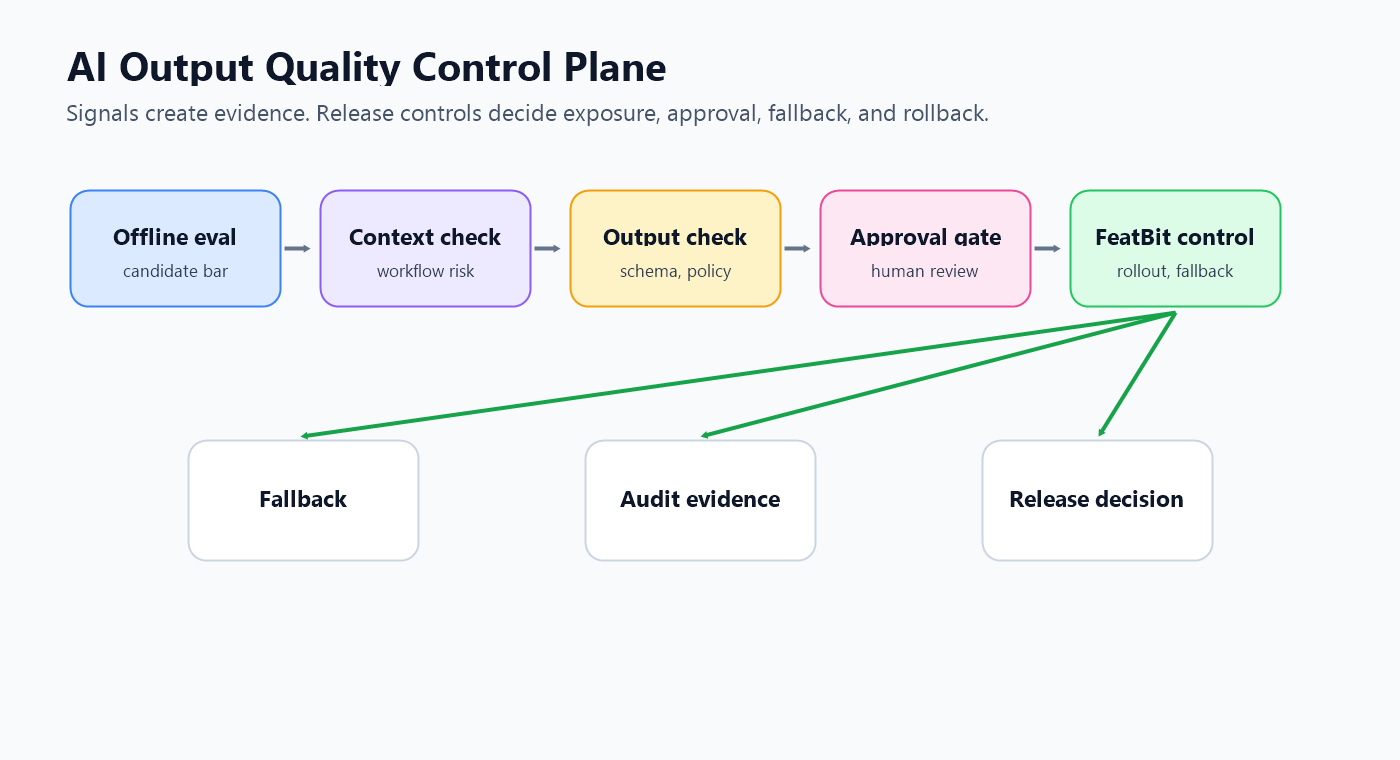
What An Output Quality Guardrail Must Decide
Output quality is broader than "the model produced safe text." A generated output can be fluent and still be wrong for the product, risky for the account, too expensive to serve broadly, missing required citations, or inappropriate for a regulated workflow.
Start by separating four decisions:
| Decision | Question | Example outcome |
|---|---|---|
| Quality | Is this output good enough for the current workflow? | Publish, revise, queue for review, or reject |
| Risk | Is this output allowed for this audience and context? | Allow for internal users, require approval for enterprise accounts, exclude a region |
| Release | Should this output path expand to more traffic? | Continue canary, pause, roll back, or start an A/B test |
| Evidence | Can the team explain what happened later? | Store variation, judge result, reviewer, fallback reason, and rollout state |
This is where many guardrail programs become too narrow. A classifier might catch a policy violation, but it does not answer who should see the new prompt version. An eval score might approve a candidate before launch, but it does not decide whether a live rollout should expand. A human approval queue might stop a bad output, but it does not give operators a fast way to roll back the output route for one segment.
NIST's AI Risk Management Framework is useful context because it treats AI risk management as work across design, development, use, and evaluation of AI systems, and it is voluntary rather than a certification claim. The practical lesson for product teams is continuous control: a guardrail should change the release path when quality evidence is weak.
Build A Guardrail Stack, Not One Gate
No single check should carry the whole quality decision. Use a stack that matches the moment in the release path.
| Layer | When it runs | What it catches | Runtime action |
|---|---|---|---|
| Offline eval gate | Before exposure | Known regressions, schema failures, protected cases, severe quality failures | Keep candidate at zero exposure |
| Input and context checks | Before generation | unsupported workflow, missing context, sensitive field, risk tier | route to safe mode or require approval |
| Output validation | Before user display | malformed JSON, missing citation, policy violation, unsafe instruction, low confidence | repair, fallback, or hold |
| Online quality signal | After exposure | correction rate, user rejection, human edit rate, complaint, support escalation | pause or reduce rollout |
| Release review | At expansion points | whether evidence justifies a wider audience | continue, expand, roll back, or clean up |
The OpenAI Agents SDK documentation describes input guardrails and output guardrails as checks that can run around agent execution. That pattern is portable: place checks at the boundary where the system still has time to stop, repair, or route the output before harm spreads.
OWASP's 2025 Top 10 for LLM and Gen AI applications is also relevant, especially categories such as improper output handling, sensitive information disclosure, misinformation, and unbounded consumption. Treat those as risk prompts, not as a complete product-quality model. A support answer can avoid security issues and still fail because it is unhelpful, outdated, too slow, too expensive, or missing the citation a customer expects.
The Release Control Contract
Before a new output path reaches production, write the guardrail as a release contract. The contract should be short enough for a pull request or release ticket, but specific enough for product, engineering, security, support, and compliance reviewers to understand.
ai_output_quality_guardrail:
behavior: "support_answer_prompt_v4"
owner: "support-platform"
default_variation: "stable_answer"
candidate_variation: "quality_guarded_answer"
first_audience: "internal_support"
eligible_next_stage: "five_percent_canary"
output_checks:
- "schema_valid"
- "required_citations_present"
- "no_sensitive_field_leak"
- "answer_quality_judge_passed"
approval_required_when:
- "enterprise_account"
- "billing_or_security_topic"
- "judge_confidence_low"
fallback:
default: "stable_answer"
missing_context: "search_only_answer"
policy_violation: "human_handoff"
audit_fields:
- "flag_key"
- "variation"
- "guardrail_result"
- "fallback_reason"
- "reviewer"
- "release_decision"
cleanup_rule: "remove candidate path after full release and two healthy review windows"
The fields can change by product. The discipline matters more than the exact names. A reviewer should be able to trace each line to a runtime flag, output validator, telemetry event, approval path, fallback path, or cleanup decision.
For FeatBit, the flag should select the named output route or mode. Keep secrets, raw prompts, large policy documents, and sensitive user data outside the flag value. The application evaluates the flag server-side, runs the AI behavior, checks output quality, records evidence, and falls back when the contract says the output is not ready.
Use Guardrail Modes Instead Of A Global Switch
A global "AI on" switch is useful during emergencies, but output quality usually needs smaller controls. Different audiences and workflows need different answers.
| Mode | What happens | Best use |
|---|---|---|
off |
Serve the stable non-AI or previous AI path | default for unapproved behavior |
observe |
Generate internally, do not show to users | dry runs and shadow testing |
draft_only |
Show output to staff as a draft | internal support or operations workflows |
approval_required |
Queue output before user-visible delivery | high-value accounts, sensitive topics, low confidence |
guarded_release |
Show output if checks pass, fallback if not | narrow canary or beta rollout |
full |
Make the candidate the default for the eligible audience | after guardrails and outcomes are stable |
fallback |
Force stable answer, search-only answer, or human handoff | incident response or failed guardrail |
Model this as a multivariate flag or a JSON variation when the route needs several fields. For example, a route might include prompt version, retrieval profile, output validator profile, fallback profile, and approval mode. The important point is visibility: release owners should be able to see which mode is active, who changed it, and which audience receives it.

Decide Where Human Approval Belongs
Human approval is expensive. Use it where judgment changes the outcome, not as a blanket ritual for every generated response.
Approval usually belongs when:
- the output creates or recommends a customer-visible action;
- the answer touches billing, security, legal, medical, financial, or regulated topics;
- the output will be sent to a high-value or high-risk account;
- the judge score is uncertain or conflicting;
- the supporting sources are missing, stale, or low confidence;
- the rollout is entering a new segment, region, or plan tier;
- the team is still learning what the guardrail misses.
Do not make approval the only guardrail. A good approval path should sit beside targeting, fallback, telemetry, audit logs, and rollback. Otherwise the team stops one output at a time while the risky route remains active for the next request.
| Output risk | Example | Default control | Approval rule | Fallback |
|---|---|---|---|---|
| Low | UI copy suggestion, internal summary | guarded release | sampled review | stable answer |
| Medium | support answer, onboarding recommendation | canary plus output checks | low confidence or protected topic | search-only answer |
| High | billing, security, account access, contract wording | approval required | before user delivery | human handoff |
| Restricted | legal, regulated, financial, safety-critical, irreversible impact | off or separate policy review | named human owner | do not generate |
This table is intentionally conservative. FeatBit does not replace legal, privacy, security, or domain review. It gives teams a release-control layer for approved AI behavior: target narrowly, require review where needed, record evidence, and roll back quickly.
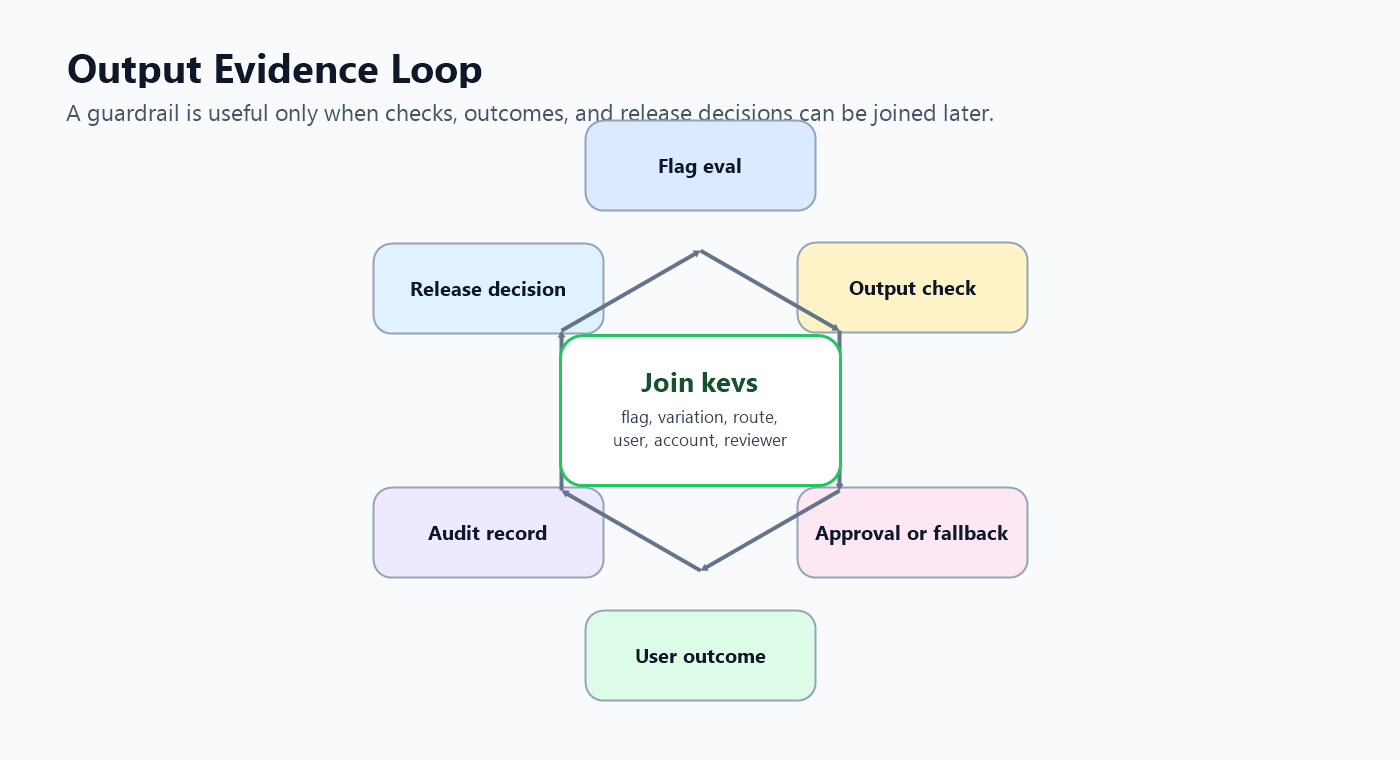
Connect Output Evidence To Release Decisions
A quality guardrail is weak if its evidence cannot be joined later. Record the evaluated flag variation beside the output result, judge result, approval decision, and user outcome.
Minimum event fields:
| Field | Why it matters |
|---|---|
flagKey and variation |
Connects output behavior to release state |
promptVersion or routeName |
Prevents prompt drift from being mistaken for quality change |
userId, accountId, or conversationId |
Joins exposure, outcome, and reviewer evidence |
riskClass and workflow |
Explains why approval or fallback was required |
guardrailResult |
Shows pass, repair, approval required, fallback, or reject |
fallbackReason |
Makes safe degradation observable |
reviewer and approvalOutcome |
Supports accountability for human-gated outputs |
outcomeMetric |
Connects quality to product impact |
FeatBit's Track Insights API can record feature flag usage events and custom metric events. FeatBit audit logs, webhooks, and OpenTelemetry integration help connect control-plane changes with runtime evidence.
The release decision should stay simple:
- continue the current rollout;
- expand to a wider segment;
- narrow to a safer audience;
- switch to approval-required mode;
- roll back to the stable output route;
- keep the guardrail as a permanent operational control;
- clean up the temporary flag and candidate path.
How FeatBit Fits The Architecture
FeatBit should sit in the release-control layer, not inside the model as another prompt instruction.
A practical architecture looks like this:
- CI and offline evals block candidates that fail the pre-exposure bar.
- The application deploys the candidate path behind a FeatBit flag with the stable route as default.
- Server-side flag evaluation selects
off,observe,draft_only,approval_required,guarded_release,full, orfallbackfor the current context. - The AI service generates the output only within the selected route and allowed context.
- Output validators, judges, schema checks, and policy checks run before user display.
- The application falls back or queues approval when a guardrail fails.
- Exposure, guardrail, approval, fallback, and outcome events are recorded.
- The release owner uses evidence to expand, pause, roll back, or clean up.
FeatBit's targeting rules, percentage rollouts, flag insights, and feature flag lifecycle management support this operating model. For the broader category context, see FeatBit's AI control layer, safe AI deployment, and AI governance and risk control pages.
This article is distinct from broader AI governance guidance. The reader job here is narrower: build or evaluate the control plane that governs output quality at the moment an AI response is about to reach a user.
Buyer Checklist For AI Output Quality Guardrails
If you are evaluating a guardrail workflow, ask:
- Can the system keep a candidate output route at zero exposure until the release owner starts rollout?
- Can output modes vary by user, account, environment, region, plan, workflow, and risk class?
- Can guardrail checks run before user-visible delivery?
- Can a failed output check trigger fallback instead of only logging an alert?
- Can human approval be required only for higher-risk contexts?
- Can operators reduce rollout, switch modes, or roll back without redeploying?
- Can evaluated variation, guardrail result, reviewer, fallback reason, and outcome metric be joined later?
- Can audit logs show who changed the output route and when?
- Can temporary guardrail flags be cleaned up after the release decision?
- Does the workflow distinguish governance evidence from legal or compliance certification?
If the answer is mostly no, the team may have AI quality checks, but it does not yet have AI output quality guardrails as an operating system.
Common Mistakes
Treating a content filter as the whole guardrail. Output safety is necessary, but product quality also includes correctness, usefulness, citation quality, cost, latency, escalation, and business outcome.
Letting the model decide its own authority. The model can provide a confidence signal. The application should enforce approval, fallback, and release controls.
Approving one output while the risky route stays live. Approval handles individual exceptions. Runtime rollout controls handle the route that produced them.
Recording eval scores without release context. A score is more useful when it is tied to a flag, variation, audience, rollout stage, and decision.
Never cleaning up temporary guardrails. After a route is accepted or rejected, remove stale candidate paths or document why the guardrail is now a permanent operational control.
Source Notes And Internal Link Plan
- Standards and security context: NIST's AI Risk Management Framework is used as voluntary risk-management context. OWASP's 2025 Top 10 for LLM and Gen AI applications is used for application risk categories including improper output handling, sensitive information disclosure, misinformation, and unbounded consumption.
- Guardrail pattern context: OpenAI's Agents SDK guardrails documentation is used for the general input and output guardrail pattern. This article does not depend on a specific model provider.
- FeatBit implementation sources: targeting rules, percentage rollouts, flag insights, audit logs, Track Insights API, webhooks, OpenTelemetry integration, and feature flag lifecycle management.
- FeatBit reader journey links: AI control layer, safe AI deployment, AI governance and risk control, feature flag lifecycle management, and offline eval gate launch blocking.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it frames output quality guardrails as a release-control system, not a decorative AI concept. - Use
output-quality-control-plane.pngnear the opening because it shows how checks, approvals, fallback, audit, and rollback connect. - Use
guardrail-mode-ladder.pngin the mode section because it makes the difference between off, observe, approval, guarded release, full release, and fallback visible. - Use
output-evidence-loop.pngin the evidence section because it shows how output checks become release decisions.
Next Step
Pick one AI output path that is close to production, such as a support answer, account summary, recommendation, or generated reply. Write the release contract before rollout: owner, default route, candidate route, first audience, output checks, approval triggers, fallback modes, audit fields, and cleanup rule. Then keep the candidate behind controlled FeatBit exposure until the evidence justifies expansion.