Fallback Behavior for AI Feature Flags: Safe Defaults, Evidence, and Rollback
Fallback behavior is the production contract for what happens when an AI feature flag cannot safely serve the intended variation. It is not only the SDK default value. For AI systems, fallback behavior can decide whether a request uses the baseline prompt, a safer model route, a narrower retrieval profile, human review, cached output, or a full rollback path.
The useful design rule is simple: every AI flag should define the safest acceptable behavior before the flag is evaluated, before the model is called, and before the rollout expands. If the flag service is unavailable, a variation has the wrong shape, telemetry is missing, or guardrails breach, the application should return to a known behavior without guessing.
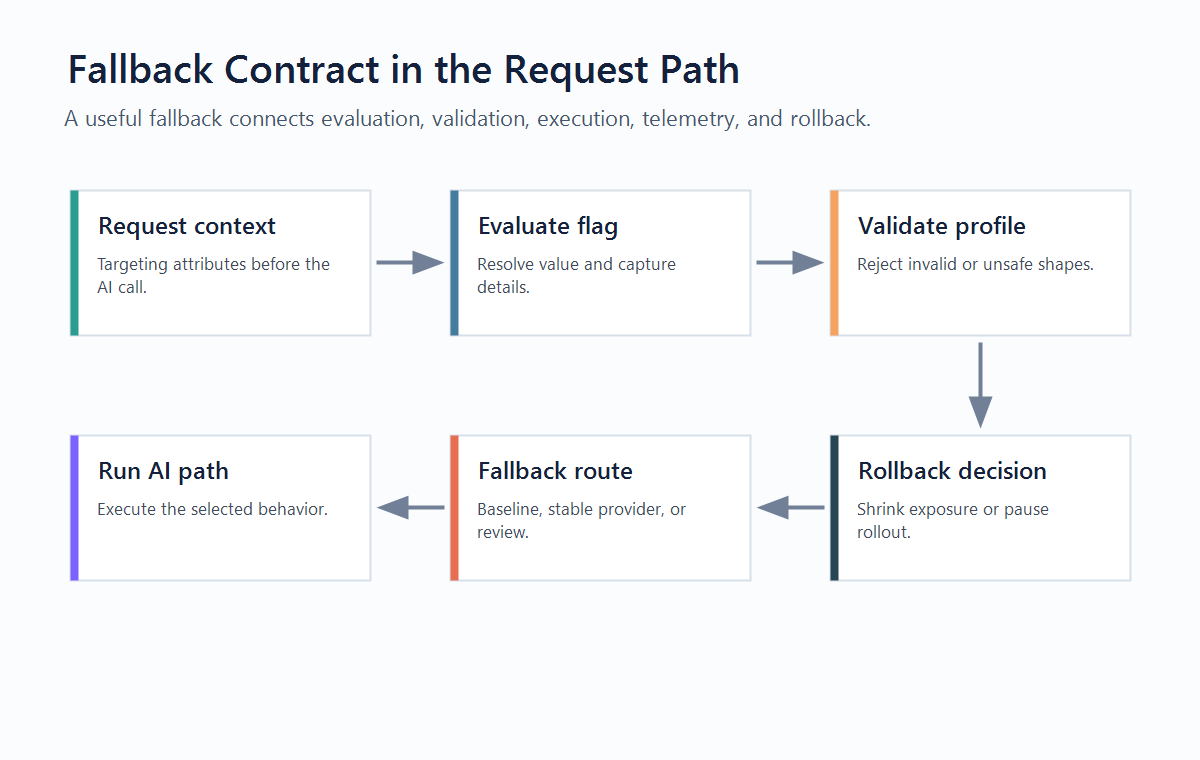
What Fallback Behavior Means in AI Feature Flags
In ordinary feature flagging, fallback often means "return the default value if evaluation fails." That still matters. The OpenFeature flag evaluation specification says typed evaluation methods require a default value, and abnormal execution should return that supplied default value. OpenFeature also notes that a no-op provider returns the supplied default flag value when no provider is configured.
AI feature flags need a wider definition because the selected value may change an expensive or risky runtime path:
| Flag controls | Fallback behavior should answer |
|---|---|
| Prompt version | Which reviewed prompt should run if the candidate prompt is unavailable or unsafe? |
| Model route | Which stable model or provider route should handle the request? |
| Retrieval profile | Which index, source filter, or conservative search path should be used? |
| Guardrail mode | Should the system tighten review, refuse, or escalate? |
| Agent tool policy | Should the agent continue in read-only mode, require approval, or stop tool execution? |
| AI parameter profile | Which typed profile is safe when JSON validation fails? |
That makes fallback behavior a release decision. It defines how much capability the product keeps when the preferred AI behavior cannot be trusted.
The Reader Job: Choose the Right Safe Default
The wrong fallback can be worse than no fallback. A default that silently serves a cheaper but lower-quality model may hide a product regression. A fallback that always shuts the feature off may create avoidable downtime. A fallback that keeps the candidate variation after telemetry fails can make the release impossible to evaluate.
Use this decision frame:
| Situation | Safer fallback | Why |
|---|---|---|
| Flag service unavailable | In-code baseline value | The application must keep a reviewed behavior available without network dependence. |
| Flag key missing | Baseline variation and alertable telemetry | Missing configuration should not become an unreviewed AI path. |
| Variation has invalid type or schema | Reject the variation and use typed baseline | AI profiles often carry JSON; type mismatch should not reach prompt assembly or model routing. |
| Candidate model provider fails | Stable model route or human escalation | The user still needs a useful outcome, not a hidden experiment failure. |
| Retrieval profile has unsafe scope | Conservative source set | Data-boundary assumptions should fail toward narrower access. |
| Guardrail metric breaches | Reduce exposure or return affected segment to baseline | Rollback should be targeted before the issue reaches every user. |
| Telemetry is missing | Pause expansion and keep baseline for new traffic | A release without evidence cannot support a safe decision. |
This is the main difference from a generic default value. A fallback should protect the request path, the user experience, and the release evidence at the same time.
Four Layers of Fallback Behavior
Treat fallback as a layered control, not a single value.
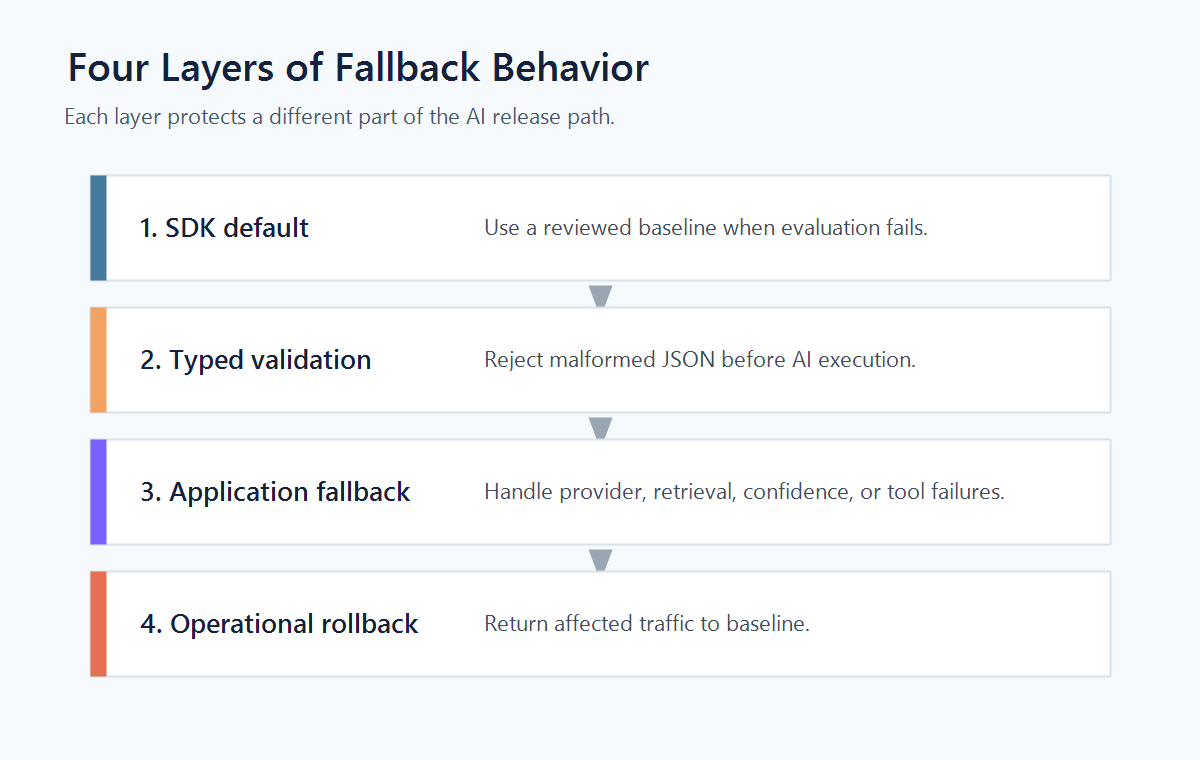
1. SDK Default
The SDK default is the value passed into the evaluation call. It protects the hot path when flag evaluation cannot return a valid value. For AI flags, this value should be a real baseline profile, not a placeholder.
type SupportAnswerProfile = {
profile: string;
prompt: "baseline_v3" | "candidate_v4";
modelRoute: "stable" | "candidate";
retrievalScope: "approved_docs" | "expanded_docs";
fallbackMode: "baseline" | "human_review";
};
const baselineProfile: SupportAnswerProfile = {
profile: "support_baseline_v3",
prompt: "baseline_v3",
modelRoute: "stable",
retrievalScope: "approved_docs",
fallbackMode: "human_review",
};
const profile = await flags.jsonVariation<SupportAnswerProfile>(
"support-answer-ai-profile",
userContext,
baselineProfile
);
OpenFeature's detailed evaluation API also includes metadata such as flag key, value, variant, reason, and error information when supported. That metadata is useful when you need to distinguish "served baseline by targeting rule" from "served baseline because evaluation failed."
2. Typed Validation
AI flags often carry structured profiles. The application should validate the resolved value before it reaches prompt assembly, retrieval, tool choice, or model routing.
function isSupportAnswerProfile(value: unknown): value is SupportAnswerProfile {
if (!value || typeof value !== "object") return false;
const profile = value as Partial<SupportAnswerProfile>;
return (
typeof profile.profile === "string" &&
["baseline_v3", "candidate_v4"].includes(profile.prompt ?? "") &&
["stable", "candidate"].includes(profile.modelRoute ?? "") &&
["approved_docs", "expanded_docs"].includes(profile.retrievalScope ?? "") &&
["baseline", "human_review"].includes(profile.fallbackMode ?? "")
);
}
const evaluatedProfile = isSupportAnswerProfile(profile)
? profile
: baselineProfile;
FeatBit supports multivariate flags with string, number, and JSON variations, and its remote config guide explains using non-boolean values to change application behavior without deployment. That flexibility is useful only when the consuming service validates the shape it expects.
3. Application Fallback
The application fallback is the behavior users experience when something downstream fails. It is different from the SDK default because it happens after evaluation.
Examples:
- the candidate model times out, so the service routes to the stable model;
- retrieval returns an unsafe or empty result set, so the answer switches to approved documentation only;
- the agent wants a risky tool, so the workflow becomes approval-required;
- the confidence score is too low, so the product returns a human-review path;
- cost guardrails breach, so the request uses a lower-cost stable route for the affected segment.
For AI systems, application fallback should be explicit in telemetry. If candidate traffic repeatedly falls back to baseline execution, the release result is not the same as a clean candidate exposure.
4. Operational Rollback
Operational rollback is the human or automated release action that changes exposure after evidence arrives. FeatBit's targeting rules and percentage rollouts are relevant here because rollback often needs to affect a segment, account group, region, or traffic percentage rather than the whole product.
A useful rollback rule is written before exposure:
rollback_when:
- candidate_error_rate_above_guardrail
- fallback_rate_above_guardrail
- p95_latency_regresses
- telemetry_missing_for_candidate
rollback_action:
internal: keep_candidate_for_debugging
production_canary: return_to_baseline
high_risk_accounts: human_review
FeatBit's broader AI safe deployment model follows the same operating idea: start with limited exposure, observe the result, and keep rollback available before the behavior scales.
A Practical Fallback Workflow
Design fallback behavior before creating the flag.
| Step | What to decide | Output |
|---|---|---|
| Name the release question | What AI behavior is changing and why? | support-answer-ai-profile controls the support assistant profile. |
| Define the baseline | What behavior is already reviewed? | Baseline prompt, stable model, approved retrieval scope, human review fallback. |
| Define candidate variations | What behavior may expand? | Candidate prompt or model route with a named owner. |
| Choose safe failure modes | What happens when evaluation, validation, provider, retrieval, or telemetry fails? | SDK default, schema rejection, model fallback, rollout pause. |
| Instrument evidence | Which events prove the behavior that actually ran? | Exposure event, execution event, fallback reason, outcome event. |
| Write rollback criteria | When should exposure shrink or stop? | Guardrail thresholds and rollback action. |
| Set cleanup rule | What happens after the decision? | Promote baseline or candidate, remove temporary branches, keep only durable controls. |
The server-side evaluation for AI feature flags pattern is important because most fallback decisions must happen before the AI call. Browser-only evaluation cannot safely decide model route, retrieval scope, tool authority, or provider fallback.
Track Fallback as Evidence, Not Noise
Fallback events should be visible in the release record. Otherwise a candidate can look safe because the risky path rarely ran.

At minimum, track:
- flag key and evaluated variation;
- default value used or not used;
- evaluation reason or error state when available;
- profile version that reached execution;
- fallback mode, such as baseline, stable provider, cached answer, human review, or denial;
- fallback reason, such as timeout, schema error, provider error, guardrail breach, unsafe retrieval, or telemetry failure;
- primary outcome and guardrails such as task completion, correction rate, latency, cost, error rate, and fallback rate.
FeatBit's flag insights, Track Insights API, and experimentation workflow can support this evidence loop when the application emits the right context. The important modeling choice is to treat fallback rate as a guardrail. It can reveal provider instability, schema mistakes, risky targeting, or a candidate that only works when the system quietly avoids it.
Fallback Behavior for AI Experiments
Fallback behavior changes how you interpret an AI experiment.
Suppose 10 percent of traffic is assigned to a candidate model route. If 30 percent of those candidate requests time out and use the stable model, the experiment is not measuring pure candidate behavior. It is measuring a mixed route: candidate when healthy, stable when failing.
That may be the product you intend to ship. If so, record it honestly. If not, the experiment needs a different setup:
| Experiment question | Fallback treatment |
|---|---|
| Does candidate model B improve support resolution? | Count fallback-to-baseline as a candidate guardrail failure. |
| Does a resilient model routing policy improve reliability? | Treat candidate-plus-fallback as the evaluated product behavior. |
| Does a prompt profile improve quality? | Keep model route stable so fallback does not hide prompt effects. |
| Does a stricter retrieval policy reduce unsafe answers? | Track empty-result fallback separately from answer quality. |
This is why fallback belongs in the metric plan. FeatBit's measurement design guidance separates primary outcomes from guardrails so a release can improve one metric without hiding damage in another.
How FeatBit Fits
FeatBit should sit at the release-control layer, not inside the model call itself. The application still owns prompt assembly, model provider credentials, retrieval, tool execution, authorization, and validation.
FeatBit is useful for fallback behavior because it can help teams:
- serve typed variations or remote config profiles for AI behavior;
- target fallback-sensitive changes by user, account, environment, segment, or percentage;
- keep baseline variations available during rollout;
- reduce exposure or roll back a segment without redeploying;
- use audit logs to see who changed a flag and when;
- connect flag evaluations and metric events to release evidence;
- apply feature flag lifecycle management so temporary AI fallback controls do not become stale production branches.
For implementation details, use FeatBit docs for create flag variations, remote config, targeting rules, percentage rollouts, flag insights, and the Track Insights API.
Common Mistakes
Using a placeholder default. A default value such as "control" is not enough if the application needs a complete prompt, model, retrieval, and fallback profile.
Letting invalid JSON reach runtime execution. Structured variations need schema validation before the AI call.
Failing open on risky capability. If context is missing or policy cannot be evaluated, agent tool access, broad retrieval, and relaxed guardrails should fall back to safer modes.
Confusing fallback with rollback. Fallback handles one request or one execution path. Rollback changes exposure for future traffic.
Ignoring fallback rate in experiments. A candidate that frequently falls back to baseline may appear safer than it is.
Leaving fallback controls forever. Temporary fallback branches need the same cleanup expectation as other release flags.
Starting Checklist
Before launching an AI flag, confirm:
- The flag has a reviewed baseline value that can run without network evaluation.
- Structured variations are validated before prompt, model, retrieval, guardrail, or tool logic runs.
- The default behavior is safer than the candidate for missing context, invalid type, provider error, and telemetry failure.
- Application fallback is recorded separately from flag evaluation fallback.
- The exposure event says what variation was assigned.
- The execution event says what behavior actually ran.
- Fallback rate is a guardrail metric.
- Rollback rules are written before production exposure.
- High-risk segments have narrower fallback behavior.
- Cleanup rules say when temporary fallback paths are removed or made durable.
Bottom Line
Fallback behavior for AI feature flags is a release-control design problem. The SDK default protects the evaluation path, typed validation protects the runtime path, application fallback protects the user experience, and operational rollback protects future exposure.
Design those layers before the rollout starts. Then the AI flag can do its real job: control who receives a behavior, prove what actually ran, and let the team reverse the decision before a small failure becomes a broad incident.
Source Notes
- Vendor-neutral flag evaluation context: OpenFeature's Flag Evaluation API specification describes typed evaluation methods, required default values, detailed evaluation metadata, and default return behavior during abnormal execution.
- FeatBit implementation context: create flag variations, remote config, targeting rules, percentage rollouts, flag insights, Track Insights API, and feature flag lifecycle management support the workflow described here.
- Related FeatBit reading: AI control layer, AI safe deployment, server-side evaluation for AI feature flags, measurement design, and feature flag lifecycle management.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it frames fallback behavior as a production release-control contract. - Use
fallback-contract.pngnear the opening because it shows where fallback decisions sit between flag evaluation, AI execution, telemetry, and rollback. - Use
fallback-layers.pngin the layered design section because it separates SDK default, typed validation, application fallback, and operational rollback. - Use
fallback-metrics.pngin the evidence section because it shows fallback rate as a guardrail rather than background noise.