FeatureOps for AI Feature Flags: The Operating Model for Runtime Control
FeatureOps is the discipline of controlling software behavior after deployment. For AI features, that means prompts, model routes, retrieval profiles, guardrail modes, agent tools, and fallback paths are not treated as loose configuration. They become governed release decisions with owners, targeting rules, evidence, rollback paths, and cleanup rules.
Feature flags are the runtime control surface for that discipline. A flag does not make an AI system safe by itself. It gives the team a precise place to decide who sees a behavior, how exposure expands, what telemetry proves the behavior ran, when to roll back, and whether the control should be retired or kept as a permanent operational guardrail.
This article is for platform, product engineering, DevOps, and AI application teams that are hearing "FeatureOps" as market language and need to turn it into an operating model for AI feature flags.
What FeatureOps Means
The useful definition is simple: FeatureOps is runtime operations for feature behavior. DevOps asks whether code can move through build, test, deploy, and infrastructure automation. FeatureOps asks whether the running behavior is exposed to the right audience, measured against the right signals, reversible at the right scope, and governed through the full lifecycle.
The public FeatureOps Manifesto frames the category around runtime control and makes a key distinction: deployment is not the same as release. That distinction matters even more for AI systems because an AI "feature" may be a prompt, model route, retrieval strategy, tool permission, guardrail threshold, fallback rule, or generated-code path.
For traditional software, a feature flag might hide an incomplete screen. For AI software, a flag may decide:
- which prompt profile answers a support question;
- which model route handles a high-risk workflow;
- whether an agent can draft, request approval, or call a tool;
- which retrieval profile is active for a tenant or region;
- whether a strict guardrail or fallback mode is used during an incident;
- whether an experiment candidate is eligible for a user, account, conversation, or workflow.
That is why FeatureOps should not be reduced to "more toggles." It is the operating discipline around those toggles.
Why AI Makes FeatureOps Urgent
AI changes can be small in code and large in behavior. A prompt edit can change tone, refusal behavior, or tool selection. A retrieval profile can change which sources the system trusts. A model route can change latency, cost, quality, and failure modes. An agent permission can turn a read-only assistant into a system that mutates production data.
Static release gates do not cover all of that risk. A pull request can pass tests, a deployment can succeed, and an offline eval can look acceptable, while a narrow production cohort still sees a behavior that is too slow, too expensive, poorly grounded, or operationally unsafe.
FeatureOps gives AI teams a runtime answer:
| AI release question | FeatureOps answer |
|---|---|
| Who should see this AI behavior first? | Targeting rules, segments, environments, and percentage rollout. |
| What exactly changed? | A named flag contract for prompt, model, retrieval, tool, guardrail, or fallback behavior. |
| What proves the behavior ran? | Exposure and outcome events joined to the flag key and variation. |
| What stops expansion? | Guardrail metrics for quality, latency, cost, safety, and support impact. |
| How do we recover? | A prepared rollback state, fallback route, or kill switch. |
| When does the control end? | Lifecycle metadata, review date, owner, and cleanup condition. |
This is compatible with vendor-neutral feature flag thinking. The OpenFeature flag evaluation specification defines typed flag evaluation around a flag key, default value, evaluation context, and evaluation details. AI FeatureOps uses that same shape, but the release decision may select an AI behavior profile instead of a UI branch.
FeatureOps Is Bigger Than Feature Flags
Feature flags are essential, but FeatureOps includes the workflow around them.
If a team creates a flag called new_ai_assistant and leaves it on forever, that is not FeatureOps. It is an unowned control. If the team defines the assistant mode, owner, first audience, fallback, telemetry, release decision rule, and cleanup path, then the flag becomes part of a FeatureOps system.
A useful AI FeatureOps contract looks like this:
ai_featureops_contract:
flag_key: support_assistant_route
behavior_surface: retrieval_and_prompt_profile
owner: support-ai-platform
default: baseline_profile
candidate: citation_first_v2
fallback: baseline_profile
first_audience: internal_support_team
rollout_path:
- internal_users
- beta_accounts
- 5_percent_eligible_traffic
- 50_percent_experiment
- default_behavior
primary_metric: resolved_without_escalation
guardrails:
- p95_latency
- no_answer_rate
- citation_failure_rate
- support_complaint_rate
rollback_action: route_new_sessions_to_baseline_profile
cleanup_rule: remove_losing_profile_or_document_winner_as_operational_config
The contract is more important than the YAML. It makes the release decision explicit enough for engineers, product managers, operators, and auditors to discuss the same object.
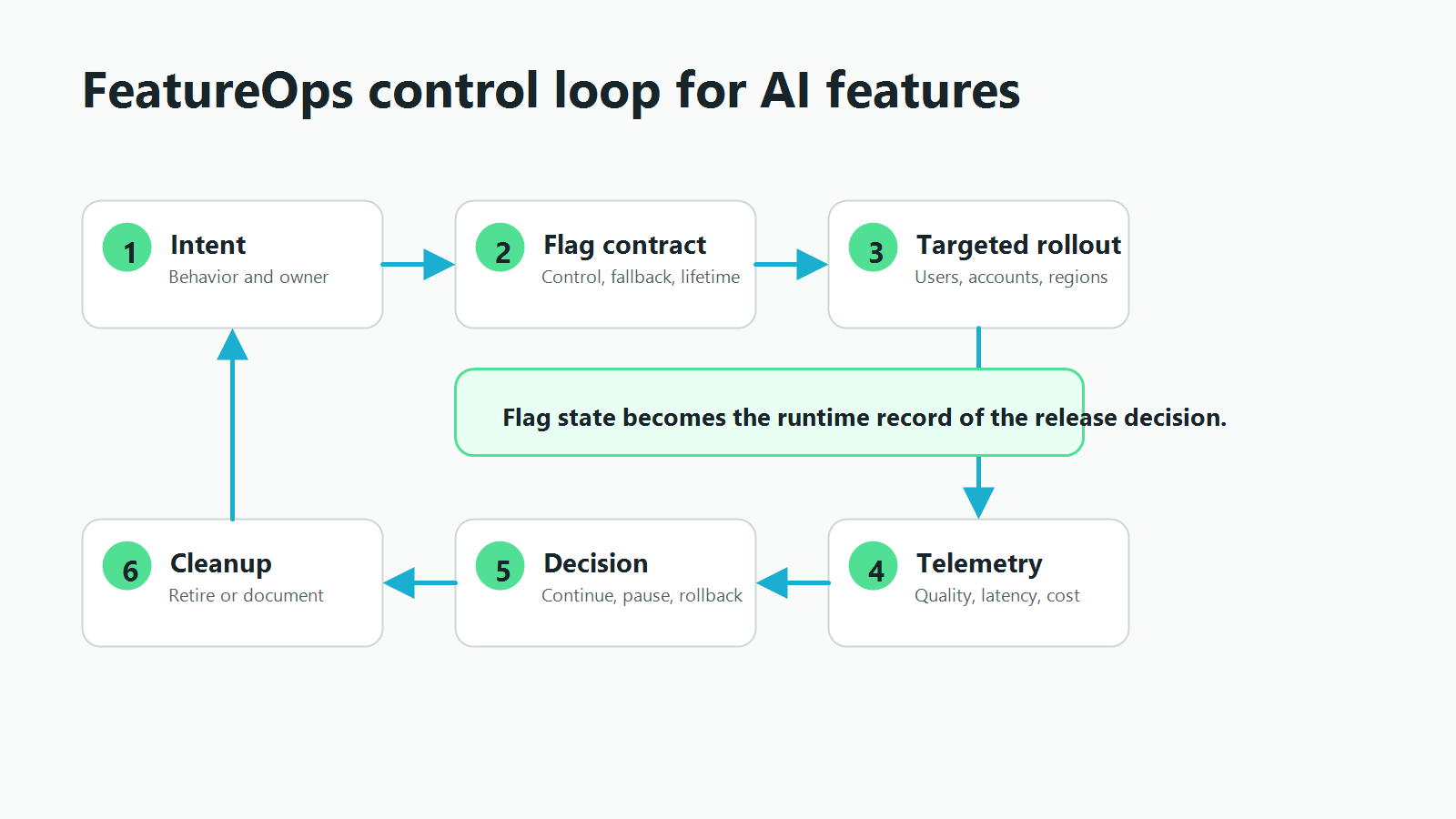
The AI FeatureOps Control Loop
A practical FeatureOps loop has six steps.
- Define the intent. Name the AI behavior and the product or operational reason it exists.
- Create the flag contract. Decide the flag type, variations, fallback, owner, target context, and expected lifetime.
- Roll out deliberately. Start with internal users or safe segments, then expand by account, region, workflow, risk tier, or percentage.
- Join telemetry. Record both assigned variation and actual behavior served, because AI systems can fall back, timeout, or route around a candidate.
- Make the release decision. Continue, pause, roll back, promote, or investigate based on evidence, not only deployment status.
- Close the lifecycle. Remove temporary branches, archive stale flags, or document long-lived operational controls such as kill switches and permission gates.
FeatBit's view is that feature flags are release-decision infrastructure. For AI systems, that infrastructure should carry the decision from reversible exposure to evidence and cleanup. The flag is not just a switch. It is the runtime record of the decision.
What To Put Behind An AI Feature Flag
Do not put every constant behind a flag. Use FeatureOps when a behavior changes production exposure, user trust, cost, risk, or release evidence.

| AI surface | Good flag shape | Evidence to collect | Rollback path |
|---|---|---|---|
| Prompt profile | String or JSON variation with reviewed profile names | answer quality, escalation, human review edits | return to last stable prompt |
| Model route | Route profile such as balanced_v2 or fallback_first |
latency, cost, error rate, task success | move affected cohort to baseline route |
| Retrieval profile | Segment-targeted rollout rule | citation coverage, no-answer rate, complaint rate | fallback to verified source |
| Agent tool | Capability tier flag | approval rate, denial rate, incident signal | disable tool or require approval |
| Guardrail mode | Strict, standard, or fallback-first variation | blocked output, false positive rate, escalation | switch to safer guardrail mode |
| Fallback mode | Operational switch or incident variation | recovery rate and support impact | keep degraded safe path active |
FeatBit documentation supports the implementation primitives behind this model: targeting rules, percentage rollouts, flag insights, audit logs, and the Track Insights API.
How FeatureOps Differs From AI Delivery And AI Operations
Several terms overlap, so the boundaries should be clear.
AI delivery layer is the architecture that moves AI changes from build-time intent to production exposure. It includes prompts, model routes, retrieval, telemetry, approvals, and rollback. If you need the architecture map, read FeatBit's guide to the AI delivery layer.
AI-assisted operations is the use of AI to summarize signals, propose actions, and prepare changes for approval. It is about how AI helps operators work. FeatBit's article on AI-assisted operations with feature flags covers that workflow.
FeatureOps is the operating discipline that keeps feature behavior controlled after deployment. It includes the flag contract, release evidence, rollback, governance, and lifecycle closure. It can apply to AI delivery, AI-assisted operations, ordinary product releases, backend policy changes, and long-lived operational kill switches.
The terms are complementary. FeatureOps is the operating model; feature flags are the control surface; telemetry is the evidence system; delivery and operations are where the model is used.
Governance Without Pretending Flags Are Security
A feature flag can decide whether an approved behavior is active for a context. It should not replace hard authorization, scoped credentials, network policy, data access rules, or tool-router enforcement.
This distinction is important for AI agents. Unleash's article on runtime control for AI agents uses FeatureOps language for agent tool control and argues that agent capabilities can be governed with feature flags. That is useful category context, but the practical design should still separate release control from security control.
For example:
- IAM decides whether a service account can call a billing API.
- The tool router enforces which operation is allowed.
- A feature flag decides whether the billing assistant is in read-only, draft, approval-required, or disabled mode for a given tenant.
- Audit logs record who changed the release state.
- Telemetry shows whether the change improved or harmed the workflow.
That separation keeps FeatureOps honest. It controls exposure and rollback. It does not turn a prompt into a permission model.
A FeatBit-Oriented Implementation Path
A team can adopt AI FeatureOps without rebuilding its whole AI stack.
Start with one AI behavior that is close to production and meaningful enough to need runtime control. Good candidates include a support-answer prompt, a model route, an agent tool, a retrieval profile, or an incident fallback mode.
Then implement the operating path:
- Create a typed flag variation for the behavior profile.
- Evaluate the flag server-side where the AI behavior is selected.
- Pass evaluation context that matches real risk: user, account, region, plan, environment, workflow, and risk tier.
- Keep a safe default and fallback route outside the model prompt.
- Emit exposure and outcome events with the flag key, variation, assignment unit, and actual route served.
- Use rollout stages instead of one big launch.
- Connect audit logs and observability to release decisions.
- Add owner, review date, and cleanup condition before expanding rollout.
FeatBit fits this path as a runtime release-control layer. It can manage flag variations, targeting, percentage rollout, audit history, event tracking, APIs, webhooks, and self-hosted control for teams that want infrastructure ownership. It should not replace the prompt registry, model gateway, eval harness, authorization service, or observability backend. The point is to keep the release decision visible and reversible while those specialized systems do their jobs.
For broader context, see FeatBit's AI control layer, safe AI deployment, AI experimentation, AI governance, and feature flag lifecycle management.
Common Failure Modes
Treating FeatureOps as a slogan. If there is no owner, fallback, evidence rule, or cleanup condition, the team has feature flags but not FeatureOps.
Using one global AI flag. A global switch is useful for emergency shutdown, but normal AI release control needs separate surfaces for prompt profile, model route, retrieval, tool tier, guardrail mode, and fallback behavior.
Hiding randomization in the AI service. If the model gateway silently splits traffic, product and operations teams lose targeting, auditability, and rollback context. Keep assignment visible in the release-control layer.
Recording assignment but not execution. AI systems can fall back or skip the intended route. Track what actually served the request, not only which variation was assigned.
Letting temporary flags become permanent debt. Some operational controls should live for years, such as kill switches and permission gates. Temporary rollout or experiment flags should be reviewed, archived, or removed after the decision closes.
The Short Checklist
Before calling an AI release "FeatureOps-ready," confirm:
- the AI behavior has a named flag key and typed variation;
- the flag is evaluated where the behavior is selected;
- the evaluation context includes the assignment unit and risk context;
- there is a safe default and a tested fallback;
- exposure and outcome events can be joined;
- guardrails can stop expansion;
- rollback does not require redeployment;
- production changes leave an audit trail;
- hard authorization remains outside the flag;
- temporary controls have an owner, review date, and cleanup condition.
FeatureOps is how AI feature flags become more than runtime switches. It turns prompts, models, agents, retrieval, guardrails, and fallbacks into controlled release decisions that can be targeted, measured, rolled back, governed, and eventually cleaned up.
Source Notes
- Category context: the FeatureOps Manifesto defines FeatureOps as runtime control for software behavior and distinguishes deployment from release.
- Vendor terminology context: Unleash's runtime control for AI agents uses FeatureOps language for AI agent tool control. This article cites it as market-language context, not as a product comparison.
- Vendor-neutral flag context: the OpenFeature flag evaluation specification provides useful language for typed flag evaluation, default values, evaluation context, and evaluation details.
- FeatBit implementation context: targeting rules, percentage rollouts, flag insights, audit logs, Track Insights API, AI control layer, safe AI deployment, AI experimentation, AI governance, and feature flag lifecycle management.
- Related FeatBit reading: AI delivery layer, AI-assisted operations with feature flags, AI agent runtime control runbook, and vendor-agnostic AI feature flags.
Image And Open Graph Notes
- Use
/images/blogs/featureops-ai-feature-flags/cover.pngas the Open Graph image because it summarizes FeatureOps as runtime control for AI feature flags. - Use
featureops-control-loop.pngnear the opening to show the operating loop from intent to cleanup. - Use
featureops-readiness-matrix.pngbeside the readiness section because it turns the decision criteria into a quick implementation checklist.