What Is a Human-in-the-Loop Flag?
In FeatBit's release-control vocabulary, a human-in-the-loop flag is a runtime feature flag that decides when an AI behavior can run automatically, when it must pause for human review, when it should fall back to safer behavior, and when it should be rolled back. It turns human oversight into an operational control that can be targeted, changed, audited, and reversed without redeploying code.
That makes the term more specific than a generic "human review" step. The flag is the production switch that routes each AI decision based on context: user, account, workflow, region, risk tier, confidence score, incident state, rollout stage, and reviewer availability.
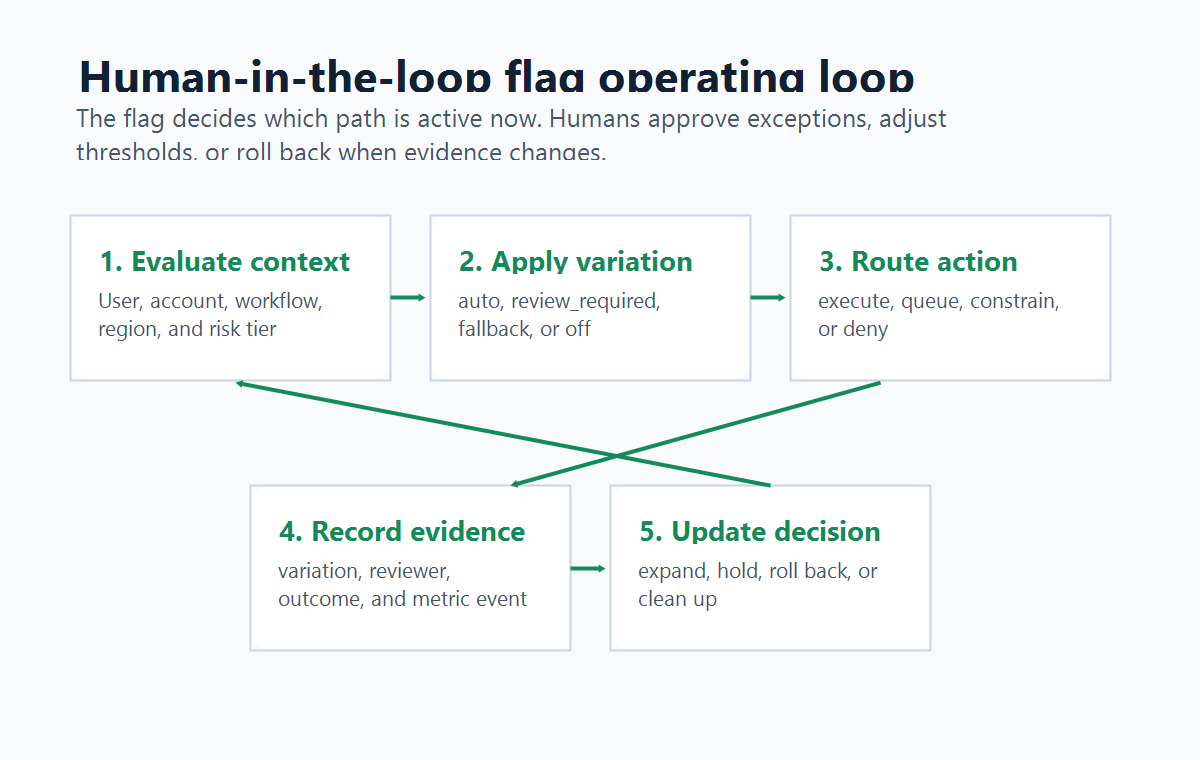
What The Flag Actually Controls
A human-in-the-loop flag controls the boundary between automation and human judgment.
For an AI assistant, that boundary might decide whether the system can answer directly, send a draft to a reviewer, ask a human to approve an external action, route to a fallback workflow, or disable the risky behavior for one segment. For an AI agent, it might decide whether a tool call is read-only, draft-only, approval-required, or unavailable.
The flag usually has one of these shapes:
| Flag shape | Example variation values | Best fit |
|---|---|---|
| Boolean | automatic or human_review_required |
A simple gate where one risky action must be approved. |
| String | auto, review_required, fallback, off |
A workflow with multiple operating modes. |
| JSON | { "mode": "review_required", "queue": "support-leads", "fallback": "draft" } |
A richer policy that needs queue, timeout, fallback, or reviewer metadata. |
The important point is that the AI model should not decide its own authority from a prompt. The application should evaluate the flag at the execution boundary, then route the behavior.
Why AI Systems Need This Kind Of Flag
AI behavior changes faster than traditional application behavior. A prompt edit, model route, retrieval source, confidence threshold, or agent tool policy can change what users see even when the deployment pipeline is quiet. NIST's AI Risk Management Framework frames AI risk management as work across design, development, use, and evaluation of AI systems. A human-in-the-loop flag is one way to make that oversight operational during production use.
Microsoft's Azure AI Content Safety documentation shows how cloud AI platforms expose moderation, prompt protection, groundedness, task adherence, and monitoring capabilities. Those services can detect or score risk. A human-in-the-loop flag answers the next release-control question: what should the product do right now for this user, account, workflow, and risk level?
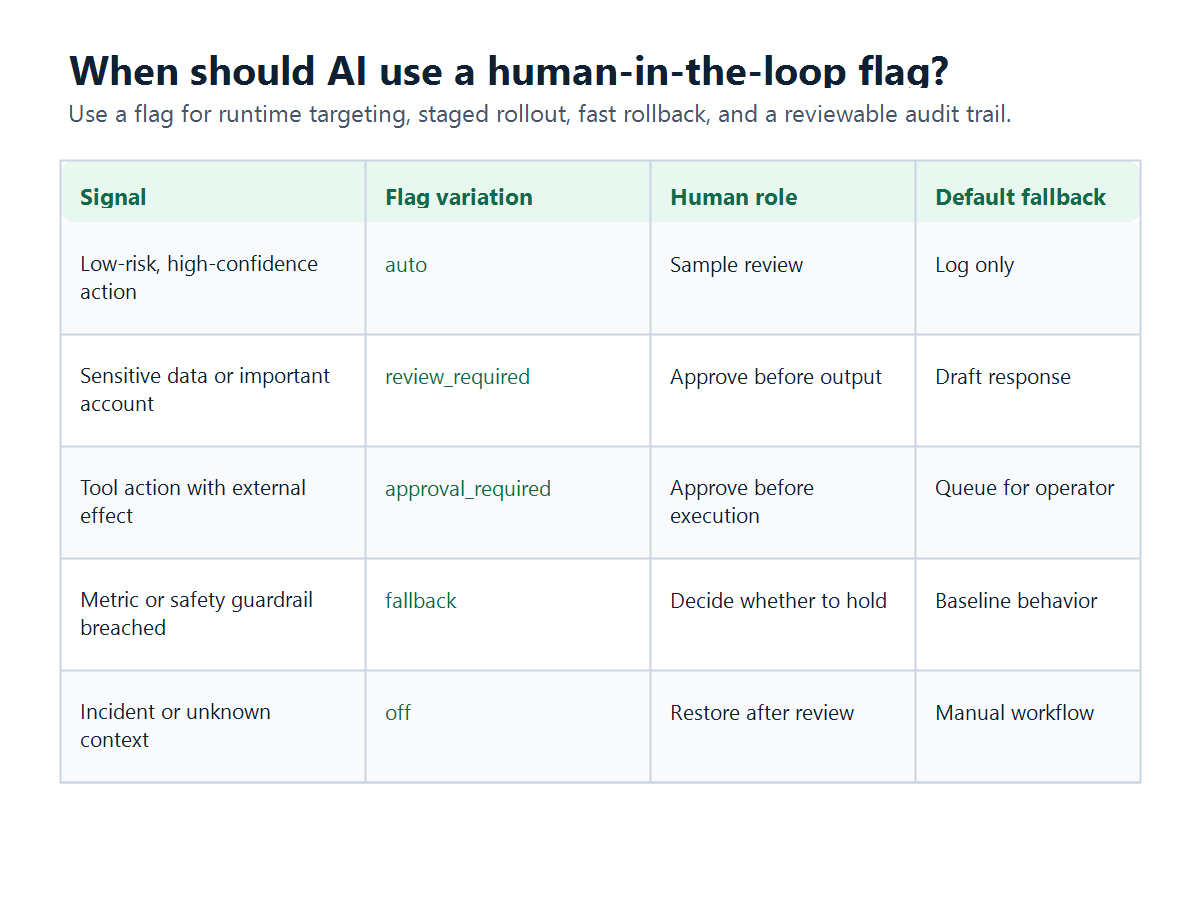
Use a human-in-the-loop flag when at least one of these conditions is true:
- the AI action can affect customer trust, money, permissions, data, compliance posture, support burden, or external systems;
- the model, prompt, retrieval, grader, or tool policy is still being rolled out;
- automated confidence or safety signals are useful but not enough to approve the action;
- different user segments need different levels of review;
- operators need a fast way to reduce AI autonomy during an incident;
- the team needs audit evidence that connects AI behavior, flag variation, reviewer decision, and outcome.
Human-In-The-Loop Flag Vs Related Controls
Teams often mix up human-in-the-loop flags with approval workflows, permissions, eval gates, and content filters. They are related, but they do different jobs.
| Control | Primary job | Where it sits | What it does not replace |
|---|---|---|---|
| Human-in-the-loop flag | Decide the active runtime mode for a context | Application or agent execution boundary | Identity, authorization, security review |
| Approval workflow | Route a change or action to a reviewer | Ticket, pull request, admin UI, queue | Runtime targeting and rollback |
| Permission check | Enforce what an identity is allowed to access | IAM, API, service, tool boundary | Release rollout or experiment logic |
| Offline eval gate | Qualify a candidate before exposure | CI, eval platform, model registry | Production evidence from real users |
| Content safety filter | Detect or block risky content | Input or output processing path | Human decision ownership |
A useful design keeps these layers separate. Authorization says what an actor can ever reach. The human-in-the-loop flag says what the AI behavior may do now. Approval handles consequential exceptions. Evaluation and content safety provide evidence. Audit records let the team reconstruct the decision.
A Simple Example
Imagine a support AI assistant that can answer users, draft replies, and update tickets.
The team starts with a flag called support_ai_action_mode:
support_ai_action_mode:
default: review_required
variations:
auto:
allowedActions:
- answer_with_citations
humanReview: sampled
review_required:
allowedActions:
- draft_reply
- suggest_ticket_update
humanReview: before_external_action
fallback:
allowedActions:
- search_docs
humanReview: optional
off:
allowedActions: []
humanReview: manual_support_workflow
The first rollout stage targets internal support staff. If answer quality, latency, escalation rate, and reviewer correction rate stay healthy, the team can expand auto to a low-risk beta segment. If a guardrail fails, the release owner can switch the same segment to fallback or off without redeploying the assistant.
This is the same release-control pattern behind FeatBit's AI control layer and safe AI deployment: expose behavior gradually, keep the rollback path active, and make the decision visible.
What To Include In The Flag Contract
A human-in-the-loop flag should be boring to operate. The contract should make the safe path obvious before production traffic starts.
Include these fields:
| Contract field | Why it matters |
|---|---|
| Flag key and owner | Prevents anonymous AI controls from becoming permanent release debt. |
| Default variation | Defines the safe behavior when context is missing. |
| Review trigger | Explains why human judgment is required. |
| Reviewer role or queue | Keeps approval from depending on informal chat. |
| Fallback behavior | Preserves a useful product path when autonomy is reduced. |
| Rollback variation | Lets operators stop the risky behavior quickly. |
| Evidence event | Connects the evaluated variation to outcome metrics. |
| Audit fields | Records user, account, workflow, flag variation, reviewer, and action result. |
| Cleanup or permanence rule | Decides whether the flag is temporary release control or durable product policy. |
FeatBit docs for targeting rules, percentage rollouts, audit logs, and IAM cover the product primitives behind this contract. For metric evidence, FeatBit's Track Insights API can connect variation exposure and custom events to release decisions.
Where FeatBit Fits
FeatBit fits the runtime release-control layer around AI systems. It does not need to be the model registry, prompt editor, content moderation service, identity provider, or ticket queue.
Use FeatBit to:
- evaluate the human-in-the-loop flag by user, account, environment, workflow, region, agent identity, or risk segment;
- target review-required behavior to sensitive accounts while allowing lower-risk behavior elsewhere;
- roll out autonomy in stages, such as internal, beta, percentage canary, and broader production;
- roll back to
fallbackoroffwithout a code deployment; - audit who changed the flag, when they changed it, and which variation was active;
- connect flag evaluations and metric events to the release decision;
- review temporary AI release flags through feature flag lifecycle management.
For teams working specifically with agents, FeatBit's human-in-the-loop release control page expands the same idea into capability gates, confidence thresholds, scope limitation flags, and override trails.
Common Mistakes
Putting the rule only in the prompt. A prompt can describe the desired behavior, but it is not a reliable production control. The execution boundary should enforce the evaluated flag.
Using one global mode. Human review often depends on account tier, region, action type, confidence, data sensitivity, and rollout stage. One global "review on" setting is usually too blunt.
Letting review become the fallback for every failure. If every uncertain action becomes a human ticket, the review queue becomes the bottleneck. Design safe fallback modes such as draft, search-only, or baseline behavior.
Skipping audit context. "Human approved" is not enough. The record should show what action was proposed, which variation was evaluated, who reviewed it, what evidence they saw, and what happened next.
Forgetting lifecycle. Some human-in-the-loop flags are permanent policy controls. Others are temporary rollout controls. Decide which one you are creating before the flag spreads through the codebase.
Quick FAQ
Is a human-in-the-loop flag just a feature flag?
It is a feature flag used for a specific AI release-control job: deciding when automation should continue, pause for human review, fall back, or roll back. The feature flag mechanism is familiar. The controlled behavior is AI oversight.
Is it the same as a kill switch?
No. A kill switch usually turns behavior off. A human-in-the-loop flag can turn behavior off, but it can also route to review, constrain autonomy, switch to a draft mode, or keep low-risk automation active.
Should every AI feature have one?
No. Use one when the AI behavior is risky, changing, segment-dependent, or operationally important enough to need runtime control. Low-risk static experiences may only need normal review, monitoring, and rollback.
Can the flag replace security permissions?
No. Keep hard authorization in IAM, API scopes, network controls, and tool-specific permissions. The flag controls runtime release behavior after those boundaries are enforced.
Source Notes
- NIST AI Risk Management Framework, for the voluntary risk-management framing across AI design, development, use, and evaluation.
- NIST AI RMF Playbook, for Govern, Map, Measure, and Manage as an operational vocabulary for AI risk management.
- Microsoft Learn Azure AI Content Safety overview, for category context on moderation, prompt protection, task adherence, Studio workflows, and monitoring.
- FeatBit implementation context: AI control layer, safe AI deployment, human-in-the-loop release control, feature flag lifecycle management, targeting rules, percentage rollouts, audit logs, IAM, and Track Insights API.
Image And Open Graph Notes
- Use
cover.pngas the Open Graph image because it summarizes the AI decision, flag evaluation, and human review path. - Use
hitl-flag-loop.pngnear the opening because it shows the operating loop from context evaluation to release decision update. - Use
hitl-flag-decision-matrix.pngnear the comparison section because it gives readers a practical way to map risk signals to flag variations.