Shadow Testing vs A/B Testing for Models: What Is the Difference?
Shadow testing and A/B testing answer different questions about a model change. A shadow test asks whether a candidate model can run safely on real production inputs without changing the user experience. An A/B test asks whether users who actually receive the candidate model get a better product outcome than users who stay on the control model.
The shortest practical distinction is this: shadow testing qualifies the model for exposure; A/B testing decides whether the exposed model should win.
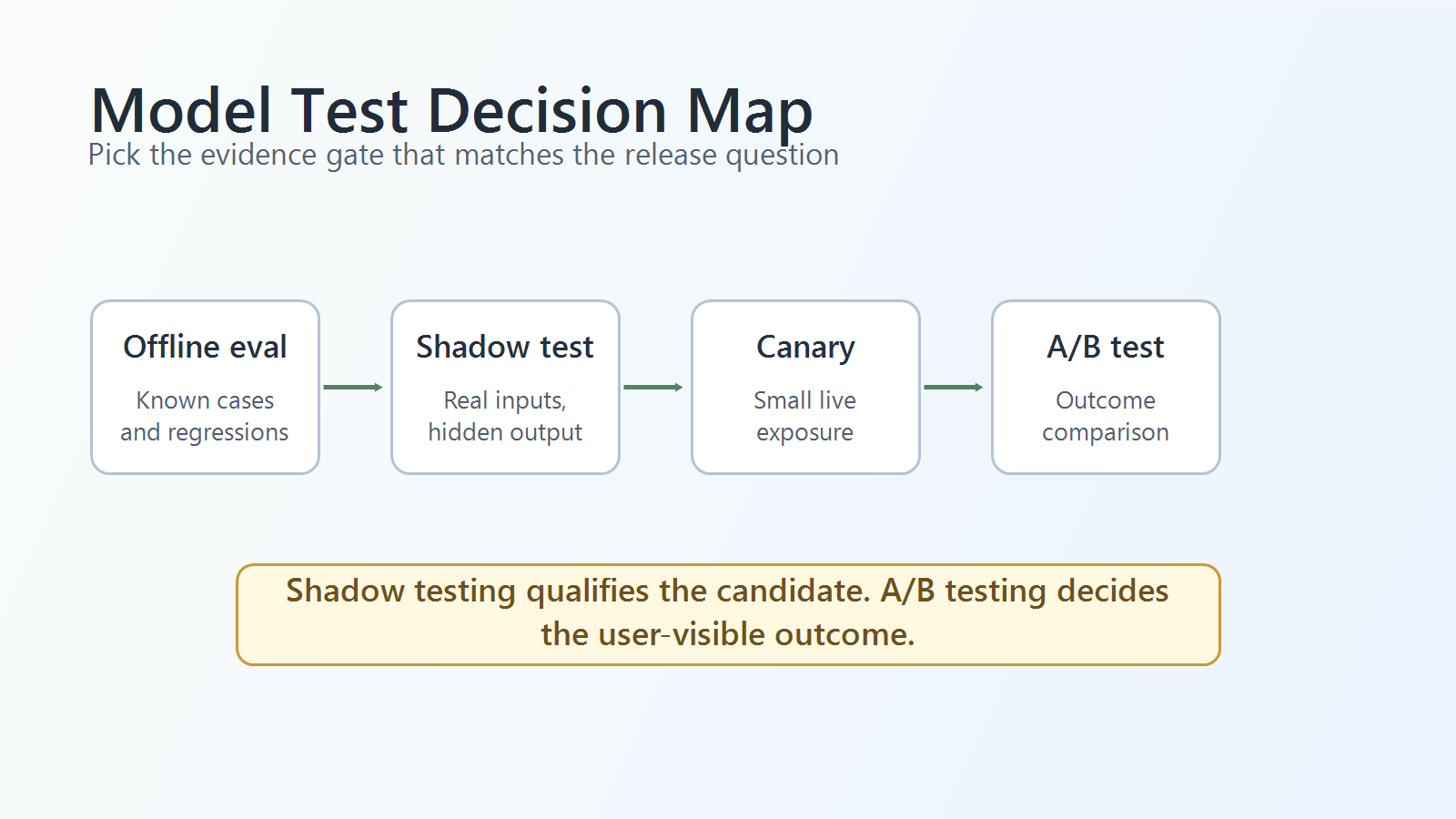
The Core Difference
In a shadow test, the current production model still serves the user. The candidate model receives a copy of the same request, produces an output, and records telemetry for review. The candidate output is not returned to the user.
In an A/B test, eligible users, accounts, sessions, or workflows are assigned to a control model or candidate model. The assigned model affects the live experience, and the team compares outcomes between groups.
| Question | Shadow testing | A/B testing |
|---|---|---|
| Does the user see the candidate model? | No | Yes, for treatment traffic |
| What is the main purpose? | Production readiness and risk discovery | Measured product or business impact |
| What traffic does it use? | Mirrored or replayed production inputs | Live assigned users or experiment units |
| What can it prove well? | Latency, cost, reliability, schema fit, severe quality issues, observability gaps | Conversion, task success, retention, support deflection, user behavior, guardrail impact |
| What can it not prove? | User preference or business lift | Whether the model was safe before exposure |
| Typical decision | Repair, reject, proceed to exposure | Ship, pause, roll back, or iterate |
This distinction is especially important for AI models because quality is not only a lab score. A model route can look strong in offline evaluation, then fail on long-tail prompts, account-specific documents, provider latency, tool calls, retrieval gaps, or cost patterns that appear only under production traffic.
How The Traffic Flow Changes
The traffic pattern is the easiest way to keep the methods separate.
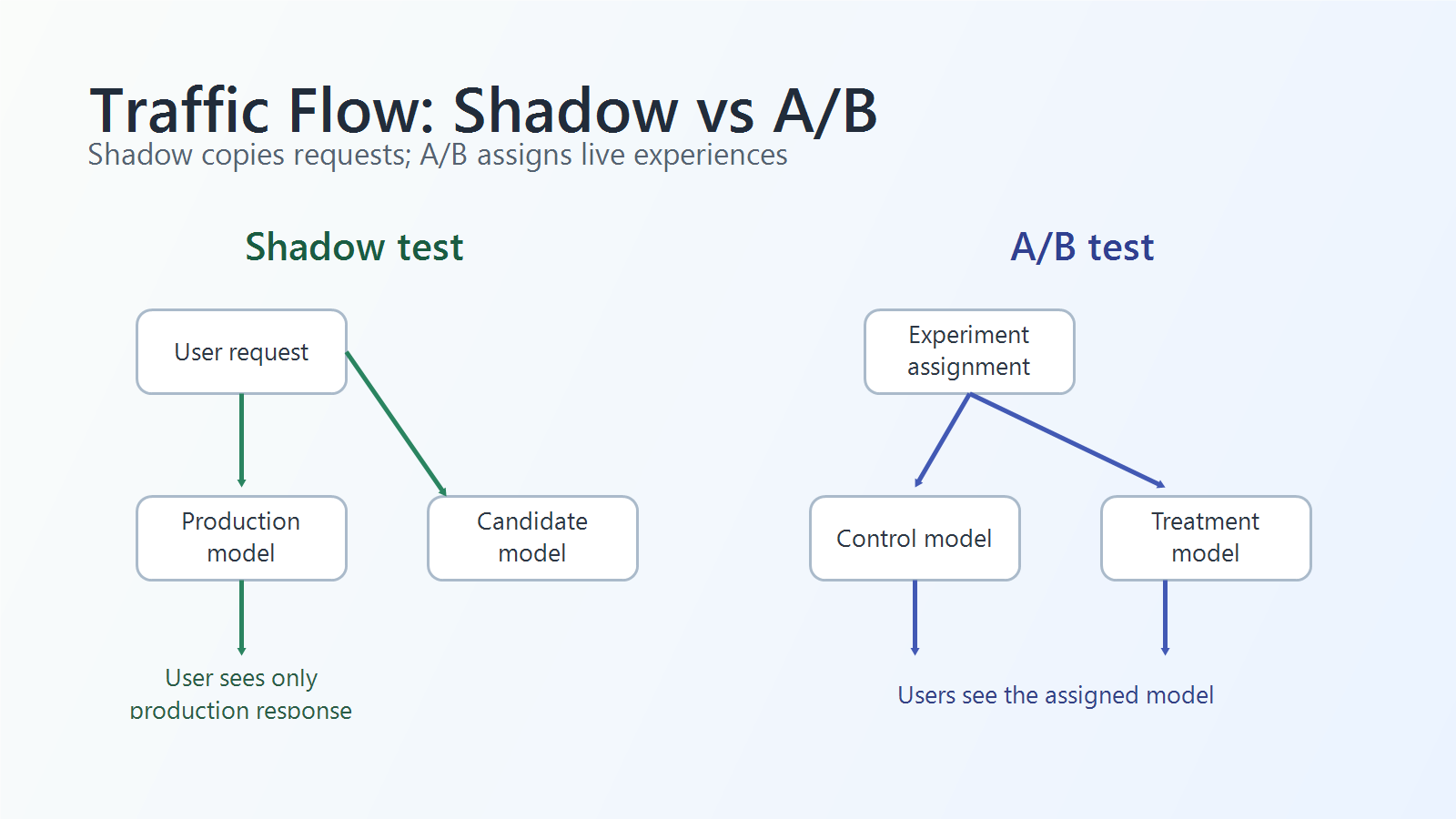
In shadow testing, the production request path remains authoritative:
- A user request reaches the application.
- The current production model generates the user-visible response.
- A copied request is sent to the candidate model.
- The candidate output is logged, scored, compared, or reviewed.
- Any side effects from the candidate path are blocked or sandboxed.
AWS SageMaker AI describes model shadow deployments as a way to validate a candidate component of the model serving stack before promotion, with production and shadow variants configured together. Istio's traffic mirroring documentation uses the same general infrastructure idea: a copy of live traffic can be sent to another service outside the critical request path.
In A/B testing, assignment is part of the live product:
- The application evaluates the experiment assignment.
- The user, account, session, conversation, or workflow is routed to a control or treatment model.
- The assigned model generates the user-visible response.
- Exposure and outcome events are recorded.
- The team compares the primary metric and guardrails before deciding whether to expand or roll back.
Experiment platforms describe this as a measurement problem, not only a routing problem. Statsig's guide on feature gates versus experiments separates gradual exposure from quantified lift across metrics. GrowthBook similarly connects feature flags and experiments as rollout and measurement tools. For model teams, the category lesson is clear: the routing decision and the metric plan have to be designed together.
When Shadow Testing Is The Right First Step
Use shadow testing when the candidate model needs real production input shape, but user exposure would be premature.
Good shadow-test candidates include:
- a new model endpoint for support answers, search, summarization, classification, or recommendations;
- a model route that may increase p95 latency, token cost, fallback rate, or provider errors;
- a retrieval or reranking model that needs live query distribution before exposure;
- an agent model that may propose tool calls, but should not execute side effects yet;
- a model integration where request schema, response schema, tracing, and fallback behavior are still being validated.
The useful shadow metrics are operational and quality-focused:
| Metric family | Examples |
|---|---|
| Runtime health | p95 latency, timeout rate, provider error rate, fallback rate |
| Cost | tokens per request, inference cost per task, capacity pressure |
| Output shape | schema validity, citation presence, required fields, confidence fields |
| Quality review | severe failure rate, hallucination review flags, policy failure flags |
| Segment risk | failures by account type, locale, document class, traffic source, workflow |
| Instrumentation | trace completeness, exposure field readiness, joinable request IDs |
Shadow testing is not automatically safe. If the candidate path can send messages, update records, trigger payments, create tickets, or call write APIs, the shadow path must block or sandbox those actions. Otherwise the test is changing production even if the model response is hidden.
When A/B Testing Is The Right Step
Use A/B testing when the real question depends on what users experience.
Examples:
- Does the candidate support model resolve more tickets without human escalation?
- Does a new recommendation model increase completed purchases without hurting returns?
- Does a search ranking model improve successful sessions without increasing no-result exits?
- Does a smaller model reduce cost while keeping task completion and quality inside guardrails?
- Does a model route improve activation for one segment but harm another?
An A/B test needs a primary metric, guardrails, stable assignment, and rollback before traffic starts. The primary metric decides whether the model is worth shipping. Guardrails decide whether the test should pause or roll back even if the primary metric improves.
For example:
model_experiment:
decision: choose the default support answer model
unit: account
control: current_support_model
treatment: candidate_support_model_b
primary_metric: resolved_without_human_escalation
guardrails:
- p95_latency
- cost_per_resolved_case
- hallucination_review_rate
- customer_complaint_rate
rollback_when:
- severe_quality_failure_detected
- latency_guardrail_breached
- exposure_or_outcome_events_missing
FeatBit's measurement design guidance is useful here because it separates the success metric from the guardrails that protect the release. For implementation, FeatBit's docs on A/B testing with feature flags, targeting rules, percentage rollouts, and the Track Insights API cover the primitives behind assignment, exposure, and metric events.
The Evidence Contract Is Different
The easiest mistake is to use evidence from one method to make the decision that belongs to the other.
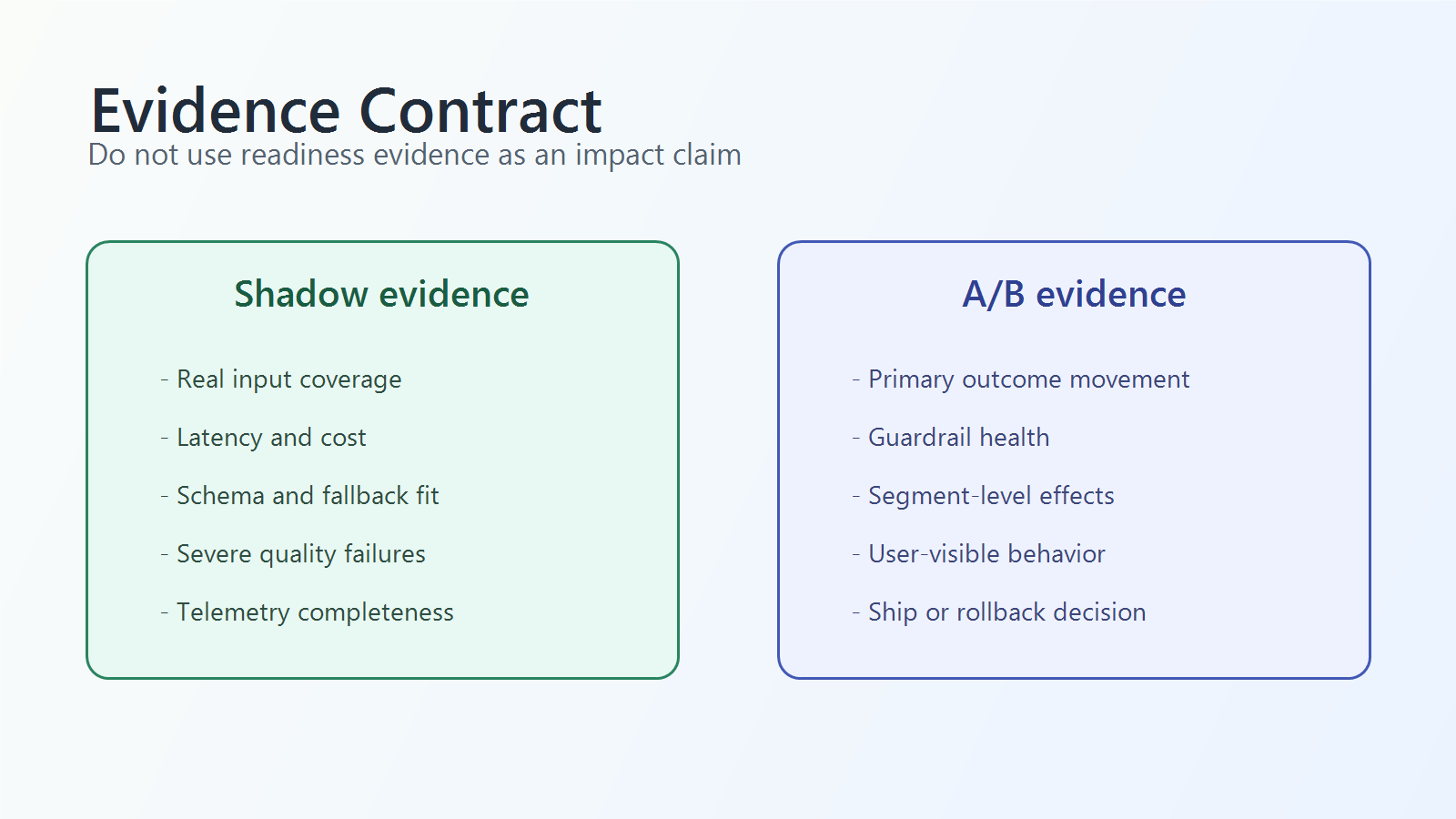
A shadow test can say:
- the candidate model processed real production inputs;
- the model stayed within latency and cost limits;
- severe output failures did or did not appear in reviewed samples;
- side effects were successfully blocked;
- telemetry fields are complete enough for later exposure analysis.
A shadow test cannot honestly say:
- users prefer the candidate model;
- the candidate improves conversion, retention, task completion, or support deflection;
- the model should become the default for everyone.
An A/B test can say:
- assigned users who saw the treatment changed a measured outcome;
- the business metric improved, stayed flat, or got worse;
- guardrails were healthy or unhealthy under live exposure;
- the treatment should expand, pause, roll back, or be revised.
An A/B test should not be used as the first proof that the model can run. If the candidate model has not passed offline checks, shadow validation, internal exposure, or another readiness gate, then the experiment is carrying preventable technical risk.
Use Both When The Risk Justifies It
For many model changes, the safer sequence is not either-or. It is staged evidence:
- Offline evaluation checks known examples and regression cases.
- Shadow testing checks production input shape without user-visible impact.
- Internal or canary exposure checks early live behavior on a small audience.
- A/B testing compares the committed product metric and guardrails.
- Rollout or rollback turns the evidence into a release decision.
This does not mean every model edit needs every stage. A low-risk routing change may go from offline evaluation to a small canary. A high-risk agent model with tool access may need shadow testing before any live capability is enabled. The right gate depends on blast radius, side effects, reversibility, input diversity, and the cost of a bad decision.
For the sequencing question, use the related FeatBit guide on whether to run a shadow test before an A/B test. For the model-specific experiment design, see A/B testing for AI models. For broader release control across prompts, models, retrieval, and agent strategies, FeatBit's AI experimentation page explains the full operating model.
How FeatBit Fits The Model Release Workflow
FeatBit is not a traffic mirroring proxy. It is the release-decision control plane around model exposure.
In practice, FeatBit can help teams:
- represent model route selection as a multivariate feature flag;
- keep a candidate disabled for users while shadow infrastructure validates it;
- target internal users, beta accounts, regions, or low-risk segments before broader exposure;
- run stable A/B assignment when users actually see the candidate model;
- connect exposure and metric events for experimentation;
- roll back the model route without redeploying application code;
- preserve audit history and cleanup expectations after the decision.
That last point matters. A temporary model experiment flag should not become permanent clutter. Once the winning model becomes default, remove the stale route or convert the flag into a clearly named operational control. FeatBit's feature flag lifecycle management model helps keep model release memory from turning into unmanaged runtime logic.
Common Mistakes
Calling shadow testing an A/B test. If users never see the candidate model, user behavior cannot prove the candidate's impact.
Shipping directly from shadow. A clean shadow run means the model is eligible for controlled exposure. It does not mean the model improved the product.
Running an A/B test before readiness is known. Live experiments should measure impact, not discover that the candidate route times out, breaks schema, or calls unsafe tools.
Using request-level assignment when the product needs continuity. For chat, support, agent workflows, and B2B accounts, randomizing each request can create inconsistent experiences and unreliable results.
Ignoring cost and latency. A model can improve a primary metric while becoming too slow or too expensive to scale.
Forgetting cleanup. After the release decision, remove temporary branches, stale model aliases, and old experiment flags unless they intentionally become operational controls.
Practical Decision Rule
Use shadow testing when the question is:
Can this candidate model run safely on real production inputs without affecting users?
Use A/B testing when the question is:
Does this candidate model improve the product outcome for users who actually receive it?
Use both when the model is promising but risky: shadow first to qualify the candidate, then A/B test to decide whether the model should win.
Source Notes
- Shadow testing context: Amazon SageMaker AI documents model shadow deployments for validating candidate model serving components before promotion, and Istio documents traffic mirroring as sending copied live traffic to a mirrored service outside the primary request path.
- Experimentation category context: Statsig's feature gates versus experiments guide distinguishes gradual rollout from quantified experiment lift, and GrowthBook's feature flagging product page describes converting flags to experiments with metric tracking. These sources are used for category context, not vendor rankings.
- FeatBit implementation context: A/B testing with feature flags, targeting rules, percentage rollouts, Track Insights API, AI experimentation, measurement design, and feature flag lifecycle management support the release-control workflow described here.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the model readiness versus impact distinction. - Use
model-testing-decision-map.pngnear the opening because it gives readers the direct answer before the detailed comparison. - Use
shadow-vs-ab-model-flow.pngin the traffic-flow section because the routing difference is the core concept. - Use
evidence-contract.pngin the evidence section because it separates readiness claims from impact claims in crawlable-supporting visual form.