What to Look for in a Production AI Experimentation Platform
AI teams rarely fail because they cannot create another prompt, model route, retrieval setting, or agent workflow. They fail because they cannot prove which change should stay in production.
A production AI experimentation platform is the control layer that lets a team expose an AI change to the right users, measure quality and business impact, watch guardrails, and roll back without another deployment. It is not just an offline eval dashboard. It is also not just a feature flag tool with an experiment chart attached. For AI systems, the platform has to connect release control, evaluation, telemetry, and decision-making.
This guide is for engineering, platform, and product teams evaluating whether to buy, build, or extend a production AI experimentation platform. The useful question is not "does it run experiments?" The useful question is "can it help us decide whether an AI change is good enough to keep serving?"
Start with the production decision
Before comparing platforms, name the decision the platform must support. Most AI experiment decisions fit one of five patterns:
| Decision | Example | Platform requirement |
|---|---|---|
| Ship | Replace a prompt for all users | Evidence that quality, business metrics, and guardrails improved or stayed acceptable |
| Hold | Keep the current AI behavior | A clear reason the candidate did not beat the control |
| Roll back | Disable a harmful variant | A runtime switch that works without deploys |
| Segment | Serve the variant only to a safer audience | Targeting by user, account, region, plan, or risk group |
| Iterate | Keep testing offline or in shadow mode | Traceable results that explain what failed |
If a tool only produces a score, your team still has to translate that score into a production action. A strong platform makes the action visible: keep the control, expand rollout, narrow exposure, or stop the variant.
The core capabilities to require
1. Runtime control over AI behavior
AI changes are often configuration changes: prompt text, model choice, temperature, retrieval strategy, tool access, ranking logic, or an agent policy. The platform should let operators change those variants at runtime, target them to a specific audience, and stop them quickly.
This is why feature flags matter. Feature flags let teams release code separately from exposure. In FeatBit, that same release-control layer can be used for AI changes that need staged rollout, rollback, and environment isolation. FeatBit's AI-native page frames this as extending open-source feature flags into release control for AI-native delivery.
When evaluating a platform, check whether AI variants are first-class release units or just labels in a chart. A production-ready setup should support:
- Boolean and multivariate variants.
- Percentage rollout.
- Targeting rules.
- Kill switches.
- Environment separation.
- Audit history for flag and configuration changes.
- SDK evaluation on the server side when the AI decision affects backend behavior.
The details matter because the platform becomes part of your production control plane. If the AI variant cannot be disabled quickly, the experiment is not production-safe.
2. Exposure events tied to the exact served variant
An experiment is only trustworthy if the platform knows which user, account, session, or request received which variant. For AI systems, that exposure record should include enough context to connect later outcomes back to the served behavior.
A minimal exposure contract looks like this:
{
"experimentKey": "support-summary-prompt",
"unitId": "account_123",
"requestId": "req_789",
"variant": "prompt_v2_retrieval_on",
"model": "model-family-or-route",
"timestamp": "2026-06-04T10:30:00Z"
}
The platform should not force every team to use the same unit. A support workflow may randomize by account. A checkout assistant may randomize by user. A developer assistant may randomize by workspace. The unit has to match the business decision and avoid mixing variants inside the same meaningful experience.
3. Evaluation signals for output quality
AI output quality is not always visible in business metrics right away. A new support summarizer can look faster but omit critical details. A new recommendation agent can increase clicks while hurting trust. A new retrieval strategy can reduce latency while increasing unsupported answers.
The platform should let teams attach AI-specific quality signals such as:
- Human review labels.
- Task success or failure.
- Ground-truth comparison for known-answer tasks.
- Rule-based checks for required fields or forbidden output.
- LLM-as-judge scores with explicit rubrics.
- Retrieval quality signals, such as source coverage or citation validity.
OpenAI's evaluation guidance emphasizes designing evals around the behavior you expect from the application and using appropriate data sources, including production and historical data when relevant. Statsig's AI Evals documentation also separates offline evals from online evals, which is a useful distinction for production teams: offline tests catch regressions before exposure, while online evals observe real production behavior.
The important platform requirement is not the presence of an AI score. It is the ability to connect the score to the actual production variant, audience, and release action.
4. Business metrics beside AI metrics
An AI variant can score well on a rubric and still fail the product. A chatbot answer can be fluent but reduce resolution rate. A summarizer can be accurate but slow down operators. A coding agent can complete more tasks but increase review rework.
A production AI experimentation platform should put AI quality and business outcomes in the same decision frame:
| AI quality signal | Business outcome | Guardrail |
|---|---|---|
| Answer correctness | Ticket resolution rate | Escalation errors |
| Summary completeness | Agent handling time | Missing required fields |
| Retrieval relevance | Conversion to next step | Latency and cost |
| Agent task success | Human review acceptance | Unsafe tool calls |
This is where traditional experimentation platforms and feature flag platforms overlap. GrowthBook positions experimentation around metrics and feature flags. Optimizely Feature Experimentation connects flags, rollouts, rollback, and A/B tests. LaunchDarkly Experimentation ties metrics to flags or AI-related configs. These are useful category signals: production experimentation requires assignment, metrics, and a release control surface, not just a notebook.
5. Guardrails that can stop rollout
For AI changes, guardrails should be treated as decision inputs, not dashboard decoration. The platform should let the team define thresholds that block or stop expansion:
- Error rate exceeds a threshold.
- Latency exceeds a threshold.
- Cost per successful task rises too far.
- Safety, privacy, or policy checks fail.
- A critical eval grade fails.
- Human review rejection rises.
Some teams keep the automated stop outside the experiment platform and run it through observability or incident tooling. That can work, but the relationship must be explicit. The platform should make it easy to answer: "Which variant caused this guardrail breach, who saw it, and how do we stop it?"

Offline eval, shadow test, canary, and experiment are different stages
A common mistake is to ask one platform feature to do every job. Production AI experimentation usually needs a staged workflow:
- Offline eval: Test candidate behavior against curated, historical, or synthetic cases before real exposure.
- Shadow test: Run the candidate on production inputs without showing its output to users.
- Canary rollout: Serve the candidate to a small controlled audience with guardrails.
- Experiment: Compare variants against quality and business metrics.
- Expansion or rollback: Use the evidence to change production exposure.
Each stage reduces a different kind of risk. Offline evals reduce obvious regression risk. Shadow tests reveal production input surprises. Canary rollout limits blast radius. Experiments connect the change to real outcomes. Rollback keeps the team from waiting on another deployment when the evidence is bad.
FeatBit is most relevant in the runtime-control and production-exposure parts of this workflow. Its feature flags, targeting, percentage rollout, and experimentation capabilities help teams control who sees which variant and connect that exposure to release decisions. AI-specific eval tooling can sit beside that control layer when a team has custom graders, offline datasets, or domain review workflows.
Build versus buy: a practical decision frame
Many teams already have pieces of the platform: feature flags, event pipelines, model evaluation scripts, product analytics, observability, and incident response. The decision is whether those pieces form a reliable production workflow.
Use this build-versus-buy checklist:
| Question | Build may fit when | Buy or extend may fit when |
|---|---|---|
| Do you already have trusted feature flags? | Yes, with targeting, rollout, rollback, and audit history | No, or flags are local config without governance |
| Do you have clean exposure events? | Yes, variant assignment is already logged reliably | No, outcomes cannot be tied to served variants |
| Can you evaluate AI quality? | Yes, teams own graders and review workflows | No, teams need guided eval setup and reporting |
| Can product metrics join exposure data? | Yes, analytics is already standardized | No, metrics live in disconnected systems |
| Can guardrails stop rollout? | Yes, incident and rollback workflows are wired | No, detection and action are separate manual steps |
| Do you need self-hosting or data control? | Existing platform meets governance needs | SaaS data flow, cost, or compliance pressure is a blocker |
For a FeatBit buyer, the strongest fit is usually this: you want open-source or self-hosted feature flag infrastructure, lower-cost rollout control, and a practical way to turn releases into measurable decisions. FeatBit should not be presented as a magic AI judge. It is the production control layer that helps teams expose, measure, govern, and reverse AI changes.
Vendor evaluation questions
Use these questions when comparing FeatBit, GrowthBook, Statsig, Optimizely, LaunchDarkly, or an internal platform.
Release control
- Can AI variants be changed without redeploying application code?
- Can the platform target users, accounts, environments, and risk segments?
- Can operators roll back immediately?
- Does it show who changed exposure and when?
Experiment design
- Does the platform support the right assignment unit for your AI workflow?
- Can it avoid cross-contamination between variants inside the same user journey?
- Can it handle boolean, multivariate, and configuration-style experiments?
- Can it separate release rollout from statistical decision-making?
Evaluation
- Can offline eval results be stored with versioned variants?
- Can online evals observe real production inputs?
- Can custom graders or human labels be attached?
- Are eval rubrics visible enough for review?
Metrics
- Can product metrics be tied to exposure events?
- Can guardrails be tracked beside primary metrics?
- Can metric definitions be reused across teams?
- Can the platform explain why a result is not decision-ready?
Operations
- Can the system work if the AI provider, analytics system, or evaluator is degraded?
- Does the SDK behavior fail safely?
- Are costs predictable as events, requests, and experiments grow?
- Can the team self-host or keep data in its own infrastructure when required?
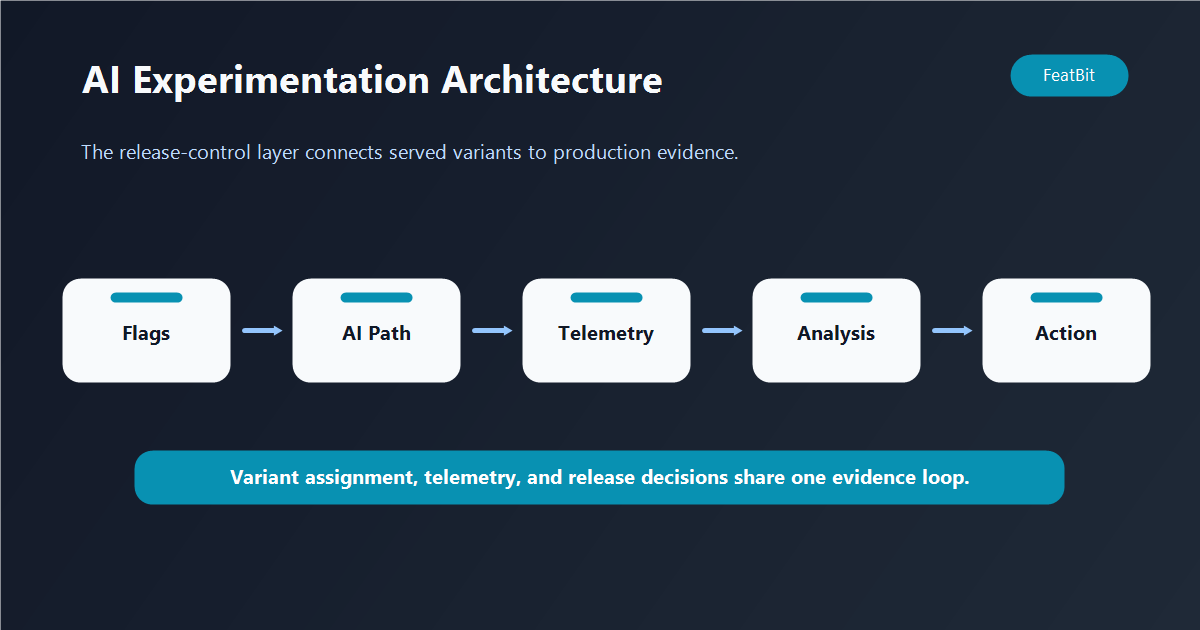
A reference architecture
A practical production AI experimentation platform has five layers:
- Variant registry: Prompts, models, retrieval settings, tools, and agent policies are versioned as variants.
- Exposure control: Feature flags or runtime configs decide which unit receives which variant.
- Telemetry pipeline: Exposure, quality, guardrail, and business events are recorded with shared identifiers.
- Decision analysis: The platform compares variants against primary metrics, guardrails, and eval scores.
- Release action: Operators expand, hold, segment, or roll back the variant.
This architecture keeps the decision close to production reality. Offline evals are still useful, but they do not replace controlled exposure. Product analytics are still useful, but they do not replace variant assignment. Observability is still useful, but it does not replace an explicit release action.
Common anti-patterns
Treating eval score as the only decision metric
Eval scores are useful, especially for catching regressions before user exposure. They are not the same as customer impact. Pair eval scores with business metrics and guardrails.
Running AI experiments without a rollback path
If the team cannot disable a variant quickly, it is not an experiment control plane. It is a report after the fact.
Randomizing at the wrong unit
Randomizing per request may be fine for some backend tasks, but it can confuse user-facing experiences where a person expects consistent behavior. Choose the assignment unit deliberately.
Hiding the variant inside application code
If only developers can see or change the variant, product, support, compliance, and operations teams cannot participate in the release decision. Runtime flags or configs make the decision visible.
Separating AI evals from release governance
Offline eval tools can identify promising changes. Production experimentation decides what real users should receive. The handoff between those two steps must be explicit.
How FeatBit fits the platform model
FeatBit is an open-source feature flag and experimentation platform for teams that want runtime control, progressive rollout, rollback, and self-hosted flexibility. For AI experimentation, that makes FeatBit a practical base layer when the team's main problem is production exposure control and release decision governance.
In a FeatBit-centered workflow:
- A prompt, model route, retrieval setting, or agent behavior is wrapped behind a flag.
- The flag targets a safe audience or percentage rollout.
- The application emits exposure and outcome events.
- Experiment metrics and guardrails are reviewed.
- The team expands, narrows, or rolls back the variant.
Teams with specialized AI eval needs can connect custom graders, review queues, or observability pipelines around that control layer. The key is to keep the release decision tied to the exact variant that production users received.
Selection checklist
Before you choose a production AI experimentation platform, require evidence for these statements:
- We can identify every AI variant that is live in production.
- We can control which users, accounts, or requests see each variant.
- We can log exposure events with stable identifiers.
- We can attach AI quality signals to the served variant.
- We can attach business metrics to the same exposure record.
- We can monitor guardrails while rollout is happening.
- We can roll back without a redeploy.
- We can explain who changed rollout state and why.
- We can keep data, cost, and governance within our operating constraints.
If a platform cannot support those statements, it may still be useful for offline testing or analytics. It is not yet a production AI experimentation platform.
Source notes
- FeatBit product context: FeatBit AI Native, FeatBit documentation overview, and FeatBit home page.
- Evaluation context: OpenAI evaluation best practices and OpenAI Evals guide.
- Category context from official vendor documentation and pages: Statsig AI Evals overview, GrowthBook experimentation platform, Optimizely Feature Experimentation introduction, and LaunchDarkly Experimentation.
- Image recommendations: use the cover image as the Open Graph image; use the architecture and decision-matrix images beside the first platform architecture and decision criteria sections.