AI Delivery Layer: Control the Path From AI Change to Production
An AI delivery layer is the operating layer that carries AI changes from build-time intent to production exposure. It decides which prompt, model route, retrieval profile, guardrail, or agent mode is active for a user, account, conversation, region, or workflow. It also records the evidence needed to expand, pause, roll back, or clean up that change.
This is different from the model runtime. It is also different from CI/CD, offline evaluation, or a prompt editor. The delivery layer sits between those systems and real users. Its job is to make AI behavior releasable: targeted, observable, reversible, and owned.
For FeatBit, the useful angle is simple: AI delivery should be treated as release-decision infrastructure. Feature flags are the control surface that lets teams expose AI behavior deliberately instead of pushing every prompt, model, retrieval, or agent change directly to everyone.
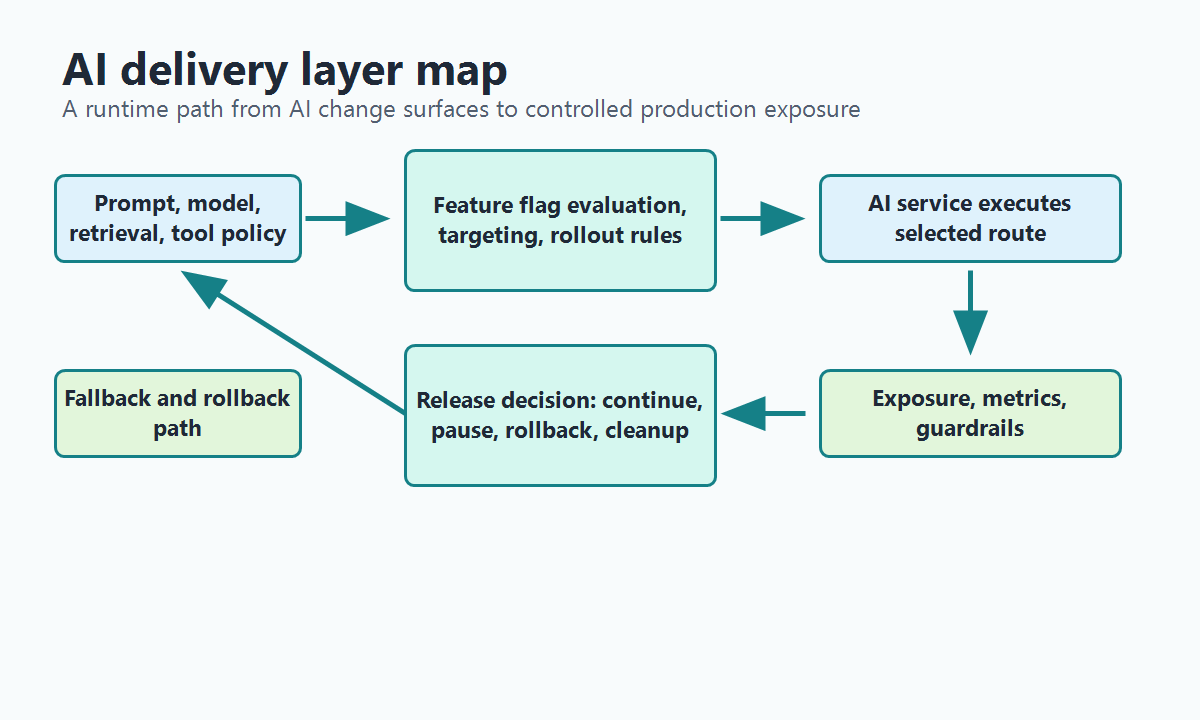
What the AI delivery layer includes
An AI product usually has several moving parts that can change independently:
| Change surface | Example | Delivery-layer responsibility |
|---|---|---|
| Prompt | new support-answer prompt | decide who sees it and keep a fallback prompt available |
| Model route | baseline model versus candidate model | target eligible traffic and record the actual route served |
| Retrieval profile | current index versus reranker | expose only to safe segments and track grounding outcomes |
| Guardrail policy | standard versus strict policy | switch policy by risk tier, region, or workflow |
| Agent mode | draft, approval-required, autonomous | expand authority only after evidence and approval |
| Tool access | read-only versus write-capable tool tier | keep hard authorization separate from release exposure |
| Fallback path | stable answer flow or human handoff | preserve a known safe path during rollout or incident response |
The delivery layer is the control plane around those surfaces. It should answer five operational questions:
- What AI behavior can change without redeploying?
- Who or what is eligible to see the change?
- What evidence proves the change was actually served?
- Which metrics decide whether exposure expands or stops?
- How does the team roll back and clean up after the decision?
If those answers live only in code comments, dashboards, or tribal knowledge, the team does not yet have a delivery layer. It has AI behavior with partial deployment automation.
Why this became a market term
"AI delivery layer" is useful market language because teams are discovering that AI work does not end when a model, prompt, or agent workflow passes a test. AI changes often need live routing, stable assignment, user targeting, outcome telemetry, guardrails, approvals, and rollback.
That category pressure appears in several public product patterns. Optimizely's Feature Experimentation documentation describes deploying code behind feature flags, running A/B tests, using targeted deliveries, and rolling back flags immediately. Its A/B test documentation also starts from a flag, user IDs, an A/B rule, application code, and non-production testing. Those are delivery-layer concerns: assignment, exposure, experimentation, and rollback.
OpenFeature gives the same pattern a vendor-neutral shape. Its flag evaluation specification defines typed flag evaluation with a flag key, default value, evaluation context, and evaluation details. For AI delivery, that matters because prompts, model routes, retrieval profiles, and agent modes need stable typed decisions before the AI service executes behavior.
Agent systems add one more boundary. The Model Context Protocol security guidance is a reminder that consent, authorization, and unsafe tool-use controls are not solved by a release flag alone. A delivery layer can decide whether an approved behavior is active now. It should not replace hard security boundaries, scoped credentials, or tool-router enforcement.
What belongs outside the delivery layer
A useful delivery layer has clear boundaries. It should not become an all-purpose AI platform.
| System | Belongs in the delivery layer? | Reason |
|---|---|---|
| Model provider | No | The provider executes inference. The delivery layer decides which route is exposed. |
| Prompt registry | Usually no | The registry stores versions. The delivery layer controls who sees each version. |
| Offline eval suite | No | Offline evals qualify candidates. The delivery layer manages production exposure. |
| Observability stack | No | Observability stores signals. The delivery layer must attach variation and exposure context. |
| Authorization service | No | Authorization enforces hard access. The delivery layer controls rollout of approved behavior. |
| Feature flag platform | Yes | It evaluates runtime decisions, targeting, rollout, rollback, and audit history. |
| Experiment workflow | Partly | It defines metrics and decision rules tied to exposure. |
This boundary prevents two common mistakes.
The first mistake is hiding release decisions inside the AI gateway. If the gateway silently splits traffic among models, the product team may lose the targeting rules, exposure records, audit trail, and rollback path.
The second mistake is treating a prompt editor as the delivery system. A prompt version is a stored artifact. A delivery decision is a runtime control: who receives that prompt, under which conditions, with which fallback, and with which evidence.
A delivery-layer architecture for AI releases
A practical architecture has six pieces.
1. A named AI change contract
Start with the release decision, not the implementation detail.
ai_delivery_change:
key: support-answer-route-v2
surface: retrieval_profile
owner: support-ai-platform
control: baseline_retrieval
candidate: reranker_v2
fallback: baseline_retrieval
first_audience: internal_support_team
expansion_path:
- internal_users
- beta_accounts
- 5_percent_eligible_traffic
- 50_percent_ab_test
- default_behavior
primary_metric: resolved_without_escalation
guardrails:
- p95_latency
- no_answer_rate
- citation_failure_rate
- support_complaint_rate
cleanup: remove losing route or convert winner into stable config
This contract gives product, engineering, data, and operations the same object to reason about.
2. Server-side evaluation near the AI behavior
For sensitive or server-owned AI decisions, evaluate the flag on the server side, close to the code that chooses the prompt, model route, retrieval profile, or agent mode.
type DeliveryVariation = "baseline" | "candidate" | "fallback";
async function resolveSupportRoute(account: {
key: string;
plan: string;
region: string;
riskTier: string;
}): Promise<DeliveryVariation> {
const variation = await featbit.variation("support-answer-route-v2", {
key: account.key,
custom: {
plan: account.plan,
region: account.region,
riskTier: account.riskTier,
},
}, "baseline");
return variation as DeliveryVariation;
}
The model should not decide whether it is in the experiment. The application should evaluate the release control, then execute the selected AI route.
3. Targeting rules that match real risk
AI changes are rarely equally safe for every user. The delivery layer should support targeting by:
- account or tenant;
- environment;
- region;
- plan or entitlement;
- workflow type;
- data sensitivity;
- risk tier;
- conversation or workflow ID;
- internal, beta, or production cohort.
FeatBit's targeting rules, segments, and percentage rollouts are the implementation primitives for this part of the delivery layer.
4. Exposure records tied to actual execution
Assignment is not enough. AI systems can fall back, timeout, route around a provider, or skip a model call. The delivery layer needs evidence that the AI behavior actually ran.
{
"event": "ai_delivery_exposure",
"flagKey": "support-answer-route-v2",
"unitType": "account",
"unitId": "acct_1842",
"assignedVariation": "candidate",
"actualRoute": "reranker_v2",
"fallbackUsed": false,
"region": "us",
"workflow": "support_chat",
"timestamp": "2026-06-18T09:20:00Z"
}
Outcome events should share the same unit ID, flag key, variation, and workflow context. FeatBit's Track Insights API is one path for sending feature flag usage and custom metric events.
5. Guardrails that can stop exposure
Guardrails should change the release decision. Otherwise they are only dashboard decoration.
| Guardrail | Delivery-layer action |
|---|---|
| unsafe output reports rise | pause expansion and route new traffic to baseline |
| p95 latency regresses | reduce candidate percentage or fall back to stable model route |
| cost per successful task exceeds budget | narrow eligibility or lower-cost route |
| no-answer rate increases | roll back retrieval profile |
| human review rejection rate rises | move agent mode to approval-required |
| incident account appears | exclude the segment immediately |
FeatBit's measurement design guidance is useful here because it separates the metric that decides the release from guardrails that stop expansion.
6. Rollback and cleanup as first-class states
Rollback should be a normal delivery state, not an emergency exception. Cleanup should be part of the same contract.
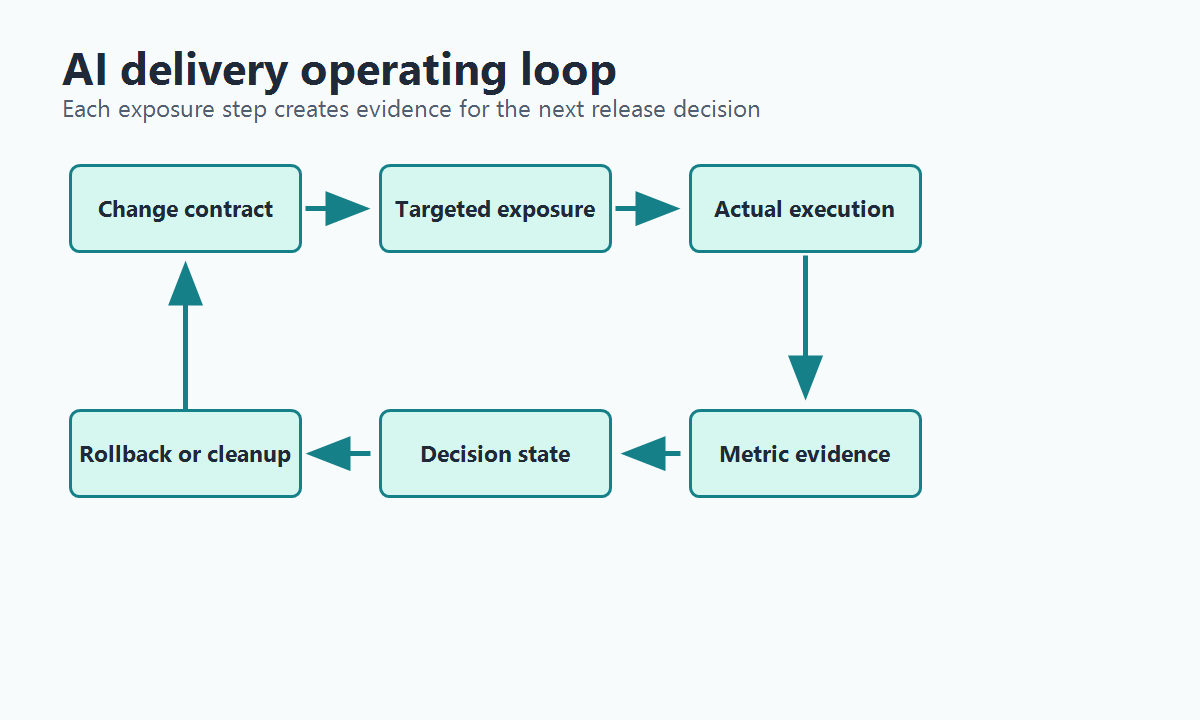
Use explicit decision states:
| State | Meaning | Next action |
|---|---|---|
| Draft | contract exists but no production exposure | review targeting, metrics, and fallback |
| Internal | internal audience sees the candidate | inspect logs and qualitative feedback |
| Canary | small external cohort sees the candidate | watch guardrails and support signals |
| Experiment | candidate is compared against control | collect outcome evidence |
| Continue | evidence is healthy but incomplete | expand within the rollout plan |
| Pause | measurement or guardrail quality is weak | fix instrumentation or narrow scope |
| Rollback | guardrail breach or unacceptable outcome | route to fallback and investigate |
| Promote | candidate becomes default | remove temporary branches or keep an operational flag intentionally |
| Retire | release decision is complete | archive or delete stale temporary controls |
FeatBit's feature flag lifecycle management content expands this cleanup discipline: flags need owners, evidence rules, review windows, and expected end states.
How FeatBit fits the delivery layer
FeatBit should sit in the AI delivery layer when the team wants release control for AI behavior without turning the feature flag platform into the model runtime.
That means FeatBit can own:
- typed variations for AI routes, prompt modes, guardrail modes, and agent authority levels;
- targeting rules for users, accounts, regions, plans, environments, and risk tiers;
- percentage rollout and staged exposure;
- flag insights, audit logs, APIs, webhooks, and event tracking;
- experiment and release-decision workflows;
- lifecycle rules for temporary rollout or experiment controls;
- self-hosted and open-source control when infrastructure ownership matters.
FeatBit should not need to own the prompt editor, vector database, AI eval harness, tool router, or model provider. The delivery layer is stronger when those systems remain specialized and the release decision remains visible.
For the broader architecture, start with FeatBit's AI control layer, safe AI deployment, AI experimentation, AI DevOps stack, and feature flags as release decision infrastructure.
A buyer checklist for an AI delivery layer
Use this checklist when evaluating FeatBit, Optimizely, a model gateway, an experimentation platform, or an internal control plane.

| Area | Verification question |
|---|---|
| Runtime placement | Is the decision evaluated where the AI behavior actually runs? |
| Typed decisions | Can variations represent prompts, models, retrieval profiles, guardrails, and agent modes clearly? |
| Targeting | Can the platform target by account, region, workflow, environment, entitlement, and risk tier? |
| Stable assignment | Can assignment stay stable for the right unit: user, account, conversation, workflow, or request? |
| Actual exposure | Can events prove which AI route actually served the user, including fallback state? |
| Guardrails | Can quality, latency, cost, safety, support, and review signals stop expansion? |
| Rollback | Can a release owner reduce, pause, exclude, or return to baseline without redeploying? |
| Governance | Are permissions, approvals, audit logs, and webhooks available for production changes? |
| Security boundary | Are hard authorization and credential controls separate from release flags? |
| Cleanup | Does every temporary AI flag have an owner, review date, and expected end state? |
The most important test is not a demo. Pick one real AI change and require the delivery layer to carry it from contract to targeted exposure, metric evidence, rollback drill, and cleanup decision.
Common failure modes
The delivery layer is hidden in code. If only one service knows how traffic is split, the team may not be able to audit or roll back the decision quickly.
The platform logs assignment but not actual execution. AI behavior can fall back or reroute. Record the route that actually served the user.
Every AI setting becomes one giant config object. Bundle only when the release decision is truly bundled. Otherwise separate prompt, model, retrieval, guardrail, and agent-mode controls so rollback can be precise.
The model prompt acts as the policy boundary. Prompts can guide behavior, but hard authorization, scoped credentials, and tool-router checks must enforce what the agent is allowed to do.
Temporary controls never end. A delivery layer that never cleans up becomes release debt. Promote, retire, or document long-lived operational controls intentionally.
Bottom line
The AI delivery layer is the part of the stack that makes AI behavior operationally releasable. It does not train the model or replace evaluation. It controls exposure, records evidence, supports rollback, and keeps the release decision visible after deployment.
For teams shipping AI features, that layer should be designed deliberately. Keep execution systems specialized, keep authorization hard, keep telemetry joinable, and keep the release control plane explicit. FeatBit's role is to provide that runtime release-control layer for prompts, models, retrieval paths, guardrails, agent modes, experimentation, rollback, and lifecycle cleanup.
Source Notes
- Optimizely category context: Optimizely's Feature Experimentation introduction describes feature flags, A/B tests, targeted deliveries, rollback, server-side SDKs, remote configuration, and experimentation. Its A/B test documentation is cited for the flag, user ID, A/B rule, code integration, and non-production test workflow.
- Vendor-neutral flag context: OpenFeature's flag evaluation specification is cited for typed flag evaluation, default values, evaluation context, and evaluation details.
- Agent security context: the Model Context Protocol security best practices are cited for tool-use and authorization risk context. This article uses that source to separate release flags from hard security boundaries.
- FeatBit implementation context: AI control layer, safe AI deployment, AI experimentation, AI DevOps stack, measurement design, feature flag lifecycle management, targeting rules, percentage rollouts, Track Insights API, and audit logs support the operating model described here.
Image And Open Graph Notes
- Use
/images/blogs/ai-delivery-layer/cover.pngas the Open Graph image because it summarizes AI delivery as a runtime control path from change to production. - Use
delivery-layer-map.pngnear the opening to show the relationship between AI change surfaces, feature flags, telemetry, rollout decisions, and rollback. - Use
ai-delivery-operating-loop.pngin the decision-state section because it reinforces the release loop from contract to cleanup. - Use
delivery-layer-checklist.pngbeside the buyer checklist because it gives readers a concrete evaluation frame for tools and proofs of concept.