Feature Attribution for AI Explanations: How to Release Explanations Safely
Feature attribution for AI explanations answers a narrow but important question: which input features, signals, or context items contributed most to a model output?
For product teams, the harder question is not only how to compute attribution. It is how to release explanations without confusing users, leaking sensitive signals, slowing the product, or turning an uncertain explanation into a false promise. Feature flags help because explanation behavior is a runtime product decision: who sees it, which method is used, what guardrails must pass, and how quickly the team can roll back.
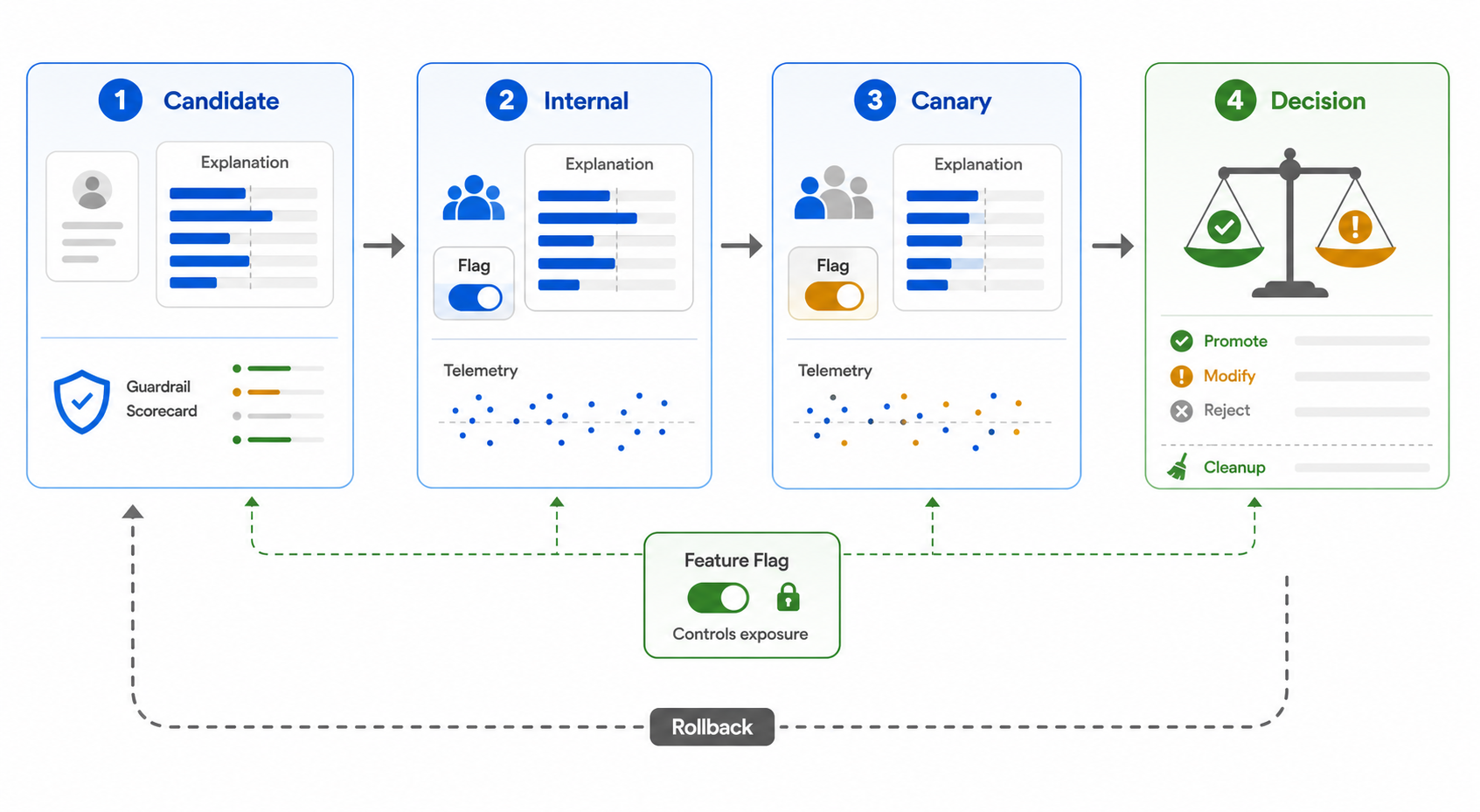
What Feature Attribution Explains
Feature attribution assigns importance to the inputs used in a prediction, recommendation, ranking, classification, or generated response. In a support assistant, the features might include account tier, product area, recent error code, language, ticket history, or retrieved documentation. In a risk model, they might include behavioral signals, transaction context, account age, or policy rules.
An attribution explanation usually tries to say:
| Explanation question | Example answer |
|---|---|
| Which inputs pushed the result up? | Recent error frequency and enterprise plan increased escalation risk. |
| Which inputs pushed the result down? | Long account tenure and successful recent renewals reduced churn risk. |
| Which signals were ignored or weak? | Browser version was present but had little effect on this recommendation. |
| Which context should a human review? | Retrieved policy document and support history were the strongest explanation inputs. |
Methods such as SHAP and LIME are widely cited because they help explain model predictions without forcing every production model to be inherently simple. The SHAP paper describes assigning each feature an importance value for a prediction. The LIME paper frames the problem around explaining classifier predictions in a way a person can inspect. Those methods are useful, but the release problem remains: an explanation can be technically valid and still be harmful, too slow, too expensive, or too hard for users to interpret.
Why Explanations Need Release Control
AI explanations are user-facing product behavior. Treat them that way.
An explanation panel can change user trust, decision speed, complaint rate, support tickets, conversion, compliance review, and operator behavior. It can also expose internal signals that were never meant to be shown. For generated AI systems, explanations may combine feature attribution, retrieved context, prompt metadata, model confidence, tool traces, or evaluator labels. That makes the explanation experience a release surface, not just a model artifact.
A feature attribution explanation should usually be controlled when:
- it appears in a user interface, workflow, dashboard, decision review, or support tool;
- it changes how a human accepts, rejects, escalates, or overrides an AI output;
- it may reveal sensitive or proprietary input signals;
- it adds model or explainer latency to a production request;
- it uses a new attribution method, explanation format, threshold, or segment-specific policy;
- it needs experiment evidence before becoming the default.
FeatBit's AI control layer framing is useful here. Each AI decision point can become a named runtime control surface. For explanations, the control surface is not only "show or hide explanations." It can also select the explanation method, detail level, segment, fallback behavior, and rollback rule.
Define The Release Question Before The Explainer
Do not begin with "Can we add SHAP values to the UI?" Begin with the release decision.
A useful release question sounds like this:
Should the support assistant show feature attribution explanations to internal support agents for English billing cases, if explanations improve correct escalation decisions without increasing p95 latency, complaint rate, or manual review time?
That question names the surface, audience, scope, expected benefit, guardrails, and first exposure stage. It also avoids overclaiming. The goal is not to prove that feature attribution explains the entire model. The goal is to decide whether this explanation experience is useful and safe for a defined workflow.
Use a small contract before the first rollout:
attribution_explanation_release:
flag_key: support_assistant_attribution_explanation
candidate: shap_top_five_feature_panel
baseline: no_visible_attribution_panel
audience: internal_support_agents
eligible_scope:
language: english
ticket_type: billing
exclusions:
- regulated_accounts
- active_incident_accounts
primary_outcome: correct_escalation_decision
guardrails:
- p95_response_latency
- explanation_dispute_rate
- manual_review_time
- sensitive_signal_exposure
- support_agent_override_rate
rollback: hide_explanation_panel_and_keep_baseline_answer
cleanup: remove_losing_explanation_branch_after_decision
This makes the explanation a reversible release, not a permanent UI addition hidden behind a model team decision.
Use Flags For Explanation Variants
Feature attribution is rarely one binary choice. The team may need to compare explanation methods, formats, thresholds, and audiences.
| Runtime choice | Example flag variation | Why it matters |
|---|---|---|
| Visibility | hidden, internal_only, customer_visible |
Controls blast radius before broad exposure. |
| Method | shap, lime, model_native, rule_summary |
Different methods have different fidelity, cost, and interpretability. |
| Detail level | top_3, top_5, full_debug |
Too much detail can confuse users or leak internal signals. |
| Audience | support_agents, admins, beta_customers |
Explanations may be useful for operators before end users. |
| Fallback | hide_on_timeout, show_summary, require_review |
Explanation failures should not break the primary product path. |
In code, evaluate the flag before the model response is assembled or before the explanation panel is rendered:
type AttributionMode = 'hidden' | 'internal_top_5' | 'customer_summary';
async function resolveSupportAnswer(request: SupportRequest) {
const attributionMode = await flags.getString<AttributionMode>(
'support_assistant_attribution_explanation',
request.user,
'hidden'
);
const answer = await supportModel.generateAnswer(request);
if (attributionMode === 'hidden') {
return { answer, explanation: null };
}
const explanation = await buildAttributionExplanation({
mode: attributionMode,
answer,
requestContext: request.context
});
return { answer, explanation };
}
The exact SDK call will depend on your stack. The release principle is stable: evaluate once for the request, use the selected variation to control behavior, and attach the variation to the telemetry that supports the final decision.
For implementation patterns, FeatBit docs on targeting rules, percentage rollouts, and A/B testing with feature flags provide the practical release mechanics.
Join Attribution To Evidence
An explanation rollout is weak if the team cannot reconstruct who saw which explanation, which model and explainer version generated it, and what happened afterward.
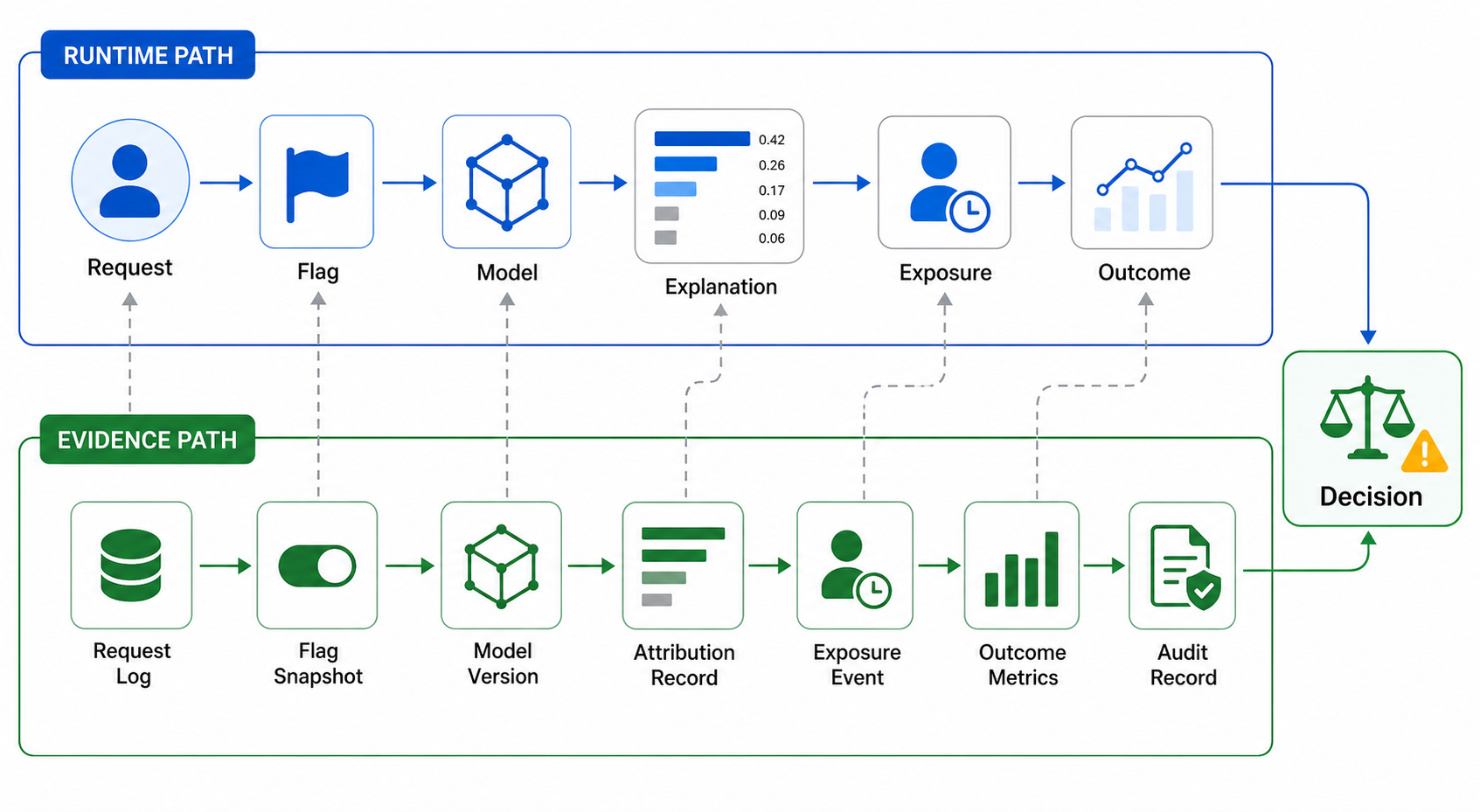
Track at least four layers:
| Evidence layer | What to record | Why it matters |
|---|---|---|
| Assignment | flag key, variation, environment, targeting rule, assignment unit | Proves which explanation experience was served. |
| AI route | model version, prompt or policy version, retrieval profile, explainer method | Prevents a result from being attributed to the wrong component. |
| Explanation record | top features, redacted display text, confidence or quality label, timeout state | Shows what the user or operator actually saw. |
| Outcome | accepted decision, override, escalation, dispute, task completion, latency, cost | Connects explanation behavior to product and operational results. |
OpenTelemetry's generative AI semantic conventions are useful background for consistent AI telemetry. You do not need every attribute on day one, but you do need a stable join between request context, model behavior, explanation output, and user outcome.
FeatBit's Track Insights API is relevant when a team wants to send custom metric events that connect feature flag variation to behavior or outcome evidence. FeatBit's flag insights can also help teams observe variation delivery before treating the release as successful.
Stage The Rollout
Feature attribution explanations should usually move through evidence stages.
| Stage | What to learn | Action if unhealthy |
|---|---|---|
| Offline review | Are the displayed features plausible, redacted, and understandable? | Fix feature mapping, labels, redaction, or method choice. |
| Internal exposure | Do operators understand the explanation and avoid misuse? | Narrow the audience or simplify the format. |
| Canary | Does latency, cost, complaint rate, or override behavior change? | Roll back to hidden or internal-only explanations. |
| Experiment | Does the explanation improve the primary workflow outcome? | Keep control, change format, or test a narrower segment. |
| Full rollout | Can the team operate, audit, and clean up the explanation path? | Keep a deliberate kill switch or remove temporary branches. |
This staged model matches FeatBit's safe AI deployment guidance: expose AI behavior gradually, use metric gates, and preserve rollback. It also fits FeatBit's AI experimentation view that prompts, models, retrieval settings, and agent strategies should be measurable production variants when they affect users.
NIST's AI Risk Management Framework is useful context because it treats trustworthy AI as a risk-management discipline across the design, development, use, and evaluation of AI systems. For feature attribution explanations, that means the team should evaluate the explanation in the context where people will actually use it, not only in a notebook or model report.
Guardrails For Feature Attribution
Attribution explanations can fail in ways that ordinary feature releases do not.
False precision. A ranked feature list can look more certain than it is. Use careful language such as "strongest contributing signals for this model output" instead of implying causal truth.
Sensitive signal exposure. A model may use features that should not appear in a UI. Redact, bucket, or summarize sensitive inputs before rollout.
Wrong audience. A detailed operator explanation may be useful for a trained reviewer and harmful for an end user. Start with the audience that can interpret it.
Latency and cost drift. Some attribution methods require extra computation. Add timeout behavior and measure cost per explained decision.
Attribution without action. If the explanation does not help a person accept, reject, escalate, or debug the AI output, it may add noise.
Cleanup neglect. Temporary explanation modes, feature mappings, redaction rules, and experiment flags become release debt if the team never promotes, removes, or archives them. FeatBit's feature flag lifecycle management model helps keep those controls tied to owner, evidence, decision, and cleanup.
A Practical Checklist
Before publishing feature attribution explanations, confirm:
- The release question names the user, workflow, candidate explanation, baseline, and expected outcome.
- The attribution method is appropriate for the model and product decision.
- Sensitive features are redacted, bucketed, renamed, or excluded from display.
- The flag controls visibility, method, detail level, audience, or fallback behavior at runtime.
- Exposure starts with internal users or a narrow segment before broad customer visibility.
- Explanation records can be joined to flag variation, model route, outcome metrics, and guardrails.
- The UI avoids causal overclaiming when the attribution method only shows contribution.
- Rollback hides the explanation or returns to the baseline without redeploying.
- The release owner has a decision rule for promote, modify, pause, or reject.
- The cleanup path removes losing explanation branches and stale telemetry fields.
Where FeatBit Fits
FeatBit does not compute SHAP values, replace an explainability library, or certify that an explanation is fair or compliant. It fits the release-control layer around explanation behavior.
Use FeatBit when the explanation experience needs:
- targeting by internal team, beta segment, plan, region, risk tier, or environment;
- multivariate control over attribution method, detail level, or UI format;
- staged percentage rollout as explanation evidence improves;
- fast rollback if guardrails fail;
- exposure and outcome events for release decisions;
- auditability around who changed the rollout;
- lifecycle cleanup after the explanation decision is made.
That is the operational role of feature flags in explainable AI: they do not make the explanation correct by themselves. They make explanation rollout controlled, observable, reversible, and easier to govern.
Bottom Line
Feature attribution for AI explanations is not only a model-interpretability topic. It is a production release topic.
Compute the attribution with the method your model and domain require. Release the explanation with the same discipline you would use for any risky AI behavior: define the decision, target the first audience, measure outcomes and guardrails, preserve rollback, and clean up after the evidence is clear.
Source Notes
- Feature attribution method context: Scott Lundberg and Su-In Lee's paper, A Unified Approach to Interpreting Model Predictions, introduces SHAP and describes feature-importance values for individual predictions.
- Local explanation method context: Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin's paper, "Why Should I Trust You?": Explaining the Predictions of Any Classifier, is cited for the LIME explanation framing.
- AI risk context: NIST's AI Risk Management Framework supports the view that AI evaluation and trustworthiness should be managed in the system's context of use.
- AI telemetry context: OpenTelemetry's Generative AI semantic conventions are useful background for teams standardizing AI request, model, and output telemetry.
- FeatBit implementation context: AI control layer, safe AI deployment, AI experimentation, feature flag lifecycle management, targeting rules, percentage rollouts, A/B testing with feature flags, flag insights, and the Track Insights API support the release-control workflow described here.
- This article does not claim that feature attribution proves causality, fairness, compliance, or model correctness. It explains how to control and evaluate the release of attribution-based explanation experiences.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it shows the article's core idea: AI attribution explanations connected to feature flag release control. - Use
attribution-release-loop.pngnear the opening because it visualizes candidate, internal, canary, decision, rollback, and cleanup stages. - Use
runtime-evidence-path.pngin the evidence section because it shows how runtime explanation behavior joins to exposure, outcome, audit, and release-decision records.