Offline Eval to Shadow Test to Canary Rollout: An AI Release Playbook
Offline evaluation, shadow testing, and canary rollout answer different release questions. Offline eval asks, "Does this AI change look better against known cases?" Shadow testing asks, "Does it behave safely against real production traffic without affecting users?" Canary rollout asks, "Does it improve the real product outcome for a controlled audience?" Treating them as one generic evaluation step creates a release gap: teams either over-trust lab scores or expose users before they have enough operational evidence.
For AI systems, the safer path is a staged release decision loop. Keep each stage small, define the evidence required to leave it, and make the production stages reversible with feature flags. FeatBit's point of view is simple: AI changes are runtime decisions, not only model or prompt artifacts. A prompt, model route, retrieval rule, agent tool policy, or generated-code path should move through controlled exposure before it becomes the default behavior.
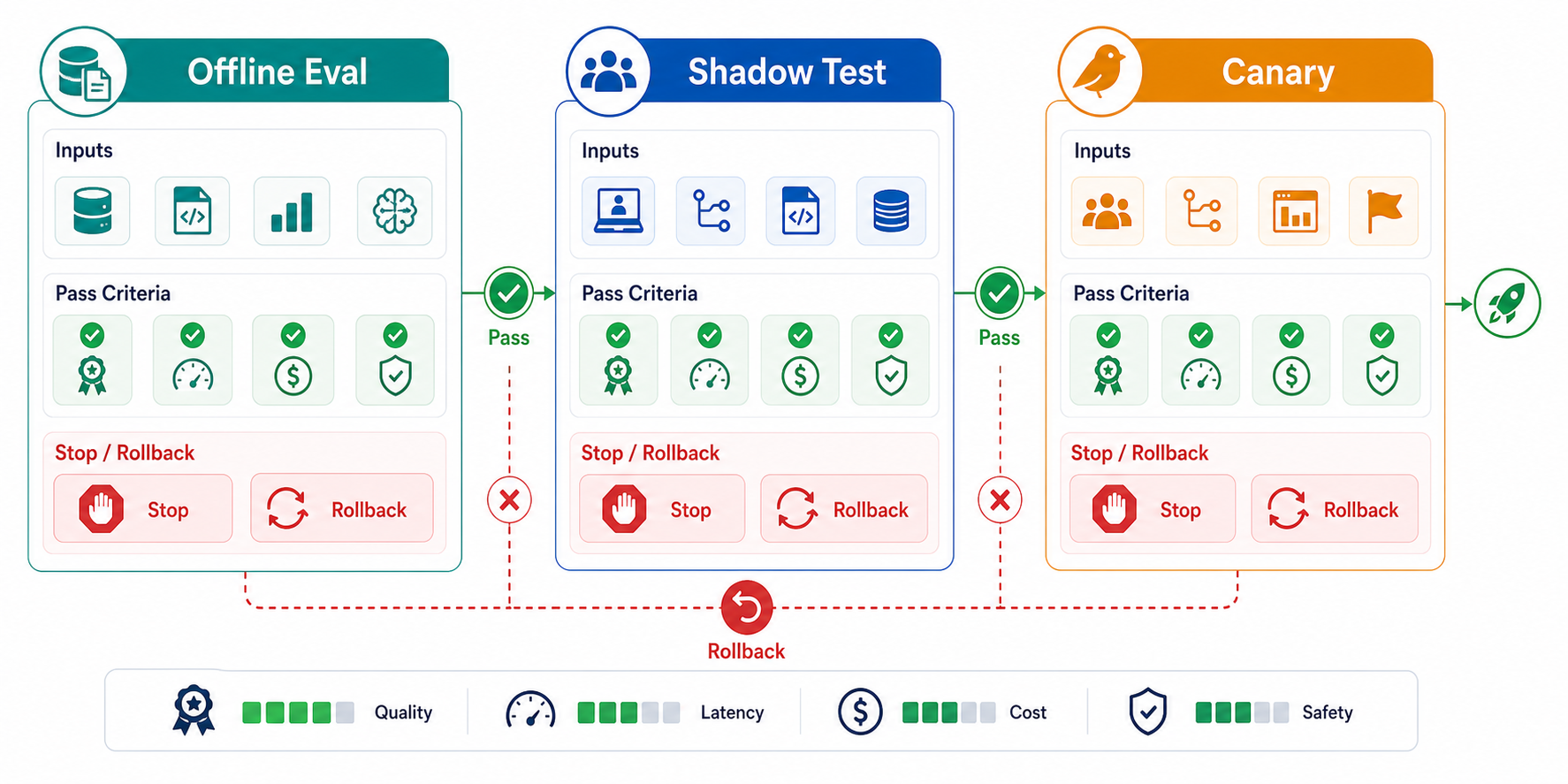
The Three Stages Answer Different Questions
An offline eval is not a canary, and a canary is not a substitute for offline eval. Each stage reduces a different kind of uncertainty.
| Stage | Main question | Traffic source | User impact | Best evidence |
|---|---|---|---|---|
| Offline eval | Does the new behavior pass known quality cases? | Curated datasets, historical examples, synthetic tests | None | Quality scores, regression cases, rubric judgments, latency and cost estimates |
| Shadow test | What happens on real production inputs? | Mirrored or replayed production requests | None if responses are not shown to users | Safety failures, routing gaps, latency, cost, observability gaps, unexpected input patterns |
| Canary rollout | Does the change improve real outcomes? | A targeted slice of live users | Controlled and reversible | Product metrics, guardrails, user behavior, support signals, rollback evidence |
This distinction matters because AI quality is context-sensitive. A new prompt can score well on a benchmark and still fail on rare customer phrasing. A model route can look acceptable in replay but increase latency under production load. An agent policy can pass task-completion tests and still invoke a tool too often when real users ask ambiguous questions.
The goal is not to add ceremony. The goal is to stop using one kind of evidence to answer every release question.
Stage 1: Offline Eval Finds Regression Before Production
Start with offline evaluation when the AI change can be judged against examples you already understand. This stage is useful for prompt revisions, model swaps, classifier changes, retrieval configuration, tool-selection policies, and generated-code paths that can be exercised with repeatable test cases.
Good offline evals include:
- A baseline version and a candidate version.
- A representative dataset that includes routine cases, edge cases, and known failure modes.
- A scoring method that fits the task, such as exact match, rubric-based judgment, human review, structured assertions, or cost and latency thresholds.
- A regression list that names which cases got worse, not only the average score.
- A decision threshold for moving to shadow testing.
OpenAI's eval guidance frames evaluations as a way to measure model behavior against task-specific criteria before deployment, and Google Cloud's generative AI evaluation guidance similarly separates model evaluation from the act of serving a model in production. Those sources are useful reminders: offline eval is a measurement step, not a release step.
For release decisions, the offline eval exit rule should be explicit:
Move to shadow test only if:
- Candidate quality is equal or better on the primary rubric.
- No severity-1 regression appears in the protected case set.
- Latency and cost estimates remain within guardrail limits.
- The team can explain the remaining uncertainty that only production traffic can answer.
That last line is important. Offline eval should produce a known-risk note for the next stage. For example: "The candidate improved support-ticket summarization, but we have limited evidence on multilingual tickets and very long threads." That note becomes the shadow-test focus.
Stage 2: Shadow Test Uses Real Traffic Without User Exposure
A shadow test runs the candidate behavior on real or replayed production inputs while keeping the current behavior visible to users. The candidate output is logged, scored, compared, and observed, but it does not affect the customer experience.
Shadow testing is especially useful for AI changes because production inputs are messy. Users send incomplete prompts, mix intents, paste large documents, attach unusual metadata, and create load patterns that a curated eval set rarely captures. Shadow traffic helps reveal those realities before the candidate becomes visible.
A practical shadow test should capture:
- Candidate output and baseline output for the same request.
- Request attributes needed for analysis, such as user segment, locale, plan, channel, device, or task type.
- Latency, token cost, tool calls, retrieval hits, refusal or fallback behavior, and error rates.
- Quality labels when automated scoring or human review is available.
- Safety and policy failures that require immediate blocking.
Do not let the shadow stage become a hidden production launch. If the candidate response can write data, invoke tools, send notifications, update user-visible state, or consume expensive third-party resources, gate those side effects separately. For agentic systems, shadow mode often means allowing the agent to plan and score tool calls while blocking execution.
FeatBit's AI control layer perspective fits this stage: every AI decision point is a control surface. A flag can route candidate behavior only for shadow evaluation, while a separate guard can keep side effects disabled until the canary stage.
Stage 3: Canary Rollout Measures Business Outcomes
Canary rollout is the first stage where selected users actually receive the candidate behavior. That makes it more valuable and more dangerous. It is the right stage for measuring real product outcomes, but only after offline and shadow evidence has reduced obvious quality and operational risks.
For AI systems, a canary should be narrow enough to protect users and broad enough to answer the decision. Good canary dimensions include:
- Percentage rollout for a small, sticky user cohort.
- Targeted rollout for internal users, beta customers, a region, a plan tier, or a low-risk workflow.
- Variant rollout for prompt, model, retrieval, or agent-policy alternatives.
- Time-boxed exposure with a rollback review after each stage.
The canary should have one primary success metric and several guardrails. For example, an AI support assistant might use "successful ticket resolution without human escalation" as the primary metric, with guardrails for latency, cost per resolved ticket, user dissatisfaction, incorrect category assignment, and support-agent override rate.
FeatBit's AI safe deployment and LLM canary release pages describe this production-control idea in more detail: start with a small exposed segment, watch the metrics that matter, then expand, hold, or roll back. The difference in this playbook is that the canary is not the first test. It is the stage where you intentionally start measuring real user and business effects after earlier stages have filtered technical and quality failures.

Use Feature Flags as the Handoff Between Stages
The handoff between stages is where many AI releases lose discipline. A team may run an offline eval in a notebook, run a shadow test through a temporary script, and launch the canary through a config file. That makes the release hard to audit and harder to reverse.
Use feature flags to make the release path visible and controllable:
| Control | Offline eval | Shadow test | Canary rollout |
|---|---|---|---|
| Candidate selection | Record candidate version and baseline | Route mirrored traffic to candidate | Serve candidate to a controlled audience |
| Exposure | None | Invisible to users | Visible to targeted users |
| Metrics | Eval score, failures, estimated cost | Production input coverage, safety, latency, cost | Conversion, task success, retention, support, guardrails |
| Decision | Proceed, revise, or reject | Proceed, revise, block, or expand shadow | Expand, hold, roll back, or ship |
| Reversibility | Revert candidate artifact | Stop shadow route | Turn flag off or reduce rollout |
In FeatBit, the flag is not only a switch. It becomes release memory: who approved exposure, which segment saw the candidate, which metrics were watched, and why the team expanded or rolled back. The feature flag lifecycle management model is useful here because AI release flags should not become permanent clutter. They need owners, evidence, review windows, and cleanup rules.
If the change is part of a controlled experiment, connect exposure to metric events. FeatBit's experimentation workflow and Track Insights API are designed around evaluated variations and metric events, so teams can connect who saw which variant with the outcome they care about.
A Practical Release Gate Template
Teams do not need a complicated governance board for every AI change. They need a small, repeatable gate that forces the right evidence at the right time.
Use this template before moving from one stage to the next:
Change:
- Candidate artifact:
- Baseline artifact:
- Owner:
- Primary user journey:
Offline eval:
- Dataset:
- Protected cases:
- Primary score:
- Regression findings:
- Cost and latency estimate:
- Decision:
Shadow test:
- Traffic source:
- Side effects blocked:
- Observability fields:
- Unexpected input patterns:
- Safety or reliability findings:
- Decision:
Canary rollout:
- Target segment:
- Initial percentage:
- Primary success metric:
- Guardrail metrics:
- Expansion rule:
- Rollback rule:
- Cleanup plan:
The template keeps the team honest about the difference between "the model looked better" and "the product got better." It also gives engineering, product, data, and support teams a shared release language.
Common Mistakes
The most common mistake is skipping shadow testing because offline eval scores look strong. This is risky for AI systems that depend on live context, retrieval freshness, tool permissions, user phrasing, or unpredictable load.
A second mistake is treating canary metrics as only technical metrics. Latency and error rate matter, but they rarely prove the AI change is better for the business. Add outcome metrics such as resolved tasks, completed workflows, retained sessions, reduced support escalation, or accepted suggestions.
A third mistake is giving the canary no rollback rule. "We will monitor it" is not a rollback rule. A rollback rule names the metric, threshold, time window, and action. For example: "If the candidate increases escalation rate by more than 5 percent for two consecutive hourly windows, reduce rollout to 0 percent and keep shadow logging on for diagnosis." Avoid invented universal thresholds; choose numbers based on your own baseline and risk tolerance.
A fourth mistake is leaving the flag alive after the decision. Once the candidate becomes the default, either convert the flag into a long-lived operational control with a clear owner or remove it through the lifecycle process.
Where FeatBit Fits
FeatBit helps teams turn AI release evaluation into a controlled production workflow:
- Use targeting and percentage rollout to expose candidate AI behavior gradually.
- Use flags to separate deployment from release, so a prompt, model route, retrieval configuration, or agent behavior can be changed without redeploying the application.
- Use experimentation and metric events when the canary needs a measured outcome rather than only technical monitoring.
- Use rollback controls to reduce exposure quickly when guardrails fail.
- Use lifecycle practices so AI release flags have owners, evidence, and cleanup paths.
This is the operational reason to connect offline eval, shadow testing, and canary rollout. Offline eval reduces known quality risk. Shadow test reduces production-context risk. Canary rollout measures real user and business impact. Feature flags make the transitions explicit, reversible, and auditable.
Source Notes
- OpenAI documentation on model evaluations supports the idea that teams should define task-specific evaluation criteria before relying on a model change.
- Google Cloud documentation on generative AI evaluation is a useful external reference for separating model evaluation from production deployment decisions.
- FeatBit's AI safe deployment, LLM canary release, AI experimentation, and feature flag lifecycle management pages provide the FeatBit-specific release-control context behind this playbook.
Next Step
If your team is preparing an AI prompt, model, RAG, or agent behavior change, start by writing the three stage gates before you change production traffic. Then use FeatBit to make the shadow route, canary segment, metric collection, rollback rule, and cleanup plan visible in the same release decision path.