Time to First Token Monitoring for AI Rollouts
Time to first token monitoring tracks how long a user waits before a streamed AI response begins. For chat, support, coding, search, and agent workflows, that first visible token often decides whether the experience feels alive or stalled.
The release-control mistake is to treat time to first token, or TTFT, as only an infrastructure metric. During an AI rollout, TTFT should be joined to the flag variation that selected the prompt, model route, retrieval profile, guardrail mode, or fallback path. Then the team can ask a sharper question: is this candidate AI behavior still responsive enough to expand?

What Time To First Token Measures
TTFT measures elapsed time from the product's request start to the first token or first streamed chunk visible to the caller. It is not the same as end-to-end latency.
| Metric | What it captures | Release question |
|---|---|---|
| Time to first token | request setup, routing, retrieval, safety checks, provider queueing, and initial generation | Does the experience start quickly enough? |
| Tokens per second | generation throughput after streaming begins | Does the answer continue at an acceptable pace? |
| End-to-end latency | full time until the response, tool step, or workflow completes | Is the whole task fast enough? |
| Timeout rate | requests that do not produce a useful response in time | Should the route pause, fallback, or roll back? |
| Cost per successful task | spend after quality and outcome are considered | Is the route economically releasable? |
TTFT matters most when users are waiting in the interface. A batch summarizer may tolerate slow first output if the total job is predictable. A support assistant, agent copilot, or interactive code helper may feel broken if nothing appears quickly, even when the final answer is useful.
OpenAI's latency guidance separates several levers: process tokens faster, generate fewer tokens, use fewer input tokens, make fewer requests, parallelize work, make users wait less, and avoid using an LLM when a simpler method is enough. That is useful context for TTFT because the first token can be delayed by both model work and non-model work before the model starts responding.
Why TTFT Belongs In The Rollout Gate
AI teams often monitor average response time after launch. That is too late and too broad for controlled rollout.
TTFT should be visible while the rollout is still narrow because it can change when the team modifies:
- prompt length or prompt assembly;
- model provider, model family, or model route;
- retrieval depth, reranking, or document filtering;
- safety checks, moderation, or policy classification;
- tool planning before the first answer;
- fallback and retry behavior;
- streaming settings and response format.
A candidate route can have good final quality and still fail the release if users stare at a blank interface too long. Another route can start quickly but degrade answer quality or increase cost. The rollout gate should preserve those tradeoffs instead of hiding them behind a single "latency" chart.
Use TTFT as a guardrail, not the primary success metric. The primary metric might be case resolved, task completed, answer accepted, conversion, or escalation avoided. TTFT answers whether the candidate is viable enough for users while that outcome is being measured.
The Minimum TTFT Event Contract
Time to first token monitoring becomes useful when every event carries release context. The event should say what ran, who saw it, where it ran, and what action the team can take.

Use a contract like this before the first production canary:
ttft_monitoring_contract:
release_question: should_support_assistant_streaming_route_expand
flag_key: support_assistant_route
assignment_unit: conversation_id
candidate_variation: fast_streaming_v2
baseline_variation: stable_streaming_v1
event_start: product_request_received
event_stop: first_visible_token_or_first_stream_chunk
guardrails:
- p95_time_to_first_token_ms
- first_token_timeout_rate
- end_to_end_latency_ms
- estimated_cost_per_resolved_case
- human_correction_rate
release_actions:
warning: hold_expansion
breach: reduce_candidate_percentage
severe_breach: route_affected_segment_to_baseline
The threshold values should come from your product, not from a generic blog post. A customer support chat, an internal developer assistant, and a high-risk agent workflow can have different tolerance for delay.
The important part is that the metric is not floating alone. If TTFT breaches the gate, the owner knows whether to hold expansion, reduce a segment, switch the route profile, activate fallback, or roll back the candidate.
Instrument The Stream Where The User Waits
TTFT should start at the boundary that represents user waiting, not at a convenient internal timestamp. If the user clicks "ask" and the application spends time authenticating, evaluating a flag, fetching context, calling retrieval, applying policy checks, and then opening a model stream, all of that waiting can affect perceived responsiveness.
A practical event shape:
{
"event": "ai_first_token_observed",
"flagKey": "support_assistant_route",
"variation": "fast_streaming_v2",
"assignmentUnit": "conversation",
"unitId": "conv_83921",
"workflow": "support_chat",
"modelRoute": "balanced_streaming",
"retrievalProfile": "top8_rerank_v2",
"rolloutStage": "canary_5_percent",
"timeToFirstTokenMs": 1240,
"endToEndLatencyMs": 4820,
"inputTokens": 3180,
"outputTokens": 612,
"estimatedCostUsd": 0.009,
"fallbackUsed": false,
"timestamp": "2026-06-26T09:15:30Z"
}
The same unit ID and variation should appear on outcome events:
{
"event": "support_assistant_outcome",
"flagKey": "support_assistant_route",
"variation": "fast_streaming_v2",
"assignmentUnit": "conversation",
"unitId": "conv_83921",
"resolvedWithoutEscalation": true,
"humanCorrection": false,
"userStoppedGeneration": false
}
That join lets the release owner compare perceived responsiveness with actual outcome. If faster first tokens lead to more corrections, the route may be optimizing the wrong thing. If a slower first token leads to much better outcomes and acceptable abandonment, the product may choose to keep the candidate for specific workflows.
Separate TTFT From The Causes Behind It
TTFT is a symptom. The rollout needs enough fields to explain the likely cause.
| Cause area | Field to capture | Example release action |
|---|---|---|
| Prompt or context growth | input tokens, retrieval profile, prompt profile | trim context, change retrieval depth, or hold rollout |
| Provider or model route | model route, provider, retry count, queue delay if available | switch segment to baseline route or fallback |
| Pre-generation checks | policy mode, safety check duration, approval mode | narrow the workflow or adjust guardrail placement |
| Tool planning | tool policy, planned tool count, first tool latency | disable candidate tool mode for affected segment |
| Streaming implementation | stream enabled, first chunk timestamp, client disconnect | fix streaming path before expanding |
| User behavior | abandonment, stop generation, retry, correction | compare TTFT with actual product tolerance |
This is where FeatBit's release-control role is useful. The flag variation should name the route profile that changed. Observability and product analytics can explain the runtime details. The release owner can then change targeting or percentage without redeploying the application.
A Rollout Playbook For TTFT Monitoring
Use TTFT in the same staged release path as other AI guardrails.
-
Define the user journey. Decide whether TTFT matters at the request, conversation, workflow, or account level. Chat and agent workflows often need conversation-level continuity.
-
Put the AI route behind a typed flag. The variation might represent a prompt profile, model route, retrieval profile, response mode, or bundled route profile.
-
Start the timer at product request start. Measure what the user experiences, not only provider latency.
-
Stop the timer at first visible token. For server-side streams, record first chunk received from the provider and first chunk flushed to the client when both are available.
-
Emit exposure when the AI behavior runs. Assignment is not enough. A user can be eligible for a candidate but never trigger the AI stream.
-
Join TTFT to outcome and cost. Use the same flag key, variation, assignment unit, and unit ID across first-token, final-response, outcome, quality, and cost events.
-
Decide the rollout action before expansion. If p95 TTFT breaches the gate, hold expansion. If the breach is segment-specific, narrow the segment. If the breach is severe, route affected traffic to baseline.
-
Clean up after the decision. Promote the winning route, remove losing branches, or convert a fallback route into an intentional operational flag with an owner.
FeatBit can support this flow with targeting rules, percentage rollouts, Track Insights API, flag insights, and feature flag lifecycle management.
How FeatBit Fits
FeatBit should not replace your LLM gateway, tracing system, or product analytics stack. Its job is the release decision: who receives which AI route, how quickly exposure expands, and how quickly the team can reverse a bad route.
Use FeatBit to:
- target the TTFT-sensitive route by account, plan, region, workflow, environment, or risk tier;
- roll out the candidate route to internal users, beta customers, or a small percentage first;
- represent model, prompt, retrieval, streaming, and fallback profiles as typed variations;
- preserve audit history around route and rollout changes;
- send variation-aware metric events through FeatBit insights when useful;
- keep cleanup expectations attached to temporary rollout flags.
Use the application, AI gateway, and observability stack to:
- start and stop TTFT timers accurately;
- enforce timeouts, retries, streaming, and fallback behavior;
- estimate token cost from provider usage data or billing exports;
- correlate traces, logs, errors, and user outcome data;
- diagnose whether delay came from retrieval, policy checks, provider queueing, generation, or client streaming.
OpenFeature's flag evaluation specification is useful vendor-neutral language here: typed evaluation uses a flag key, default value, and evaluation context, while detailed evaluation can add telemetry-friendly metadata. That model maps cleanly to TTFT monitoring because every first-token event needs to know which variation was served.
Dashboard Views That Actually Help
A TTFT dashboard should be designed for release decisions, not curiosity.
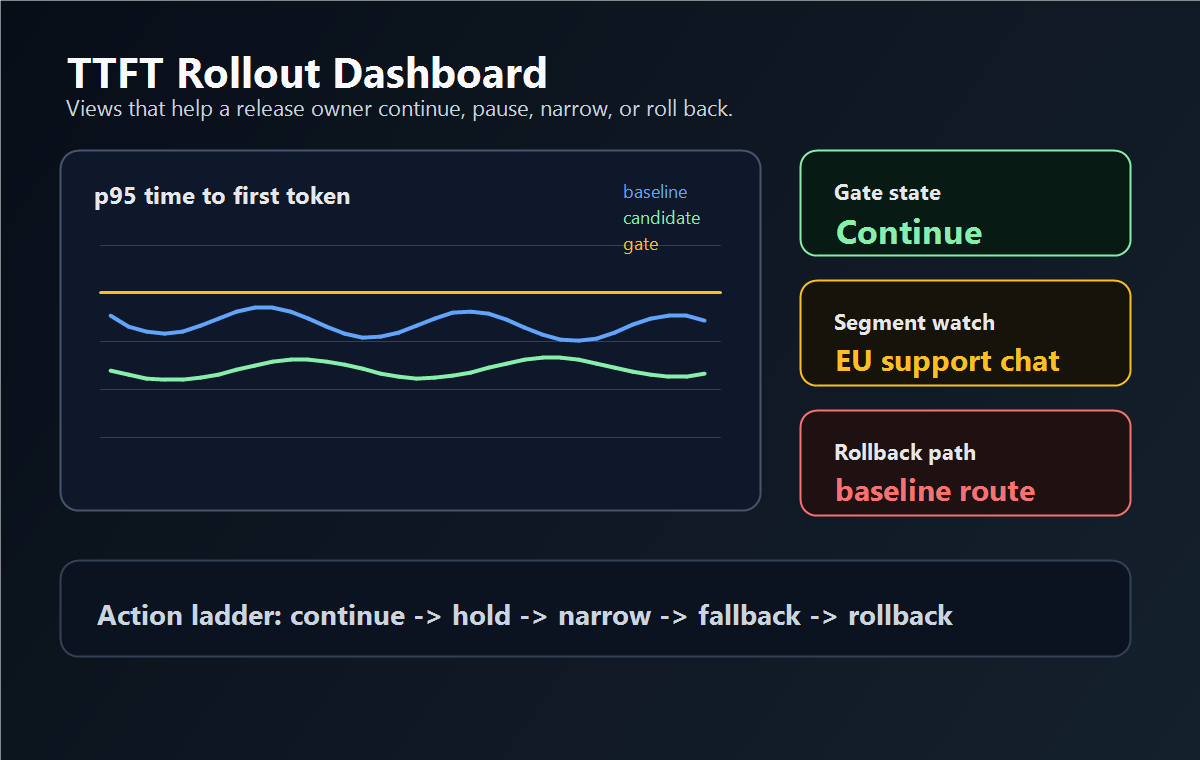
| View | What it should show | Decision it supports |
|---|---|---|
| Rollout stage health | p50, p95, p99 TTFT by baseline, candidate, and fallback | continue, pause, or expand |
| Segment drilldown | TTFT by account tier, region, workflow, plan, or risk level | narrow rollout or exclude affected segment |
| Cause breakdown | retrieval time, policy time, provider wait, first chunk flush, generation rate | fix route profile before changing percentage |
| Outcome join | TTFT next to completion, correction, abandonment, retry, and cost | avoid optimizing speed against quality or value |
| Action history | flag changes, rollout percentage, owner, incident notes, rollback state | audit and post-release learning |
| Cleanup queue | temporary TTFT flags, losing routes, stale fallback logic | prevent release-control debt |
Do not hide the release rule in the dashboard. Put the gate near the chart: "p95 TTFT breach pauses expansion" is more actionable than a line graph with no owner.
Common Mistakes
Measuring provider latency only. Provider timing is useful, but the user waits through request handling, flag evaluation, retrieval, safety checks, routing, and stream flushing too.
Treating assignment as exposure. Emit the TTFT event when the AI stream actually starts producing output, not when a user becomes eligible for the candidate.
Optimizing first token while damaging the task. A fast first token can still produce a worse answer, higher cost, or more escalations. Join TTFT to outcome.
Using averages for rollout gates. Tail latency matters for interactive AI. Use p95 or p99 where user experience risk is concentrated.
Ignoring fallback behavior. A candidate that frequently falls back may look healthier than it is. Record fallback use and fallback reason.
Letting temporary route flags live forever. TTFT experiments should end with a decision: promote, segment, operationalize, or remove.
Bottom Line
Time to first token monitoring is most valuable when it is treated as release evidence.
Measure the first visible token where the user waits. Attach the event to the feature flag variation that selected the AI behavior. Join it to quality, cost, fallback, and product outcome. Then use FeatBit to expand, pause, narrow, roll back, or clean up the route based on evidence instead of guesswork.
Source Notes
- OpenAI latency context: OpenAI's latency optimization guide describes major latency levers such as processing tokens faster, generating fewer tokens, using fewer input tokens, making fewer requests, parallelizing, improving perceived waiting, and avoiding unnecessary LLM calls.
- Streaming telemetry context: Vercel's AI SDK telemetry documentation documents stream-related spans such as
ai.streamText,ai.streamText.doStream, and first-chunk stream events, plus model, provider, and token usage attributes. - Observability context: OpenTelemetry's GenAI semantic conventions page now points to a dedicated GenAI semantic conventions repository. This article uses that as context for evolving telemetry vocabulary, not as a requirement.
- Feature flag context: OpenFeature's flag evaluation specification describes typed flag evaluation, defaults, evaluation context, and detailed evaluation metadata that can support telemetry attribution.
- FeatBit implementation context: FeatBit docs for Track Insights API, targeting rules, percentage rollouts, flag insights, OpenTelemetry integration, and feature flag lifecycle management support the workflow described here.
- Related FeatBit reading: Latency and Cost Guardrails for LLMs, Monitor AI Guardrails for Latency, Cost, Quality, and Safety, AI Insights for Feature-Flagged AI Releases, safe AI deployment, and measurement design.
Image And Open Graph Notes
- Use
/images/blogs/time-to-first-token-monitoring/cover.pngas the Open Graph image because it frames TTFT as a rollout health signal. - Use
/images/blogs/time-to-first-token-monitoring/ttft-release-loop.pngnear the opening because it shows how first-token timing becomes release action. - Use
/images/blogs/time-to-first-token-monitoring/ttft-event-contract.pngin the event contract section because it turns telemetry guidance into a concrete schema. - Use
/images/blogs/time-to-first-token-monitoring/ttft-dashboard.pngin the dashboard section because it shows the decision views release owners need.