Should You Run a Shadow Test Before an A/B Test?
Run a shadow test before an A/B test when the change can be evaluated on real production inputs without changing what users see, and when the first risk is quality, reliability, latency, cost, or instrumentation failure. Do not use a shadow test to decide business impact. Use it to decide whether the candidate is ready for live exposure.
That distinction matters for AI changes. A prompt, model route, retrieval profile, ranking function, or agent workflow can look acceptable in offline evaluation but fail on messy production inputs. A shadow test lets the candidate process those inputs while the current production behavior still serves the user. The A/B test comes later, when you need to compare user-visible outcomes between control and treatment.

The Short Answer
A shadow test is useful before an A/B test when you need a no-user-impact evidence gate.
Use it when:
- the candidate behavior is risky enough that direct exposure feels premature;
- the output can be compared to the current behavior without being shown to users;
- production input distribution matters more than synthetic test cases;
- cost, latency, fallback, or provider reliability is still uncertain;
- exposure and outcome telemetry need to be checked before the experiment starts.
Skip it when the change only makes sense after users interact with it. A new checkout layout, onboarding page, pricing message, or product workflow usually needs visible exposure because the outcome depends on user behavior. In that case, start with internal testing, targeted rollout, or a small canary instead of pretending a shadow run can answer an interaction question.
FeatBit's broader progressive rollout patterns cover internal-first, canary, percentage, segment-targeted, and time-gated exposure. This article focuses on the step before exposure: whether a shadow test should prove that the candidate is ready to become a treatment.
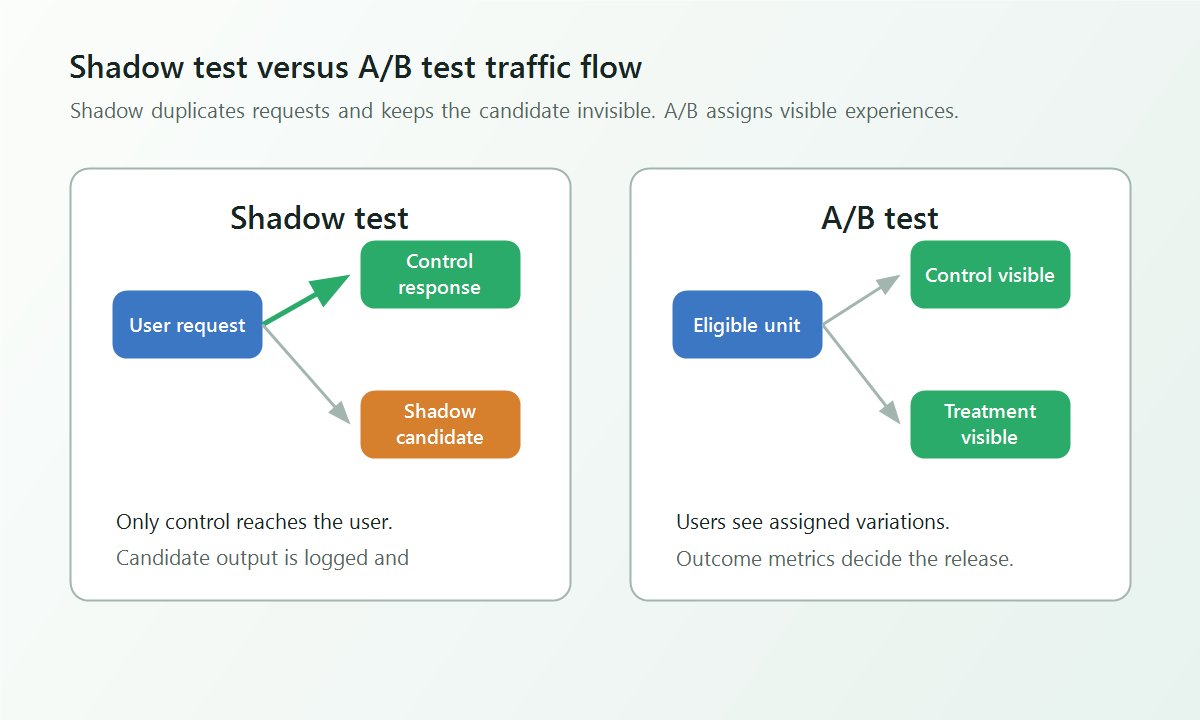
Shadow Test Versus A/B Test
A shadow test and an A/B test answer different release questions.
| Method | User sees | Best question | Weak question | Typical decision |
|---|---|---|---|---|
| Shadow test | Control behavior only | Can the candidate run safely on production-like inputs? | Does the candidate improve user behavior? | fix, discard, or proceed to exposure |
| Canary | A small live segment sees treatment | Is limited exposure safe enough to continue? | What is the full business lift? | continue, pause, or roll back |
| A/B test | Control and treatment are both visible to assigned users | Does treatment improve the committed metric without guardrail harm? | Is the candidate technically ready? | ship treatment, keep control, or iterate |
Istio describes traffic mirroring, also called shadowing, as sending a copy of live traffic to a mirrored service while normal traffic continues to the primary service. Amazon SageMaker AI documents shadow variants as a way to validate a candidate model serving stack before promotion. Those are useful engineering patterns, but they still do not create a user-visible treatment group.
The A/B test is different. Experiment platforms such as Statsig, LaunchDarkly, GrowthBook, and Optimizely describe experiments in terms of variations, metrics, and measured impact. That is the job a shadow test cannot do alone: compare outcomes caused by different visible experiences.
What A Shadow Test Can Prove
A well-designed shadow test can produce strong pre-exposure evidence.
For an AI system, it can answer:
- Does the candidate model, prompt, retrieval profile, or agent workflow complete under real input shape?
- Does it stay within latency and cost budgets?
- Does it call tools, databases, or external services safely?
- Does it produce severe quality failures on known risky segments?
- Does fallback behavior work when the candidate fails?
- Are logs, exposure records, and diagnostic fields complete enough for a later experiment?
It can also reveal whether the candidate is even comparable. If the current model and candidate model return outputs with different schemas, missing citations, incompatible confidence fields, or different handoff states, the team should fix that before user exposure.
This is why shadow testing is often more valuable for AI changes than for simple UI changes. AI behavior may fail because of real prompts, long-tail accounts, retrieval gaps, provider errors, tool side effects, or cost spikes that were not represented in offline evaluation.
What A Shadow Test Cannot Prove
A shadow test cannot prove user preference, conversion lift, retention impact, support deflection, or satisfaction. Users do not experience the candidate, so their behavior cannot respond to it.
It also cannot fully prove safety when the candidate has side effects. If an agent would send email, update a record, charge a payment method, create a ticket, or call a write API, the shadow path must block or sandbox those actions. Otherwise the shadow test is not truly no-impact.
Treat these as hard limits:
| Claim | Can a shadow test support it? | Why |
|---|---|---|
| The candidate stays within latency and cost budgets | Yes | It runs on production-like inputs and can be measured |
| The candidate output matches quality rules | Partly | You can review outputs, but users do not react to them |
| The candidate improves conversion | No | Users never see the candidate |
| The candidate reduces support tickets | No | The production response still drives user behavior |
| The candidate is safe for tool use | Partly | Read-only paths can be checked; write paths need sandboxing |
| The experiment telemetry is ready | Yes | You can verify identifiers, variants, and event shape before exposure |
This boundary keeps the team from making the common mistake: promoting a candidate because the shadow result looked cleaner than production. Cleaner output is eligibility evidence. It is not the release decision.
A Decision Rule For Running Shadow First
Use a shadow test before the A/B test when at least one of these conditions is true:
| Condition | Example | Why shadow helps |
|---|---|---|
| AI output quality is uncertain | new prompt, model, reranker, summarizer, or classifier | compare candidate output against current output before users see it |
| Production input shape is hard to simulate | long support threads, account-specific documents, noisy search queries | run against real input distribution without changing the response |
| Runtime cost may change materially | larger model, more tool calls, heavier retrieval | measure cost per request before broad exposure |
| Latency may affect experience | chat, search, checkout assistant, agent workflow | measure p95 and timeout behavior without user-visible delay |
| Side effects need containment | agent tool use, ticket creation, CRM update | confirm read-only or sandbox behavior before live permission |
| Instrumentation is new | exposure events, metric events, tracing fields | validate joinability before the A/B readout depends on it |
Skip shadow and move to limited exposure when:
- the candidate is already low-risk and covered by strong automated tests;
- the key outcome depends on user choice or perception;
- mirroring production traffic would create privacy, security, cost, or infrastructure risk;
- the team cannot safely suppress side effects;
- the shadow result would not change the decision.
The last point is important. If the team will run the same A/B test regardless of shadow findings, the shadow test is only ceremony. Write the gate first, then run it.
How To Design A Useful Shadow Test
Start with a release hypothesis, then define the pre-exposure gate.
shadow_test:
change: route support-answer requests through candidate_retrieval_v2
user_visible_response: current_retrieval
shadow_response: candidate_retrieval_v2
traffic_sample: 20_percent_of_eligible_requests
duration: 48_hours
block_side_effects:
- ticket_write
- customer_email
- account_update
compare:
- output_schema_valid
- citation_coverage
- severe_quality_failure_rate
- p95_latency
- estimated_cost_per_request
- fallback_rate
proceed_to_canary_when:
- no severity_one_quality_failures
- p95_latency_within_budget
- cost_per_request_within_budget
- telemetry_join_rate_above_threshold
stop_when:
- side_effect_suppression_fails
- candidate_schema_mismatch
- severe_segment_failure
The gate should be strict because the shadow test is not trying to maximize learning. It is trying to avoid preventable exposure. A candidate that fails shadow does not need a statistically elegant rejection. It needs repair, narrower scope, or removal from the release path.
Move From Shadow To A/B Testing
Once the shadow gate passes, the release question changes from "Can this candidate run?" to "Should users receive this candidate?"

Move to a live experiment when:
- The candidate has passed the shadow gate.
- The assignment unit is clear: user, account, conversation, workflow, or request.
- The primary metric is written before exposure starts.
- Guardrails cover quality, latency, cost, reliability, support load, and segment harm.
- Exposure events are emitted when the candidate behavior is actually used.
- Outcome events can be joined to exposure by unit and variation.
- Rollback can return traffic to control without redeploying code.
FeatBit's measurement design guidance is useful here because it separates the metric that decides the experiment from guardrails that stop expansion. For AI changes, that separation prevents a candidate from winning one business metric while quietly damaging reliability, cost, or trust.
For a staged rollout after shadow, use a small canary before the balanced A/B split if the candidate still carries operational risk. The related FeatBit guide on 5% canary, 50% A/B test, and 100% rollout covers that later sequence.
How FeatBit Fits The Workflow
FeatBit is not a traffic mirroring proxy. It is the release-decision control plane around the candidate.
In practice, FeatBit can help a team:
- name the runtime decision as a feature flag or multivariate flag;
- keep the candidate disabled for users while shadow infrastructure evaluates it;
- target internal users, accounts, or low-risk segments when exposure begins;
- move from 1% canary to a balanced A/B test with stable variation assignment;
- connect exposure and metric events through the Track Insights API;
- roll back treatment without redeploying application code;
- preserve audit history and cleanup expectations after the decision.
The same flag should not be asked to do everything forever. During shadow, it may represent candidate eligibility or route selection inside infrastructure. During A/B testing, it represents visible treatment assignment. After rollout, it should either be removed as a temporary experiment flag or converted into a clearly named operational control. FeatBit's feature flag lifecycle management model helps keep that release memory from becoming stale code.
For AI-specific release control, FeatBit's safe AI deployment and AI experimentation pages expand the same idea: expose risky behavior deliberately, measure it with guardrails, and keep rollback available while evidence is incomplete.
Common Mistakes
Calling a shadow test an A/B test. If users do not see the candidate, it is not measuring user behavior caused by the candidate.
Letting the shadow path create side effects. A no-impact test must block writes, notifications, irreversible tool calls, and downstream workflow changes unless they are sandboxed.
Comparing aggregate quality only. Segment failures matter. Review long-tail accounts, languages, document types, traffic sources, and risk tiers before exposure.
Ignoring infrastructure cost. Shadow traffic can double candidate compute for the sampled path. Measure cost and capacity, especially for large models and heavy retrieval.
Skipping telemetry validation. A clean shadow run without joinable event IDs does not prepare the A/B test. It only proves the candidate can run silently.
Shipping from shadow. A shadow pass means "ready for controlled exposure." It does not mean "ready for default."
Practical Checklist
Before deciding whether to run shadow first, answer these questions:
- Can the candidate process production inputs without changing what users see?
- Can all side effects be blocked, mocked, or sandboxed?
- Will shadow evidence change whether the candidate advances?
- Are latency, cost, fallback, and quality measurable in the shadow path?
- Is the assignment unit for the later A/B test already defined?
- Are exposure and outcome events joinable by experiment unit and variation?
- Is there a clear gate for canary, A/B test, rollback, or repair?
If most answers are yes, run the shadow test before the A/B test. If the answer to side-effect containment is no, do not shadow real production traffic until the architecture is safe. If the answer to user-visible learning is the only thing that matters, skip shadow and use targeted live exposure with rollback.
The practical rule is simple: shadow testing qualifies the candidate; A/B testing decides the outcome. Use both when the risk justifies the extra gate.
Source Notes
- Shadow testing context: Amazon SageMaker AI documents shadow variants for validating candidate model serving stacks before promotion, and Istio documents traffic mirroring as shadowing traffic to another service.
- Experimentation category context: Statsig's feature gates versus experiments guide distinguishes gradual rollout from quantified experiment lift, LaunchDarkly documents creating experiments with metrics, GrowthBook positions feature flags and experiments together in its documentation, and Optimizely documents choosing metrics for Feature Experimentation. These sources are used as category context, not vendor rankings.
- FeatBit implementation context: targeted progressive delivery, percentage rollouts, A/B testing with feature flags, Track Insights API, measurement design, and feature flag lifecycle management support the release-control workflow described here.
- Internal reader journey: continue with AI-native experimentation and feature flags, A/B testing AI models for business impact, and 5% canary to 50% A/B to 100% rollout.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the shadow-to-experiment decision path. - Use
decision-ladder.pngnear the opening because it shows where shadow testing sits between offline evaluation and live exposure. - Use
shadow-vs-ab-flow.pngin the comparison section because it makes the no-user-impact boundary explicit. - Use
evidence-gates.pngbefore the A/B transition because it shows which evidence belongs at each stage without replacing the crawlable tables.